






前言
概述增强式学习(二)Policy gradient
Policy gradient的重点是怎么定义A(如何评价actor的行为)
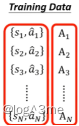
一、定义A的不同版本
1.Version0
一个最简单的方法是:首先收集一些成对的s和a,actor可以看做是随机的,看到s随机输出一个a。A时用来评价希不希望actor采取某个行为,reward的正负表示这个action是否是好的。把reward当做A就可以评价actor采取的行为。这种方法不是一个好的方法,这种方法learn出来的actor,没有一个全面规划的概念。应为s1经过actor得出的a1并不是互动的全部,应为a1会影响s2,s2会影响a2…在互动时会进行reward delay,用短期的利益换取更长的目标。这种方法只会学到reward是正的情况。
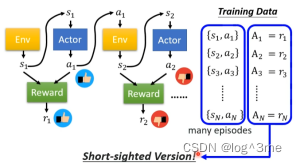
2.Version1
a1不在取决于r1而是a1之后所有发生的,G1=r1+r2+…+rn,A1=G1;以此类推A2=G2=r2+r3+…+rn。

3.Version2
但是version1也有点问题,当一个过程很长的时候,把rn归功于a1不是很合适。采取a1后立即有影响的是r1,然后是r2,r3…最后才是rn。所以在计算G的时候越往后的,r前面要乘一个系数,距离r1越远这个系数越小。

4.Version3
Reward是相对的,如果得到的reward都是正的,不过有大有小,G算出来的结果都是正的,有些行为是不好的,但是依然会鼓励model采取这些行动。所以这需要做一下标准化。把G都减去一个b,让G有正有负。
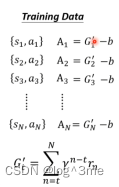
二、Policy gradient
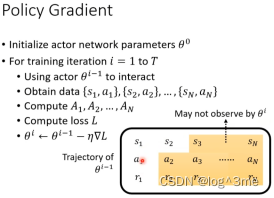
首先随机初始化actor
拿初始的actor和环境做互动,拿到成对的s和a。用A评价这些action是好还是坏(重点在于怎么选择A)。定义loss,用gradient descent update model。
和其他不同的点在于,一般训练资料收集都在for之外,但是在RL是在for以内。这就表示每次收集到训练资料后,就只能更新一次参数,要想在更新就得在收集一次参数。用i-1收集到的资料,只能拿来训练i-1,不能拿这些资料训练i。要被训练actor和要拿来跟环境互动的actor最好是同一个。当这两个是同一个的时候,叫做on-policy learning。
三、Explotration
Actor采取行为的时候是有随机性的,这个随机性很重要,假设一开始初始的actor第一步永远只会一个行动,不采取另一个行动,那么就永远不知道另一个行动到底是好是坏。只有actor随机到另一个行动,才能去评估这个行为。期望这个actor随机性大一点,才能收集到更多的资料,避免有一些情况的reward从来不知道。为了让actor随机性大一点,在training的时候刻意加大随机性,比如actor的output是一个分布,刻意加大这个分布的cross-entropy,这样刻意比较容易的sample到概率低的行为。或者直接在actor的参数上加noise,让actor每次的行为都不一样。
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7/?p=29&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









