







标题:扩展语言-图像预训练模型以进行通用视频识别
发表:ECCV-2022
问题
使用视频 - 文本预训练会带来以下两个问题:
数据困境:需要数以亿计的视频 - 文本数据,但是大量的数据是难以获得的;
计算困境:视频的训练通常需要数倍于图像的计算资源,这些资源消耗通常无法承受。
有鉴于此,研究者考虑探索如何将预训练的语言 - 图像模型中的知识迁移到视频领域,而非从零预训练一个语言 - 视频模型。与图像相比,视频增加了时间的维度;与传统视频识别框架相比,研究者引入了文本信息。
因此,研究者需要解决两个关键问题:
1.如何在语言 - 图像预训练模型中建模视频的时序信息?
2.如何利用视频类别标签中的文本信息?
方法
针对第一个问题,研究者提出了 Cross-frame Communication Transformer 和 Multi-frame Integration Transformer 模块,在预训练模型中引入时序信息;
对于第二个问题,研究者提出了 Video-specific Prompting 机制,用于产生视频自适应的提示信息,充分地利用了类别标签中的文本信息和视频信息。整体架构如下图所示:
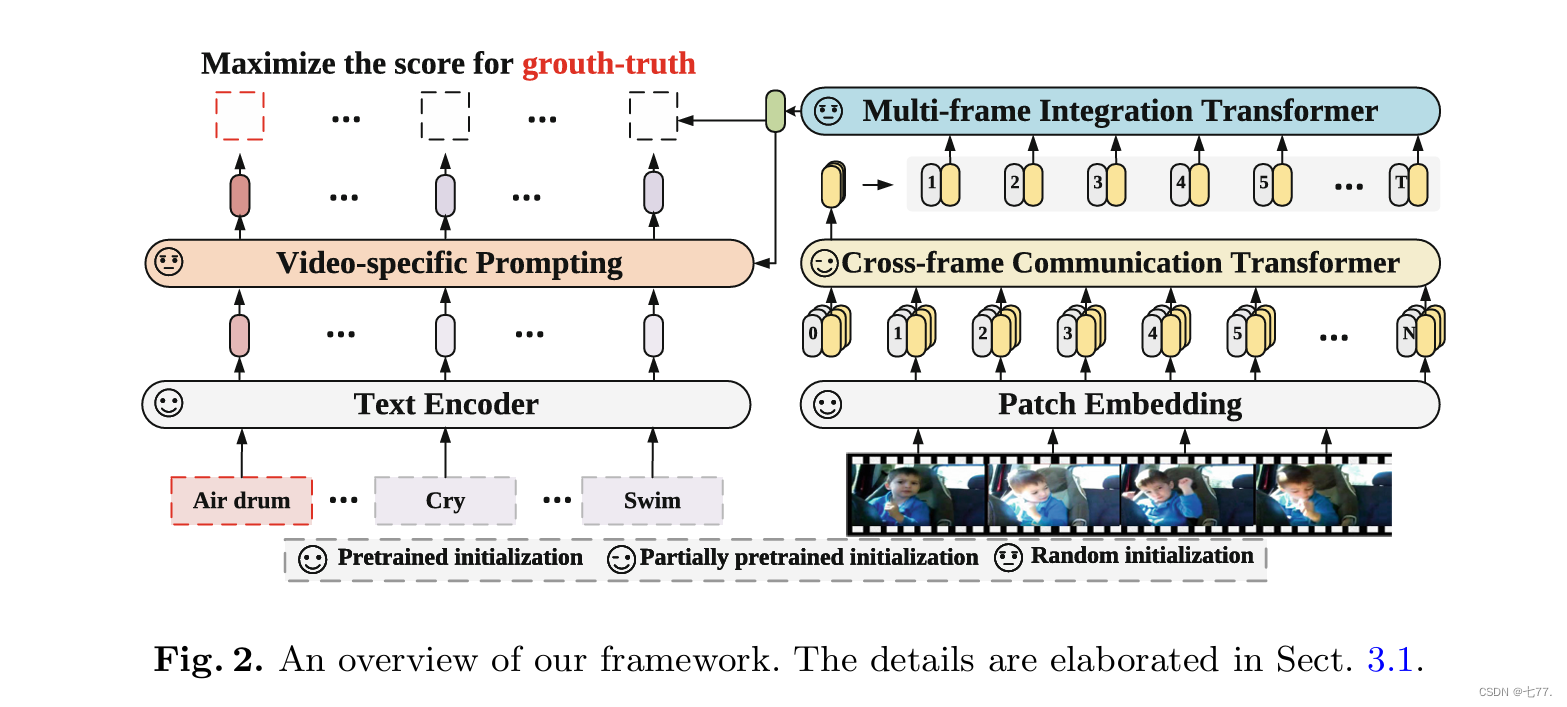
1.视频编码器
CCA(Cross-frame Communication attention block)模块如下图所示:利用message token(cls_token)帧间通讯,来建模时序信息.

本文中,研究者提出了一种简单高效的视频编码器。该编码器由两部分组成,即 Cross-frame Communication Transformer(CCT)和 Multi-frame Integration Transformer(MIT)。为了避免联合时空建模(join space-time attention)的高计算量,整体上,CCT 采用各帧独立编码的计算方式。
具体地,对每一帧编码时,动态地生成各自的 message token(也即是每一帧的cls_token)(如图3中彩色的圆形部分),携带所在帧的信息,再通过 Cross-frame Fusion Attention 交换不同帧的 message token 携带的信息,弥补了时序信息的缺失。具体地,如图3所示,在 CCT 的每一个 block 中,我们在 cls token 上施加线性变化得到 message token,每帧的 message token 通过 Cross-frame Fusion Attention(CFA)交换信息,如下面公式所示:
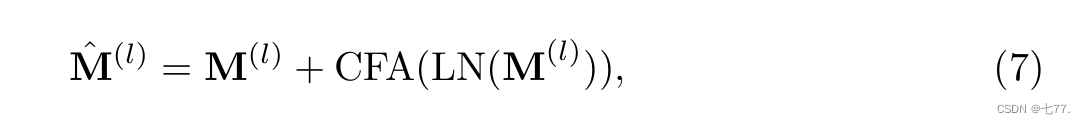
随后,每一帧的 message token 再回归到所属帧。通过 Intra-frame Diffusion Attention(也即是每帧进行空间上的self-attention自注意力计算),每一帧内的 spatial tokens 在建模空间信息的同时,吸收了来自 message token 的全局时序信息,如下面公式所示:
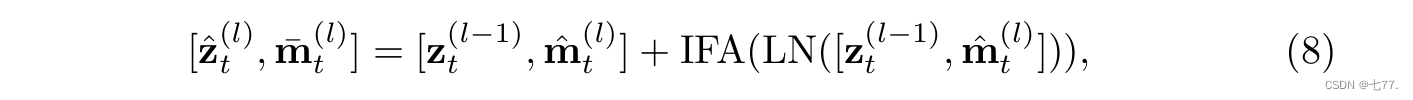
最后,每一帧的 spatial tokens 再经过 FFN 进一步编码信息。为了进一步提升性能,研究者在 CCT 产生的每帧的特征上,额外使用一层 Multi-frame Integration Transformer(MIT)聚合每一帧的信息(使用每一帧的cls-token进行multi-self attention自注意力计算),产生视频最终的表达。
Cross-frame Fusion Attention 和 MIT 是额外添加的模块并使用随机初始化。Intra-Frame Diffusion Attention 和 FFN 对应于预训练 Vision Transformer 中的 self-attention 和 FFN 部分。值得注意的是,因为帧数(本篇论文通常采用8或者16帧)(message tokens 的数量)远小于 spatial tokens 的数量,所以 Cross-frame Fusion Attention 和一层 MIT 的计算量远小于 Intra-frame Diffusion Attention, 这样便以较小的计算代价建模了全局的时序信息。
2.文本编码器
利用标签的语义信息:视频自适应的提示学习针对第二个问题,提示学习(Prompt learning)主张为下游任务设计一种模板,使用该模板可以帮助预训练模型回忆起自己预训练学到的知识。比如, CLIP手动构造了 80 个模板,CoOp主张构造可学习的模板。
研究者认为,人类在理解一张图片或视频时,自然地会从视觉内容中寻找有判别性的线索。例如有额外的提示信息「在水中」,那么「游泳」和「跑步」会变得更容易区分。但是,获取这样的提示信息是困难的,原因有二:
数据集中通常只有类别标签,即「跑步」、「游泳」、「拳击」等名称,缺乏必要的上下文描述,固定的标签名称;
同一个类别下的视频共享相同的标签信息,但它们的关键视觉线索可能是不同。
为了缓解上述问题,研究者提出了从视觉表征中学习具有判别性的线索。具体地,他们提出了视频自适应的提示模块,根据视频内容的上下文,自适应地为每个类别生成合适的提示信息。每个视频的自适应提示模块由一个 cross-attention 和一个 FFN 组成。令文本特征当作 query,视频内容的编码当作 key 和 value(Key,Value是从经过视频编码器Multi-frame Integration Transformer(MIT)后得到的,也即是视频每帧添加的cls_token作为key,value),允许每个类别的文本从视频的上下文中提取有用的提示信息作为自己的补充,最后,使用学习到的提示信息来丰富原本文本信息的表示,使得其具有更强的判别性。公式如下。
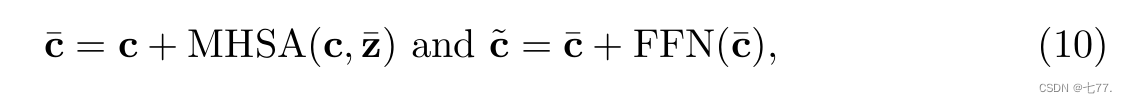
总结
创新点1:视频编码器包含两个transformer,第一个transformer是Cross-frame Communication Transformer(CCT),包含12个block,里面每个block有Cross-frame Fusion Attention(CFA)和 Intra-frame Diffusion Attention(IFA),CFA将各帧cls_token计算多头自注意力(Mutil-head self attention),从而对视频时序建模,获取视频全局时序信息;IFA计算每一帧里面各个patch的空间自注意力信息。
创新点2:第二个transformer是Multi-frame Integration Transformer(MIT),只包含1个block,一个标准的transformer encoder 的block(一个Mutil-head Self Attention+FFN),输入是视频每帧经过第一个transformer编码得到后的所有帧的cls_token作为输入,进行多头自注意力计算。
创新点3:视频自适应文本提示:将数据集标签经过text transformer编码后得到的cls_token当做query与经过视频编码器后得到的所有帧的cls_token当做key,value 进行多头注意力计算(注意此处不是进行自注意力计算),来生成视频自适应的文本提示。















 2240
2240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









