









【大模型】 炸裂!!阿里开源大模型 Qwen/QwQ-32B 性能追平 DeepSeek-R1、o1-mini
Qwen/QwQ-32B 模型介绍
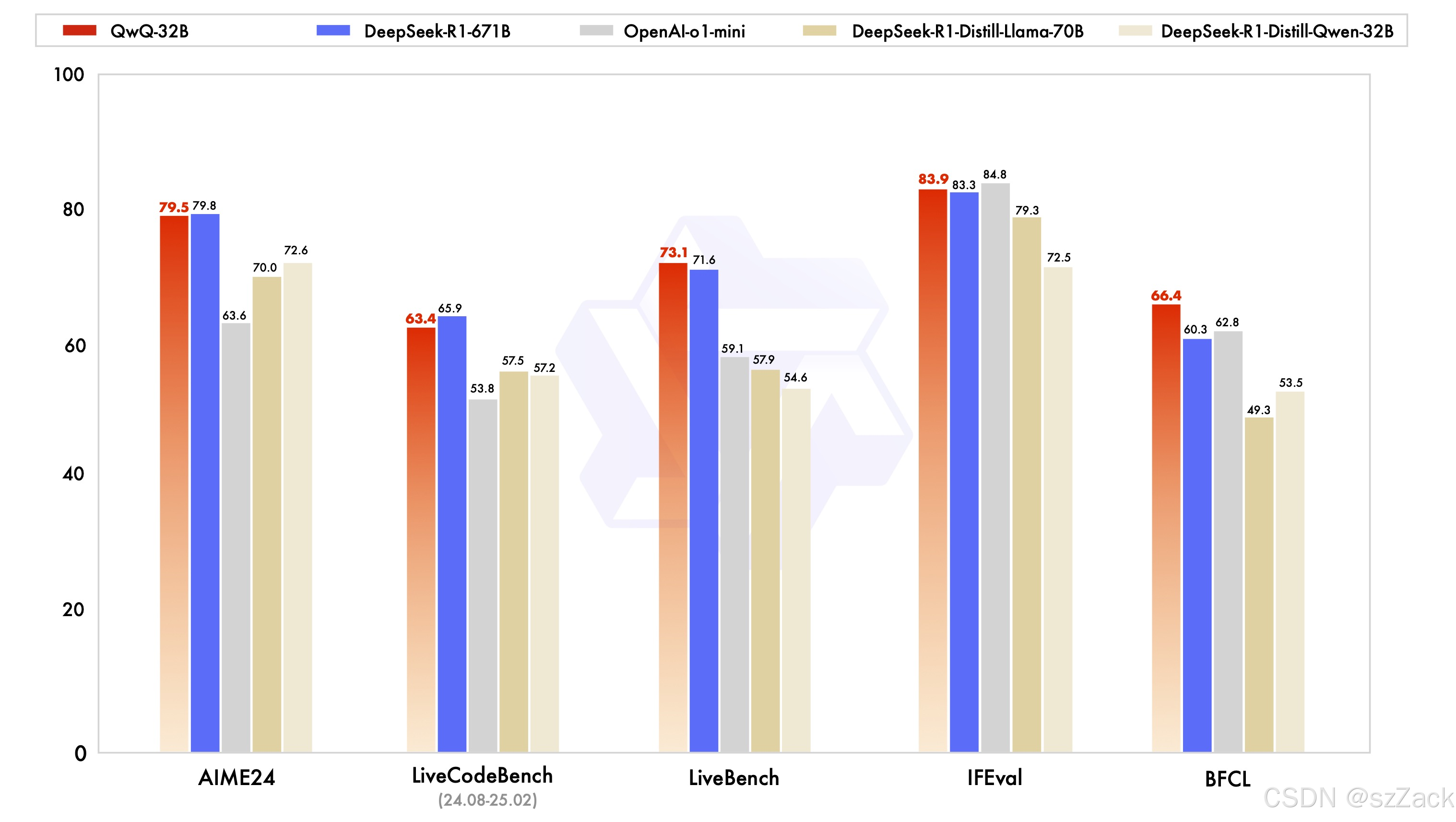
QwQ是Qwen系列的推理模型。与传统的指令调优模型相比,QwQ具有思考和推理能力,可以在下游任务,特别是难题中实现显著提高的性能。QwQ-32B是中等规模的推理模型,能够与最先进的推理模型(如DeepSeek-R1、o1-mini)实现竞争性能。
模型特性
Type: Causal Language Models
Training Stage: Pretraining & Post-training (Supervised Finetuning and Reinforcement Learning)
Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
Number of Parameters: 32.5B
Number of Paramaters (Non-Embedding): 31.0B
Number of Layers: 64
Number of Attention Heads (GQA): 40 for Q and 8 for KV
Context Length: Full 131,072 tokens
发布时间
2025年3月5日
模型性能
运行环境安装
pip install transformers==4.47 -i https://mirrors.aliyun.com/pypi/simple/
运行模型
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
下载
model_id: Qwen/Qwen2.5-1.5B-Instruct
下载地址:https://hf-mirror.com/Qwen/QwQ-32B 不需要翻墙
gguf量化后的模型
- 16显存跑32B 模型
下载模型 https://hf-mirror.com/bartowski/Qwen_QwQ-32B-GGUF/tree/main,选择:Qwen_QwQ-32B-IQ2_S.gguf 10.4 GB
使用llama.cpp测试
- 24GB 显存跑32B 模型
下载模型 https://hf-mirror.com/bartowski/Qwen_QwQ-32B-GGUF/tree/main,选择:Qwen_QwQ-32B-Q4_0.gguf 18.7 GB
使用llama.cpp测试
开源协议
License: apache-2.0


















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











