






算法基础课
🐵 写题解的浏览器插件:acwing-helper (greasyfork.org)
目录:
一级标题 哪一讲
**二级标题 **题目,知识点(两个数字)
**三级标题 **小节 (三个数字)
四级标题 小节内容
每个小节对应一道题,小节标题下附上题目链接和题解代码,小节内容中写下分析过程、证明过程,时间复杂度分析、思维模式等笔记,或写下一些启发。
第一讲 基础算法
- 输入输出处理方法
C++ 中,数据量大用scanf速度更快,数据量小用cin
C++也可以使用cin.tie(0);和ios::sync_with_stdio(false);来提高cin的速度。副作用就是整段代码都无法使用scanf了
java 输入用buffer reader ,比scan 快十几倍
- 数组初始化:默认数组中的值为0
- 数组访问:C++没有内置的数组边界检查,如果访问超出数组边界的内存空间,是一种不安全的行为。
-
模版要在理解的前提下背熟,考试就是比拼的记忆力和毅力(自制力)!
1.1 快速排序
1.1.1 快速排序
#include <iostream>
using namespace std;
const int N = 100010;
int q[N];
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1]; // 左边界,下面不能取再递归i
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j); // 递归右边界j
quick_sort(q, j + 1, r);
}
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &q[i]);
quick_sort(q, 0, n - 1);
for (int i = 0; i < n; i ++ ) printf("%d ", q[i]);
return 0;
}
边界问题
- 若下面递归的两个区间是[l , j] 和 [j + 1 , r], x(枢轴元素)不能取a[r](右边界),因为j是右边界
// 右边界
int x = a[(l + r + 1) / 2];
int x = a[l + (r - l) + 1 / 2 ];
// 对应
quick_sort(q, l, i - 1);
quick_sort(q, i, r);
- 若下面递归的两个区间是[l , i - 1] 和 [i , r] , x(枢轴元素)不能取a[l](左边界),因为i是左边界
// 左边界
int x = a[(l + r) / 2];
int x = a[l + (r - l) / 2 ];
// 对应
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
- 反例:
2
0 1
总之:用i,不能取到左边界;用j,不能取到右边界。
时间复杂度
递归每层时间复杂度为n
共 l o g 2 n log_2n log2n层(使用树的高度来证明)
最坏时间复杂度为 O ( n 2 ) O(n^2) O(n2)
Tips
防止右值过大导致溢出
int x = a[l + (r - l) / 2 ]; //---> 有可能取到l(左边界)
快排是不稳定的,快排如何变稳定?
让快排里面所有数都不同,<a , i> 用二元组形式。
C++不能返回数组
// C++不能返回数组,只能返回指针,(定长)数组要在函数外面定义好了,再传进函数。
// return a[];
1.1.2 快速查找(基于快排)
#include <iostream>
using namespace std;
const int N = 1e6 + 10;
int n , k;
int a[N];
int quick_search(int l , int r , int k)
{
if(l == r) return a[l];
int i = l - 1 , j = r + 1;
int x = a[i + (j - i + 1) / 2];
while(i < j)
{
do i++ ; while(a[i] < x);
do j-- ; while(a[j] > x);
if(i < j) swap(a[i] , a[j]);
}
if(k <= i - 1) return quick_search(l , i - 1 , k); // 判断要找的数属于哪一个区间,递归查找哪一个区间即可
return quick_search(i , r , k);
}
int main()
{
scanf("%d%d" , &n , &k);
for(int i = 0 ; i<n ; i++) cin >> a[i];
cout << quick_search(0 , n - 1 , k - 1) << endl;
return 0;
}
时间复杂度
2n --> O ( n ) O(n) O(n)(因为相比快排剪枝了),证明如下图:
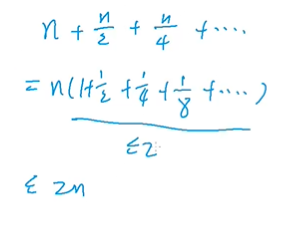
第一层需要处理区间大小为n,第二层需要处理的为n/2,第三层为n/4,以此类推
每次处理的区间大小都为一半。
1.2 归并排序
1.2.1 归并排序
#include <iostream>
using namespace std;
const int N = 10 + 10e6;
int n;
int q[N] , tmp[N];
void merge_sort(int q[] , int l , int r)
{
if(l >= r) return;
int mid = l + r >> 1;
merge_sort(q , l ,mid);
merge_sort(q , mid + 1 , r);
int i = l , j = mid + 1 , k = 0;
while (i <= mid && j <= r)
{
if (q[i] <= q[j]) tmp[k++] = q[i++];
else tmp[k++] = q[j++];
}
while (i <= mid) tmp[k++] = q[i++];
while (j <= r) tmp[k++] = q[j++];
for (int i = l , j = 0 ; i <= r ; i ++ ,j ++) q[i] = tmp[j];
}
int main()
{
scanf("%d" , &n);
for (int i = 0; i < n; i ++ ) scanf("%d" , &q[i]);
merge_sort(q , 0 , n - 1);
for (int i = 0; i < n; i ++ ) printf("%d " , q[i]);
return 0;
}
归并排序,它有两大核心操作.
一个是将数组一分为二,一个无序的数组成为两个数组.
另外一个操作就是,合二为一,将两个有序数组合并成为一个有序数组.
时间复杂度
O ( n l o g n ) O(nlogn) O(nlogn) 每层排序的时间复杂度是n,共logn层
类似于快排,只不过快排是排完再分区间(递归),归并是先分完(递归)再排。
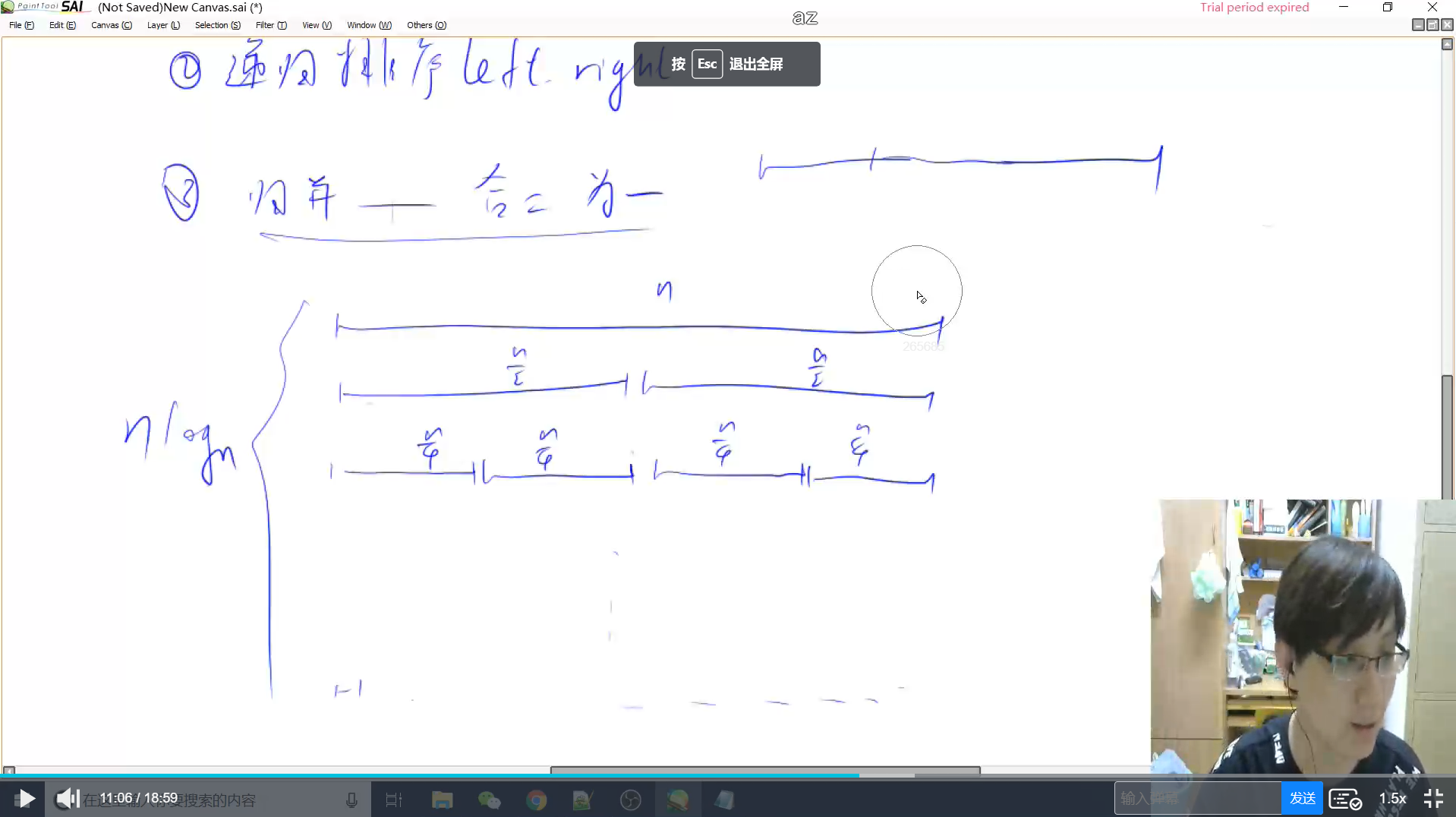
Tips
归并排序是稳定的
1.2.2 在归并排序中处理逆序数量
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 1e6 + 10;
int n;
int a[N] , tmp[N];
LL merge_sort(int l , int r){
if(l >= r) return 0;
int mid = l + r >> 1;
// res不能定义为int ,可能会超出范围,考虑极端情况 n + n-1 + n-2 + n-3 + ...... = n(n - 1) / 2
// 数据是十万,代入约为 5 x 1e9 超出int范围
LL res = merge_sort(l , mid) + merge_sort(mid + 1 , r);
int k = 0 , i = l , j = mid + 1; // 区间[i , mid] , [j , r]
while(i <= mid && j <= r)
{
if(a[i] <= a[j]) tmp[k++] = a[i++];
else
{
tmp[k++] = a[j++];
res += mid - i + 1;
}
}
while(i <= mid) tmp[k++] = a[i++];
while(j <= r) tmp[k++] = a[j++];
// 还是不能省tmp这个空间,因为要更新原数组,后面的递归才得以更新,不重复工作
for(i = l , j = 0; i <= r ; i++ , j++) a[i] = tmp[j];
return res;
}
int main()
{
scanf("%d" , &n);
for(int i = 0 ; i < n ; i++ ) scanf("%d" , &a[i]);
cout << merge_sort(0 , n - 1) << endl;
return 0;
}
思路:
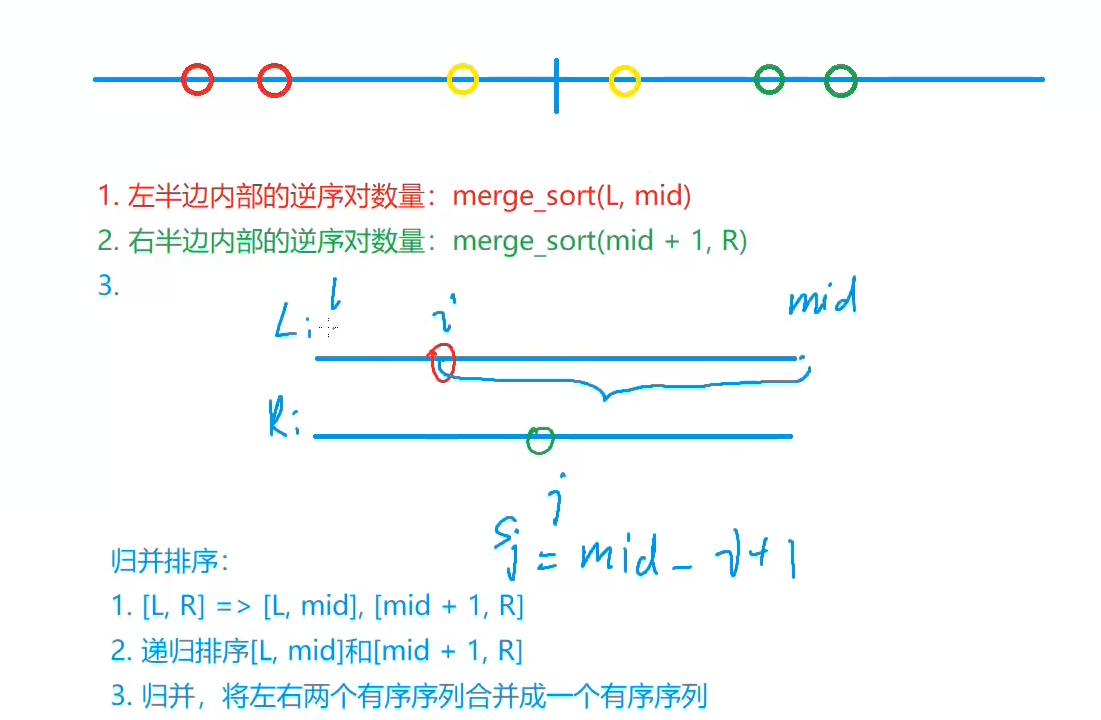
假定有把一个无序序列一分为二为两个有序序列,然后对其归并,设置双指针 i , j 分别指向左半区间和右半区间,即两个元素 a 和 b 分别位于左右两个区间产生的逆序对数量为 s0,元素 a 和 b 同时位于左半区间或右半区间产生的逆序对数量为s1和 s2。
那么,当指针 i 所指的元素 nums[i] 第一次大于指针 j 所指的元素 nums[j] 时,从此时起区间 [i,mid] 里的所有元素都一定大于指针 j 所指的元素 nums[j] ,区间长度 mid−i+1 (图中大括号所标示的区间)就是左半区间对指针 j 所指的元素 nums[j] 的逆序对数量,把所有单个元素的逆序对数量累加,就得到了该序列的逆序对数量s0。
由于序列左右半边的逆序对数量s1,s2可以递归求出,因此该序列的逆序对总数量为 s=s0+s1+s2。
因为每一趟归并排序(都是两个有序的序列合并)都可以求出当前序列的逆序对数量,所以归并排序可以用来求解整个序列逆序对数量。
- ⭐️ 归并的本质
递归到最后区间都是由一个数组成,然后再逐个合并,所有我认为只会出现第3中情况,即一个在左,一个在右
其实本质还是递归跟分治。
假设给你两个有序列的数组A,B,求那么显然,A和B的逆序数就都是0对不对,所以将A,B按照顺序接成一个新的数组的逆序数,是不是就等于求y总视频中所讲的黄色逆序数的个数?
本质就是 C由A,B构成,那么对C求某些特定的性质,可以等价于 对A求(红色)加上对B求(绿色),再加上将A,B整合之后产生的性质(黄色),然后又可以将A看作由更小的 E,F。而但数组不可以再划分的时候,即只要一个元素的时候,就是我们递归的尽头了。
所以归并的本质还是求黄色的逆序数,因为A红色的逆序数可以等于A的红色+黄色+绿色,而最底层的红色和绿色都为0,所以本质是求黄色。
- 为什么用归并排序可以边排序边计算?
因为算完排好序可以避免重复统计逆序数对,而且可以减少对比次数,降低时间复杂度。
我们注意到一个很重要的性质,左右半边的元素在各自任意调换顺序,是不影响第三步计数的,因此我们可以数完就给它排序。这么做的好处在于,如果序列是有序的,会让第三步计数很容易。
如果无序暴力数的话这一步是O(n^2)的。
比如序列是这样的
4 5 6 | 1 2 3
当你发现 4 比 3 大的时候,也就是说右边最大的元素都小于左边最小的元素,那么左边剩下的5和6都必然比右边的所有元素大,因此就可以不用数5和6的情形了,直接分别加上右半边的元素个数就可以了,这一步就降低到了O(n), 我们知道递归式 T(n) = 2T(n/2)+O(n) = O(nlogn)的,所以排序的成本是可以接受的,并且这一问题下,可以很自然地使用归并排序。
Tips
局部思考,适用于分治、递归类型算法
假设两个已经排好序的序列,思考如何求逆序。
更一般来说,只考虑每一个小递归区间对问题的处理方法。
因为类似于这种分治的算法,是递归的,在每一个小的区间上处理、解决问题,然后就可以递归到处理整个区间。
算法的特性、背后的思想决定了算法能解决什么题目
提问:
归并算法模板是用来解决哪一类的问题的?
换句话说就是,归并算法的运作本质是什么?为什么求逆序对的数量我会想到归并算法而不是其他算法?
归并算法和其他算法的区别在哪里?我觉得这才是我们应该关注的问题,否则遇到一个新的题目的话,我们明明会写归并算法,但是却不知道我们可以用归并算法来解决,学这个归并算法我觉得不能只会写模板或者只会求逆序对,然后换汤不换药来考结果还是不会,如果能搞清楚归并算法本质,这样下次我遇到类似的题目,分析之后我就能想起来用归并算法,知道归并算法能解决这一类的问题,我觉得才是把归并算法学明白了
回答:
(见上方⭐️归并的本质 )
归并排序的本质是分治,分治是一种思想,可以用分治的解决的问题可以尝试使用基于分治思想的算法来解决。
比如这道题,利用归并排序的局部有序来分治统计逆序对数量,而快排在递归的过程中只能保证局部中前面的数小于等于某个数,后面的数大于等于某个数,由于存在等于的情况,需要特殊处理,相较于归并排序步骤会多一些。归并只有将结果求出来后才能得到第i小的数,快排可以平均上省去一半时间,这是算法特性。
❓ 解决多维偏序问题,可以用归并思想(CDQ分治),降掉一个维度。
逆序对就是典型的二维偏序问题。
1.3 二分
1.3.1 整数二分
#include <iostream>
using namespace std;
const int N = 1e6 + 10;
int n , q;
int a[N];
int findLeftBound(int l , int r , int x) // 找左边界,右边的那个数
{
while(l < r)
{
int mid = l + (r - l) / 2;
if(a[mid] >= x) r = mid;
else l = mid + 1;
}
return l; // 输出l 或 r 都一样,因为while结束时,l = r
}
int findRightBound(int l , int r , int x) // 找右边界,最左边的那个数
{
while(l < r)
{
int mid = l + (r - l + 1) / 2;
if(a[mid] <= x) l = mid;
else r = mid - 1;
}
return l;
}
int main()
{
scanf("%d%d" , &n , & q);
for(int i = 0 ; i < n ; i++) scanf("%d" , &a[i]);
while(q--)
{
int k ;
scanf("%d" , &k);
int begin = findLeftBound(0 , n - 1 , k);
if(a[begin] != k) cout << "-1 -1" << endl;
else cout << begin << " " << findRightBound(begin , n - 1 , k) << endl;
}
return 0;
}
[注]:如果无解,模版1二分出来的是区间内从左到右第一个满足 c h e c k ( ) check() check() 的元素。
在本题中,就是右半区间左边第一个 >= x 的数。
二分的本质
单调 ⇒ \Rightarrow ⇒可二分,单调 ⇍ \nLeftarrow ⇍可二分
二分的本质并不是单调性,满足单调性的数组一定可以使用二分查找,但可以使用二分查找的数组不一定需要满足单调性
单调性不是二分的本质,太过于狭隘。
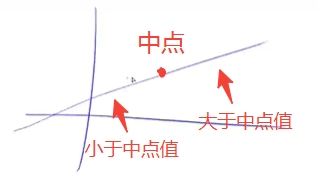
二分的本质是找到一个性质,该性质使得整个区间被一分为二(左半边满足,右半边不满足),如下图

整个区间被分为了红色部分和绿色部分,两个模版分别找的就是红色的边界和绿色的边界(图中两个箭头 ↓ \downarrow ↓处)。
找满足条件区间的边界
-
⬅️ 在满足 c h e c k ( ) check() check() 的区间找左边界点取 $mid = (l + r) / 2 $
此处 c h e c k ( m i d ) check(mid) check(mid) 函数用于判断 m i d mid mid 是否满足绿色区间:
-
若是,说明要找的左(红色)区间边界在区间 [ m i d , r ] [mid,r] [mid,r] 上,更新 $l = mid $ (注意此处更新区间包含 m i d mid mid,因为此时 m i d mid mid有可能是答案)
-
若不是,说明要找的左(红色)区间边界在区间 [ l , m i d − 1 ] [l,mid-1] [l,mid−1] 上,更新 r = m i d − 1 r=mid-1 r=mid−1
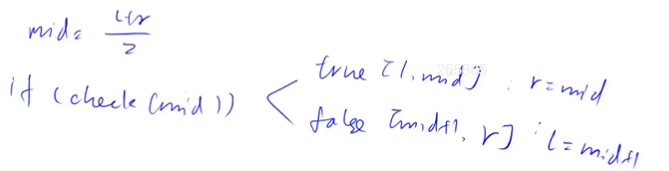
- ➡️ 在满足 c h e c k ( ) check() check() 的区间找右边界点同理,只是取 m i d = ( l + r + 1 ) / 2 mid=(l+r+1)/2 mid=(l+r+1)/2
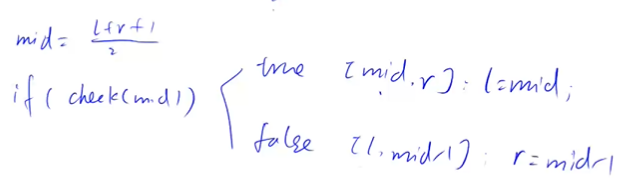
当我们将区间 [ l , r ] [l, r] [l,r] 划分成 [ l , m i d ] [l, mid] [l,mid] 和 [ m i d + 1 , r ] [mid + 1, r] [mid+1,r] 时,其更新操作是 r = m i d r = mid r=mid 或者 l = m i d + 1 l = mid + 1 l=mid+1 ;计算 m i d mid mid 时不需要加1。
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
return l;
}
当我们将区间 [ l , r ] [l, r] [l,r] 划分成 [ l , m i d − 1 ] [l, mid - 1] [l,mid−1] 和 [ m i d , r ] [mid, r] [mid,r] 时,其更新操作是 r = m i d − 1 r = mid - 1 r=mid−1 或者 l = m i d l = mid l=mid ;此时为了防止死循环,计算 m i d mid mid 时需要加1。
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1; // Why +1 ???
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
为什么更新区间为 l = m i d l=mid l=mid 时, m i d mid mid 要 + 1 +1 +1 ,即 m i d = ( l + r + 1 ) / 2 mid = (l+r+1)/2 mid=(l+r+1)/2 ?
反例: l = r − 1 l=r-1 l=r−1
假设不加1,即还是 $mid = (l + r) / 2 $
此时 m i d = ( 2 r − 1 ) / 2 = r − 1 / 2 mid = (2r-1)/2=r-1/2 mid=(2r−1)/2=r−1/2
因为C++中是下取整,所以 m i d = l mid=l mid=l
如果这时 c h e c k ( m i d ) check(mid) check(mid) 为 t r u e true true ,那么更新区间为 $ l = mid $ ,还是原区间,没有更新,就会陷入死循环
助记:男左女右(判断为true时) 男是一 所以加一 女是零所以不用加
Tips
c h e c k ( m i d ) check(mid) check(mid) 函数用于判断 m i d mid mid 是否满足性质
假设有一个总区间,经由我们的 check 函数判断后,可分成两部分,
这边以o作 true,…作 false 示意较好识别
如果我们的目标是下面这个v,那麽就必须使用模板 1
…vooooooooo
假设经由 check 划分后,整个区间的属性与目标v如下,则我们必须使用模板 2
oooooooov…
所以下次可以观察 check 属性再与模板1 or 2 互相搭配就不会写错啦
其实模板1和模板2本质上是根据代码来区分的,而不是应用场景。如果写完之后发现是l = mid,那么在计算mid时需要加上1,否则如果写完之后发现是r = mid,那么在计算mid时不能加1。
问题
Q: c h e c k ( ) check() check() 怎么选?有什么用?在其他情况的怎么选择 c h e c k ( ) check() check() ?
A:找能将区间分为两半的性质,比如数的范围这个题,要找oooooooox…,x的左边(包括他自己)可以定义为 < = x <=x <=x ,右边就可以定义为 > x >x >x ,所以 c h e c k ( m i d ) check(mid) check(mid) 就可以定义为判断 a [ m i d ] a[mid] a[mid] 是否 < = x <=x <=x ,如果为 t r u e true true (如下图)
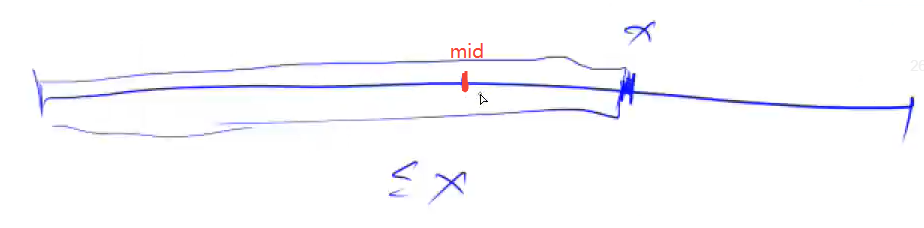
说明答案(要找的最左边那个x)在右边,就更新区间为 l = m i d l=mid l=mid .
然后因为是 $ l = mid $ 所以回头把 $ mid$ 加个1.
[注]:因为 m i d mid mid 满足 < = x <=x <=x 所以 m i d mid mid 本身有可能是 x x x ,换句话说,也就是有可能使我们找的答案(要找的最左边那个x),所以左区间 l l l 还是要包含 m i d mid mid 的.
1.3.2 浮点数二分
// 一般比题目要求的精度值多2
// mid^3不是mid的三次方,而表示异或
#include <iostream>
using namespace std;
int main()
{
double x;
cin >> x;
double l = -10000 , r = 10000; // l和r不能定义成 0 和 x ,反例0.001 , 有边界不能小于1
while(r - l > 1e-8)
{
double mid = (l + r) / 2;
if(mid * mid * mid >= x) r = mid;
else l = mid; // 浮点数不用考虑边界,所以不是mid+1
}
printf("%lf\n" , l);
return 0;
}
思路:
Tips
- 关于二分区间的选取:
区间不能取成0-x,当x=0.001时,三次方根是0.1,取0-x会找不到答案。直接取成-10000 ~ +10000,不管是什么x,答案都在这个范围内。
- 精度问题
这里使用 1e10-8,是因为题目要求保留小数点后6位,如果使用1e10-7, 那么这个因为四舍五入第八位到第七位,已经产生误差,输出六位时候误差会积累。使用1e-8,第八位由于四舍五入会有误差,但最后输出前六位时,第八位会被truncate掉,由于舍入只需要考虑后一位,此时第七位是准的,按六位输出就能保证结果准确。
1.4 高精度
1.4.1 高精度加法
#include <iostream>
#include <vector>
using namespace std;
vector<int> add(vector<int> &A , vector<int> &B)
{
vector<int> C;
int t = 0;
for(int i = 0 ; i < A.size() || i < B.size() ; i++)
{
if(i < A.size()) t += A[i];
if(i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10; //向下取整,不足10为0
}
if(t) C.push_back(1);
return C;
}
int main()
{
// 太大用string输入
string a,b;
vector<int> A,B;
cin >> a >> b;
// 用数组存起来,倒序存储,方便扩展
for(int i = a.size() - 1 ; i >=0 ; i--) A.push_back(a[i] - '0');
for(int i = b.size() - 1 ; i >=0 ; i--) B.push_back(b[i] - '0');
auto C = add(A , B);
for(int i = C.size() - 1 ; i >= 0 ; i--) printf("%d" , C[i]);
return 0;
}
数组倒着存方便进位,加到最后如果还有进位,可以不用移动那么多元素,下面是不用stl,使用数组实现(数组没有size()函数)
AcWing 791. 高精度加法C++数组实现 - AcWing
1.4.2 高精度减法
#include <iostream>
#include <vector>
using namespace std;
// A-B
vector<int> sub (vector<int> &A , vector<int> &B)
{
vector<int> C;
int t = 0;
for (int i = 0 ; i < A.size() ; i++) // 低位 -> 高位
{
t = A[i] - t; // 减去借位
if (i < B.size()) t -= B[i]; // 底下有数才相减,以免越界
C.push_back((t + 10) % 10);
if(t < 0) t = 1;
else t = 0;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
// A>=B?
bool cmp (vector<int> &A , vector<int> &B)
{
if (A.size() != B.size()) return A.size() > B.size();
for (int i = A.size() - 1 ; i >= 0 ; i--)
if (A[i] != B[i]) return A[i] > B[i] ;
return true;
}
int main()
{
string a,b;
vector<int> A,B;
cin >> a >> b;
for(int i = a.size() - 1 ; i >= 0 ; i--) A.push_back(a[i] - '0');
for(int i = b.size() - 1 ; i >= 0 ; i--) B.push_back(b[i] - '0');
/*
由于两个数都是正整数:所以先判断是否 A >= B ,是的话直接减,不是的话,变成 B - A,前面添负号
*/
if(cmp(A,B))
{
auto C = sub(A,B);
for(int i = C.size() - 1 ; i >= 0 ; i--) printf("%d" , C[i]);
}
else
{
auto C = sub(B,A);
printf("-");
for(int i = C.size() - 1 ; i >= 0 ; i--) printf("%d" , C[i]);
}
return 0;
}
使用t来实现借位和暂存数
for (int i = 0 ; i < A.size() ; i++) // 低位 -> 高位
{
t = A[i] - t; // 减去借位
if (i < B.size()) t -= B[i]; // 底下有数才相减,以免越界
C.push_back((t + 10) % 10);
if(t < 0) t = 1;
else t = 0;
}
1.4.3 高精度乘法
#include <iostream>
#include <vector>
using namespace std;
vector<int> mul(vector<int> &A , int b)
{
vector<int> C;
for(int i = 0 ,t = 0 ; i < A.size() || t ; i++) // 从前往后循环,当i没有循环完或者进位t没有处理完的时候,一直循环
{
if(i < A.size()) t = A[i] * b + t; // t += A[i] * b;
C.push_back(t % 10); // 类似于加法
t /= 10;
}
// 去除前导0
while(C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
int main()
{
string a;
int b;
vector<int> A;
cin >> a >> b;
for(int i = a.size() - 1 ; i >= 0 ; i--) A.push_back(a[i] - '0'); // ASCII码计算
vector C = mul(A,b);
for(int i = C.size() - 1; i >= 0 ; i--) printf("%d" , C[i]);
return 0;
}

此处是把B看做一个整体去跟A乘,$ C_i $ 是结果,$ t_i$ 是进位。
1.4.4 高精度除法
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> div(vector<int> A , int b , int &r)
{
vector<int> C;
for (int i = A.size() - 1 ; i >= 0 ; i--)
{
r = r * 10 + A[i];
C.push_back(r / b);
r %= b;
}
reverse(C.begin() , C.end()); // 高位在后进行的运算,商倒着存了
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
int main()
{
string a;
int b;
cin >> a >> b;
vector<int> A;
for (int i = a.size() - 1 ; i >= 0 ; i--) A.push_back(a[i] - '0');
int r = 0;
auto C = div(A , b , r);
for (int i = C.size() - 1 ; i >= 0 ; i --) printf("%d" , C[i]);
cout << endl << r << endl;
return 0;
}
(除法是从最高位开始算,但是为了加减乘除同一,所以除法也倒着存)
测试样例:(该样例可能会出现前导0,在考试时记得自己测一下样例)
10000000000
9
高精度总结
就是将原本人计算的方法进行抽象。
1.5 前缀和与差分
1.5.1 前缀和
#include <iostream>
using namespace std;
const int N = 100010;
int n , m;
int a[N],S[N];
int main()
{
scanf("%d%d" , &n , &m);
for(int i = 1 ; i <= n ; i++) scanf("%d" , &a[i]);
// 构前缀和数组
for(int i = 1 ; i <= n ; i++) S[i] = S[i - 1] + a[i];
int l , r;
while(m--)
{
scanf("%d%d" , &l , &r);
printf("%d\n" , S[r] - S[l - 1]); // S[0] = 0
}
return 0;
}
前缀和的作用
前缀和=数组前n项和,作用是可以利用 S r S_r Sr和 S l − 1 S_{l-1} Sl−1计算出任意一段数组的值。
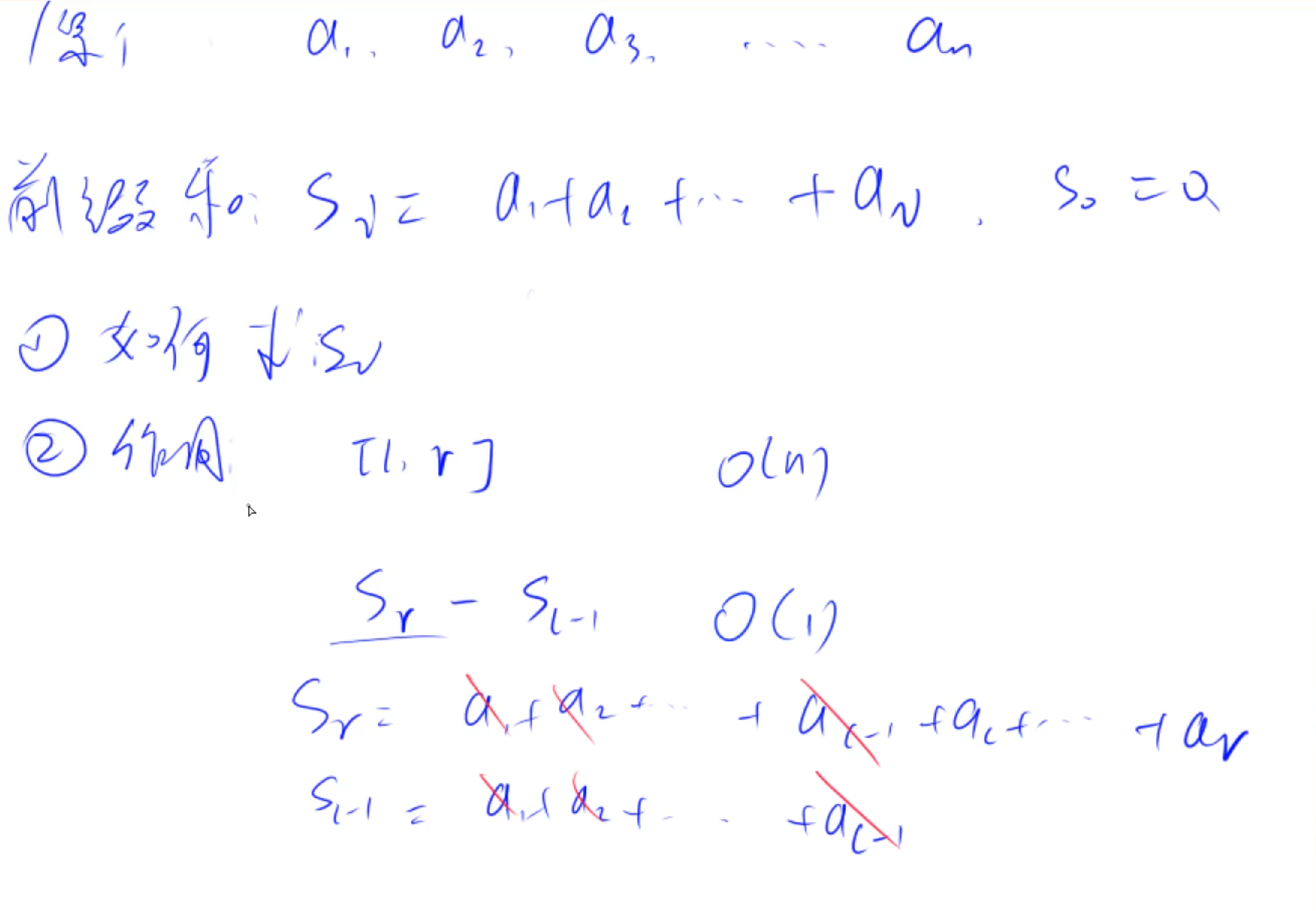
时间复杂度
预处理(构建 S[i]数组): O ( n ) O(n) O(n)
查询: O ( 1 ) O(1) O(1)
1.5.2 二维前缀和
#include <iostream>
using namespace std;
const int N = 1010;
int n , m , q ;
int a[N][N] , s[N][N]; // 全局初始化默认a[0][0],s[0][0] 为0
int main()
{
scanf("%d%d%d" , &n , &m , &q);
// 输入二维数组,从1开始比较好写
for(int i = 1 ; i <= n ; i++)
for(int j = 1 ; j <= m ; j++)
scanf("%d" , &a[i][j]);
// 构建前缀和数组
for(int i = 1 ; i <= n ; i++)
for(int j = 1 ; j <= m ; j++)
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j];
while(q--)
{
int x1 , y1 , x2 , y2;
scanf("%d%d%d%d" , &x1 , &y1 , &x2 , &y2);
printf("%d\n" , s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1]); // 边界上的也算
}
return 0;
}
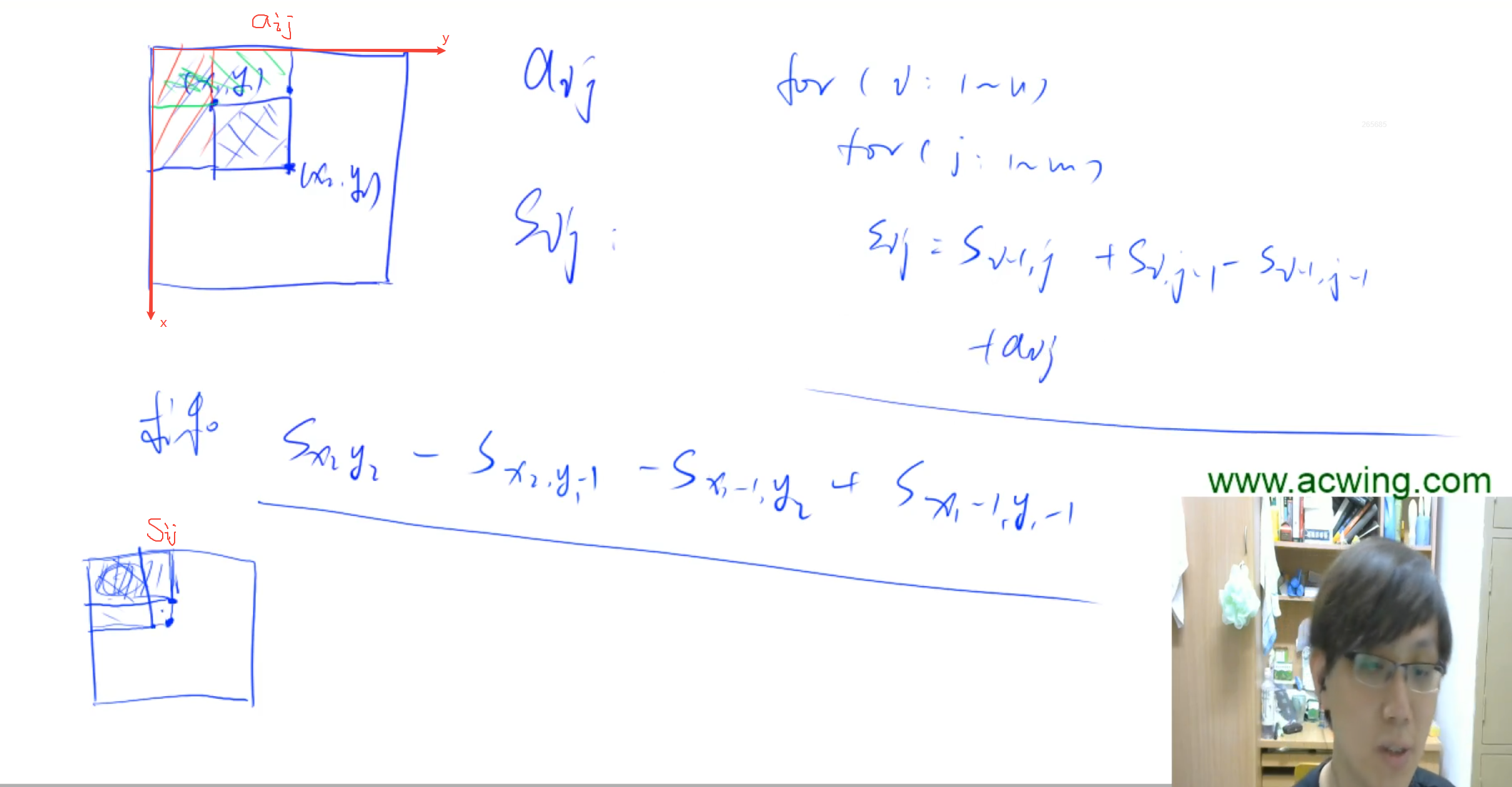
-
关注构建s [i] [j] 的方式,以及查询时求某个范围内数组的方式。
-
注意是范围内,边界上的也算(详细见公式)
1.5.3 差分
含义
-
假设有⼀个⼀维数组 a[1~ i] ,另⼀个⼀维数组为 b[1 ~ i](差分是前缀和的逆运算)
-
如果数组a是b的前缀和,那么b就是a的差分数组
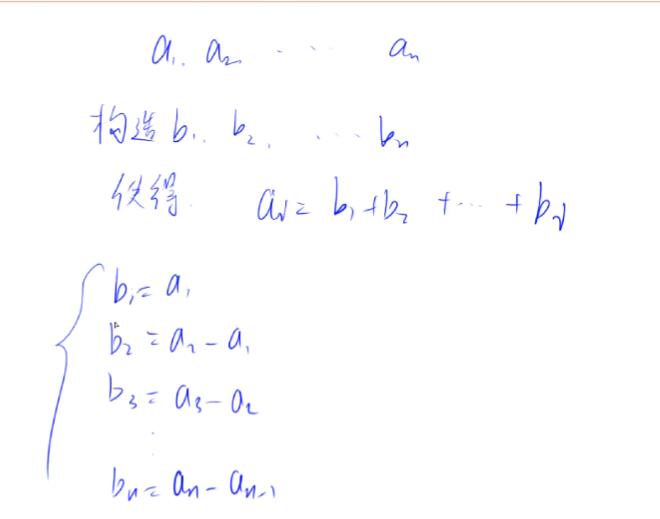
意义
让 a[ l, r ]的每⼀位加c这种操作,使用暴力解需要 O ( n ) O(n) O(n)时间,使用差分仅需 O ( 1 ) O(1) O(1)时间
从b数组转换到a数组(求前缀和数组)需要 o ( n ) o(n) o(n)时间。
核⼼步骤
当我们想要让 a[l, r ]的每⼀位加c,我们可以做如下操作:
b[l] += c // 因为a数组是b数组的前缀和,所以此操作会导致a[l]、a[l+1]、...,就是l之后的a数组元素都会加上c
b[r + 1] -= c //
这样对数组a造成的影响是:
- [1, l-1]没受影响
- [l, r]每⼀位加c
- [r + 1, n]没受影响
差分其实就这一个操作,a数组是作为输入的,构建差分数组就是在[1,1]区间插入a[1],在[2,2]区间插入a[2]…,所以差分不需考虑构造,只需要考虑如何更新。
#include <iostream>
using namespace std;
const int N = 100010;
int n , m ;
int a[N] , b[N]; // a是原数组,b是差分数组
// l到r区间内的数全部加上c
void insert(int l , int r , int c)
{
b[l] += c;
b[r + 1] -= c;
}
int main()
{
// 输入原数组
scanf("%d%d" , &n , &m);
for(int i = 1 ; i <= n ; i ++ ) scanf("%d" , &a[i]);
// 构建差分数组 在[1,1]区间插入a[1],在[2,2]区间插入a[2]....
for(int i = 1 ; i <= n ; i ++ ) insert(i , i, a[i]);
while(m--)
{
int l , r , c;
scanf("%d%d%d" , &l , &r ,&c);
insert(l , r , c);
}
//将b化为答案数组返回
for(int i = 1 ; i <= n ; i ++ ) b[i] += b[i - 1];
for(int i = 1 ; i <= n ; i ++ ) printf("%d " , b[i]);
return 0;
}
1.5.4 二维差分
核⼼操作
给以(x1, y1)为左上⻆,(x2,y2)为右下⻆的⼦矩阵中的所有数a[i,j],加上c,我们可以 做⼀下操作:
b[x1, y1] += c;
b[x1, y2 + 1] -= c;
b[x2 + 1, y1] -= c;
b[x2 + 1, y2 + 1] += c;
建议联系图来理解
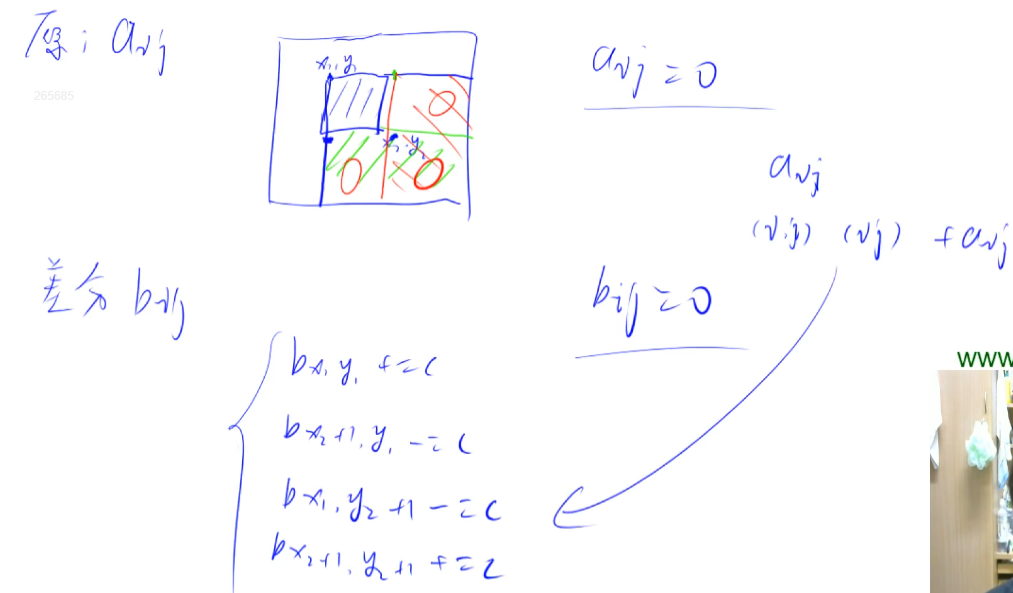
// 只要保证原矩阵是差分矩阵的前缀和
#include <iostream>
using namespace std;
const int N = 1010;
int a[N][N], b[N][N];
int n, m, q;
void insert(int x1 , int y1 ,int x2 , int y2 , int c)
{
b[x1][y1] += c;
b[x2 + 1][y1] -= c;
b[x1][y2 + 1] -= c;
b[x2 + 1][y2 + 1] += c;
}
int main()
{
scanf("%d%d%d" , &n , &m , &q);
for(int i = 1 ; i <= n ; i++)
for(int j = 1 ; j <= m ; j++)
scanf("%d" , &a[i][j]);
for(int i = 1 ; i <= n ; i++)
for(int j = 1 ; j <= m ; j++)
insert(i , j , i , j , a[i][j]); // 构建b数组
while(q--)
{
int x1 , y1 , x2 , y2 ,c;
// scanf("%d%d%d%d%d" ,&x1 , &y1, &x2, &y2, &c);
cin >> x1 >> y1 >> x2 >> y2 >> c;
insert(x1 , y1 , x2 , y2, c);
}
//--
for(int i = 1 ; i <= n ; i++)
for(int j = 1 ; j <= m ; j++)
a[i][j] = a[i -1][j] + a[i][j - 1] - a[i - 1][j - 1] + b[i][j]; // 求前缀和,也就是求更新后的a数组
for(int i = 1 ; i <= n ; i++)
{
for(int j = 1 ; j <= m ; j++) printf("%d " , a[i][j]);
puts("");
}
//--
/**
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
a[i][j] = a[i -1][j] + a[i][j - 1] - a[i - 1][j - 1] + b[i][j]; //更新原数组
cout << a[i][j];
if(i < n)
cout << endl;
**/
return 0;
}
// int puts(const char *str) 把一个字符串写入到标准输出 stdout,直到空字符,但不包括空字符。
// 换行符会被追加到输出中。
第二讲 数据结构

主要讲解使用数组来模拟链表等数据结构。
使用数组的好处就是避免了new结构体,new是非常耗时的,可能new完就超时了。
最后会讲解stl,但是stl也比用数组模拟慢。在平时编译器使用O2优化可以使得stl更快,但在竞赛的时候一般比赛方不会开
1.1 线性表
①单链表:用于构建邻接表,邻接表主要用于存储树和图。
②双链表:优化某些问题
静态链表:一个数组 e[ ] 存结点的值,一个数组 ne [ ] 存当前节点的下一个节点的序号。数组下标对应节点序号。
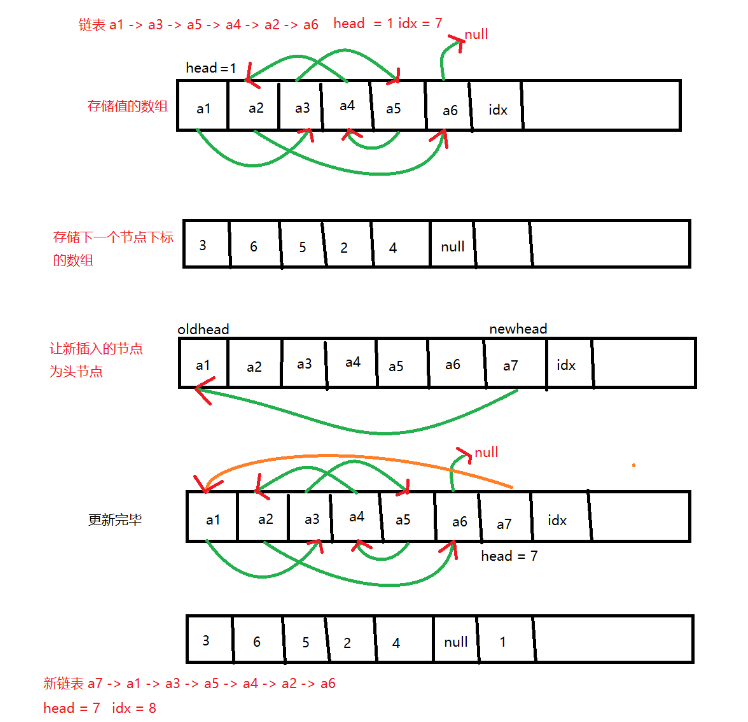
1.1.1 单链表
#include <iostream>
using namespace std;
const int N = 100010;
// head 表示头结点的下标
// e[i] 表示节点i的值
// ne[i] 表示节点i的next指针是多少
// idx 存储当前已经用到了哪个点
int head, e[N], ne[N], idx;
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 将x插到头结点
void add_to_head(int x)
{
e[idx] = x, ne[idx] = head, head = idx ++ ;
}
// 将x插到下标是k的点后面
void add(int k, int x)
{
e[idx] = x, ne[idx] = ne[k], ne[k] = idx ++ ;
}
// 将下标是k的点后面的点删掉
void remove(int k)
{
ne[k] = ne[ne[k]];
}
int main()
{
int m;
cin >> m;
init();
while (m -- )
{
int k, x;
char op;
cin >> op;
if (op == 'H')
{
cin >> x;
add_to_head(x);
}
else if (op == 'D')
{
cin >> k;
if (!k) head = ne[head]; // 判断是否删除的是头结点的下一个节点。头结点的下一个节点就是head(ne[head] = head),所以ne[ne[head]]=ne[head]
else remove(k - 1);
}
else
{
cin >> k >> x;
add(k - 1, x); // 第k个插入的点就是编号为k-1的点
}
}
for (int i = head; i != -1; i = ne[i]) cout << e[i] << ' ';
cout << endl;
return 0;
}
删除时不需要考虑内存泄露问题,不像是做工程,搞服务器,删除一个节点直接释放掉就行。
1.1.2 双链表
#include <iostream>
using namespace std;
const int N = 100010;
int m;
int e[N], l[N], r[N], idx;
// 在节点a的右边插入一个数x,如果想在左边插入一个点只需要调用insert(l[k],x)即可
void insert(int a, int x)
{
e[idx] = x;
l[idx] = a, r[idx] = r[a];
// l[r[a]] = idx, r[a] = idx ++ ;
r[a] = idx;
l[r[idx]] = idx;
idx ++ ;
}
// 删除节点a
void remove(int a)
{
l[r[a]] = l[a];
r[l[a]] = r[a];
}
int main()
{
cin >> m;
// 0是左端点,1是右端点
r[0] = 1, l[1] = 0;
idx = 2;
while (m -- )
{
string op;
cin >> op;
int k, x;
if (op == "L")
{
cin >> x;
insert(0, x);
}
else if (op == "R")
{
cin >> x;
insert(l[1], x);
}
else if (op == "D")
{
cin >> k;
remove(k + 1);
}
else if (op == "IL")
{
cin >> k >> x;
insert(l[k + 1], x);
}
else
{
cin >> k >> x;
insert(k + 1, x);
}
}
for (int i = r[0]; i != 1; i = r[i]) cout << e[i] << ' ';
cout << endl;
return 0;
}
使用结构体实现删除(右图上)对比使用数组静态链表实现删除(右),使用数组实现更加简单。


1.1.3 模拟栈
#include <iostream>
using namespace std;
const int N = 100010;
int m;
int stk[N], tt; // 此处stk[0]不存东西,tt是栈顶指针
int main()
{
cin >> m;
while (m -- )
{
string op;
int x;
cin >> op;
if (op == "push")
{
cin >> x;
stk[ ++ tt] = x;
}
else if (op == "pop") tt -- ;
else if (op == "empty") cout << (tt ? "NO" : "YES") << endl;
else cout << stk[tt] << endl;
}
return 0;
}
3302. 中缀表达式求值 (中缀转后缀+后缀求值)- AcWing题库
- 从左到右扫描中缀表达式。
- 如果遇到操作数(数字),则将其压入操作数栈。
- 如果遇到操作符(如 +, -, *, /),执行以下操作:
a. 如果操作符栈为空或栈顶元素为左括号 (,则将操作符压入操作符栈。
b. 如果新操作符的优先级高于操作符栈顶的操作符,也将新操作符压入操作符栈。
c. 如果新操作符的优先级小于或等于操作符栈顶的操作符,从操作数栈中弹出两个操作数,从操作符栈中弹出一个操作符,执行相应的计算,并将结果压入操作数栈。然后,将新操作符压入操作符栈。重复此过程,直到新操作符可以被压入操作符栈。 - 如果遇到左括号 (,将其压入操作符栈。
- 如果遇到右括号 ),重复执行以下操作,直到遇到左括号 (:
a. 从操作数栈中弹出两个操作数。
b. 从操作符栈中弹出一个操作符。
c. 执行相应的计算,并将结果压入操作数栈。
d. 在执行完这些操作后,弹出操作符栈顶的左括号 (。 - 当扫描完整个中缀表达式后,如果操作符栈仍然包含操作符,重复执行以下操作,直到操作符栈为空:
a. 从操作数栈中弹出两个操作数。
b. 从操作符栈中弹出一个操作符。
c. 执行相应的计算,并将结果压入操作数栈。 - 操作数栈中剩余的最后一个元素就是中缀表达式的计算结果。
#include<iostream>
#include<cstring>
#include<algorithm>
#include<stack>
#include<unordered_map>
using namespace std;
//操作数栈和运算符栈
stack<int>num;
stack<char>op;
//求值函数,使用末尾的运算符操作末尾的两个数
void eval()
{
auto b = num.top(); num.pop();//第二个操作数
auto a = num.top(); num.pop();//第一个操作数
auto c = op.top(); op.pop(); //运算符
int x; //结果计算(注意顺序)
if (c == '+')x = a + b;
else if (c == '-')x = a - b;
else if (c == '*')x = a * b;
else x = a / b;
num.push(x); //结果入栈
}
int main()
{
//优先级表(左键运算符,右键优先级数值越大优先级越高)
unordered_map<char, int>pr{ {'+',1},{'-',1},{'*',2},{'/',2} };
//读入表达式
string str;
cin >> str;
//从前往后扫描表达式
for (int i = 0; i < str.size(); i++)
{
auto c = str[i];
//扫描到数字,使用双指针法一直读入(读入多位数字,比如:250,个位十位百位)
if (isdigit(c))
{
//j表示扫描到数字的指针
int x = 0, j = i;
while (j < str.size() && isdigit(str[j]))
x = x * 10 + str[j++] - '0';
//更新i指针
i = j - 1;
//数字入栈
num.push(x);
}
//左括号直接入栈
else if (c == '(') op.push(c);
//右括号出现,从右往左计算栈中数据,直到遇见左括号
else if (c == ')')
{
//不断使用eval函数对末尾数字运算
while (op.top() != '(') eval();
//弹出左括号
op.pop();
}
//扫描到运算符
else
{
//如果栈顶运算符优先级较高,先操作栈顶元素再入栈
while (op.size() && pr[op.top()] >= pr[c]) eval();
//如果栈顶运算符优先级较低,直接入栈
op.push(c);
}
}
//把没有操作完的运算符从右往左操作一遍
while (op.size()) eval();
//栈顶元素为最终答案
cout << num.top() << endl;
return 0;
}
1.1.4 模拟队列
#include <iostream>
using namespace std;
const int N = 100010;
int m;
int q[N], hh, tt = -1;
int main()
{
cin >> m;
while (m -- )
{
string op;
int x;
cin >> op;
if (op == "push")
{
cin >> x;
q[ ++ tt] = x;
}
else if (op == "pop") hh ++ ;
else if (op == "empty") cout << (hh <= tt ? "NO" : "YES") << endl;
else cout << q[hh] << endl;
}
return 0;
}
hh <= tt 能取等号的主要原因是因为tt初值为 -1,hh初值为 0,相等时表示队列中只有一个元素,与栈的判断略有不同。
1.2 优化方法
1.2.1 单调栈
含义
栈中元素单调
核心步骤
a i a_i ai之前的元素都用栈来保存,在坐标系上看,栈中元素始终保持着一个单调上升的趋势。(如下图所示)
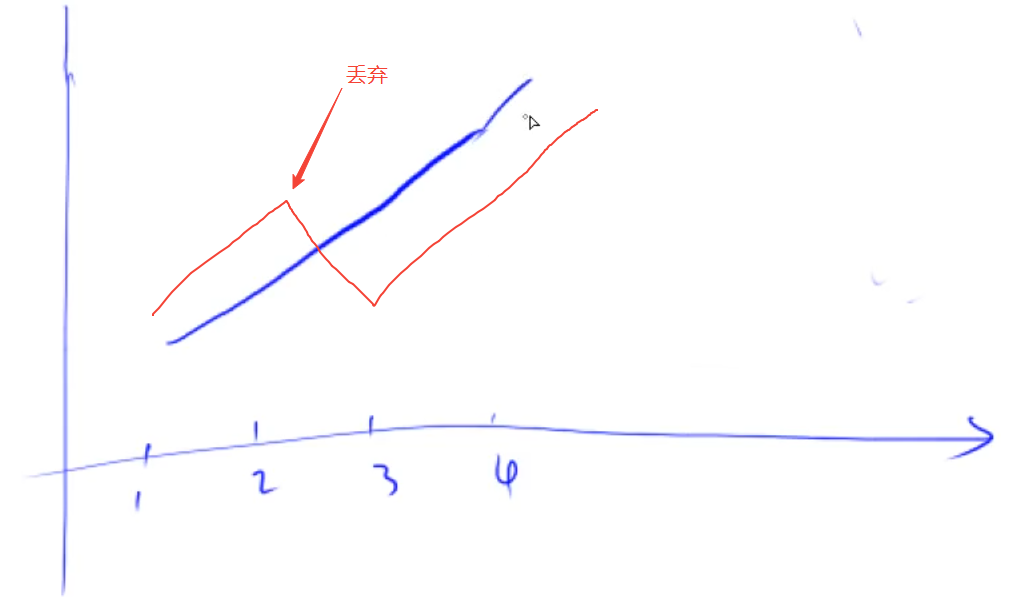
这时要寻找 a i a_i ai左边离 a i a_i ai最近且比 a i a_i ai小的数,就让栈顶元素与 a i a_i ai进行对比。
if (stk[tt] >= a_i)
tt--; // 弹出栈顶元素
else
return tt ? stk[tt] : -1; // 比a_i小且离a_i最近,如果不空的话返回,空的话返回-1
应用场景
- 求某个数左边离它最近且比它大的数。
(所有可以抽象为这种问题的都可以用单调栈来优化,比如leetcode买卖股票)
先想一下暴力做法是什么?
// 双指针遍历
for (int i = 0 ; i < n ; i++)
for (int j = i-1 ; j >= 0 ; j--)
if (a[i] > a[j])
cout << a[j] << endl;
break;
然后再挖掘一些性质,把没有用的删掉,使得时间复杂度可以降低。
如果存在 a 2 a_2 a2大于等于 a 3 a_3 a3,这时要寻找 a i a_i ai左边离 a i a_i ai最近且比 a i a_i ai小的数,那么 a 2 a_2 a2永远都不会被选到,因为有 a 3 a_3 a3, a 3 a_3 a3离 a i a_i ai更近而且更小。所以可以把 a 2 a_2 a2删掉。
#include <iostream>
using namespace std;
const int N = 100010;
int n;
int stk[N], tt;
int main()
{
cin.tie(0);
ios::sync_with_stdio(false); // 提高cin速度,加上这两句代码,可以做到跟scanf差不多
cin >> n;
while (n -- )
{
int x;
cin >> x;
while (tt && stk[tt] >= x) tt -- ;
auto res = tt ? stk[tt] : -1 ;
cout << res << " ";
stk[ ++ tt] = x;
}
return 0;
}
时间复杂度
由于每个元素只进栈一次和出栈一次,所以时间复杂度为 O ( n ) O(n) O(n),暴力算法 O ( n 2 ) O(n^2) O(n2)
1.2.2 单调队列
含义
队列中的元素保持单调
核心步骤
411 单调队列 【模板】滑动窗口最值_哔哩哔哩_bilibili

应用场景
- 求滑动窗口里的最大值和最小值。
(多重背包也可以用单调队列优化,因为多重背包中也可以找到滑动窗口求最值的过程,对该过程进行优化)
以求最小值举例,滑动窗口大小为3
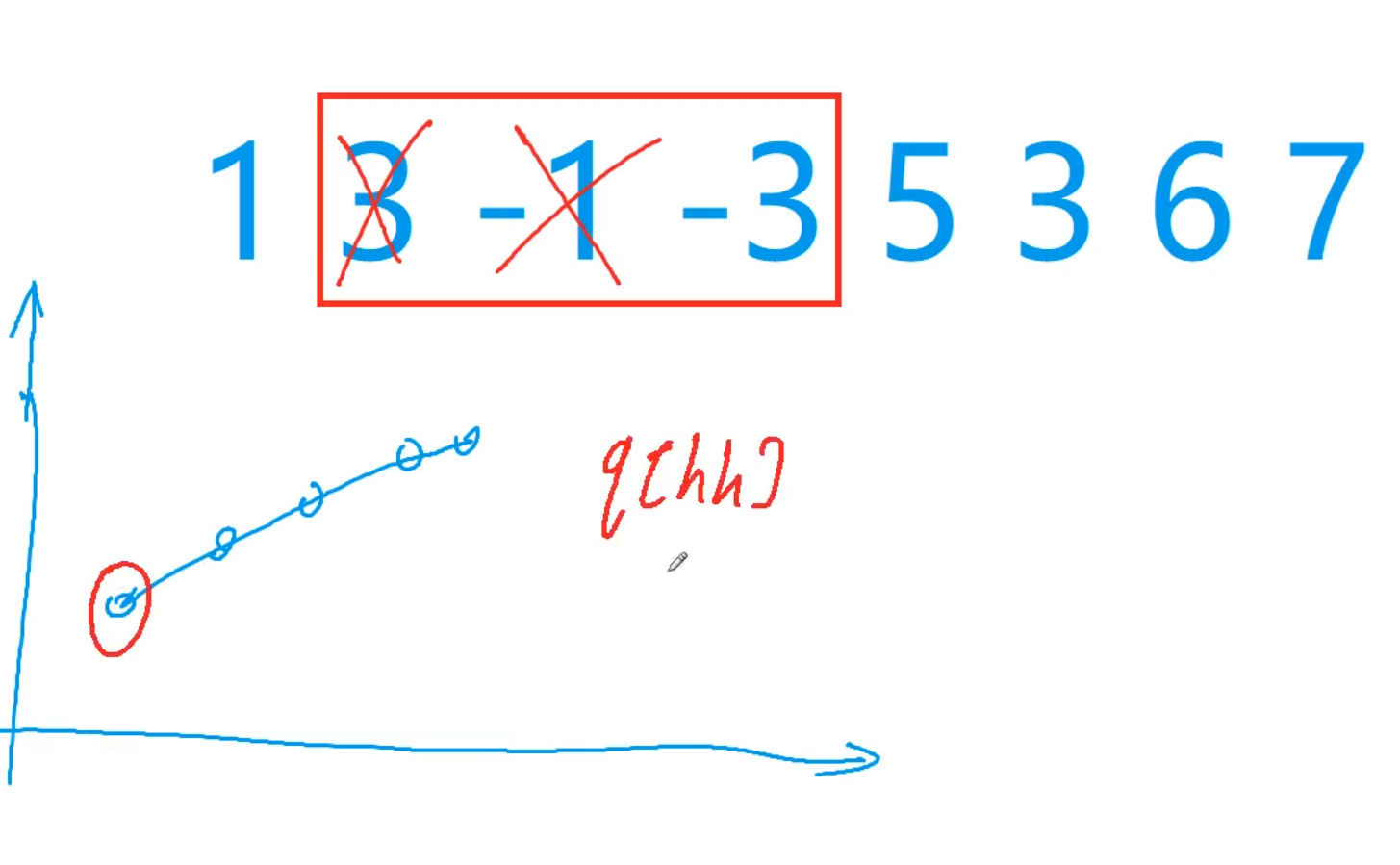
只要我-3在一天,3就永无出头之日。所以-3就可以删掉了,同理-1也可以删掉。
只要有这样的逆序对,就把大的点删掉,让队列中元素保持单调上升。
一个严格单调上升队列的最小值就是队头元素。
假设滑动窗口大小为k,暴力解时间复杂度为 O ( n k ) O(nk) O(nk)
#include <iostream>
using namespace std;
const int N = 1000010;
int a[N], q[N];
int main()
{
int n, k;
scanf("%d%d", &n, &k);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
int hh = 0, tt = -1; // head,tail 头,尾指针
for (int i = 0; i < n; i ++ )
{
if (hh <= tt && i - k + 1 > q[hh]) hh ++ ; // 判断队头是否已经滑出窗口,只有一次操作,写if,如果窗口一次移动两格或者更多,写while
while (hh <= tt && a[q[tt]] >= a[i]) tt -- ; // 维护最小值,越小越好,大的出队
q[ ++ tt] = i;
if (i >= k - 1) printf("%d ", a[q[hh]]);
}
puts("");
hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
if (hh <= tt && i - k + 1 > q[hh]) hh ++ ; // 判断队头是否已经滑出窗口
while (hh <= tt && a[q[tt]] <= a[i]) tt -- ; // 维护最大值,越大越好,小的出队
q[ ++ tt] = i;
if (i >= k - 1) printf("%d ", a[q[hh]]);
}
puts("");
return 0;
}
1.2.3 总结
-
先用 栈/队列 暴力模拟(暴力解)
-
看在 栈/队列 里面哪些元素是没有用的,将所有没有用的元素(永远不会作为答案输出)都删掉
-
剩下的元素是否有单调性
-
如果剩下的元素有单调性,就可以使用 单调栈 /单调队列 进行优化
-
要取极值,取端点即可,要取某个值,可以用二分(可以有各种各样的优化)
要维护最小值,则越小越好,大的出栈/队。
要维护最大值,则越大越好,小的出栈/队。
单调栈和单调队列区别:
- 单调栈存的是值,单调队列存的是下标
1.3 字符串相关算法
1.3.1 KMP 子串匹配算法
next数组含义
-
next记录的就是当前作为后缀末位的 j j j对应的前缀末位的位置。
-
j 回溯的位置 = 模式串的最长前后缀
而退一步的时候: j = next [ j ],表示 j 更新为 j 长的数组,即模式串中最长的公共前后缀,就是y总说的“退一步”了 -
当匹配失败,i不需要再回溯,只需要回溯 j 指针,那么模式串的指针 j 要回退多少,可以直接开始下一次匹配,而不用考虑前面已经匹配过的。
-
这个只与模版串(要匹配的子串)有关。
-
ne[j] 一定小于 j

那个交集就不用再匹配了
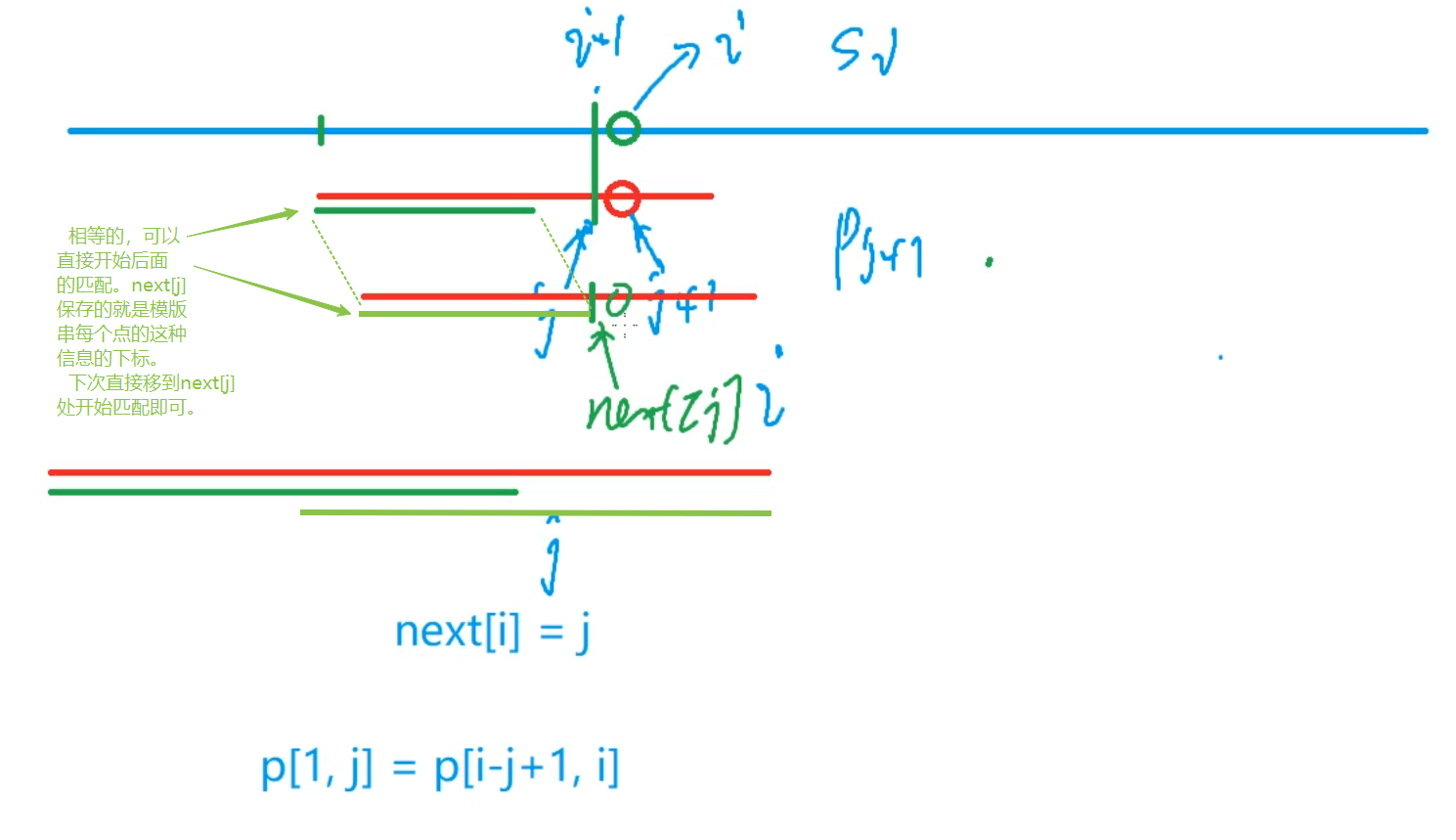
KMP匹配示例
数据结构 (一) 视频02:28:00

暴力解法:
for (int i = 1; i <= n; i ++ )
bool flag = true;
for (int j = 1; j <= m; j ++ )
if (s[i + j - 1] != p[j]) // 为什么是 i+j-1
flag=false;
break;
因为是字符串和字符串的比较,所以当你p的字符串中的j下标移动的时候,你s字符串的下标也要进行移动才行,至于i+j-1你最好看成i加上j-1就很好懂了

上图是思路,下面代码是按照主串和模式串从1开始匹配来写的。

上图为构建next数组的思路。
#include <iostream>
using namespace std;
const int N = 100010, M = 1000010;
int n, m;
int ne[N]; // 写next可能会和某些包冲突,直接写ne比较保险
char s[M], p[N];
int main()
{
cin >> n >> p + 1 >> m >> s + 1; // 注意下标从1开始匹配
for (int i = 2, j = 0; i <= n; i ++ ) // 求next数组,next[1]=0,所以直接从2开始,该过程跟匹配的过程类似
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; i ++ ) // KMP匹配过程,每次试图与s_i匹配的是p_{j+1}
{
while (j && s[i] != p[j + 1]) j = ne[j]; // 如果j没有退回到起点而且不匹配时
if (s[i] == p[j + 1]) j ++ ;
if (j == n)
{
printf("%d ", i - n); // 题目下标从0开始,所以i-n+1 -1 = i-n
j = ne[j];
}
}
return 0;
}
时间复杂度
O ( m + n ) O(m+n) O(m+n)
无论如何回溯,模式串整体都是向前移的,只要模式串移到主串尾部,算法就结束了。
KMP一次比较只会产生两种结果:
- 匹配成功主串的指针向前移动
- 匹配失败模式串整体向前移动
前面的移动必为n次,后面的移动最多n次,所以最大时间复杂度为 2 n 2n 2n
同理可得,next数组构建的最大时间复杂度为 2 m 2m 2m
【喵的算法课】KMP算法【7期】_哔哩哔哩_bilibili 有leetcode专属会员优惠
一个人能能走的多远不在于他在顺境时能走的多快,而在于他在逆境时多久能找到曾经的自己。
————KMP
第三讲 搜索与图论
深度优先搜索(DFS)
回溯、剪枝
广度优先遍历(BFS)
对比:
| 搜索方式 | 所使用数据结构 | 空间复杂度 | 最短路性质 |
|---|---|---|---|
| DFS | 栈 | O(h) | 无最短路 |
| BFS | 队列 | O(2h) | 最短路 |















 1799
1799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









