






1 CUDA学习资料合集
2 GPU概念介绍
《GPU的硬件结构与执行原理 —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
2.1 内存模型
2.1.1 Bank介绍
《GPU硬件结构之bank —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化》
3 算子优化
3.1 Conv
3.1.1 Img2col:卷积优化算法
博文《基于OneFlow实现Unfold、Fold算子》(以下简称为“《Fold优化》”)
《基于OneFlow实现Unfold、Fold算子》:理解img2col
3.1.2 Unfold & Fold
《基于OneFlow实现Unfold、Fold算子》:Unfold、Fold算子是卷积优化的基础操作
为什么这里out在索引时设计成6维的方式来进行操作呢?
在阅读《Fold优化》时,我们发现out采用6维的形式来进行操作,
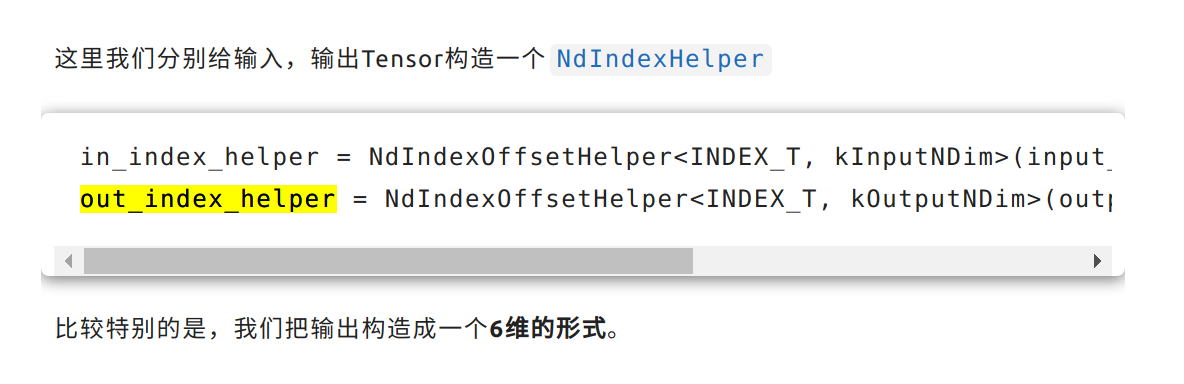
这样是为了CUDA编程时,索引可以直接对应上去,这样代码写作起来会更加简单;
3.2 Norm
3.2.2 LayerNorm
3.3 Elementwise operator
《高效、易用、可拓展我全都要:OneFlow CUDA Elementwise模板库的设计优化思路》
3.4 Softmax
《如何实现一个高效的 Softmax CUDA kernel?——OneFlow 性能优化分享》
(1)OneFlow为什么在Softmax实现时会使用ReduceMax操作呢?
这个问题的来源是这样的,博文《如何实现一个高效的 Softmax CUDA kernel?——OneFlow 性能优化分享》(以下简称为“《Softmax优化》”)在描述Softmax的CUDA实现时表示使用了ReduceMax操作,(也就是求某个维度上的最大值),但是根据Softmax的公式,这个操作在数学上其实是没有必要的,那为什么OneFlow会在CUDA实现时使用ReduceMax操作呢?
关于这一点,我们请教了晓雨哥,
【晓雨哥】:
应该是防溢出吧。
于是我们可以知道,先进行ReduceMax操作的目的是为了减去最大值,从而减小每个元素的绝对值,防止指数操作可能产生的数值溢出。
3.5 Dim transformation
《如何实现比PyTorch快6倍的Permute/Transpose算子?》
4 性能优化方法
4.1 CUDA Kernel中 grid_size 和 block_size 的设置优化
《如何设置CUDA Kernel中的grid_size和block_size?》
4.2 访存优化
《OneFlow GPU性能优化方法一:减少全局内存的访问 —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
4.2.1 Kernel fusion:核函数融合,一次访存,多次计算
(1)Element-wise kernel fusion
《1. Element-wise kernel fusion —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
(2)借助 shared memory 合并带有Reduce计算的Kernel
《2. 借助shared memory合并带有Reduce计算的Kernel —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
(3)使用bitset优化mask计算
《3. 减少实际需要的访存大小(以ReLU为例) —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
4.1.1 Memory access merging:内存访问合并
《OneFlow GPU性能优化方法二:确保全局内存访问合并 —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
以 bitset mask 生成为例讲解访存合并
《如何生成这个 bitset mask 加速Kernel的访存 —— 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化 》
4.2 计算优化
《OneFlow GPU性能优化方法三:优化Kernel计算量 》















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









