






【工业智能】需要了解的知识
写在前面:
本文仅为自己记录,不具有指导意义。
算法
关注每个算法试用的场景,哪个算法效果可能更好。一方面这个是来自于网络上介绍的算法本身的特性所导致的适用场景;另一方面来自于我们平时工作中处理某些问题自己测试出来哪种算法效果最好。
数据
样本不平衡 数据增强方法:SMOTE, diffusion model
相关性分析
简单的看两个变量的相关性:
pearson’, ‘kendall’, ‘spearman’
简单相关:研究两变量之间的关系
一般情况默认数据服从正态分布的,故用Pearson分析方法。
P值即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的P 值,一般以P < 0.05 为显著, P<0.01 为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05 或0.01。
在线性回归中,p<0.01(或者0.05)表示两个变量非常显著(显著)线性相关。
需要注意的是:在非线性回归中,不可以用p值检验相关显著性, 因为在非线性回归中,残差均值平方不再是误差方差的无偏估计,因而不能使用线性模型的检验方法来检验非线性模型,从而不能用F统计量及其P值进行检验。
秩相关系数(Coefficient of Rank Correlation),又称等级相关系数。它是反映等级相关程度的统计分析指标,常用的等级相关分析方法有Spearman相关系数和Kendall秩相关系数等。
偏相关或复相关:研究三个或者以上变量的关系,是简单相关的推广,因为实际中一个变量的变化往往要收到多种变量综合影响
reference:
https://zhuanlan.zhihu.com/p/37605060
https://blog.csdn.net/baidu_38172402/article/details/82977482
https://blog.csdn.net/sinat_35907936/article/details/123805702
模型可解释性
SHAP
是python开发的模型解释包。
可以解释任何机器学习模型的输出。
SHAP把所有特征视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。有两个核心:shape values、shape interaction values。
传统的feature importance VS SHAP:
feature importance只说哪个特征重要,但我们不知道该特征是怎么影响预测结果的。
SHAP value 能反映出每一个样本中的特征得影响力,还可以表现出影响的正负性。
dependence_plot: 单个特征如何影响模型的输出。
summary_plot: 为每个样本绘制其每个特征的SHAP值,这可以更好地理解整体模式,并允许发现预测异常值。每一行代表一个特征,横坐标为SHAP值。
force_plot:
LIME
预测模型
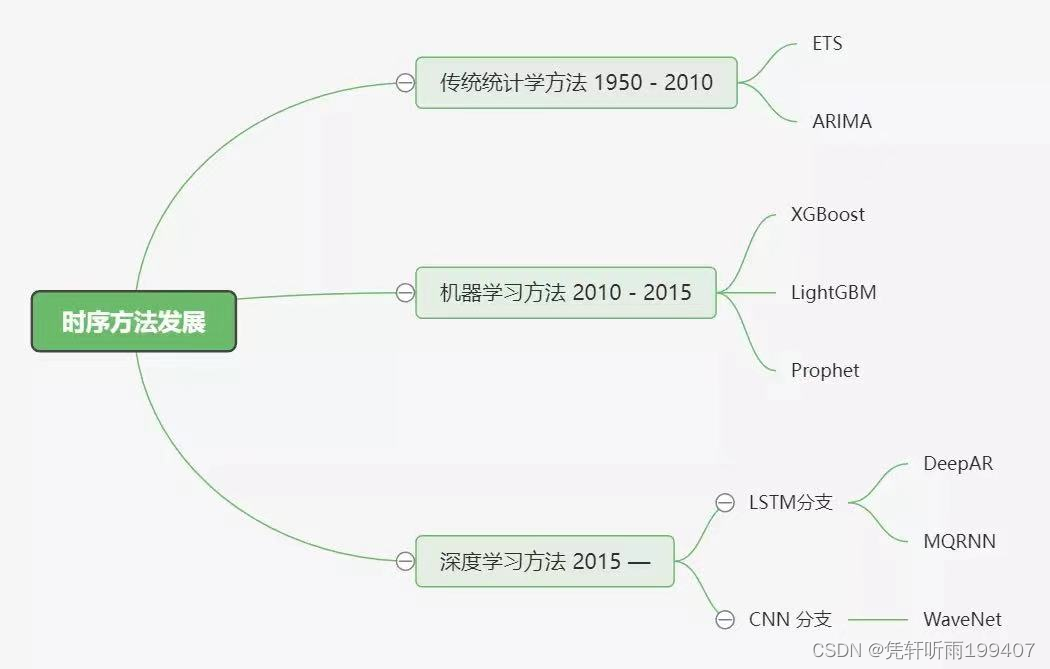
这部分应用场景可能有:
剩余寿命预测(电机)
异常预测预警
电池容量预测
产量销量预测
时间序列预测(如水分预测)
回归分析
决策协同模型
计划调度(如智能排产)
参数推荐(如注塑机控制)
KNN
REG-XGB LGB
优化控制
能耗优化(如蒸脱机控制)
工艺优化(如点焊路径规划)
控制优化(如空压机控制)
异常诊断
健康诊断
根因分析
缺陷分析
异常检测
状态监控(SCADA即可完成)
质量分析
图像
目标检测
表面缺陷检测
语义分割
eg:特殊颜色识别
关键点检测
图像匹配
匹配计数
3D抓取
零件的识别抓取
度量学习
异常检测
6D姿态估计
工业自动化、物联网通信
IOT
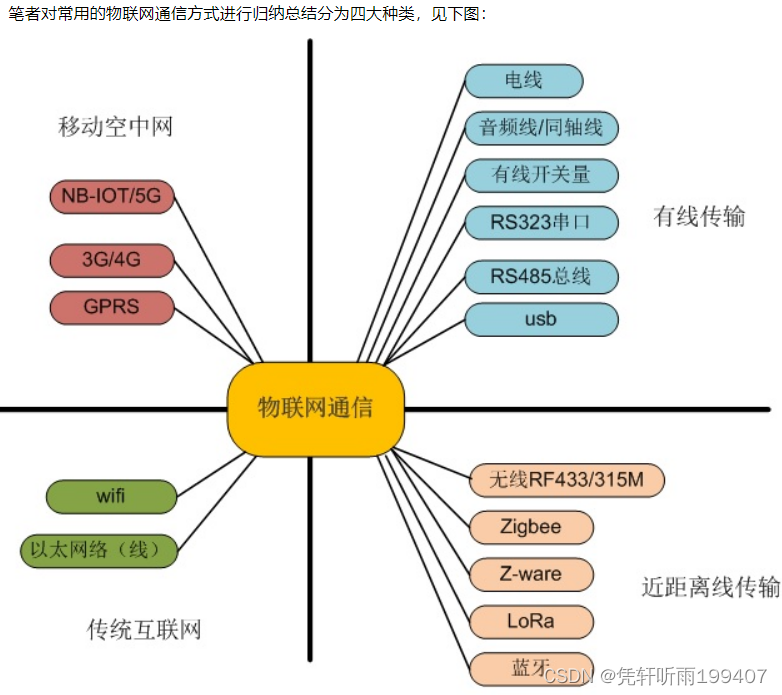
reference:
https://www.cnblogs.com/legahero/p/IOT.html
工业自动化
边缘计算
边缘设备的选型
如何选软硬件
1.服务器:CPU,几核,内存,硬盘,几张网卡,带宽要求等。
2.服务器操作系统:Windows?Ubuntu?centOS?
tricks
1.url
https://paperswithcode.com/
















 4135
4135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









