






目录
前言
如今大模型训练如火如荼,数据采集与数据质量控制对模型AI能力至关重要。无论是构建垂直领域知识大模型、训练代码模型(Code LLM),还是打造AI智能体(Agent),都离不开高质量、合规且规模化的数据作为支撑,只有在坚实的数据基础之上,模型才能展现真正的智能与价值。
文中我盘点了10个最适合模型训练的顶级AI数据采集代理,不仅对代理能力进行各维度对比,还结合企业级案例,重点解析亮数据(Bright Data)、Oxylabs、ThorData 在大规模采集、合规与技术上的系统性优势,并提供实操级代理爬虫操作指引,构建一体化训练数据采集体系。
一、十大AI数据采集代理
Bright Data
Bright Data 可以说是企业大规模采集与合规的标杆,覆盖住宅、移动、数据中心、ISP 四大网络类型,IP 池规模全球领先。工具链也十分丰富,包括针对复杂页面的 Web Unlocker、数据集市场、网页抓取 API、网页MCP服务,搜索引擎爬虫SERP等等,遵守 GDPR、CCPA 和 SEC 等法规,并设立专门的隐私中心负责用户赋能,不论对于个人还是企业使用,都可作为首选。
ScraperAPI
ScraperAPI, 开箱即用的“反封一体化”代理,提供 IP 轮换、头信息/指纹管理、Captcha/反爬自动化。以 API 方式快速接入;对工程资源少的团队非常友好。中小团队快速上线,PoC/中等规模项目的效率利器。

Oxylabs
Oxylabs覆盖住宅/移动/数据中心/ISP,高质量 IP 与出色清洗,有力的反封策略、稳定的高并发支持,提供 Scraper API 与 AI 驱动的自动重试与解封策略,适用于对稳定性与高成功率要求极高的企业。
NetNut
NetNut以稳定性著称,黏性会话表现好,适合需要“长连接”会话保持的任务。路由架构对延迟优化较好。适用于需要一致性会话上下文(登录态、购物车、分页浏览)的采集。

ThorData
ThorData 提供代理、采集调度、数据质量校验、以及可扩展管道。更偏“数据平台”思路,适配工程化团队与 MLOps/LLMOps 场景,需要把代理嵌入数据流水线,强调质量监控、元数据管理与版本化。
Proxyrack
Proxyrack可以说是住宅/数据中心/混合方案,价格策略灵活。支持不同认证方式、一定规模的并发与轮换策略。适用于预算敏感但需要多类型网络覆盖的项目。

Shifter
Shifter 以住宅网络为核心,轮换与黏性会话可选。定价相对亲民,API 接口较简洁。适用于轻到中等规模电商/本地化/地图数据任务。

Decodo
Decodo强调 AI Orchestrator 与无头浏览器编排,支持动态页面与登录态操作。集成数据清洗/标注接口,适合直接服务模型训练。适用于需要“数据到可用样本”的短链路产线;代码模型/文本模型混合样本构建。
Proxy-Cheap
Proxy-Cheap性价比高、入门门槛低,适合启动期或非关键任务。覆盖常见协议与认证方式,适用于成本敏感、对极致成功率要求不高的长尾采集。
StormProxies
StormProxies主打易用的轮换代理,API 简单在基础性能与并发上可满足入门或小规模任务,适用于原型验证、短周期采集。

下表是我根据网络类型、规模/并发、价格、工具链等方面,将上面10大代理进行对比。
| 供应商 | 网络类型 | 规模/并发 | 价格区间 | 协议 | 工具链/SDK | 典型亮点 |
| Bright Data | 住宅/移动/数据中心/ISP | 超大池/企业级并发 | 注册送2$, 低 | HTTP(S)/SOCKS5 | 抓取器、Web Unlocker、Data Sets、SDK | 企业大规模采集、合规、技术强 |
| ScraperAPI | 聚合代理(轮换) | 中-大/高并发 | 中 | HTTP(S) | 一体化 API/SDK | “反封即服务” |
| Oxylabs | 住宅/移动/数据中心/ISP | 超大池/企业级并发 | webScraper API 赠送1$ | HTTP(S)/SOCKS5 | Scraper API、SDK | 高成功率与反封 |
| NetNut | 住宅/数据中心/ISP | 大池/高并发 | 中 | HTTP(S)/SOCKS5 | SDK/管理台 | 低延迟、会话稳定 |
| ThorData | 住宅/数据中心 | 中-大/可扩展 | 中-高 | HTTP(S) | 采集编排与数据质量工具 | 数据工程友好 |
| Proxyrack | 住宅/数据中心 | 中-大/可扩展 | 低-中 | HTTP(S)/SOCKS5 | SDK/控制台 | 性价比稳健 |
| Shifter | 住宅 | 中/中并发 | 中 | HTTP(S) | 控制台/API | 老牌住宅代理 |
| Decodo | 住宅/数据中心 | 中/可扩展 | 中 | HTTP(S) | AI Orchestrator、无头浏览器 | 从采集到样本更短链路 |
| Proxy-Cheap | 住宅/数据中心 | 中/可扩展 | 低 | HTTP(S)/SOCKS5 | 控制台/API | 预算友好 |
| StormProxies | 住宅/数据中心 | 小-中/中并发 | 低 | HTTP(S) | API | 简洁轻量 |
二、AI数据采集代理如何选择?
在AI训练、数据挖掘、市场研究等场景中,企业常常需要高效、稳定、合规的数据采集代理服务。选择合适的代理,需要综合考虑以下几个核心维度:
- 合规与合法性
- 是否有明确的数据采集合规政策
- 是否适配 GDPR、CCPA 等隐私与数据法规
- 规模与稳定性
- 节点数量是否足够大
- 网络稳定性与速度是否满足大规模任务
- 技术与功能
- 是否支持住宅IP、移动IP、数据中心IP
- 是否有智能调度、Captcha绕过、Web解封等技术
- API/SDK 是否便捷易用
- 成本与灵活性
- 价格模型是否灵活(流量计费、端口计费)
- 是否支持按需扩展
选择AI数据采集代理时,需要在 规模、合规性、技术能力与成本 之间找到平衡:如 Bright Data(亮数据) 与 Oxylabs 更适合大规模、合规性要求高的企业级任务。
NetNut 适合电商与广告验证等高速度场景,ScraperAPI 与 Decodo 提供便捷的API与浏览器编排,降低工程负担;而 Proxyrack、Proxy-Cheap、Proxy-Seller、StormProxies、Shifter 等则以灵活套餐或低价满足中小团队和入门级需求,ThorData 则面向工程化团队,强调扩展性与性价比。
小结
企业级/大规模AI采集 → Bright Data、Oxylabs(亮数据更突出合规和企业服务)
中小企业/开发者 → NetNut、ScraperAPI
预算敏感/小型项目 → Proxyrack、Proxy-Cheap、StormProxies
如果你是做 AI模型训练、大规模市场情报、跨国电商数据采集 的企业,首选还是 Bright Data(亮数据) —— 合规、规模、技术全面领先。
三、具体案例
这里我演示Bright Data、Oxylabs、ThorData三款代理进行爬取数据,分析下一爬取过程。
1、Bright Data
Bright Data对于新用户使用非常友好,赠送两刀的免费额度,可以体验任意一款代理,这让我感觉非常nice,其Web Scraper API 支持120多个常用的网站,比如:Amazon、TicTok、FaceBook、X等等,还提供由数据集,直接定制。另外最近还新出了MCP服务,让我在开发工具或者Agent中就可以直接爬取到我想要的数据。
新用户免费获取额度
注册Bright Data官方账号之后,登录到用户控制面板,在支付菜单可以看到平台立即赠送的免费额度,接下来我们就可以体验平台上的任意代理。
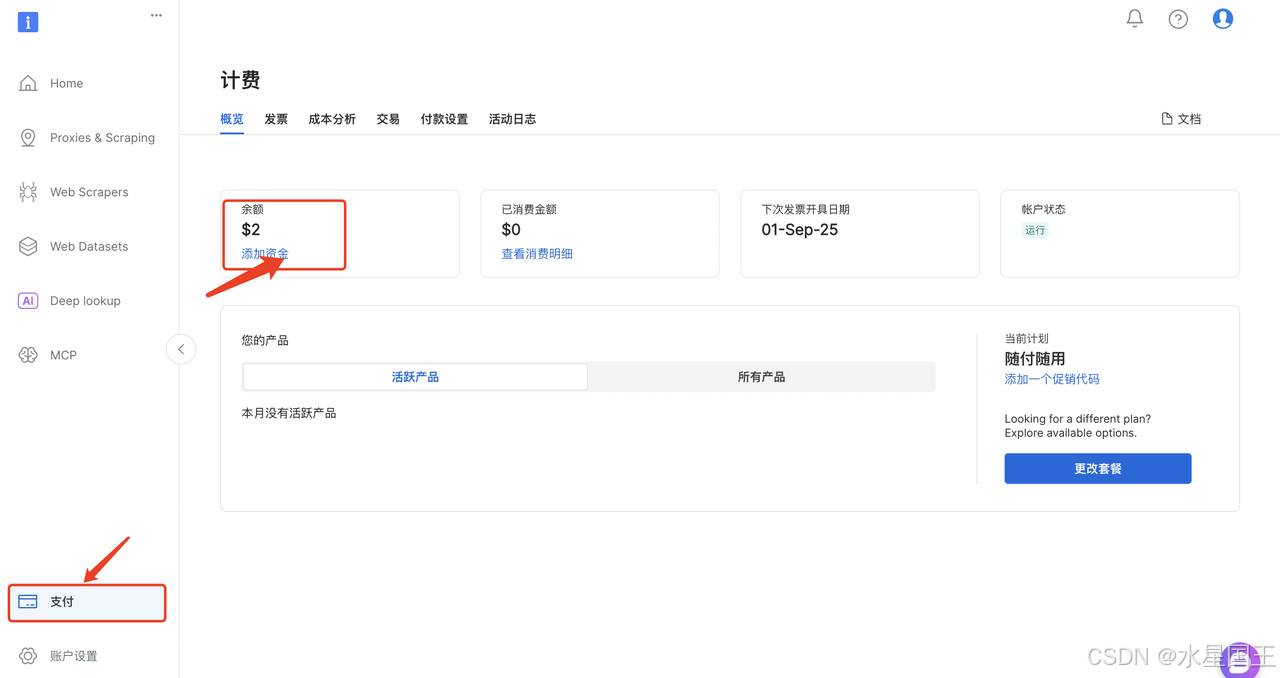
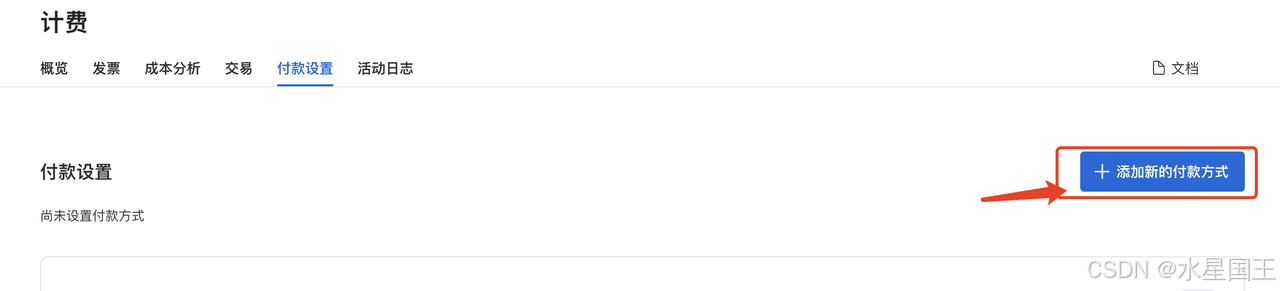
当然可以添加支付方式,这里我选择支付宝
基础代理
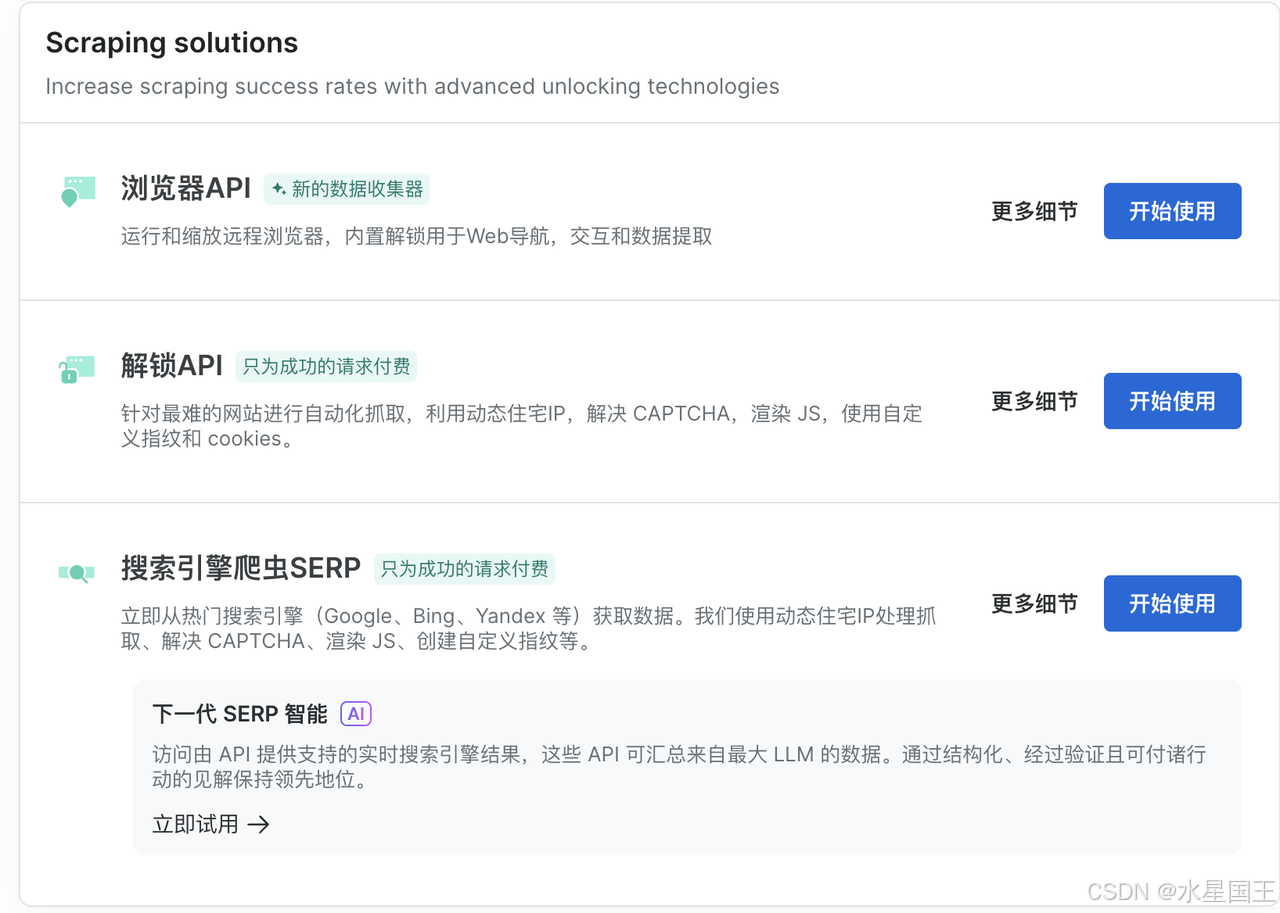
Bright Data通过浏览器 API、解锁 API 和搜索引擎爬虫 SERP 来提升复杂网站的数据采集成功率,并提供动态住宅 IP、数据中心 IP、移动代理和 ISP 静态住宅 IP 等多种代理网络,覆盖全球 195+ 国家/地区,以确保高效、稳定和可靠的数据获取。
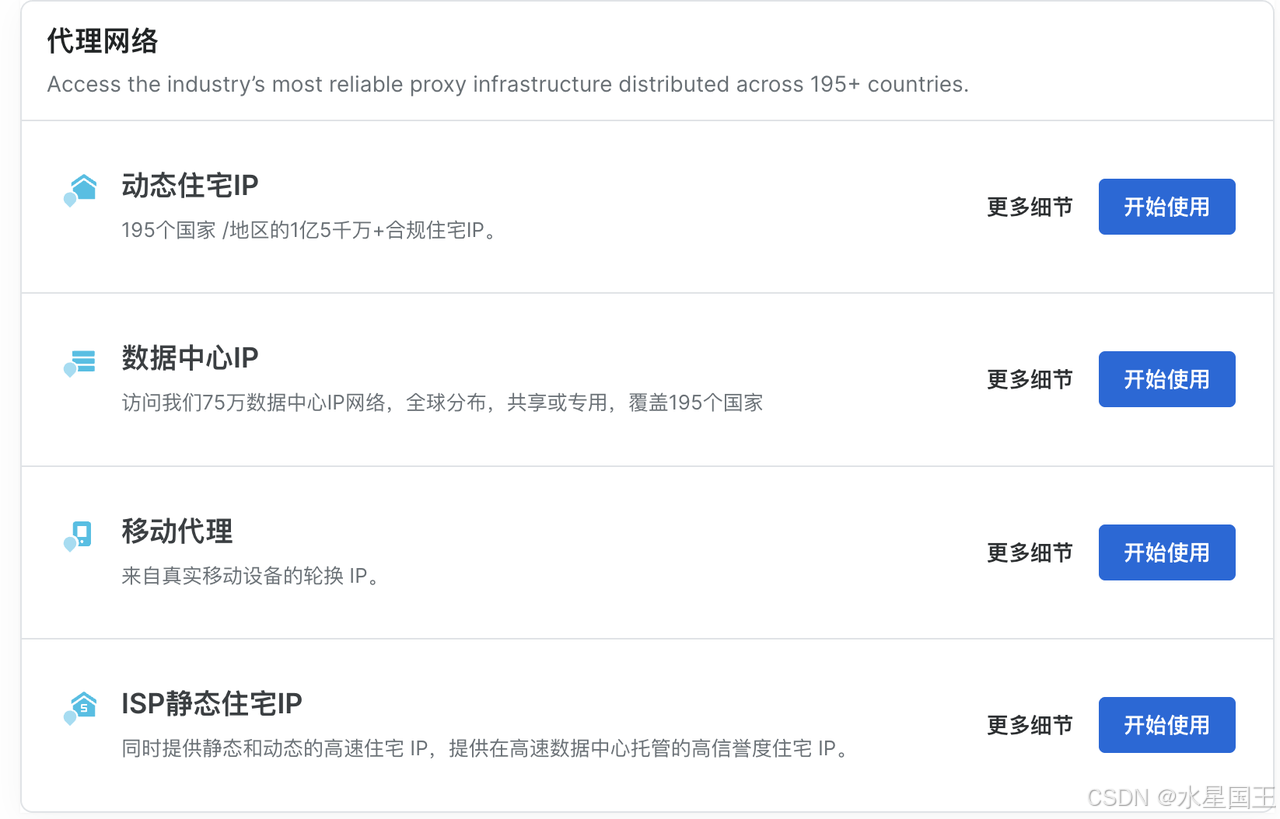
网页抓取API,无代码抓取数据
选择左侧菜单中的Web Scrapers,可以看到爬虫市场分类很多,API种类也是非常多,超120+种,这里我选择电子商务类目中的amazon.com
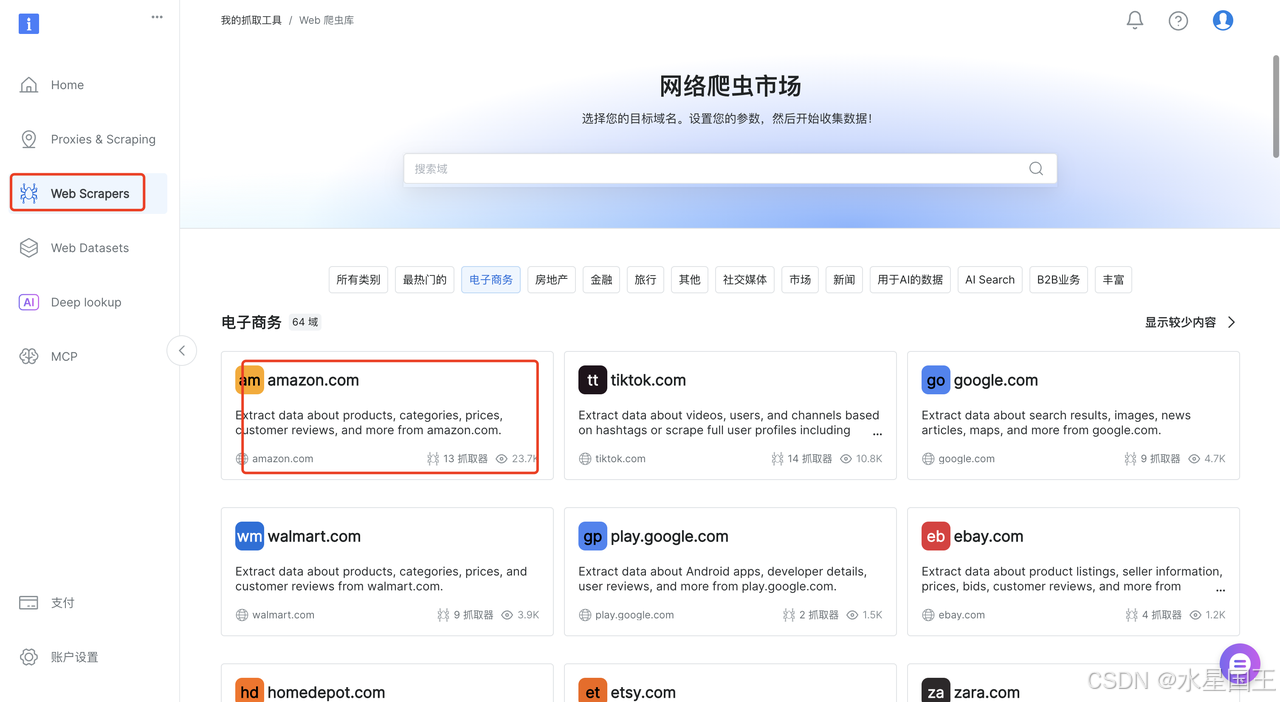
随后可以看到amazon的爬虫API有13种
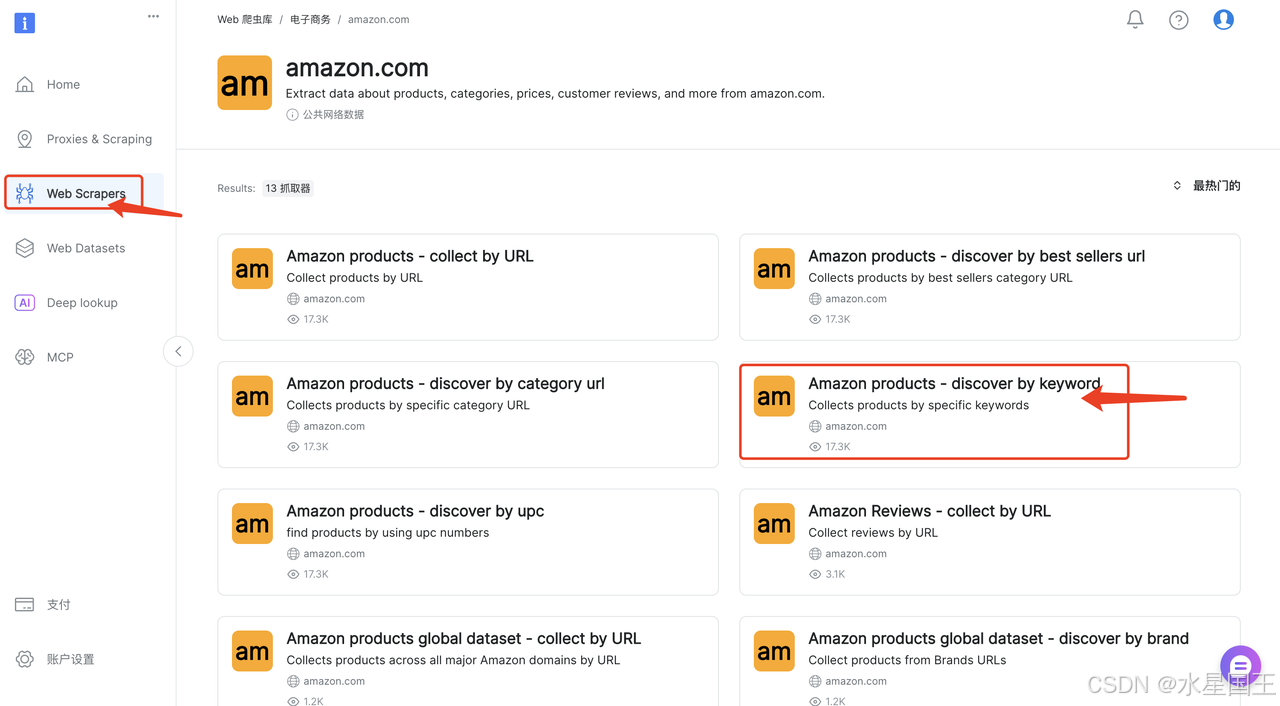
点击Amazon products-discover by keyword,可以看到两种方式抓取,左边需要手动执行脚本,右边直接无代码抓取,这里我选择无代码抓取。
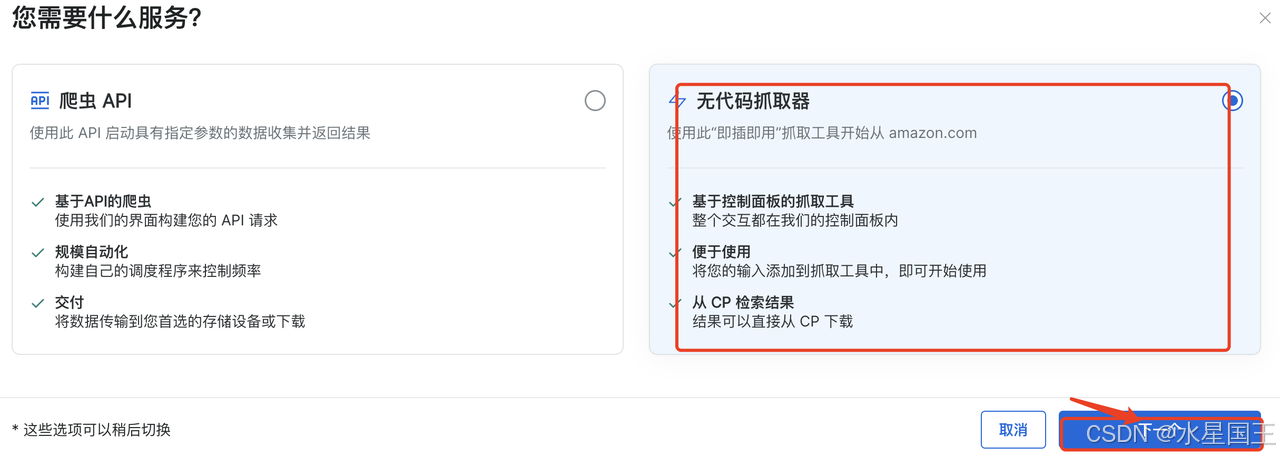
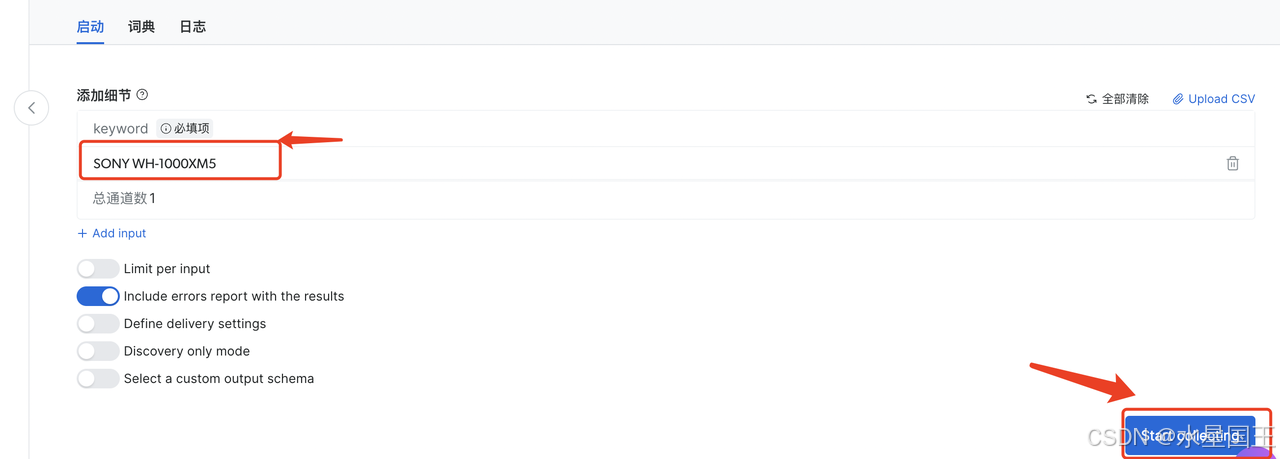
输入关键字:SONY WH-1000XM5,点击下面的“Start collecting”开始抓取
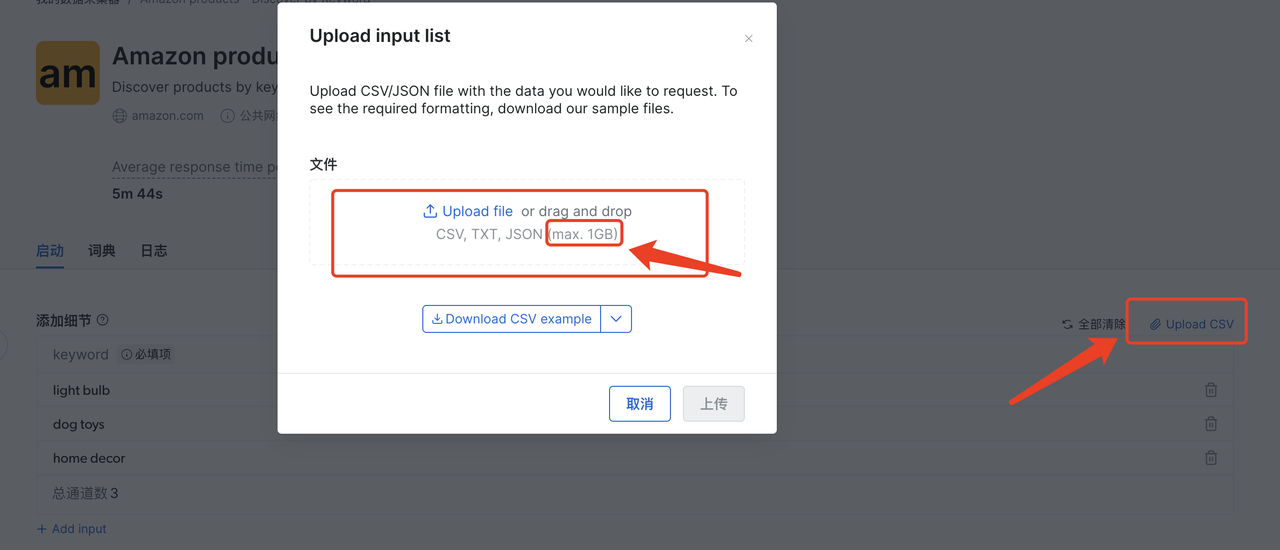
另外也可以直接上传CSV文件,直接导入数据,最大可以导入1G的数据,非常企业级大规模爬虫
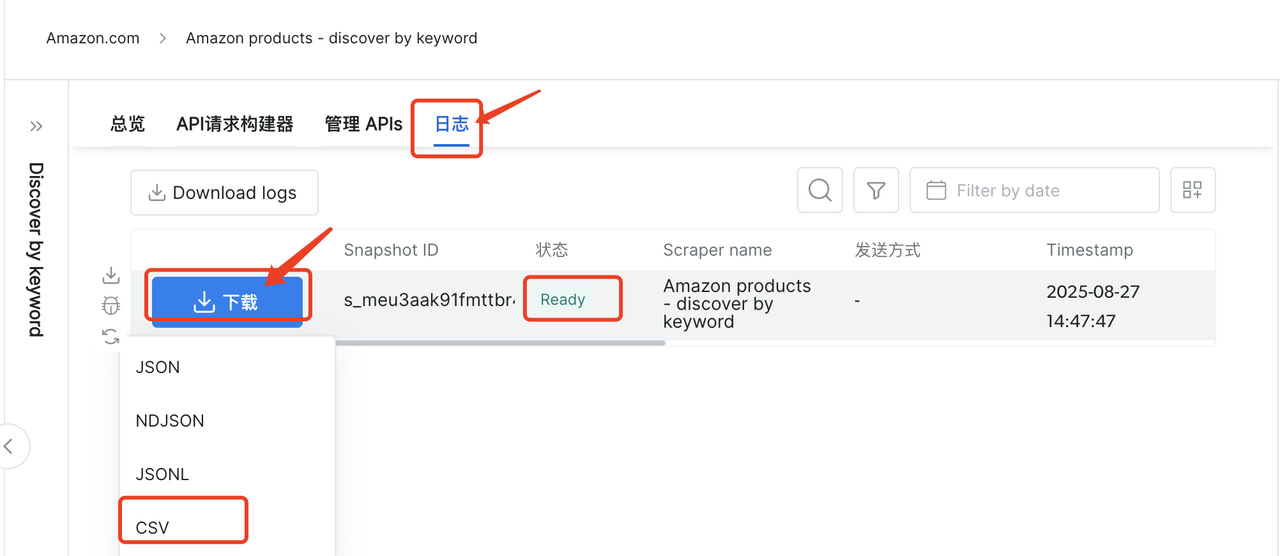
随后在“日志”中查看爬取状态,当状态为“Reay”时,说明已经爬取成功,下载选择“CSV”格式的数据
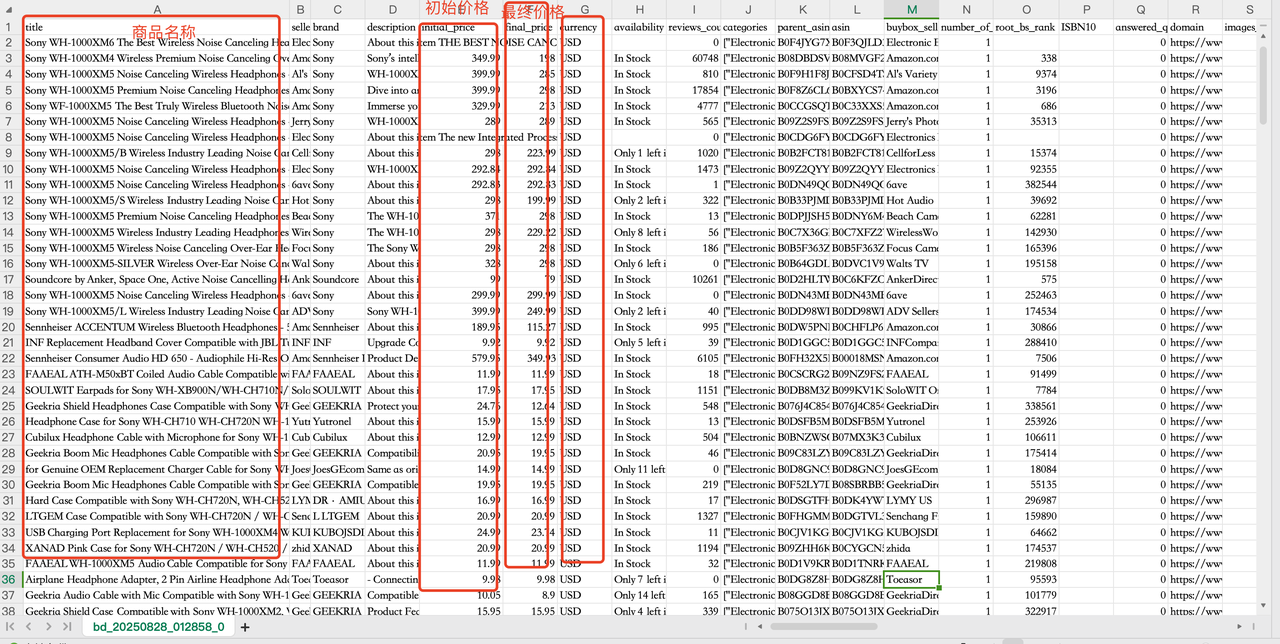
爬取结果如下,一共261条记录
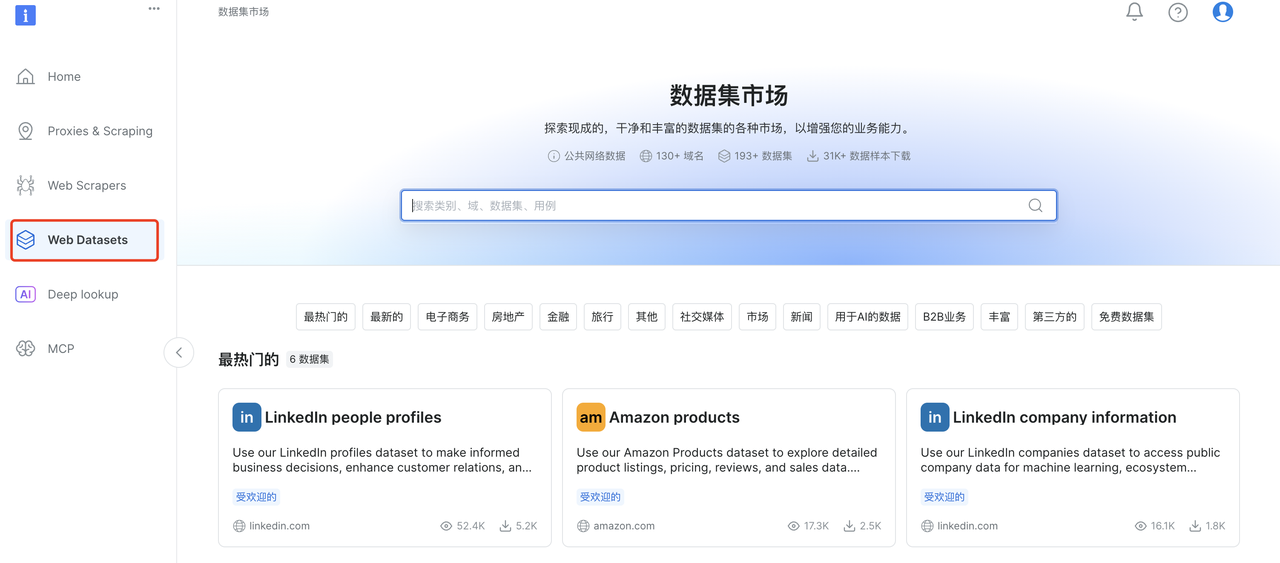
数据集市场
另外Bright Data 还有现成的数据集市场,支持常见的130多个常见网站,近200个数据集,拥有31K+数据样本可以下载,直接拿来用,真的很棒!
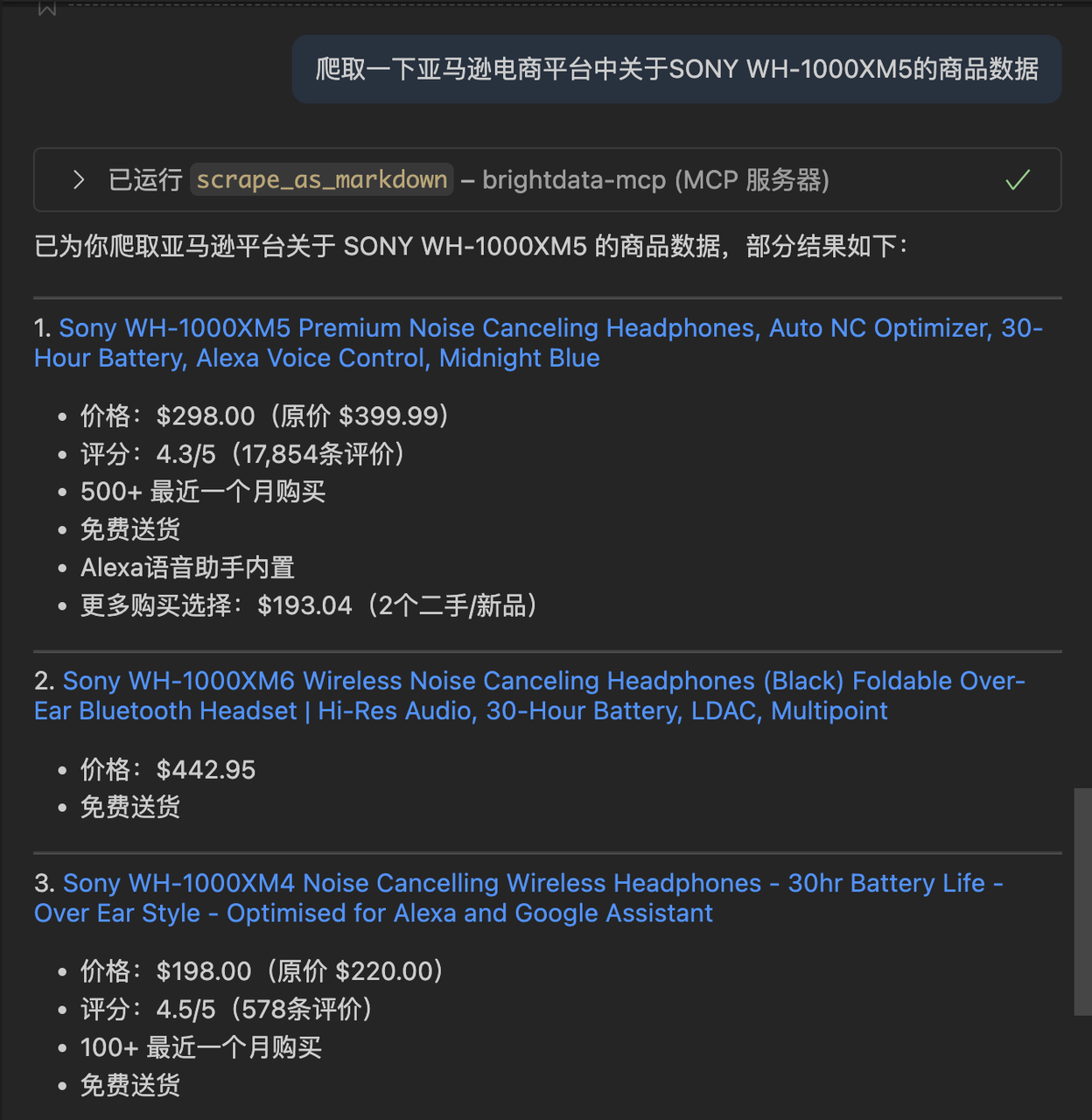
MCP
支持MCP,可以集成到Cursor、Claude、n8n、VSCode等工具,我们可以利用直接在工具里输入我们的需求,Agent可以直接调用mcp,输出我们想要的数据,比如下面是VS Code开发工具,我配置好Bright Data的 mcp 之后,在Copilot中输入我想要爬的网站或者意图,Copilot就会调用配置好的mcp进行爬取并且输出。比如这里我还是要爬取一下SONY WH-1000XM5的商品数据。
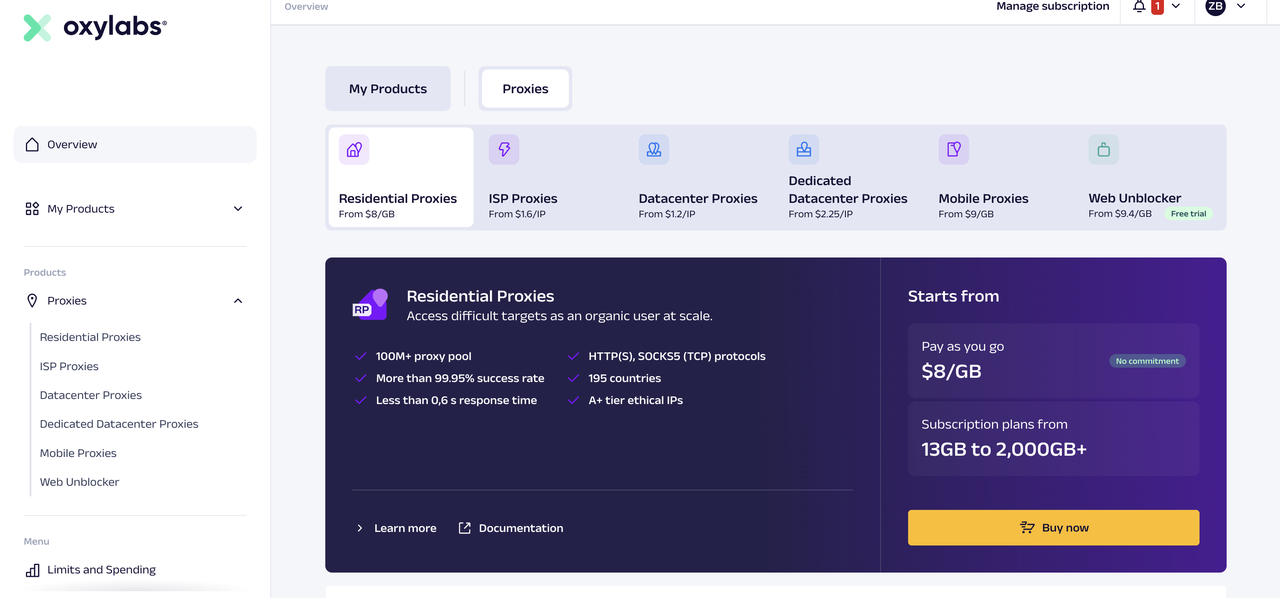
2、Oxylabs
Oxylabs的Web Scraper API 提供了1$额度以及Web Unblocker 1G额度。其他的代理比如:住宅代理、ISP、移动代理等都需要付费才能操作。
这里我使用其Web Scraper API 爬取一下亚马逊电商平台上的SONY WH-1000XM5。
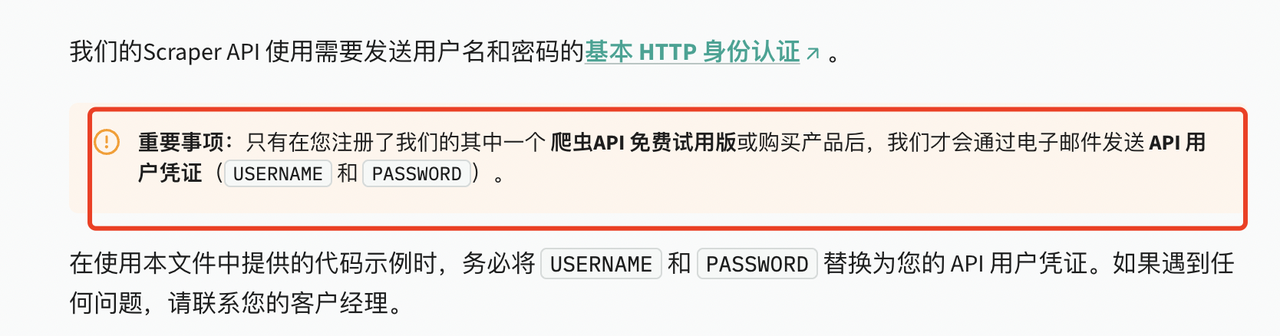
比较重要的一点,在使用Web Scraper API爬取数据要设置USERNAME和PASSWORD作为用户凭证。
根据提示页面中提示,我设置source为“amazon_search”,query为“SONY WH-1000XM5”,“start_page”:“1”,“pages”:“10”
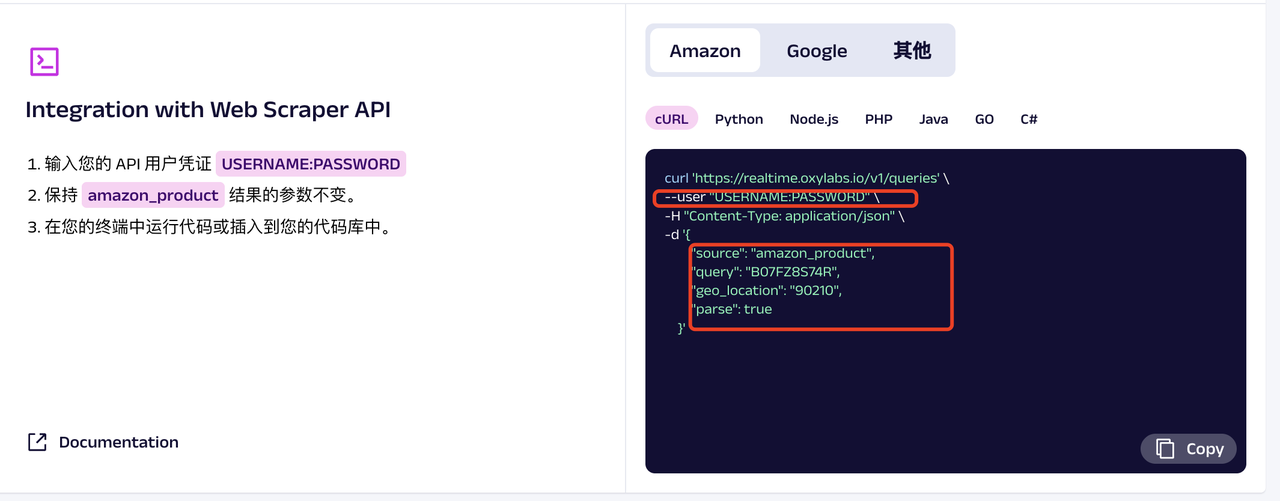
输入下面的命令:
curl ''https://realtime.oxylabs.io/v1/queries'' --user 'guilai_DFtRk:Guilai123123_' -H 'Content-Type: application/json' -d '{"source": "amazon_search", "query": "SONY WH-1000XM5", "geo_location": "90210", "parse": true,"start_page":"1","pages":"10"}' -o result.json
如果pages为30、40、100就会报下面的提示,并发量不高
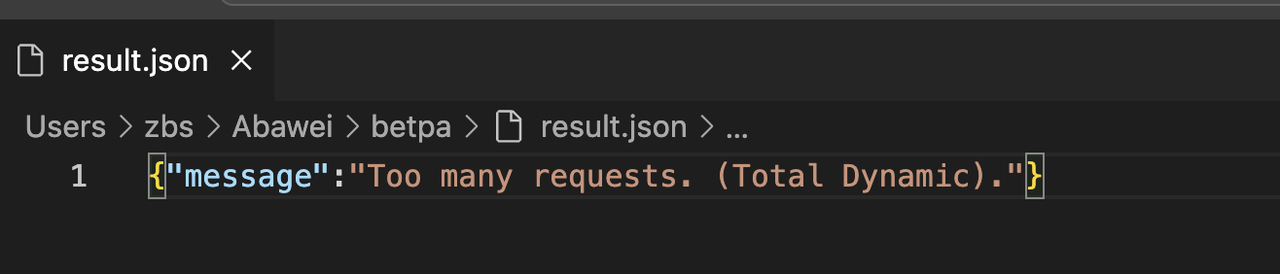
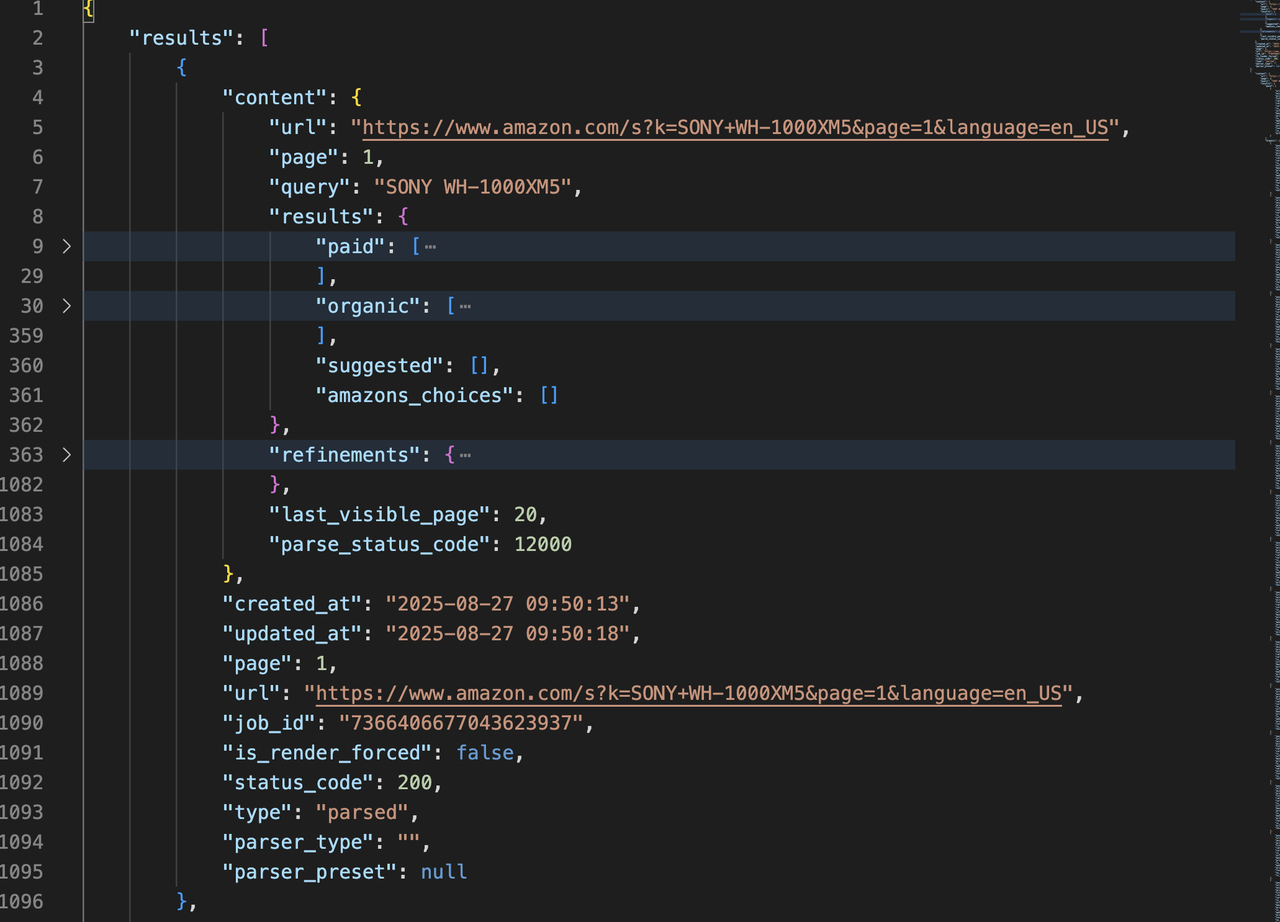
下面是最终输出的结果如下,爬虫速度在30s左右
3、ThorData
ThorData提供了常见的住宅/移动/ISP/数据中心代理等等,其SERP API可以爬取主流搜索引擎:Google、Bing、DuckDuckGo、Yandex等搜索平台的结果,新用户可以有2000个结果额度。并且它也提供Web Scraper API ,不过可以爬取的网站只有YouTube、FaceBook、Amazon,提供的API种类也比较少。
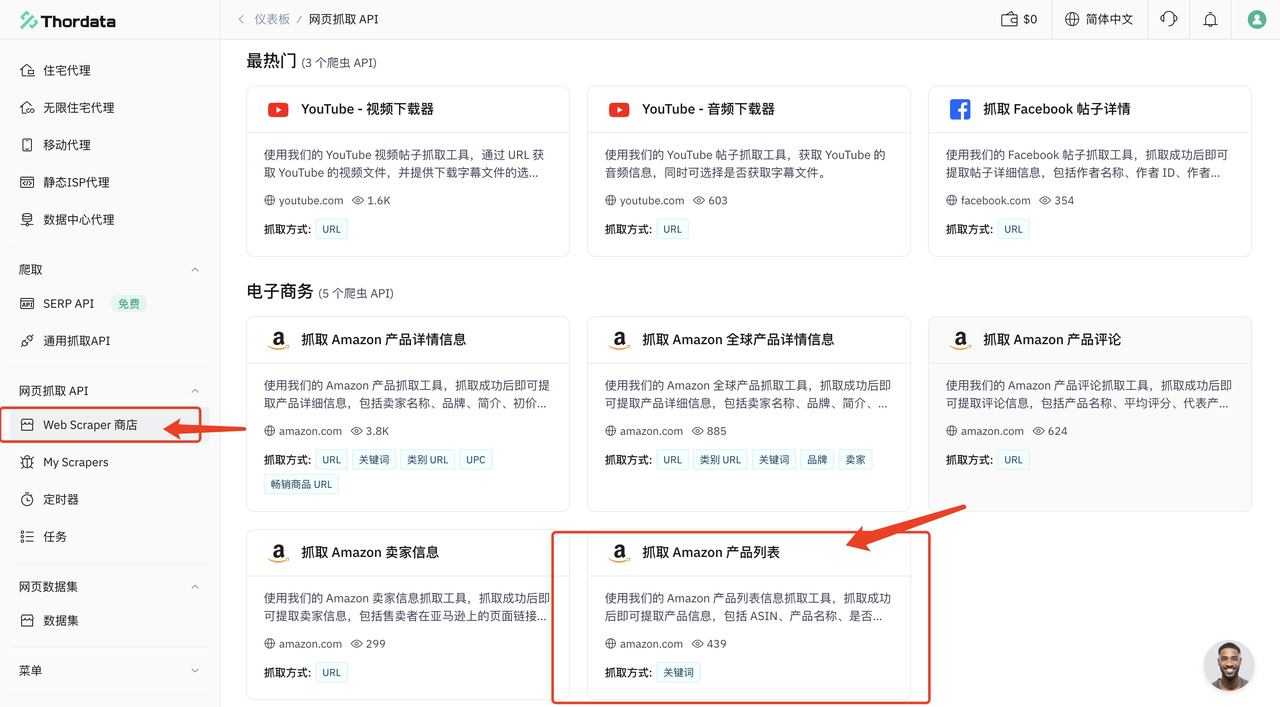
这里我使用Web Scraper API爬取一下SONY WH-1000XM5,输入关键字、爬取页数,点击开始抓取
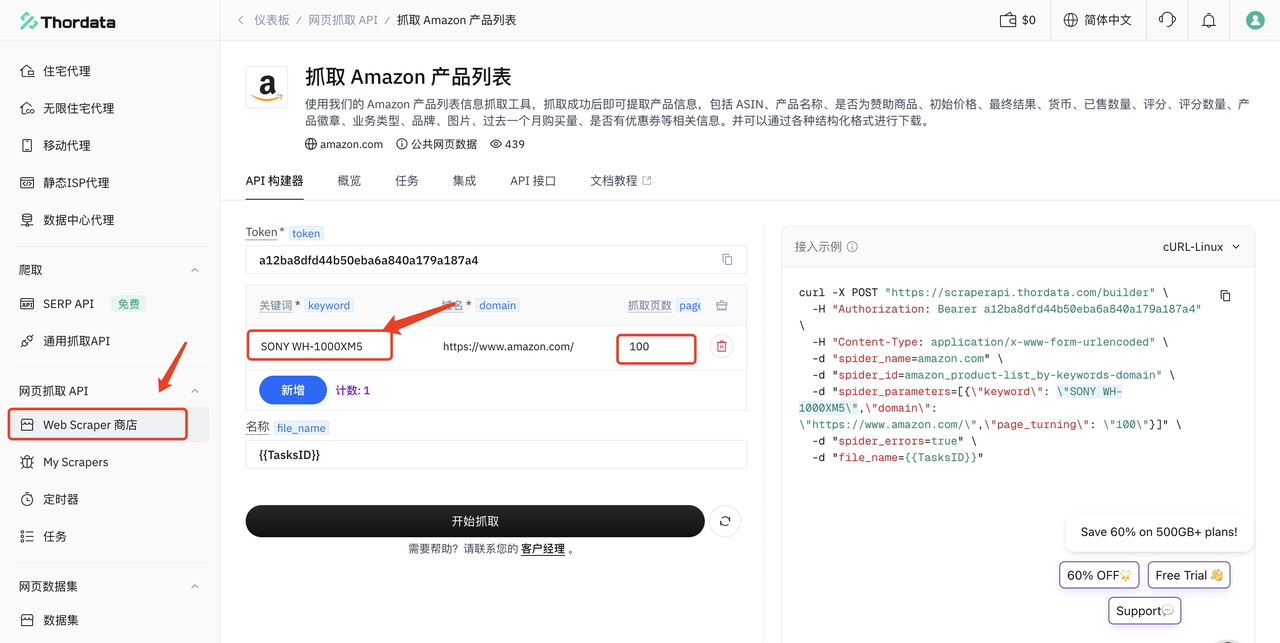
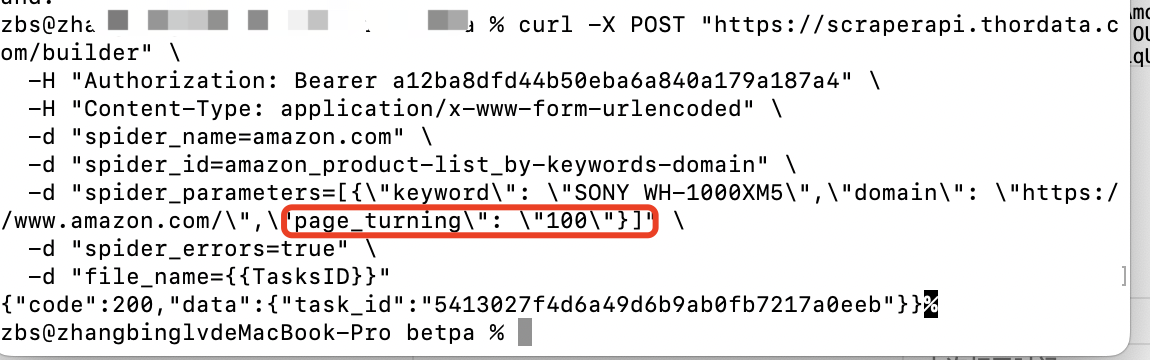
当然这里也可以直接复制脚本在本地执行,可以看到它创建了一个任务id
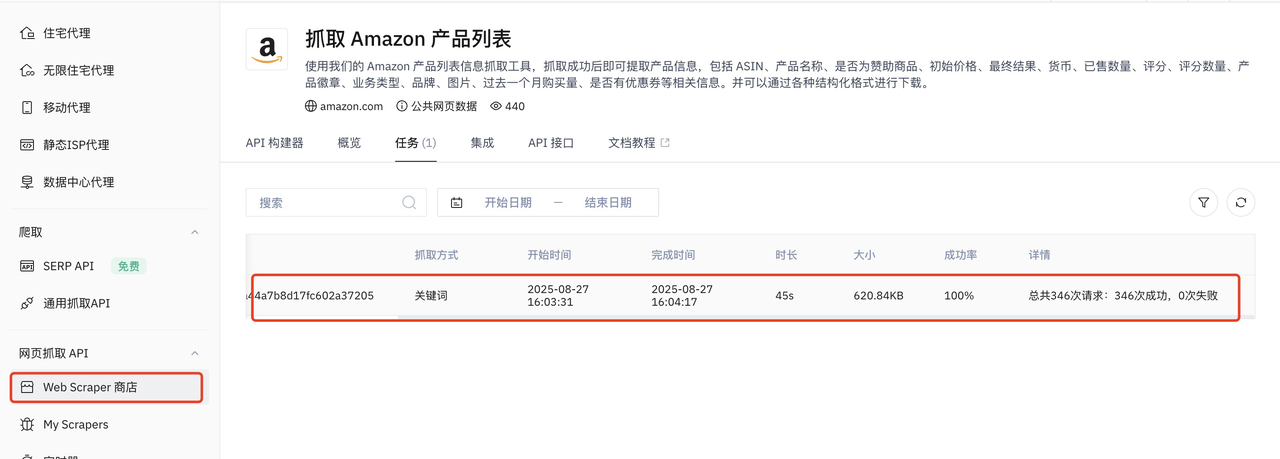
抓取成功之后可以看到爬取任务的具体信息,爬取速度为45S
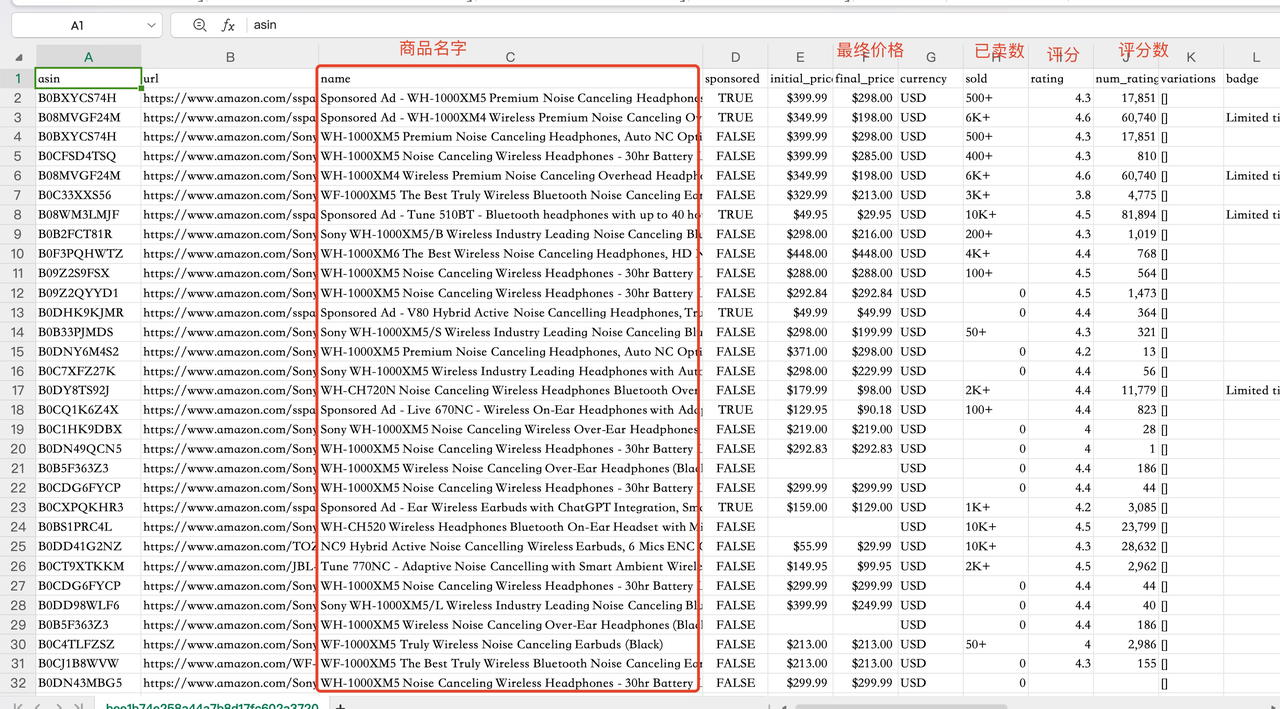
下载结果为csv文件,并查看
小结
通过上面三款代理使用,对新手来说,Bright Data 最适用,提供免费额度体验,几乎可以体验任意代理产品。另外Oxylabs支持不了很大的并发量,Bright Data、ThorData并发量还可以。ThorData抓取API种类太少了,其抓取速度很快。Bright Data支持的网页抓取API 超120+,种类丰富,爬取数据的速度稍微慢点。总体来说Bright Data 不论对于个人还是企业都非常合适,适用于大规模爬取,爬取过程还十分稳定。
最后
在选择AI数据采集代理时,关键在于明确采集目标、遵守合规性要求,并结合代理的技术能力、可扩展性与稳定性来做出选择。对于大规模、长期采集任务,像 Bright Data 和 Oxylabs这样的高端服务商提供了强大的技术支持和全球合规保障,适合需要高并发和高成功率的企业级应用。
而对于预算有限的小团队或项目,Proxyrack、Proxy-Cheap 和 Shifter 等则提供了更具性价比的选择,满足中小规模数据抓取的需求。在选择代理时,还应考虑安全性、隐私保护及数据保护等因素,确保数据采集活动不受到法律风险的影响。总之,选对代理不仅能提升数据采集的效率,还能为后续AI模型训练提供高质量的支持。
附:参考链接:
Bright Data:brightdata.com
ScraperAPI:scraperapi.com
Oxylabs:oxylabs.io
ThorData:thordata.com
Decodo:decodo.com
NetNut:netnut.io
Proxyrack:proxyrack.com
Proxy-Cheap:proxy-cheap.com
Proxy-Seller:proxy-seller.com
Shifter:shifter.io
StormProxies:stormproxies.com


















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











