






前言
概述增强式学习(五)IRL
一、如果没有reward
在游戏中reward是比较容易获得的(计分板等),但有时候在真实环境中,没法定义reward,如自动驾驶中,车辆躲避行人、闯红灯等等,如何准确的定义reward。
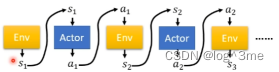
在没有reward的情况下,让actor和环境互动的一个方法叫imitation learnin。假设actor仍然可以跟环境互动,但是没法获得reward。在没有reward的情况下机器如何学习呢,虽然没有reward,但是有export,export是将人类和环境的互动记录下来,比如自动驾驶中,人类驾驶在遇到某个路口时如何采取行动等等。这个听起来很想supervised learning,有成对的资料,遇到s1采取a1,s2采取a2,让机器模仿人类的行为,让机器的行为和人类行为越接近越好。但是有可能人类和机器观察到的s是不一样的,比如机器看到的都是人类正常行驶的情况,没有见过马上撞墙的行为,机器就学不到人类平时不会遇到的情况;又比如某些人开车有特殊习惯,机器并不一定要模仿。
二、Inverse reinforcement learning(让机器自己定reward)
通过专家示范和环境去反推reward function是什么。和之前通过环境和actor互动是相反的,应为此时是没有reward。学出reward function后,就可以用一般的RL去训练actor。
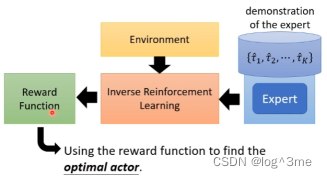
如何找出reward function:

基本条件式认为老师的行为是最棒的(假设老师的行为可以取得最高的reward)。
1.有一个actor(一开始什么都不会),在iteration里面actor会和环境互动,收集一些actor自己的行为。
2.定义一个新reward function,评价老师的行为分数高,评价actor自己的行为时分数低。然后重新训练actor,让actor去最大化得到的reward(在定义的新reward function条件下)。3.在iteration中反复执行2,想办法最大化reward function。
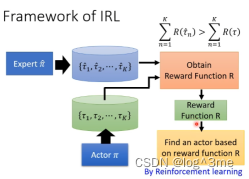
整个framework就像GAN,actor就像generator,reward function就像discriminator。
总结
视频学习地址:https://www.bilibili.com/video/BV13Z4y1P7D7?p=32&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









