






由于目前仅有双卡3090显卡,我想尝试用量化的模型试一下本地部署32B的Qwen模型
一、部署Qwen代码仓库
1. 建立Qwen的虚拟环境,安装
conda create -n qwen python=3.11
conda activate qwen
克隆项目文件
git clone https://github.com/QwenLM/Qwen
安装依赖文件
cd Qwen
pip install -r requirements.txt
2.安装GPU版本pytorch
可以先到网址找一下自己的版本和安装指令
pytorch安装
12.x版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
11.x版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
验证pytorch是否安装成功
输入python进入到解释器环境:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
如果输出是True,则安装成功
二、下载 Qwen3-32B-GGUF量化模型
我是用hugging face下载的模型
huggingface-cli download --token 这里使用自己的token --resume-download Qwen/Qwen3-32B-GGUF --local-dir ./Qwen3-32B-GGUF
hugging face要在自己的主页设置token可以访问的模型
在 https://huggingface.co/settings/tokens创建token,然后点最右边三点,选Edit permission,在Repositories permissions 下面输入自己想下载的模型,比如Qwen/Qwen3-32B-GGUF,就可以用这个token下载了。
该量化模型有多种级别
/media/ros/huck/Qwen/Qwen3-32B-GGUF/Qwen3-32B-Q4_K_M.gguf
/media/ros/huck/Qwen/Qwen3-32B-GGUF/Qwen3-32B-Q5_0.gguf
/media/ros/huck/Qwen/Qwen3-32B-GGUF/Qwen3-32B-Q5_K_M.gguf
/media/ros/huck/Qwen/Qwen3-32B-GGUF/Qwen3-32B-Q6_K.gguf
/media/ros/huck/Qwen/Qwen3-32B-GGUF/Qwen3-32B-Q8_0.gguf

三、使用Ollama运行推理GGUF文件
也可以直接安装 curl -fsSL https://ollama.com/install.sh | sh
使用 Ollama 加载本地 GGUF 文件
1. 创建 Modelfile
touch Qwen3-32B-GGUF-Q4_K_M.Modelfile
sudo chmod 777 Qwen3-32B-GGUF-Q4_K_M.Modelfile
FROM /media/ros/huck/Qwen/Qwen3-32B-GGUF/Qwen3-32B-Q4_K_M.gguf
PARAMETER temperature 0.7 # 控制生成随机性(0.1~1.0)
PARAMETER top_p 0.8 # 核采样概率
PARAMETER repeat_penalty 1.05 # 减少重复内容
SYSTEM """你是一个逻辑严谨的助手,擅长拆解复杂任务。请逐步分析问题并提供结构化解决方案。"""
注意自己用的时候把这些注释删掉。
2.注册模型到 Ollama
ollama create qwen3-logic -f Qwen3-32B-GGUF-Q4_K_M.Modelfile
3.启动模型并测试
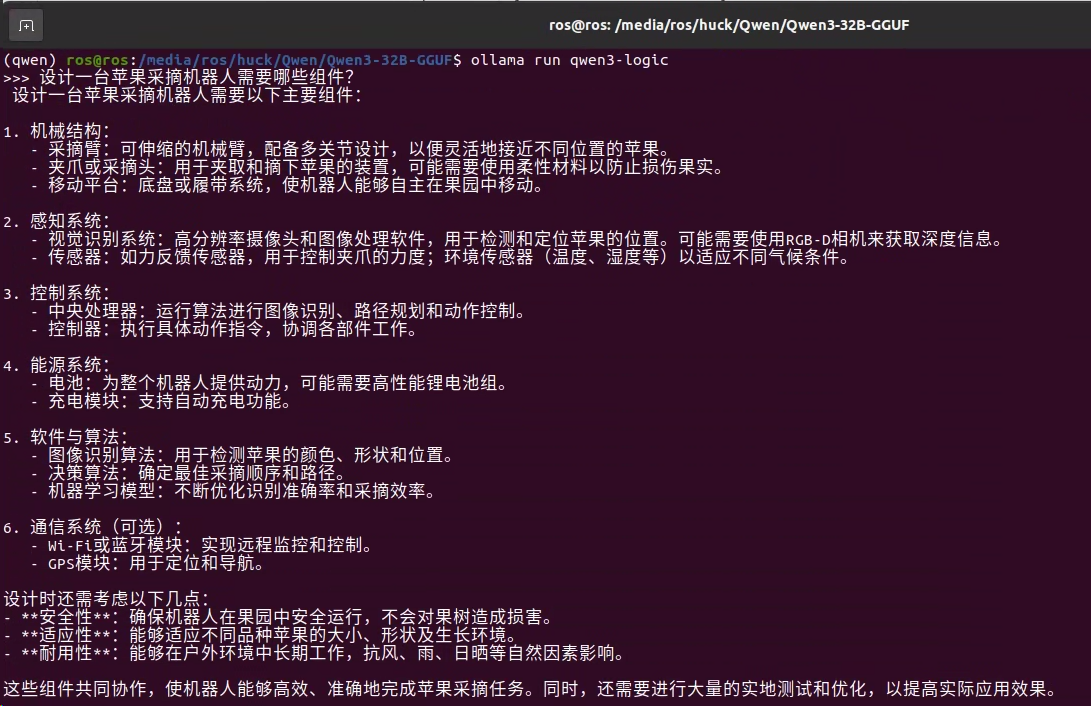
ollama run qwen3-logic
出现 >>> 并提示输入消息就是没问题的
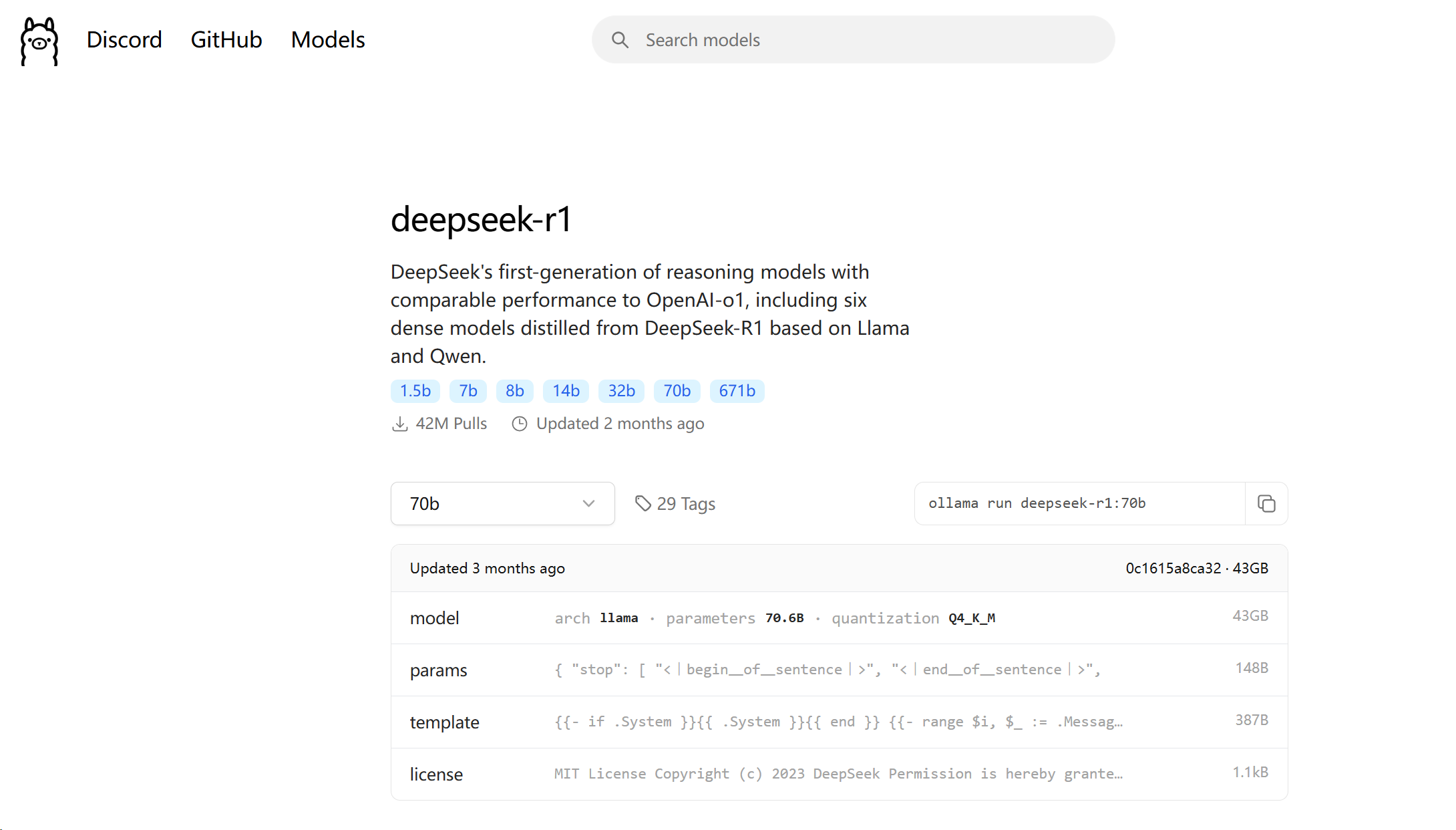
4.直接运行 ollama 官网查支持的模型
比如这里的
ollama run deepseek-r1:70b
当然,要改一下ollama默认下载模型的地址
默认情况下,ollama模型的存储目录为:
/usr/share/ollama/.ollama/models
首先,关闭服务
systemctl stop ollama.service
然后修改服务的配置文件
#步骤一:进入/home目录下名为下载的文件夹,然后点击右键创建名为ollama的文件夹,再进入该文件夹创建名为models的文件夹。
#步骤二:将目标路径的所属用户和组改为root
sudo chown -R root:root /home/alex/下载/ollama/models
#步骤三:将其文件权限更换为777
sudo chmod -R 777 /home/alex/下载/ollama/models
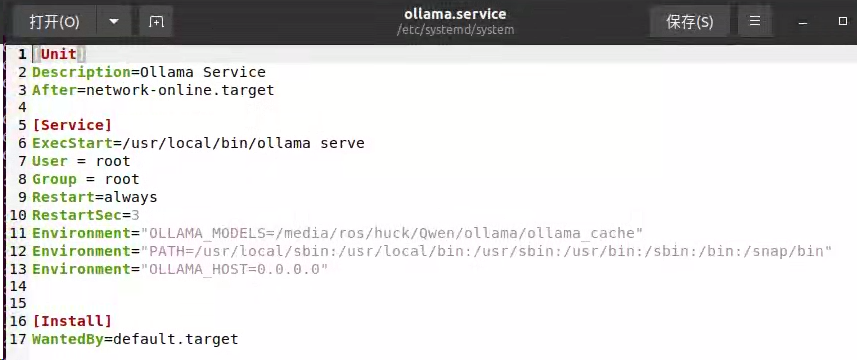
#步骤四:打开ollama.service文件
sudo gedit /etc/systemd/system/ollama.service
#步骤五:进行修改并添加环境(注意路径要改成自己设置的)
User = root
Group = root
Environment="OLLAMA_MODELS=/home/alex/下载/ollama/models"
Environment="OLLAMA_HOST=0.0.0.0:11434"
然后重启服务并且查看状态
# 刷新配置
sudo systemctl daemon-reload
# 重启ollama
sudo systemctl restart ollama.service
# 查看一下重启后的ollama运行状态
sudo systemctl status ollama

















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









