







标题:TIM:一种用于视听动作识别的时间间隔机器
源码链接:https://github.com/JacobChalk/TIM![]() https://github.com/JacobChalk/TIM
https://github.com/JacobChalk/TIM
发表:CVPR-2024
目录
摘要
长时间的视频中,各种动作会产生丰富的视听信号。最近的研究表明,音频和视频这两种模态的事件时间长度和标签各不相同。我们通过明确建模音频和视觉事件的时间长度来解决长时间视频中两种模态之间的相互作用。我们提出了时间间隔机器(TIM),其中特定模态的时间间隔被用作查询,输入到一个处理长视频输入的转换器编码器。然后,编码器关注于指定的时间间隔,以及两种模态中的周围上下文,以识别正在进行的动作。
我们在三个长视听视频数据集上测试了TIM:EPIC-KITCHENS、Perception Test和AVE,报告了识别方面的最新技术(SOTA)。在EPIC-KITCHENS上,我们击败了之前利用大型语言模型(LLMs)和显著更大预训练量的SOTA,将顶级动作识别准确率提高了2.9%。此外,我们还展示了TIM可以通过使用密集多尺度间隔查询来适应动作检测,在EPIC-KITCHENS-100上大多数指标都超过了SOTA,并在Perception Test上表现出强大的性能。我们的消融实验表明,整合两种模态并建模它们的时间间隔在实现这种性能中起着关键作用。代码和模型可在以下网址获取:https://github.com/JacobChalk/TIM。
1. 简介
长视频展现出了一系列快速连续的听觉和视觉事件。最新的尝试分别在这些模态中标注事件[15, 30],展示了两种模态之间的时间长度和类标签都有所不同。然而,这些事件仍然保持相关——识别两种模态中时间上接近的事件可以改善视觉和音频中的动作识别。
此外,迄今为止的大多数方法通常仅利用动作的精确时间长度;一个精确裁剪的动作片段被输入到基于卷积[5, 8, 39]或基于转换器[1, 11, 22]的主干网络中,该网络预测正在进行的动作。即使当利用周围上下文来改善动作识别时[18, 31, 42],这种上下文也是以相邻动作的精确片段形式提供的,而不是未裁剪的长输入视频。在本文中,我们提出了一种方法,该方法编码长视频输入中视觉和听觉流中发生的多个事件。我们通过将时间间隔提升为首要元素来实现这一点,利用它们来指定伴随模态中的查询。我们将这种机制称为时间间隔机器(TIM)。它能够接收长视频输入,并输出被查询模态的查询区间内发生的动作。
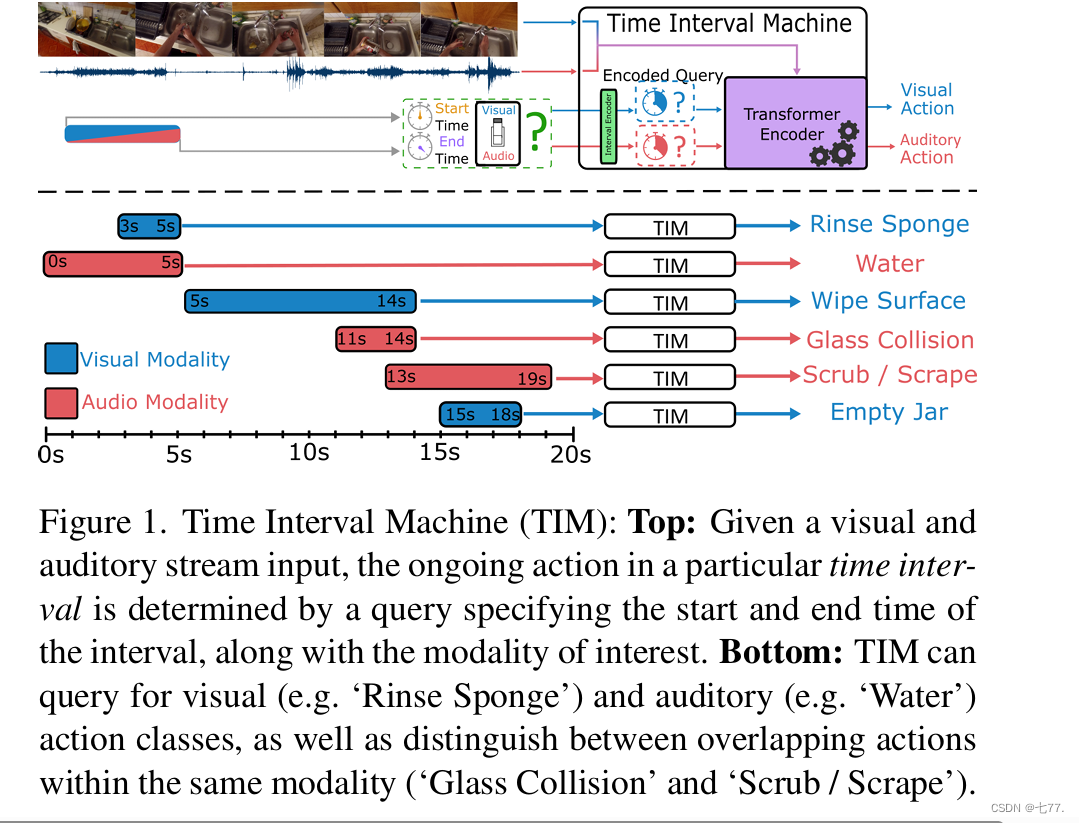
图1. 时间区间机器(TIM):顶部:给定视觉和听觉流输入,特定时间区间的正在进行的动作由指定该区间开始和结束时间的查询以及感兴趣的模态来确定。底部:TIM可以查询视觉(例如,“冲洗海绵”)和听觉(例如,“水声”)动作类别,并区分同一模态中重叠的动作(“玻璃碰撞”和“擦洗/刮擦”)。
考虑图1中的示例。输入包含水流动的声音,同时海绵被冲洗,之后用来擦拭表面。这些不同的事件在持续时间上可能差异很大,并且可能在音频或视觉模态中更为突出。尽管这些事件之间存在差异,但它们与周围环境之间很可能存在许多相关性,这可能有助于识别给定事件(例如,水声与冲洗海绵相关,为识别视觉动作提供了有用的信息)。TIM能够通过访问两种模态内的上下文(包括没有事件发生时的背景)来利用这一点。然后,它可以通过查询给定模态中特定事件的时间间隔来区分同一输入中不同且可能重叠的事件。
我们在三个具有挑战性的长视频视听识别数据集上测试了TIM:EPIC-KITCHENS[7],该数据集最近通过EPIC-SOUNDS[15]提供了不同的音频标注;Perception Test[30];以及AVE[36]。我们展示了TIM能够在长输入中有效地学习视觉和听觉类别,在EPIC-KITCHENS上比当前最先进(SOTA)的top-1准确率提高了2.9%,在EPIC-SOUNDS上提高了1.4%,尽管之前的竞争方法使用了更大的预训练数据集、大型语言模型或更高分辨率的输入。此外,我们在AVE上比使用公共数据集预训练的模型提高了0.6%,并在Perception Test的视觉和音频动作识别中分别比强大的基线提高了9.9%和3.2%。
此外,我们通过固定多尺度密集查询和添加区间回归损失,将TIM适应于动作检测。我们在EPIC-KITCHENS和Perception Test上报告了强大的检测结果,分别比Action Former[49]高出1.6平均mAP和4.3。
我们的贡献总结如下:(i) 我们提出了TIM查询机制,用于关注长视频中特定模态的区间。(ii) 我们有效地训练TIM以使用时间区间编码/查询多个音频和视频动作。(iii) 我们展示了TIM在视觉和听觉动作识别中的价值,并通过添加区间回归损失将其适应于检测。(iv) 我们在多个数据集的视频和多模态识别中均达到了新的SOTA水平。
2. 相关工作
音-视频动作识别。已有一些工作采用音频和视觉模态进行动作识别[10, 17, 18, 26, 41, 44]。一些工作引入新的架构来有效地融合不同模态[17, 18, 26, 44];其他工作则提出了独特的训练技术来解决训练多模态模型时出现的问题,如梯度混合[41],以解决每个模态以不同速度过拟合的问题,或跨模态对比学习以进行区分[25]。然而,这些工作对两种模态都使用相同的语义和时序标签。最近的工作表明,事件的时序区间和语义在不同模态之间是不同的[15, 30]。[37]独立地对视觉和听觉事件进行了时序标注,尽管它们共享相同的标签集。在这项工作中,我们为每个模态训练了不同的标签,以利用具有判别性的音频和视觉动作。
利用时序上下文。一些工作已经考虑了融入时序上下文[18, 27, 42, 43, 48],这是一个与使用多种模态正交的方向,特别是在未裁剪的视频中特别有用。在[27]中,提出了一种基于自回归LSTM的编码器-解码器,用于动作序列分类,有效地利用过去的动作上下文来预测当前的动作。时间查询网络(Temporal Query Network)[48]使用可学习的查询向量,这些向量对应于长视频的特定属性,使模型能够关注视频的各个方面及其周围的上下文,以产生针对每个属性的响应。[42]提出通过长期特征库(Long-Term Feature Bank)和注意力机制,从邻近的动作片段中聚合时间上下文来增强动作的表示。[43]通过存储一个转换器所有中间层的键和值来构建一个更复杂的记忆库,以聚合过去的上下文。最后,[18]利用视觉、音频和语言从周围动作中提取多模态时间上下文。
[18, 42, 43]与我们的方法最为接近,因为共同的目标是使用未裁剪视频中的周围上下文来丰富感兴趣动作的表示,而不是仅依赖邻近的片段。然而,[42, 43]是单模态模型,仅识别视觉动作。[18]假设所有动作的时间范围都是已知的,包括测试集,这具有一定的限制性。
视觉模型中的查询。使用Transformer架构学习视觉查询最近受到了关注[4, 14, 16, 23, 48]。通常,这些方法使用一组可学习的向量来查询输入中某个概念的存在。例如,在[4, 23]中,可学习的查询对应于不同的对象,而在[14]中,它们被用于多任务学习,每个可学习的查询对应于不同的任务。[16]已经融入了可学习的查询来适应预训练模型,同时保持其余参数冻结。与我们的动机最接近的是[48],其中查询对应于视频中的事件及其属性,用于细粒度动作识别。作者指出,这些查询还具有在未裁剪视频中定位事件时间的作用。
与[48]和其他工作不同,我们的查询主要是时间性的,没有语义解释,并且应用于多个模态。重要的是,由于时间是连续的,我们不能使用预定义的一组查询。相反,我们采用MLP架构来编码时间,类似于一个通用时钟。接下来我们将介绍我们的方法。
3. 时间间隔机
在本节中,我们描述了时间间隔机器(TIM),一个多模态Transformer编码器架构,其中所有输入(包括特征和查询)都与其相关的时间间隔进行编码。时间间隔结合了每个音频和视觉特征的持续时间和位置,并用于查询网络以获取给定时间间隔内发生的任何动作。TIM的架构如图2所示。它接收大量的视频输入,这些输入被表示为一系列音频和视觉特征,并为提供的时间间隔输出正在进行的听觉或视觉动作标签。
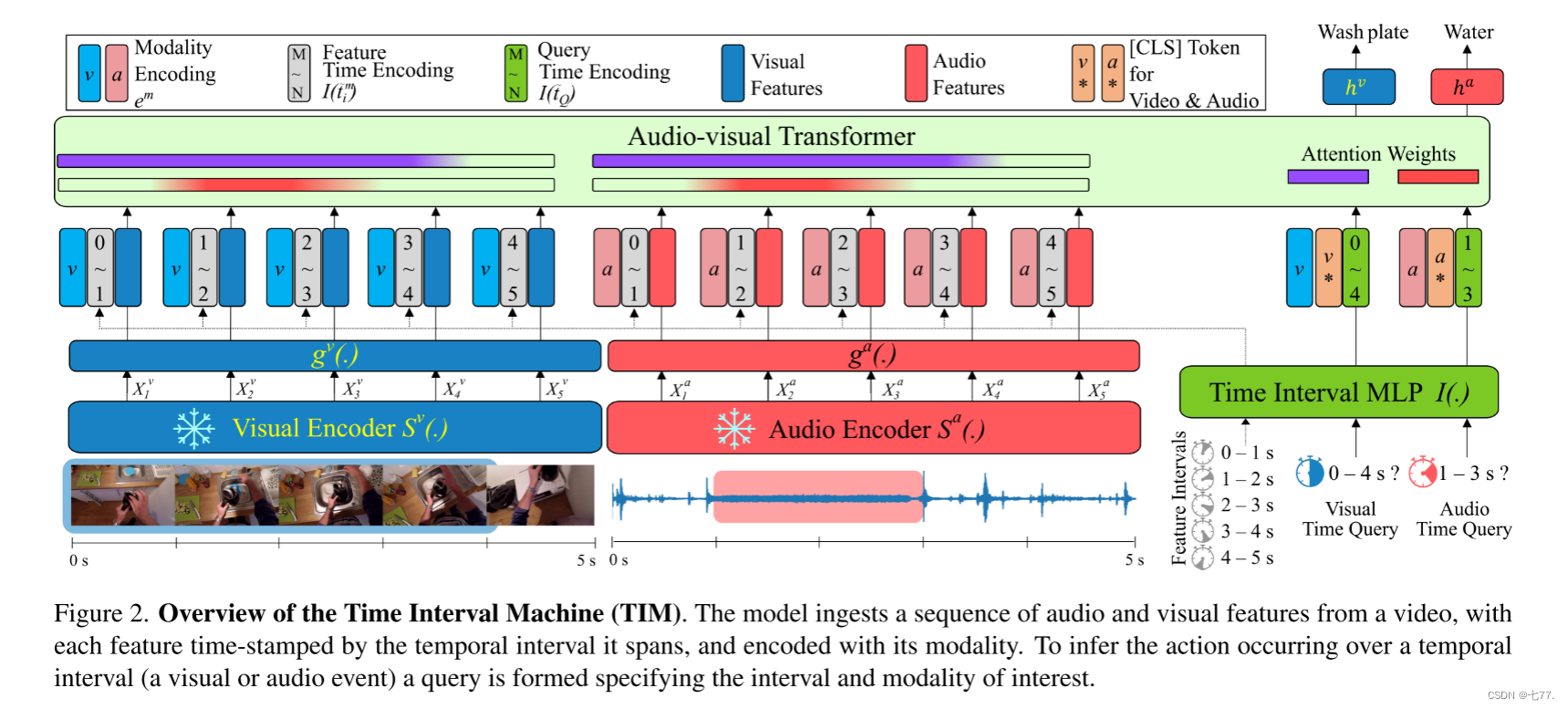
图2. 时间间隔机器(TIM)概述。该模型接收来自视频的音频和视觉特征序列,每个特征都通过其跨越的时间间隔进行时间戳记,并根据其模态进行编码。为了推断在时间间隔内发生的动作(视觉或音频事件),会形成一个查询,指定感兴趣的时间间隔和模态。
3.1. 模型体系结构
输入。TIM的输入是未裁剪视频的长片段,由提取的特征表示。当考虑两种模态输入,如视频和音频时,每种模态的嵌入是分别进行的:对于每种模态m,设Xm = [Xm1, ..., XmNm]是输入视频的Nm个按时序排列的特征表示,这些特征表示是从预训练的特征提取器Sm(·)中获得的。我们将这些特征通过特定模态的嵌入层gm(·)进行传递,将它们投影到所有模态共有的较低维度D。然后,嵌入的特征会被标记上模态编码和时间间隔编码,形成Transformer编码器的输入。现在我们详细说明如何对时间间隔进行编码。

图3. 时间间隔MLP I(·)的说明。它输入一个二维向量,即一个时间间隔的起始时间和结束时间,并输出一个单一向量,该向量可以沿着通道维度与输入特征或[CLS]标记进行级联。图中展示了三个时间间隔输入和三个对应的输出。请注意,在实际操作中,时间间隔是同时输入的。
时间间隔编码。在这项工作中,我们介绍了一种新型的学习查询网络——时间间隔MLP(多层感知器),它生成一个表示给定时间间隔的单一的D维向量。这个网络在TIM中用于编码输入特征的时间间隔以及我们想要查询并后续分类的时间间隔。图3说明了这个网络的概念。
时间间隔MLP I(·) : R2 → RD 接收一个时间间隔作为输入,这个时间间隔由起始时间和结束时间表示,并输出该时间间隔的一个单一的D维编码。请注意,这与单独编码起始时间和结束时间是不同的。具体来说,设ts和te是感兴趣的时间间隔的起始时间和结束时间,它们被长视频输入的长度归一化。I(·)接收时间间隔 ˜t = [ts, te] 作为输入,并输出该时间间隔的D维向量编码,这个向量编码了时间间隔在输入内的相对位置,以及其持续时间。然后,这个向量作为模型关于该时间间隔内发生的动作的查询。此外,每个特征在输入内跨越一定的时间间隔。因此,对特征的时间间隔进行编码也很重要。总的来说,时间间隔MLP充当了一个通用时钟,它编码了输入中来自任何模态的特征的时间范围。请注意,对于输入特征和跨模态查询的所有时间间隔,使用相同的时间间隔MLP进行编码是至关重要的,以便准确编码通用时间。还值得注意的是,时间间隔MLP可以覆盖连续的时间间隔,而传统的位置编码仅覆盖输入特征的固定位置集合。时间间隔MLP与Transformer一起进行端到端的训练。
Transformer特征输入。设 是来自模态m的视频特征Xm对应的时间间隔。我们通过通道级联将编码的时间间隔I(˜tm)注入到嵌入的特征中。然后,一个可学习的特定模态编码em ∈ R2D被添加到时间编码的特征上,以区分每个模态。总结来说,TIM的特征输入Em通过以下方式计算:
其中[·, ·]表示级联。
Transformer查询输入。为了查询某个感兴趣区间内的动作,我们采用了标准的方法,即在输入序列的末尾添加一个可学习的分类标记CLSm。如果˜tQ是一个感兴趣的时间区间,我们将时间区间表示I(˜tQ)沿着通道维度与这个分类标记连接起来,这作为网络的一个查询,以预测在˜tQ区间内发生的对应动作。我们还向每个分类标记添加了模态特定的编码,作为一个标志来区分我们正在查询的是哪种模态。编码后的[CLS]m标记可以更正式地定义为:
在训练期间,我们为输入视频中的每个动作添加一个分类标记,从而在两种模态中都生成了多个[CLS]标记。
Transformer编码器。我们使用transformer编码器对输入序列执行自注意力机制,以聚合相关的时间上下文和跨模态关系。我们使用编码后的特征输入Em和一个或多个代表每个时间区间查询的分类标记[CLS]m来形成transformer的输入序列,并将这些输入到编码器中。请注意,我们通过向输入中添加多个CLSm标记来同时识别来自任何模态的所有动作。然后,将transformer输出的[CLS]m表示ZmCLS传递给相应的线性分类器,以预测动作标签。重要的是,我们使用注意力掩码来防止查询之间相互关注,同样防止输入特征关注查询,这确保了在推理期间,每个查询都是在不依赖于其他查询或动作边界的特权知识的情况下被识别的。
3.2. TIM的训练和测试
为了训练TIM(Temporal Interaction Modeling),我们考虑未裁剪视频中的所有W秒长的连续片段,并以Hw的步长遍历整个视频。我们从这些片段中随机选择批次。对于每个窗口,我们查询所有与窗口重叠超过δ = 0.2秒的已标注音频和视觉动作。
窗口中的所有查询都被编码并连接到不同的CLS标记上。为了对查询进行分类,设为模态m的线性分类器,设
为ZmCLS输出表示的预测动作。
我们通过使用交叉熵分类损失CE(·)在真实标签ymCLS上训练TIM,如下所示:
其中NQ是批次内的查询数量。
时间距离损失。除了标准的分类损失外,我们还引入了时间距离(TD)损失作为训练TIM的辅助损失。受到[21]的启发,其中使用自监督学习令牌嵌入中的相对补丁位置,我们同样训练网络以获取两个transformer输出并预测它们对应时间区间之间的经过时间。
设为来自所有模态的特征的transformer输出。我们从这些输出中随机采样一组特征对
,将它们沿通道维度连接并输入到时间距离回归头
,以预测每对之间的时间区间差。请注意,特征对可以在模态内部和跨模态中采样。在我们的情况下,我们通过将一个视觉特征与另一个音频特征配对来跨模态采样。这有助于模型学习模态之间的时间关系。
正式地,TD损失Ltd计算为:
其中dij是区间˜ti, ˜tj之间的时间距离。
将两个时间段的特征进行通道维度拼接,输入到时间距离回归头来预测这两个时间段之间的时间差,通过最小化TD损失,来使得从特征层面预测的时间差和实际的时间差相近。
训练目标和策略。对于最终的训练损失,我们将各模态的损失与时间距离(TD)损失相加:
其中,M 是模态的集合,λm 控制每个模态损失的权重,λtd 是一个超参数,控制时间距离(TD)损失的权重。
测试时增强。我们使用测试时增强,因为这通常会增加预测的鲁棒性和性能[29, 32]。在TIM中,我们使用一个滑动窗口遍历未裁剪的视频,从而为相同的区间查询提供不同的上下文。然后,我们将不同窗口中相同区间查询的预测结果进行聚合,以做出最终预测。
3.3. 适应检测
虽然TIM最初是为了识别而设计的,但我们可以将其调整为用于检测。其基础架构在识别方面基本保持不变,但有两个主要的不同点。首先,我们在每个尺度上构建了跨越整个视频输入的密集多尺度区间查询。这些查询在训练和检测推断中都被用作区间查询。多尺度区间允许检测长动作和短动作。其次,我们引入了一个额外的区间回归头,该回归头将查询区间回归到动作的精确时间长度。
在训练过程中,我们将多尺度金字塔中任何与真实动作重叠超过某个IoU(交并比)阈值的查询视为正查询。除了对查询进行分类外,我们还训练了一个DIOU回归损失[52]来预测动作的精确区间。分类损失和区间回归损失都是联合训练的。我们在ArXiv附录中提供了完整的细节。
4. 实验
本节描述了用于评估我们模型的数据集、实现细节和结果,以及与最先进方法的比较。
4.1 数据集
EPIC-KITCHENS-100 [7] 是一个大规模视频数据集,包括 700 个记录厨房中动作的第一人称视角视频。它包含 89,977 个细粒度动作片段。受先前工作 [11, 34, 35] 的启发,我们直接在训练和验证集中从 3806 个类别中预测动作,以避免预测无效动作。
EPIC-SOUNDS [15] 提供了音频注释,这些注释捕获了 EPIC-KITCHENS-100 音频流中的时间范围和类别标签。注释包含 78,366 个标记的音频事件。我们将 EPIC-KITCHENS 的视觉注释与 EPIC-SOUNDS 的音频注释结合起来,以训练我们的音视频模型。TIM 可以使用单个模型从两个数据集中识别动作。
AVE [36] 包含 4,143 个视频,涵盖了一系列现实生活场景,并被标记为 27 个类别,如教堂钟声、男性说话和狗叫。每个视频都被平均分成 10 个段,每个段长 1 秒。我们在监督音视频事件定位任务上评估 TIM。给定一个 1 秒的片段,我们从 27 个类别加上一个背景类别中识别正在进行的动作。
Perception Test [30] 是一个最近的包含 11,620 个视频的多模态视频基准,平均长度为 23 秒,同时提供了时间动作和声音注释。有 73,503 个跨越 63 个类别的视觉注释,以及 137,128 个跨越 16 个类别的声音注释。
4.2. 实现细节
架构细节。视觉和音频嵌入层 gm 包括一个单一的 512 维前馈层,随后是 GELU [13] 激活函数和层归一化 [2],用于将特征投影到公共空间。时间间隔多层感知机 I 由三个具有 512 维隐藏维度的线性层组成,后跟 ReLU 激活函数,最后一个线性层的输出后还有层归一化。我们为每个模态的每个查询都包含了 512 维的可学习 [CLS] 标记(如 [CLS]m_action),这些标记在与时间间隔编码拼接后变为 1024 维。然后,它们与 1024 维的模态编码 e_m 相加。音视频转换器包含四个编码器层,每层有 8 个注意力头、GELU 激活函数以及 1024 维的键、查询和值。在编码器层内部应用了 p=0.1 的丢弃率。我们还在原始输入特征以及编码后的转换器输入上直接应用了通道级丢弃率 p=0.5。时间距离头由两个隐藏维度为 1024 的线性层和一个输出单个数字的第三层组成,该数字对应于每个时间间隔之间的已过去时间。我们在 ArXiv 附录中包含了关于编码器层和时间距离头的架构消融研究。
训练/验证细节。我们使用 AdamW [24] 优化器对每个模型进行 100 个周期的训练,批次大小为 64,权重衰减为 1e-4。在前两个周期中应用了线性学习率预热,从 1e-6 增加到目标学习率,并使用余弦学习率调度器。我们将 TD 损失权重 λtd 设置为 0.3。我们为批次中每个窗口的查询填充到每个数据集中单个窗口中的最大查询数。我们在 ArXiv 附录中为每个数据集提供了实现细节。
4.3.结果
我们将 TIM 与每个数据集上的最先进(SOTA)模型进行了比较。
EPIC-KITCHENS / EPIC-SOUNDS 结果。我们在 EPIC-KITCHENS 视频的视觉和音频标签上训练了一个单一模型,并在两个数据集上都报告了结果。对于视觉特征,我们将 Omnivore [11] 和 VideoMAE-L [38] 的特征沿通道维度进行拼接,形成了 2048 维的特征。对于音频特征,我们使用了 Auditory SlowFast [19],它在多个音频领域中都具有良好的泛化能力 [40]。对于这两种模态,我们每 0.2 秒提取 1 秒的特征。在训练过程中,我们提取了额外的增强特征集——对视觉特征使用 RandAugment [6] 进行增强,对音频特征使用 SpecAugment [28] 进行增强。
表 1 将 TIM 与 EPIC-KITCHENS-100 数据集上的 SOTA 模型进行了比较。我们在动词分类上比 M&M Mix [45] 高出 5.1%,在名词分类上高出 0.9%,在动作分类上高出 3.9%。与我们的模型相比,MTV 和 M&M Mix 都使用了额外的私有数据集 [33],该数据集包含 194K 小时的 7000 万个视频,而我们仅使用了使用公共数据集预训练的开源视觉主干网络。我们还超过了利用预训练的 LLM(大型语言模型)来学习视频表示的 LaViLa [51] 和 AVION [50]。
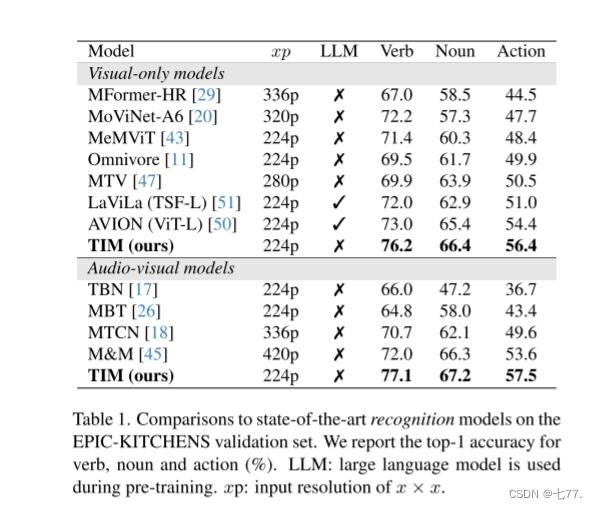
我们注意到,我们经常在不使用任何提升性能的额外技术的情况下就超过了所有先前的工作。例如,我们使用短边裁剪的 224×224 图像,而 [45] 使用 420×420 的图像,这增加了第一人称视频中物体的空间分辨率,从而实现了更好的名词识别。我们预计,当实施以下任何一项时,性能将进一步提升:使用更高分辨率的特征提取器、进行额外的大规模预训练以及引入 LLM。我们将此作为未来工作的一个方向。
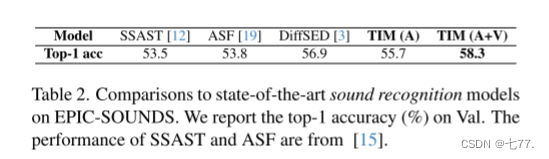
表 2 比较了 TIM 在 EPIC-SOUNDS 数据集上的表现与先前结果的对比,TIM 的表现比当前最优方法(SOTA)高出 1.4%。
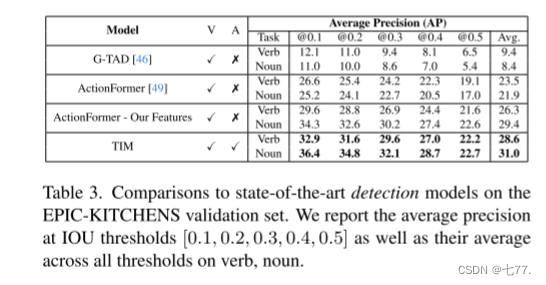
在检测方面,如表 3 所示,我们展示了 TIM 在与主要为此任务设计的模型相比时能够产生具有竞争力的结果。经过适配用于检测的 TIM 在使用相同特征集的情况下,在动词检测上比 ActionFormer [49] 高出 2.3 mAP,在名词检测上高出 1.6 mAP。
AVE 数据集结果。由于此数据集包含联合的音频-视觉标签,我们通过复制查询来训练 TIM,即每种模态使用一个 [CLS],并在训练和推理过程中结合它们的 logits。为了与其他工作进行公平比较,我们使用了 [36] 中的预训练公开可用模型。我们还在将空间视觉特征输入到转换器之前,对来自 VGG-19 的空间视觉特征应用了 AVGA [36]。表 4 展示了我们在 AVE 数据集上的结果。结合音频和视频显著提高了 TIM 的性能。尽管 [9] 的结果表现最佳,但无法复制。我们还报告了使用在 EPIC-KITCHENS 上使用的 Omnivore 视觉特征和 Auditory Slowfast 音频特征的 TIM 结果,这实现了 0.6% 的性能提升。

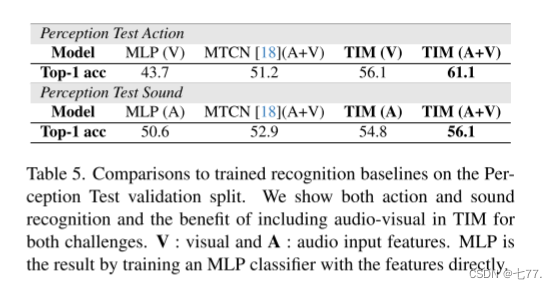
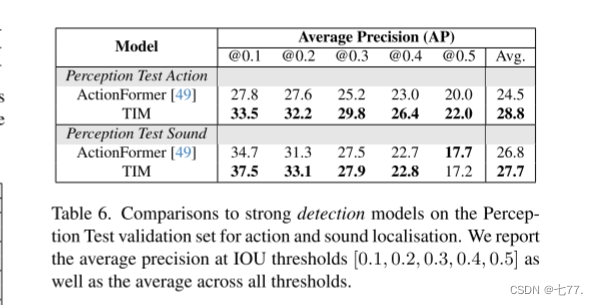
感知测试结果。我们使用相同的 Omnivore 特征和 Auditory Slowfast 特征的骨干网络,并使用视觉和音频标签训练了一个单一模型。表 5 比较了新引入的感知测试的结果。我们训练了一个具有两个线性层和 ReLU 激活函数的 MLP 分类器,直接在特征上作为基线。我们还评估了一个使用 MTCN 的具有上下文的音频-视觉模型。与这些方法相比,TIM 显然显示出显著的改进。在视觉和音频识别任务上,TIM 分别比 MTCN 提高了 9.9% 和 3.2%。表 6 还提供了检测结果。当使用相同的特征时,TIM 在视觉动作上的平均 mAP 比 ActionFormer [49] 高出 3.3%,在声音上的平均 mAP 高出 0.9%。
TIM中的跨模态性。回顾我们之前的结果,我们发现引入额外的模态在所有情况下都提高了性能,这凸显了TIM利用和区分不同模态的能力。例如,在EPIC-KITCHENS-100上,包含音频提高了视觉动作准确率0.9%。对于EPIC-SOUNDS,视觉模态进一步提高了准确率2.6%。在感知测试中,包含音频模态使视觉识别提高了5.0%,而视觉又使声音识别提高了1.3%。最后,对于AVE,我们看到了显著的改进,其中音频-视觉模型仅从音频模态就提高了13.7%的准确率。
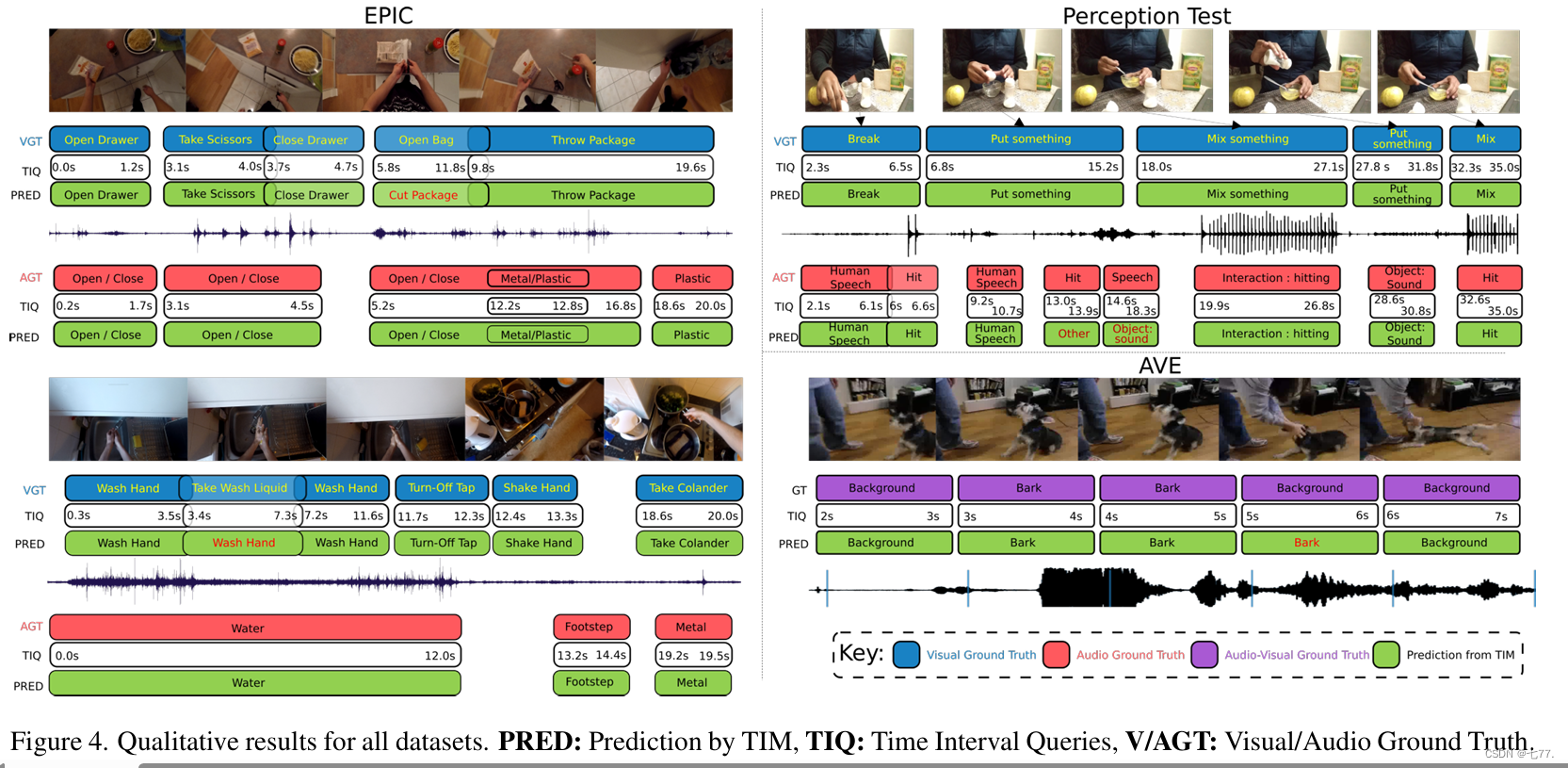
定性结果。我们在图4中展示了定性结果。我们可以看到,在EPIC-KITCHENS中,TIM能够跨两个模态(包括重叠的查询)熟练地识别动作。此外,我们还看到连续的动作被正确识别,其间隔长度各不相同,如“打开/关闭”的音频动作在0.2s到4.5s之间。对于AVE,TIM能够根据时间间隔查询区分背景和“吠叫”的音视频事件。在感知测试中,我们看到TIM可以区分两个模态中严重重叠的动作,如“破碎”、“人声”、“打击”和“放东西”。然而,也有一些失败的情况,例如在EPIC-KITCHENS中,动作“拿洗碗液”被识别为“洗手”,因为模型很可能被主要与高度重叠的“洗手”动作相关的上下文所混淆。
4.4.分析时间间隔
我们展示了有效编码时间间隔的重要性,以及它们与其他策略的差异。我们在EPIC-KITCHENS-100和EPIC-SOUNDS识别任务上进行了这项分析。
时间编码表示。为了展示TIM在所有数据集中编码时间间隔的方式,我们在图5中进行了说明。我们在同一个t-SNE投影上使用三种颜色映射来展示编码间隔的三个属性:持续时间、开始时间和结束时间。有趣的是,一维时间编码完美地捕捉了这三个属性,并且跨越了不同数据集。虽然不同数据集的编码存在差异,因为动作的位置和持续时间各不相同,但我们看到了学习的时间编码投影中的明显相似性。例如,在t-SNE图的x轴上,持续时间被完美地捕获,较低的值表示较长的时间间隔。

图5.所有数据集上时间编码I(·)的TSNE曲线图。在每个图中,我们使用彩色地图来表示时间间隔的持续时间(左)、开始时间(中)和结束时间(右)的编码。
区间查询注意力。在图6中,我们为EPIC-KITCHENS-100中的5个具有不同位置和尺度的独立查询绘制了两个注意力热图。我们从第二个Transformer编码器层提取注意力权重,因为这似乎与区间查询最相关。学习到的注意力明显适用于查询中包含的特征时间间隔。我们注意到两个随机选择窗口中的注意力具有相似性。

移动区间。为了展示TIM如何有效编码动作的时间间隔,我们将时间区间查询从正确的动作区间中移动-1.5秒到1.5秒,并评估这些调整对性能的影响。图7显示了结果。我们看到,随着查询区间远离正确的动作区间,视觉和音频的性能都逐渐下降。下降也是对称的,没有偏差。不出所料,在视频(-57.9%)和音频(-35.2%)中,短动作的性能在移动时显著下降,而在长动作中的下降则不那么明显(-14.5%和-11.2%)。我们在ArXiv附录中评估了调整时间区间大小的影响。

时间间隔编码。时间间隔多层感知机(MLP)对查询的间隔进行编码。在这里,我们将这种编码与传统的位置编码(包括正弦编码和学习的位置编码)进行了比较。我们还对时间间隔MLP的五种不同变体进行了实验,即:(i)中心——我们只编码区间的中心时间戳;(ii)单独添加/连接——我们分别编码区间的开始和结束时间,并将编码后的输出向量相加,或者沿着通道维度连接它们;(iii)区间添加/连接——我们在同一个向量中编码开始和结束时间,并将编码后的输出添加到输入序列中,或者与输入序列连接。我们在表7中展示了结果。在所有情况下,为了获得可比较的结果,最终编码的维度都是相同的。使用正弦编码或学习的位置编码时性能显著较差,因为它们无法捕获重叠动作的复杂性。仅编码时间区间的中心时性能也会下降。单独添加/连接是编码区间的替代方法(因此包括持续时间信息),其性能与区间编码方法相当。我们提出的将区间编码到MLP中的方法在视觉方面表现最佳,同时保持了强大的听觉性能。
5.结论
在本文中,我们提出将动作的时间间隔作为查询,输入到一个音视频转换器中,该转换器学习从时间间隔和未改变的周围环境上下文来识别动作。我们在特定模态的时间间隔和标签集上联合训练模型,使时间间隔机器(TIM)能够识别视觉和听觉模态中的多个事件。
TIM对时间间隔的位置和持续时间很敏感。这使得模型能够通过多尺度密集查询在动作检测上产生竞争性的结果。
读后总结
出发点:在包含音频和视频两种模态的长视频中,两种模态的事件时间长度和标签各不相同,以往对两种模态都使用相同的语义和时序标签是不合理的。
创新点1:提出了TIM查询机制,用于关注长视频中特定模态的区间。通过时间间隔机器,一方面统一划分了视频和音频的时间分割,另一方面可以将不同模态中感兴趣的时间间隔区域作为对应模态的查询,输入到处理视频和音频的transformer中进行自注意力机制计算(关注指定时间间隔和周围上下文),来聚合相关的时间上下文和跨模态关系,得到对应模态的动作预测结果。
创新点2:在分类损失的基础上,提出时间距离损失作为辅助损失,视频和音频模态的特征对经过时间距离回归头处理得到特征对之间的时间距离差,通过最小化预测的和真实的时间距离差,使得模型更好的学习模态之间的时间关系。















 8749
8749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









