






 论文关注于提升自动驾驶系统的容错能力,特别是视觉感知部分。通过采用生成式对抗网络(GAN)进行视频帧预测,改善了图像感知的容错性能。作者提出了新的卷积特征损失函数和改进的金字塔结构,以减少图像生成的模糊问题和提高实时预测效率。此外,还介绍了一个基于GAN的虚拟视觉生成框架,增强双目视觉系统的鲁棒性。
论文关注于提升自动驾驶系统的容错能力,特别是视觉感知部分。通过采用生成式对抗网络(GAN)进行视频帧预测,改善了图像感知的容错性能。作者提出了新的卷积特征损失函数和改进的金字塔结构,以减少图像生成的模糊问题和提高实时预测效率。此外,还介绍了一个基于GAN的虚拟视觉生成框架,增强双目视觉系统的鲁棒性。
论文标题:基于生成式对抗网络(GAN)的自动驾驶容错感知研究
原文链接:基于生成式对抗网络(GAN)的自动驾驶容错感知研究 - 中国知网
本论文探讨了视频帧预测在图像感知容错和端对端的强化学习框架中的应用。重点研究了感知预测模型,提高了自动驾驶系统的容错能力。图像感知模块的输入是一个超高维的状态空间,本论文通过新的图像生成网络完成图像状态空间的转移并生成动态后的图像,同时将经过预测的图像作为当前有问题图像的先验和补充,或者作为端对端强化学习框架中的输入,实现了感知层面的容错和前馈。
自动驾驶系统通常包括以下几个方面的感知:
-
视觉感知:使用摄像头和图像处理技术,对道路、交通标志、车辆、行人等进行识别、跟踪和分析。
-
雷达感知:使用雷达传感器,测量周围环境中的物体距离、速度和方向,用于障碍物检测、跟踪和避障。
-
激光雷达感知:使用激光雷达传感器,通过发射激光束并测量其返回时间和强度,生成环境的三维点云数据,用于地图构建、障碍物检测和定位。
-
超声波感知:使用超声波传感器,测量车辆周围的距离和障碍物,用于低速行驶和近距离避障。
-
GPS/惯性导航感知:使用全球定位系统(GPS)和惯性测量单元(IMU),获取车辆的位置、方向和速度信息,用于定位和导航。
在这其中,自动驾驶的视觉感知是一个视频预测问题,视频预测的输入是过去时间序列的若干帧图像,预测的输出是未来若干帧图像。视频预测包括两个子模块:无监督预测和图像生成。无监督预测学习视频间的动态关系以及机理,图像生成学习图像特征的内部表示,从而重建图像。
本文作者在前人提出的图像金字塔特征提取和生成式GAN网络训练框架的基础之上,添加了新的卷积特征损失函数,改善了生成图像模糊的问题。同时还对生成器网络中传统的金字塔结构提出改进,建立卷积特征共享层,减少参数和计算量,从而减少了测试阶段的图像生成时间。该框架的生成器如下图所示。
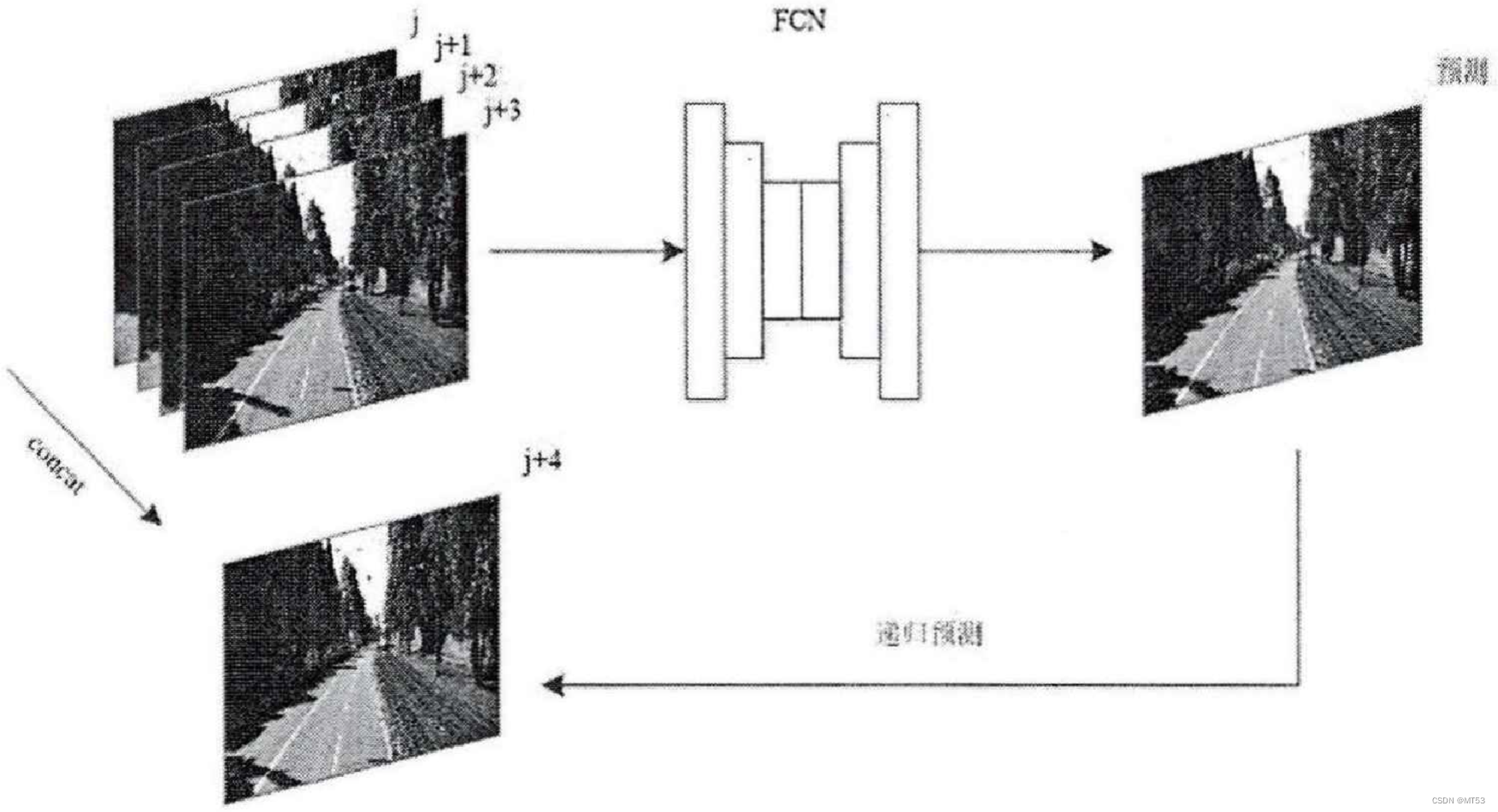
Xi = {Xij, Xi(j+1), ... Xi(j+m)} 表示生成器网络的输入,其中 i 表示第 i 个样本,j 表示第 j 帧图像。将输入的图像传入全卷积神经网络(FCN)后,FCN会返回其对输入图像的预测结果。输入图像通过沿着通道维度叠加后形成张量,输出是预测图形的张量,中间通过多层卷积操作连接。因为输入输出的图像分辨率需要保持一致,所以在卷积过程中除去常用的池化层,保留了图像的高频信息。本框架采用了循环预测的方式,即生成的预测图像会继续作为输入添加到下一帧的预测中。
此外,作者在生成对抗网络和金字塔结构的基础模型上,添加了卷积特征损失函数,提高了图片的生成质量。同时为了能使本网络无缝嵌入到自动驾驶系统容错模块中并生成实时的感知预测,作者改进了金字塔的结构,将原本从输入层开始的多尺度改进为从中间卷积特征层开始的半多尺度。修改后的生成器网络在没有特别影响性能的情况下拥有更快的测试速度。
双目视觉系统是智能汽车常用的传感器,为提高双目视觉系统的鲁棒性,提出了一种基于生成对抗网络的虚拟视觉生成框架,该框架的结构如下。

生成器由八个编码层和八个解码层组成,并且由八个跳越层连接。编码器可以对传入的特征进行编码,而解码器用于解码后的输出;跳跃层可以使解码层通过跳转连接与高层特征相结合,保证特征的多样性,也使得生成网络在不增加编码网络的参数数目和解码网络的计算复杂度的情况下获得更为鲁棒的性能。
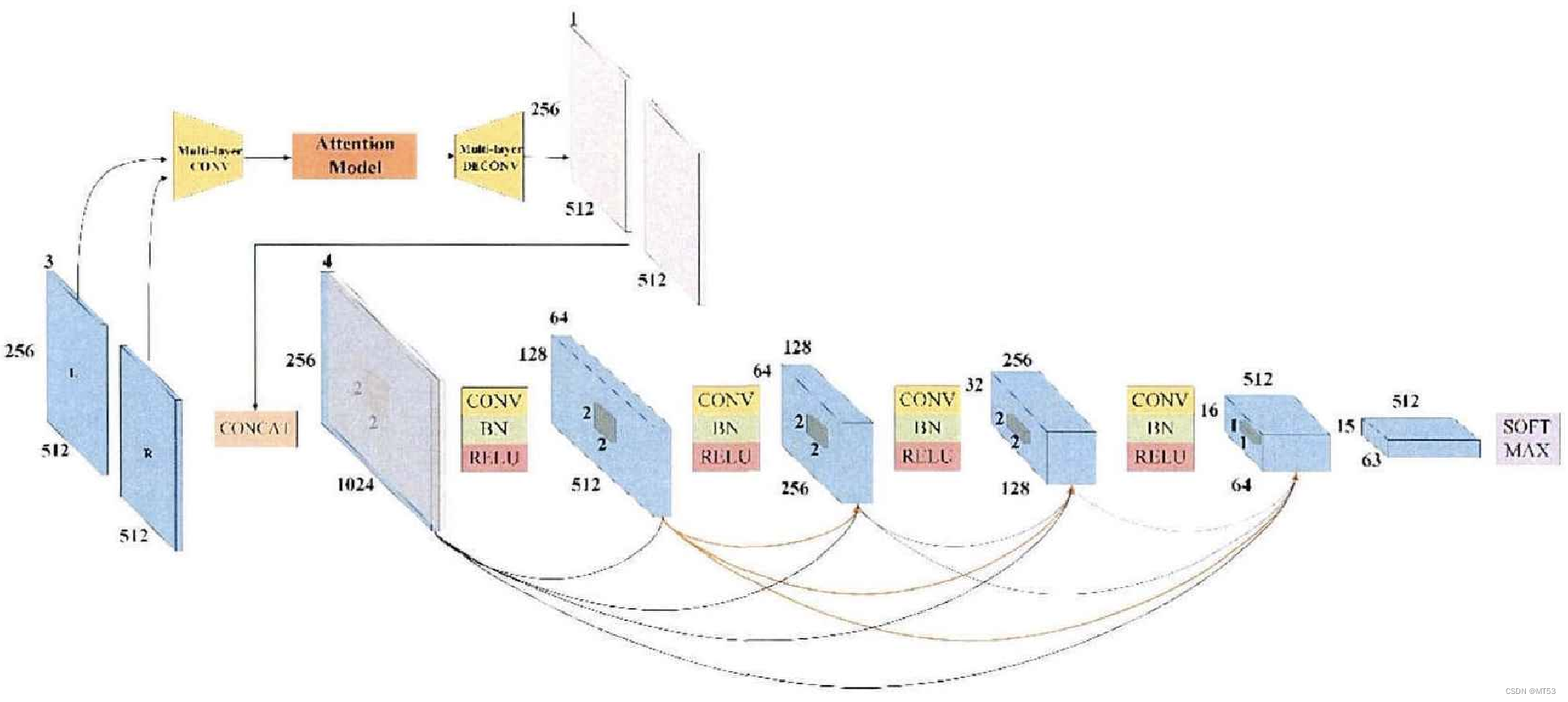
判别器由两个子网络组成,分别是Attention网络和Dense网络,如上图所示。该网络利用传统的CNN结构进行特征提取,用以获得图像相似度的概率。Dense网络的结构主要由五个普通卷积层和四个DenseBlock组成。DenseBlock的思想是将上层网络所有输出都作为本层的输入,能够保持各层特征映射在不丟失的情况下被后续卷积层学习到,从特征层面解决模型梯度消失的问题,并提高模型的判别能力。


















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









