






前言:
单GPU运行程序比较慢,再拥有多卡前提下,可以选择使用多卡去进行加速。此帖仅表示本人在多GPU运行时候遇到一个冲突,仅供参考。
遇到的问题如下
单GPU时运行代码:
self.use_cuda = use_cuda
self.device = torch.device('cuda' if self.use_cuda else 'cpu')
self.model = VNet(self.image_channel, self.numclass)
self.model.to(device=self.device)
运行正常,再更改为下面的多GPU运行时,会在第一个epoch卡住
device_ids = [0, 1]
self.model = torch.nn.DataParallel(VNet(self.image_channel, self.numclass), device_ids=device_ids).cuda()
具体信息下图所示,使用nvidia-smi查看GPU状态时,会有一个GPU一直100%,另一个GPU0%一直保持不变。

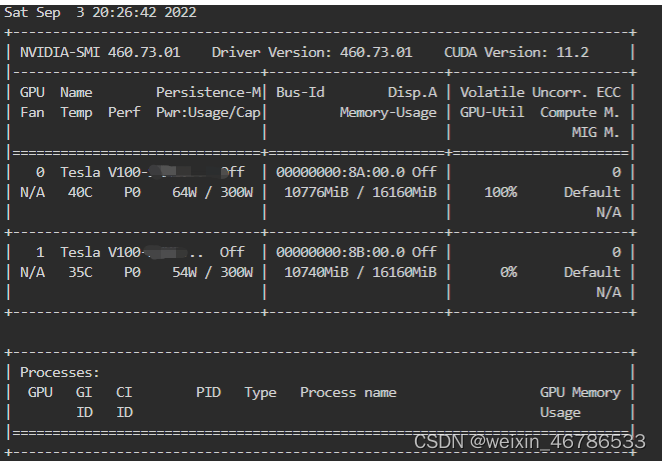
解决方法
经过漫长排查发现是与os.environ代码段发生冲突。两个代码段不能同时存在,注释掉os.environ即可:
# os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# use_cuda = torch.cuda.is_available()
一些其它多GPU运行卡住的解决方案
pytorch 多机多卡卡住问题汇总: https://blog.csdn.net/weixin_42001089/article/details/122733667
https://blog.csdn.net/yyywxk/article/details/106323049
https://zhuanlan.zhihu.com/p/95700549
希望能帮到你们!














 2115
2115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









