







手把手教你使用OpenCV,ONNXRuntime部署yolov5旋转目标检测
✨博主介绍
🌊 作者主页:苏州程序大白
🌊 作者简介:🏆CSDN人工智能域优质创作者🥇,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
💬如果文章对你有帮助,欢迎关注、点赞、收藏
💅 有任何问题欢迎私信,看到会及时回复
💅关注苏州程序大白,分享粉丝福利
学习旋转角度
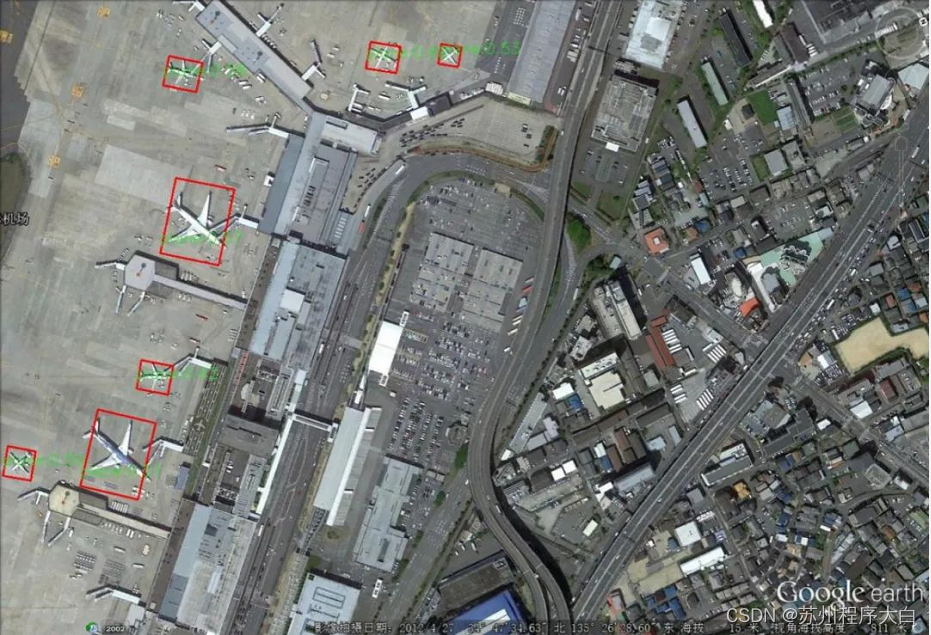
在无人机/遥感目标检测领域,拍摄到的物体通常是,如下图中红色矩形框里的飞机,这是用ultralytics/yolov5检测到的目标,很明显水平矩形检测框在检测旋转目标时,检测框里包含了无关背景区域,因此ultralytics/yolov5检测旋转目标,不是一个理想的解决方案。

在ultralytics/yolov5的检测头里添加一个学习旋转角度angle的分支,考虑到旋转角度是分布在0到180度之内的一个整数值,因此把旋转角度angle做为一个分类问题来学习。
这时模型输出的每一个候选检测框里的信息是 x,y,w,h,box_score,class_score,angle_score 这种形式的,其中x,y,w,h表示检测框的中心点坐标,宽度和高度,box_score表示检测框的置信度,class_score表示类别置信度,假如在coco数据集上训练的,coco数据集里有80个类别,那么class_score是一个长度为80的数组,它里面第i个元素表示第i个类别的置信度。angle_score表示倾斜角度的置信度,它是一个长度为180的数组,它里面第i个元素表示检测矩形框的倾斜角等于i度的置信度。那么这时检测框里包含信息的长度是5+80+180=265,这就使得yolov5的检测头里的最后3个1x1卷积的输出通道数也别大,这时无疑会增大模型的计算量。
我在github发布了一套分别使用OpenCV,ONNXRuntime部署yolov5旋转目标检测的demo程序,分别包含C++和Python两个版本的程序。程序输出矩形框的中心点坐标(x, y),矩形框的高宽(h, w),矩形框的倾斜角,源码地址是:https://github.com/hpc203/rotate-yolov5-opencv-onnxrun
在编写后处理NMS函数时,需要注意的一个问题是用C++编程实现计算两个旋转矩形框的重叠面积,实现细节可以参考源码。

学习旋转角度的余弦值
在第1部分里讲到学习旋转角度会存在的一个问题是:由于旋转角度是分布在0到180度之内的一个整数值,也就是说有180种取值的可能,把旋转角度作为一个分类任务,会使得yolov5的检测头里的最后3个1x1卷积的输出通道数也别大,这时会增大模型的计算量。注意到角度的余弦值是分布在-1到1之间的小数值,那么可以考虑学习旋转角度的余弦值和正弦值。如下图所示:

损失函数是SmoothL1Loss,示意图如下:

这时,模型输出的每个候选框里包含的信息是x,y,w,h, cos,sin, box_score,class_score这种形式的,其中cos表示检测矩形框的倾斜角的余弦值,sin表示检测矩形框的倾斜角的正弦值。假如在coco数据集上训练的,那么这时候选框的长度是4+2+1+80=87,很明显这时模型的计算量会减少很多。
程序输出矩形框的中心点坐标(x, y),矩形框的高宽(h, w),矩形框的倾斜角的余弦值和正弦值的GitHub源码地址
不规则四边形的目标检测
最近在极市平台的打榜项目里有车牌识别项目,项目里要求检测车牌的4个角点。可以仿照第1部分里的思路,在ultralytics/yolov5的检测头里添加一个学习四个角点的分支,这时,模型输出的每个候选框里包含的信息是 x,y,w,h, box_score, x1,y1,x2,y2,x3,y3,x4,y4, class_score这种形式,其中x1,y1,x2,y2,x3,y3,x4,y4表示4个角点的坐标值x和y。这时候的模型就能满足项目的需求,但是注意到水平矩形框的位置信息x,y,w,h在项目里并没有起作用,因此水平矩形框的位置信息是一个冗余的信息。
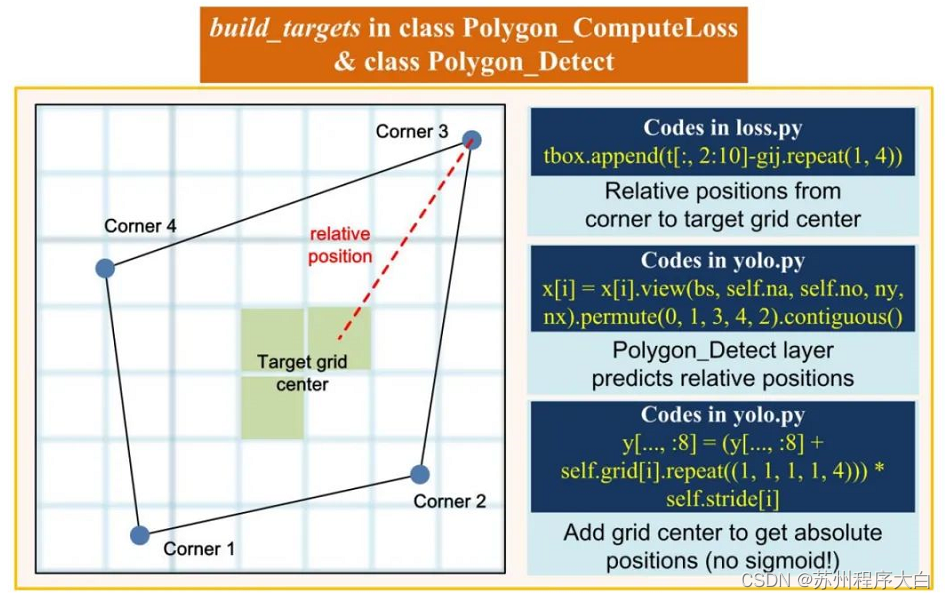
接着对模型继续做修改,使模型输出的是x1,y1,x2,y2,x3,y3,x4,y4,box_score,class_score,也就是去掉box分支,这时可以减小模型体积,减少计算量。修改的地方在yolov5的检测头和loss函数,图解如下:
build_targets函数和检测头Detect
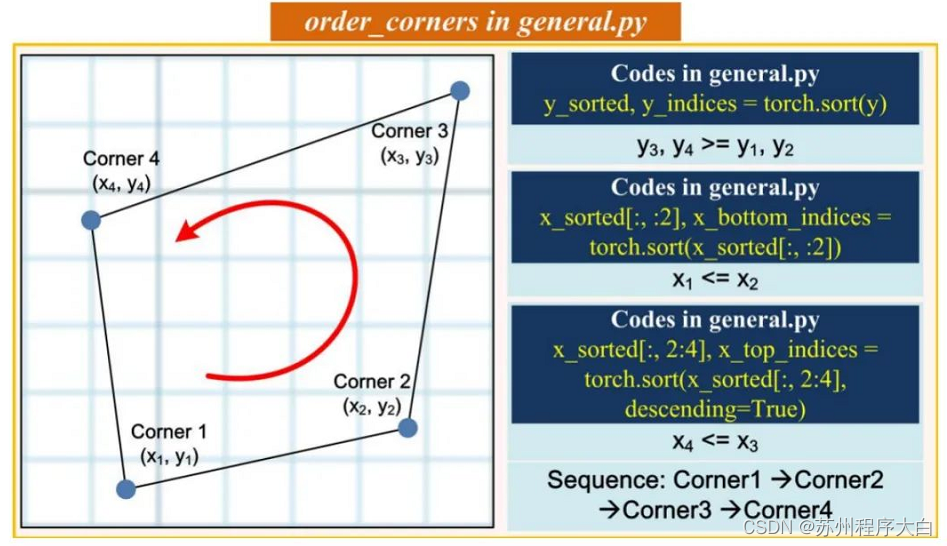
4个角点逆时针排序
polygon box loss

程序输出不规则四边形的4个角点的坐标x,y的源码地址
在编写后处理NMS函数时,一个棘手的问题是计算不规则四边形的面积,计算两个不规则四边形的重叠面积。如果是编写Python程序,可以直接调用shapely库解决,如果是编写C++程序,那就比较棘手了,C++编程实现的细节可以参考源码。

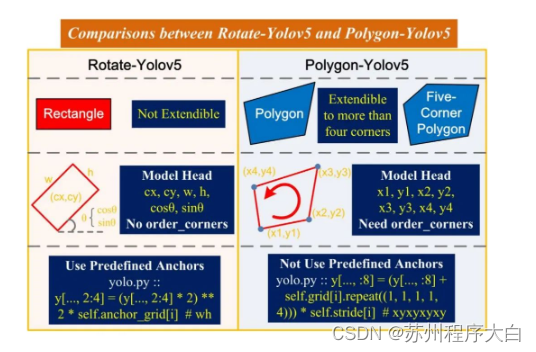
为了便于直观理解第2节里的旋转目标检测和第3节里的不规则四边形目标检测,它们的差异,图解如下:
💫点击直接资料领取💫
















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









