






本文的作者公开了一个用于车对车感知的大规模开放式模拟数据集。该数据集包含 70 多个场景、11464 帧和 232913 个带注释的3D车辆边界框。作者还提出了一个名为Attentive Intermediate Fusion的管道框架,并使用不同的已实现的模型评估了不同的信息协同策略(早期、晚期和中期协同)。实验表明,作者提出的Attentive Intermediate Fusion框架可以轻松集成现有的3D激光雷达检测器,并且其精确度优于所有其他融合方法。
原文链接:https://arxiv.org/abs/2109.07644
车端传感器
CAM:照相机传感器,分布在车的前后左右,可 360 度拍摄四周图像进行感知;其坐标轴的建立包含XYZ三个方向,其中Y轴的正方向为垂直地面向下;
LiDAR:激光雷达传感器,分布在车的顶部,通过测量光脉冲到达目标并返回传感器所用的时间来进行感知。


下图中,绿色框内为主体车辆,蓝色框内为被感知到的车辆,红色框内为被遮挡的、无法感知到的车辆。在单车感知中,主体车辆无法检测到被遮挡的车辆。在协同感知中,根据其他车辆传输的信息,主体车辆能够有效感知被遮挡的物体以做出提前判断。


Attentive Intermediate Fusion架构
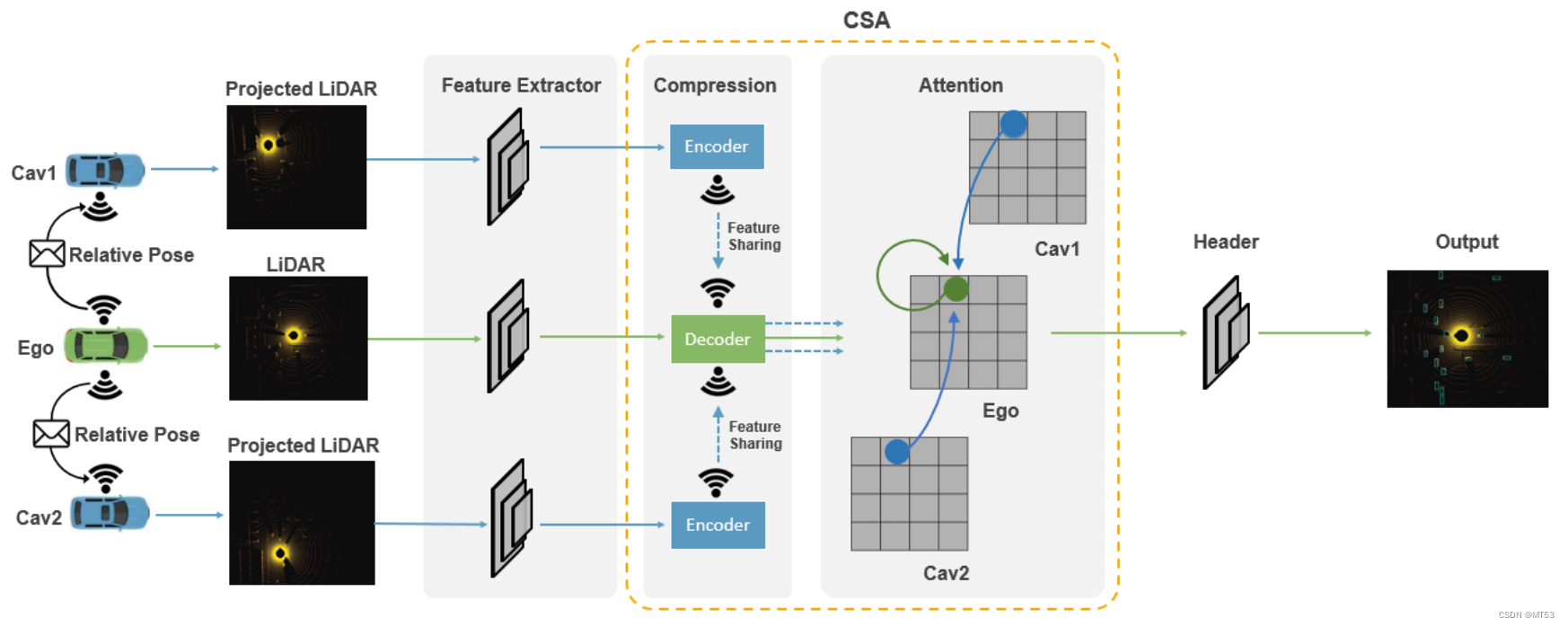
Attentive Intermediate Fusion架构(中间融合)过程如下:
- Ego接受Cav1和Cav2传输的数据;
- 将数据传入进行投影,对应出位置;
- 将位置图像传入特征提取器以提取图像中的特征;
- 将提取的特征进行编码,并传入解码器处进行整合,然后根据卷积神经网络进行解码并复原特征;
- 用加权相似度算法*得到相似度,并计算出评分;
- 将评分传入header层后,得到输出的预测图像。
(*加权相似度算法是一种用于计算两个数据集之间相似度的算法。该算法考虑了每个数据集中不同属性的权重,从而更准确地计算相似度。
该算法步骤如下:
- 对每个属性进行权重赋值(通常使用 TF-IDF算法来计算权重);
- 对于每组数据,将其各个属性的值乘以对应的权重,并将所有乘积存入一个一维列表中,将这个一维列表视为该组数据的加权向量;
- 使用余弦相似度(两个向量之间夹角的余弦值,取值范围为[-1,1])来计算两个数据集之间的相似度,值越大表示相似度越高;
- 将两个数据集的加权向量带入余弦相似度公式中,即可计算它们之间的相似度)
感知距离和边界框大小与云点数量的关系

左图为地面实况边界框内感知距离与汽车点3D云点数量的关系,包含单车感知与协同感知两种情况。在单车感知中,由于远处的车辆容易被近处车辆与路面设施遮挡,因此对远处车辆的感知效果较差,故远处物体的汽车云点特别稀疏;而在协同感知中,其他车辆能够提供远处被遮挡车辆的信息,因此远处车辆可以被感知,其远处物体的汽车云点密度也显著提高。 因此,这证明了V2V技术能够显著地增加感知范围,并将被遮挡的车辆信息提供给主感知车辆。
右图从上至下分别为边界框长度、宽度和高度与汽车3D云点分布的关系柱状图,密度分布越大则表明感知到的车辆越多,感知效果越好。由图可知,当边界框长度,宽度和高度分别为4.24,2.02和1.48时感知效果最好。
用于3D物体检测的PIXOR模型
为了评估提议的 AIF,原文作者的工作只需要将压缩、共享和注意 (Compress, Share, Attention, CSA) 模块添加到现有的网络架构中。 由于 4 个不同的检测器添加 CSA 模块的方式均类似,此处只展示与 PIXOR 模型的中间融合的架构。
PIXOR模型是一种点云的实时3D检测的方法,采用的是基于点云的输入数据格式,即将3D物体场景表示为稠密的点云数据。这种数据格式相比于传统的图像格式,能够更加精确地捕捉到物体的3D形状和空间位置信息,因此在3D物体检测中表现出了更好的效果。
PIXOR模型的主要思想是将3D物体检测任务分解为两个子任务:像素级别的物体分割和物体位置的精确定位。模型首先使用一个深度学习网络对点云数据进行像素级别的物体分割,然后再使用一个单独的神经网络来对每个检测到的物体进行位置的精确定位。
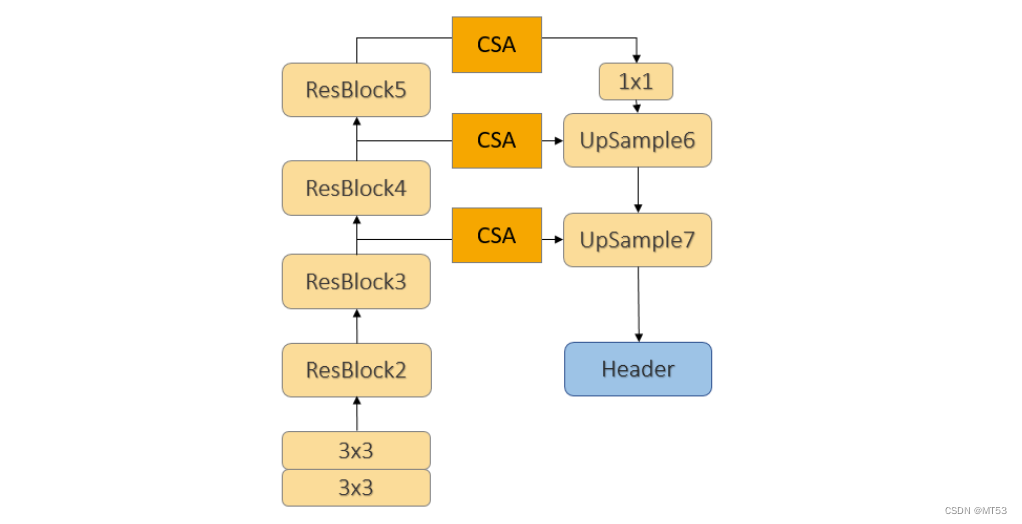
PIXOR架构工作原理如下:
- 输入点云数据由卷积神经网络处理并进行体素化以生成体积表示;
- 数据在被送入Attentive Fusion模块之前通过另一个 3D 卷积层;
- Attentive Fusion 模块接收 3D 卷积层从体素化数据中提取的特征,
- 将提取到的特征与相邻车辆的特征进行融合(这个融合过程由注意力机制引导,该机制学习关注来自邻近车辆的最有用的特征);
- 融合的特征通过多个 3D 对象提议和检测阶段以生成 PIXOR 模型的最终输出;
实验结果与分析


在实验过程中,作者在 Default CARLA Towns 和 Digital Culver City 的情境下,作者分别设定了0.5与0.7两种阀值(超过阀值的准确率则视为识别失败),使用了PIXOR,PointPillar,SECOND和VoxelNet模型,评估了早期、中期和晚期协同策略,最终得出了每一次试验的精确度结果。
作者发现,他们在前文提出的Attentive Intermediate Fusion 管道框架优于所有其他融合方法,即使在大压缩率下也能实现最先进的性能。 具体来说,在Default CARLA Towns和 Digital Culver City情境中,所提出的方法在精确度阀值为0.7 时比没有融合的对应方法的精确度高了10%。 除了 Culver City 的 PIXOR模型实验结果之外,与所有其他方法相比,中间融合在两个测试集上都取得了最佳性能。
作者认为,由于能够保留更多的传感测量和视觉线索,早期融合方法优于晚期融合方法。此外,值得注意的一点是 Digital Culver City 的预测结果普遍不如 Default CARLA Towns。 这种现象是预料之中的,因为 Digital Culver City 的交通模式更接近现实生活,这会导致与训练数据的域差距;此外,作者是在非常繁忙的时段收集的 Digital Culver City 数据,繁忙的路况环境会导致非常严重的遮挡,使检测任务非常具有挑战性。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









