







目录
一、前言
近期复现ST-GCN代码时,发现遇到一个问题,其开源代码使用了 nn.DataParallel() 进行多 GPU 并行训练,同时使用 nn.ParameterList() 来构建参数列表;这时会出现一个 Pytorch 的 Bug,即 nn.ParameterList()在 forward 阶段会出现 empty的错误,报错如下:
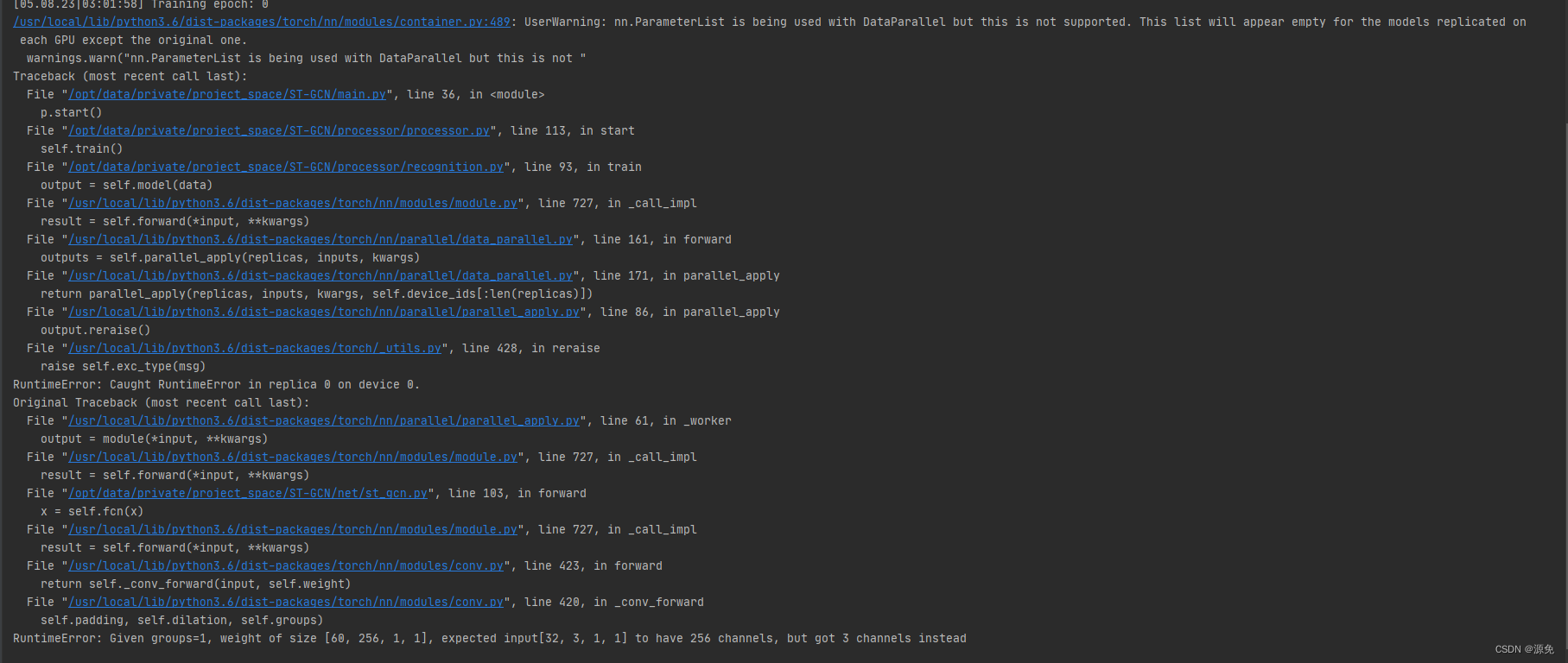
经 原作者确认,这是pytorch的bug,原作者是在torch1.2上开源的代码,本人使用的是torch1.7,会有这个问题。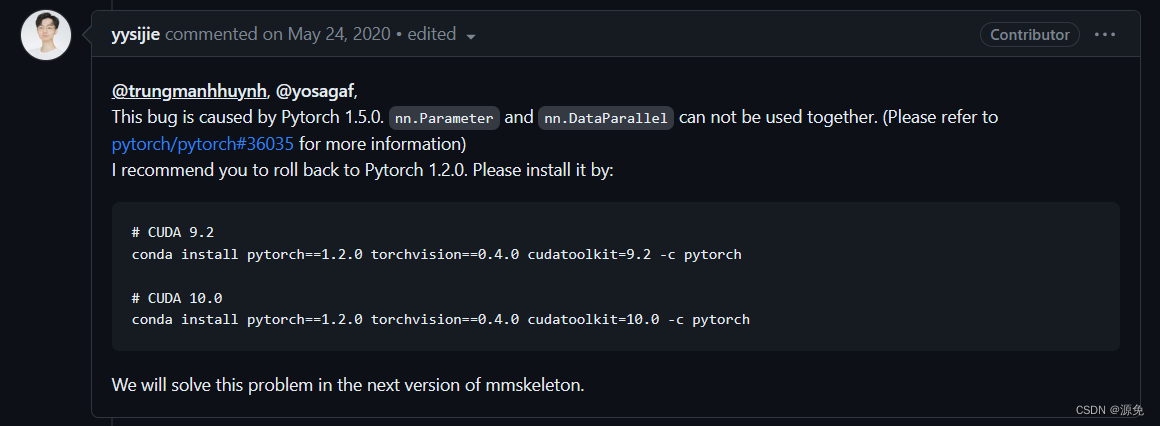
二、报错代码
ST-GCN 的 __init__
if edge_importance_weighting:
self.edge_importance = nn.ParameterList([
nn.Parameter(torch.ones(self.A.size()))
for i in self.st_gcn_networks
])在在 forward 阶段执行以下代码会直接跳过,因为使用DataParallel进行多卡训练会导致这个Parameter{List/Dict}无法作为模型的参数成功复制到其他卡上,导致 self.edge_importance 为空。
for gcn, importance in zip(self.st_gcn_networks, self.edge_importance):
x, _ = gcn(x, self.A * importance)三、解决
看了一些博客,大致有以下方法
- 经过测试可以解决:由于多 GPU 并行训练导致的问题,一个简单的方法就是使用单个GPU进行训练,但这也可能会出现显存不足的问题;
- 不使用 nn.ParameterList() 列表的方式存储参数(可能属于是笨方法):
# 修改 init 中该部分 if edge_importance_weighting: # self.edge_importance = nn.ParameterList([ # nn.Parameter(torch.ones(self.A.size())) # for i in self.st_gcn_networks # ]) for i in range(len(self.st_gcn_networks)): self.register_parameter('edge_importance{}'.format(i), nn.Parameter(torch.ones(self.A.size())))# forwad 修改forward该部分 # for gcn, importance in zip(self.st_gcn_networks, self.edge_importance): # x, _ = gcn(x, self.A * importance) x, _ = self.st_gcn_networks[0](x, self.A * self.edge_importance0) x, _ = self.st_gcn_networks[1](x, self.A * self.edge_importance1) x, _ = self.st_gcn_networks[2](x, self.A * self.edge_importance2) x, _ = self.st_gcn_networks[3](x, self.A * self.edge_importance3) x, _ = self.st_gcn_networks[4](x, self.A * self.edge_importance4) x, _ = self.st_gcn_networks[5](x, self.A * self.edge_importance5) x, _ = self.st_gcn_networks[6](x, self.A * self.edge_importance6) x, _ = self.st_gcn_networks[7](x, self.A * self.edge_importance7) x, _ = self.st_gcn_networks[8](x, self.A * self.edge_importance8) x, _ = self.st_gcn_networks[9](x, self.A * self.edge_importance9) -
将ParameterList中的元素都用nn.Module的register_parameter()单独注册为模型的参数。类似法 2
-
将DataParallel换为DistributedDataParallel。(嫌麻烦,没试过)
-
回滚torch版本。
# CUDA 9.2 conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=9.2 -c pytorch # CUDA 10.0 conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch -
修改torch源码。(试了没成功,可能是我用的远程服务器,改的总是本地的torch源码)

四、参考
https://github.com/pytorch/pytorch/issues/42327
https://github.com/pytorch/pytorch/issues/36035
https://github.com/open-mmlab/mmskeleton/issues/312
https://github.com/pytorch/pytorch/issues/36035
https://blog.csdn.net/unlimitedZR/article/details/123557017
https://blog.csdn.net/weixin_43863869/article/details/129673351
















 1981
1981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









