






本文以生成对抗网络为基础,提出了基于自注意力生成对抗网络人物姿态迁移模型。
自注意力是一种用于在序列数据中捕捉不同位置之间的关系和依赖性的注意力机制,它能让模型在处理序列数据时,根据序列中不同位置之间的相互关系,动态地分配不同位置的重要性权重。这使得模型能够更加有效地关注与当前位置相关的上下文信息,从而更好地捕捉到序列中的长距离依赖关系。
生成对抗网络(GAN)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)两个神经网络组成。GAN 的目标是通过训练生成器网络来生成与真实数据相似的合成数据,同时训练判别器网络来区分生成的合成数据和真实数据。生成对抗网络模型的结构如下图所示。

本文所提出的人物姿态迁移模型的目标是将条件图像Pc的姿态从条件姿态热图Se迁移至目标姿态热图St,然后生成一个非常逼真的图像Pg。
生成器
该模型的生成器的核心部分是姿态注意迁移网络(PATN), 它的主要目标是将一个人的姿态从一个图像中迁移到另一个图像中,实现姿态的转移。它能够学习两个图像之间的对应关系,并利用注意力机制来关注和对齐两个图像中的相关姿态部分。PATN包含两个关键组成部分:生成器和判别器。生成器通过编码器-解码器结构,将输入图像的姿态信息编码成低维表示,然后解码成目标图像的姿态。生成器使用注意力机制来对输入图像中的不同姿态部分进行对齐和转移。
PATN由多个姿态注意迁移blocks(PATBs)组成。从最输入开始的图像编码和关键姿态编码, PATN通过PATBs的序列渐进式地更新这两个编码的信息。在输出部分,最终输出的图像编码被用来解码输出图像,而最终的姿态编码则被丢弃。生成器结构如下图所示。

判别器
该模型的判别器是基于融合自注意力机制的 EfficientNetV2 判别器该进的,共提出了两种判别器改进方案。
1.以自注意力层处理图像输入
这种方案相当于将Transformer编码器进行n次堆叠的 网络作为输入图像的编码器,然后EfficientNet模块则作为卷积神经网络的框架对 Transformer层的输出解码成为最终的分类结果。

2.以卷积神经网络处理图像输入
这种方案首先使用EfficientNet模块对图像输入进行特征提取,然后将特征提取 出来的结果使用嵌入层将特征图切分成多个patch并转换成为Transformer编码器的输 入嵌入向量。第二步使用多层Transformer编码器对输入嵌入信息进行编码然后使用 Transformer分类头进行分类。整体的网络框架相当于使用卷积神经网络对原始输入提 取有效的语义信息,然后使用Transformer编码器对这些语义信息进行自注意力计算并输出最终分类。
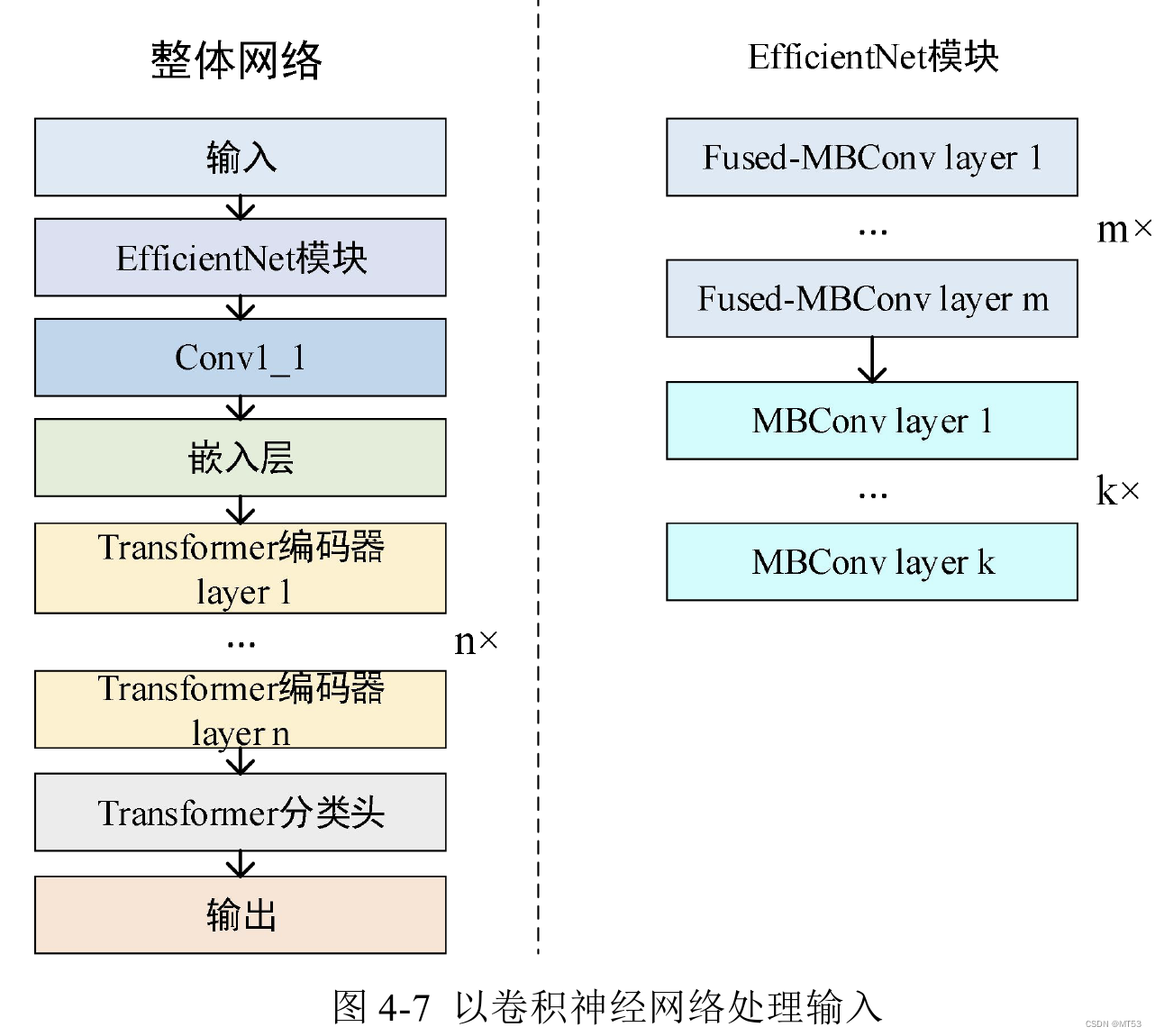
通过实验发现,以卷积神经网络为输入处理模块的模型不论是训练准确率、训练损失、测试准确率、测试损失还是参数量上均优于以自注意力机制为输入处理模块。
在选择以卷积神经网络作为输入预处理模块的基础上,该模型的判别器使用了两个融合自注意力机制卷积神经网络的判别器,分别是外观判别器(Appearance discriminator)和形状判别器(Shape discriminator),分别负责判断Pg在Pc中包含的人物相同的可能性,以及Pg与目标姿态的一致性。两个判别器拥有相似的结构,Pg会与Pc或者St在深度方向进行连接操作,再将其丢进融合自注意力机制卷积神经网络的判别器,最终输出对应的外观相关性分数RA和形状相关性分数RS,而整个判别器最终输出的分数为R = RA * RS。
















 3121
3121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









