






前言
来自人类的恶意攻击(下)
知道模型参数的攻击叫白箱攻击,反之叫做黑箱攻击。
一、如何进行黑箱攻击
假设知道network是通过什么训练资料训练出来的,可以训练一个proxy network模仿。对proxy network攻击也许丢到不知道参数的network上也会成功。
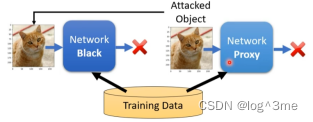
假设完全不知道训练资料,也是可以攻击的。把图片丢入network,看看他会输出什么。把输入输出的成对资料训练一个模型,当做proxy network。
二、防御的方式
可以大致分为被动防御和主动防御
1.被动防御
被动防御,是指在模型前面加一个filter,filter的功能是削减attack signal的效果,让network不会辨析错误。一个简单的方法直接用模糊化就可以使attack的效果下降,但是缺点就是使network对于图片辨析的confidence分数下降。所以模糊的程度不能太大。
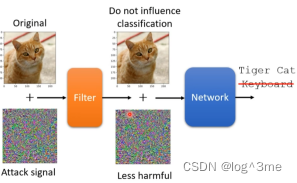
另一种做法是压缩再解压缩,失真这件事可能会让攻击失去威力。
也可以用generator的方法,让generator产生一个和输入一样的图片。
被动防御在被攻击方知道的情况下就不那么有效,比如模糊化,模糊化就相当于是network的第一层,如果攻击方知道在network多加了一层,把多加的这一层放到攻击中,就可以躲过模糊化这个过程。
一种解决办法就是加上随机性,比如一张图片输入进来,可以放大也可以缩小,是随机。把图片放到灰色背景上,放的位置也是随机的,然后将这个灰色背景的图片给影像辨识系统。

这种随机的方式也有问题,假设别人知道你的随机的分布的话,找到一个attack signal可以攻破所有图片变化方式的话,还是会被攻破。
2.主动防御
主动防御,在训练的时候就训练一个不容易被攻破的模型。这种方式叫做adversarial training。
训练资料有image和image label,训练完一个后。用训练资料训练一个模型在训练的阶段对这个模型进行攻击,在训练资料上加上attack signal,把攻击后的图片标上正确的label,制造一个新的训练资料,新的训练资料都是被攻击过的。把两个训练资料放到一起重新训练模型,不断找漏洞,补漏洞。这个过程也是data augmentation。但如果新的攻击的方法没有被adversarial training考虑过,那么adversarial training就不一定能挡住新的攻击。

总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7/?p=24&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









