






文章目录
前言
概述增强式学习(三)Actor-Critic
一、Critic
Critic的工作是评估一个actor的好坏,通过看到某个样子的observation,接下来可能会得到多少reward。
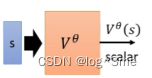
Value function Vθ(s):V的输入是s,s是状况(比如说游戏的画面),V观察的是参数为θ的actor。Vθ是一个function,输入是s,输出是scalar,这个scalar是discounted cumulated reward(在reward前面乘上系数的G(即G’),离当前r越远的r,系数越小)。Value function就是要未卜先知,只看到s就预测actor的表现。Value functtion的数值和被观察的对象有关系,同样一个s,不同的actor得到的分数是不同的。
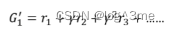
Critic是怎么被训练出来的,
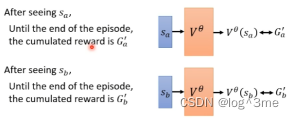
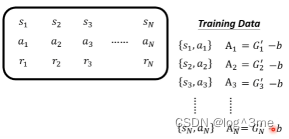
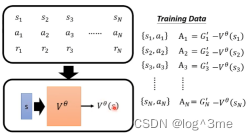
一种方法是monte-carlo(MC)based approach。用actor和环境互动很多轮,会拿到很多记录,完成actor和环境的全部互动后会得到一个Ga’。这样看到sa接下来的输出应该是Ga’。这样value function就会获得一笔训练资料,如果看到sa作为输入,Vθ(sa)应该要跟Ga’越接近越好。同理看到sb、sc…
另一种方法是temporal-difference(TD) approach。区别于上一个方法,这个方法不用进行玩全部的互动就可以得到训练资料,看到st之后actor执行at得到的rt,再看到st+1,(st,at,rt,st+1)这些资料就可以训练Vθ(s)。
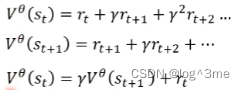
通过V(st)和V(st+1)的关系,会发现这两者之间的关系,可以写成第三个式子的关系。虽然不知道把st和st+1带入Vθ后输出是多少,但是知道两者相减的数值是多少。这两者相减,应该和rt越接近越好,而rt是知道的。
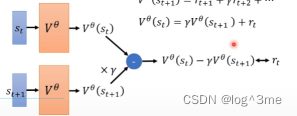
MC和TD是基于两种不同的假设,所以会有差异。

V(sb)出现8次,6次为1,平均下来,V(sb)=3/4。但基于MC,sa出现一次是0,所以V(sa)=0。而基于TD,V(sa)=V(sb)+r,r在第一个式子中为0,所以V(sa)=3/4.
Critic如何被用在actor
二、Critic如何被用在Actor
1.Version3.5
之前做normalization时G’-b,而这个b的合适取法是设为V(s)。
V(st)是看到st时的一个期望值,因为有随机性的每次得到的reward不太一样。当看到st时不一定会执行at这个操作,actor本身是有随机性的,同样的st,actor的输出会不一样,每次算出的G’都会是不一样的,把这些G’平均起来就是V(st)。Gt’是st情况下执行at接下来会得到的Gt’。
At大于0表示这个action是比随机出来的action要好,反之表示要比随机出来的要坏。
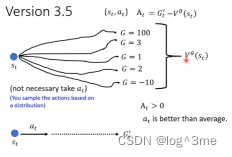
这个Gt’是到结束为止某一个随机出来的结果,而V(st)是很多条路径平均后的结果,用sample减平均好像不是一个好的选择。
2.Version4 :Advantage actor-critic
平均-平均
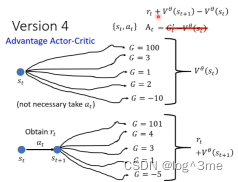
st经过at获得rt,到st+1,让st+1一直到结束会有很多不同的G’,把这些平均起来就是V(st+1),再加上rt,表示在st执行at后得到的期望值,用at+V(st+1)-V(st)表示At。这样st采取at得到的期望reward-不采取at而是随机sample的一个action两者期望值差距有多大。如果At>0就表示比随机出来的action要好。
三、Tip of actor critic
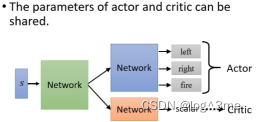
以游戏画面为例,Actor和critic都是network,actor的输入是一个画面,输出是每一个action的输出,critic的输入是一个画面,输出是一个数值代表接下来得到的reward的总和。这两者有共同的输入,且前面的部分是可以公用的(如cnn)。
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7?p=30&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









