






 本文介绍了一种新的离散提示优化框架EVOPROMPT,它将大型语言模型与进化算法相结合,自动化提示生成过程,显著提升了在多项任务中的性能,特别是在Big-BenchHard上达到25%的改进。
本文介绍了一种新的离散提示优化框架EVOPROMPT,它将大型语言模型与进化算法相结合,自动化提示生成过程,显著提升了在多项任务中的性能,特别是在Big-BenchHard上达到25%的改进。
论文标题: CONNECTING LARGE LANGUAGE MODELS WITH EVOLUTIONARY ALGORITHMS YIELDS POWERFUL PROMPT OPTIMIZERS
翻译: 将大型语言模型与进化算法连接起来,可以产生强大的提示优化器
摘要
大型语言模型(llm)擅长于各种任务,但它们依赖于精心制作的提示,这些提示通常需要大量的人力。
为了使这一过程自动化,在本文中,我们提出了一个新的离散提示优化框架,称为EVOPROMPT,它借用了进化算法(EAs)的思想,因为它们表现出良好的性能和快速收敛。
为了使ea能够处理离散的提示,这些提示是需要连贯和人类可读的自然语言表达式,我们将llm与ea连接起来。这种方法使我们能够同时利用llm强大的语言处理能力和ea的高效优化性能。
具体来说,EVOPROMPT避免了任何梯度或参数,它从提示符的种群开始,并基于进化算子迭代地使用llm生成新的提示符,根据开发集改进种群。
我们对包括GPT-3.5和Alpaca在内的封闭和开源LLMs在31个数据集上的提示进行了优化,这些数据集涵盖了语言理解、生成任务以及BIG-Bench Hard (BBH)任务。EVOPROMPT显著优于人工设计的提示符和现有的自动提示符生成方法(例如,在BBH上高达25%)。此外,EVOPROMPT表明,将llm与ea相结合可以产生协同效应,这可以激发对llm与传统算法结合的进一步研究。
代码:https://github.com/beeevita/EvoPrompt
自动离散提示优化
算法结构:

当前先进的llm通常通过黑盒api进行交互,而梯度和参数是不可访问的。进化算法(EAs)是一种无导数的算法,具有优异的精度和快速收敛性。因此,我们考虑在离散提示优化中引入ea。然而,为了生成新的候选解,进化算子通常独立地编辑当前解中的元素,而不考虑它们之间的联系。这使得在离散提示符上应用进化算子具有挑战性,这需要连贯性和可读性。
为了应对这一挑战,我们提出了一种协同方法,将法学硕士的自然语言处理专业知识与ea的优化能力联系起来,称为EVOPROMPT。
具体而言,llm基于进化算子生成新的候选提示,而ea则指导优化过程以找到最优提示。
由llm(算法1中的Evo(·))实现的GA过程如下。在步骤1中,llm对给定的两个提示(橙色和蓝色的单词分别继承自提示1和提示2)进行交叉。在步骤2中,llm对提示符执行突变。

为了在实践中实现EVOPROMPT,需要使用特定的ea算法对其进行实例化。ea有多种类型,在本文中,我们考虑了两种广泛使用的算法,包括遗传算法(GA) 和差分进化(DE) 。遗传算法是最受推崇的进化算法之一,DE自诞生以来已成为复杂优化挑战中应用最广泛的算法之一。在下文中,我们将首先概述提议的EVOPROMPT,然后分别使用GA和DE实例化EVOPROMPT。
evoprompt框架
EA通常从N个解的初始种群开始,然后使用进化算子(例如,突变和交叉)在当前种群上迭代地生成新的解,并基于适应度函数更新它。根据典型的EA, EVOPROMPT主要包含三个步骤:
- 初始种群:与大多数现有的自动提示方法忽略人类先验知识相反,我们使用可用的手动提示作为初始种群,以利用人类的智慧。此外,ea通常从随机解开始,导致种群多样化,避免陷入局部最优。因此,我们还将llm 生成的一些提示符引入初始种群。
- 进化:在每次迭代中,EVOPROMPT使用llm作为进化算子,根据从当前种群中选择的几个父提示生成新的提示。为了实现这一目标,我们为每种特定类型的EA设计了突变和交叉操作符的步骤,以及指导llm根据这些步骤生成新提示的相应说明。
- 更新:我们在开发集上评估生成的候选提示,并保留那些性能优越的提示,类似于自然界的适者生存。具体的更新策略可能因所使用的ea类型而异。
当迭代次数达到预定义值时,算法停止。算法1概述了EVOPROMPT的细节。当使用特定的EA算法实例化EVOPROMPT时,需要调整进化过程,其中关键的挑战是在离散提示上设计进化算子。
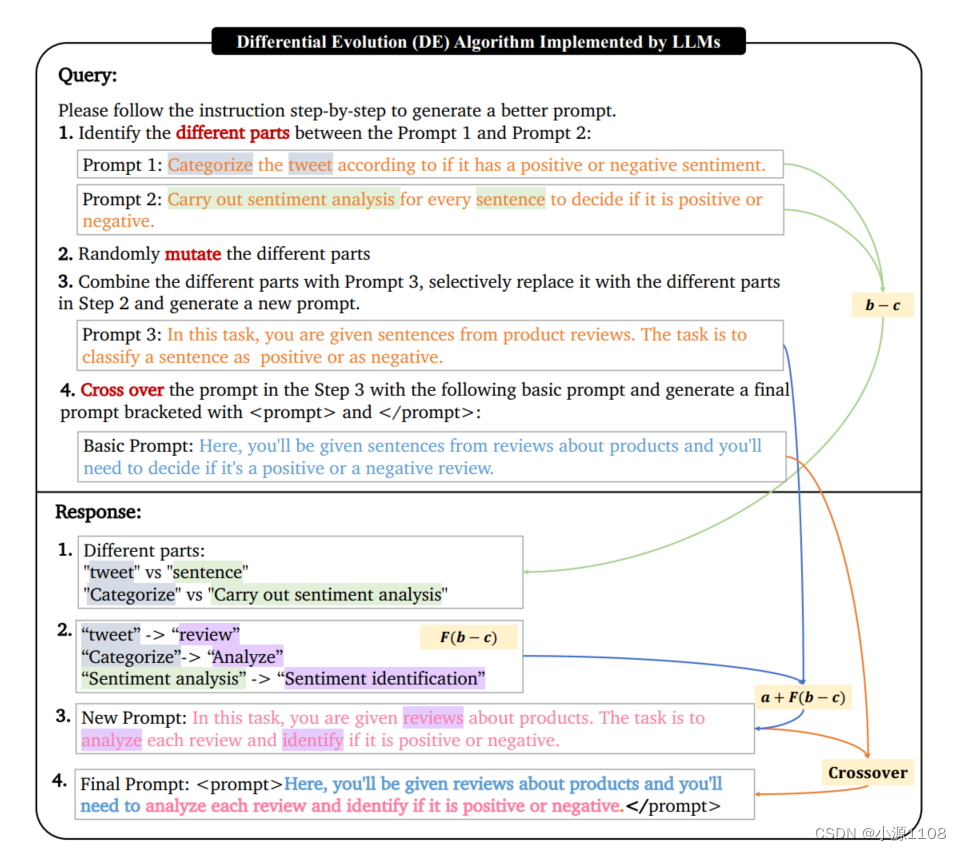
由llm实现的DE过程(算法1中的Evo(·))。
在步骤1中,llm找到提示1和提示2(典型DE中的b−c)之间的不同部分(不同颜色标识的单词)。
在步骤2中,llm对它们执行突变(颜色标识的单词)(模仿F(b - c))。
接下来,llm将当前最佳提示符作为提示符3与步骤2中的突变结果合并,以生成新的提示符(DE中的a + F(b−c)对应)。
最后,llm对当前基本提示pi和步骤3中生成的提示符进行交叉。
用遗传算法实例化
- 选择 在遗传算法中,通常使用轮盘赌选择方法选择父解,并以其适应度值为指。类似地,我们使用轮盘选择从当前总体中选择两个父提示,基于它们在开发集中获得的性能分数。
- 进化 根据遗传算法框架,我们通过两个步骤生成一个新的候选提示:1)在父提示之间进行交叉,产生一个新的后代提示,该后代提示继承了双亲的特征;2)突变应用于后代提示,对某些元素引入随机改变。我们将这两阶段的操作形式化为算法指令,以指导llm在算法1中实现Evo(·)。
- 更新 我们采用一种简单的选择策略来更新种群:在每次迭代中,EVOPROMPT产生N个新提示,这些提示与N个提示的现有种群合并。随后,根据得分,保留前N个提示以形成更新的总体。因此,人口的整体素质不断提高,最终在最终人口中选出最优的一个作为最优提示。
具有差分进化的实例化
与遗传算法不同,DE的解由数值向量表示。依次选择种群内的每个载体作为基载体,记为x,随后进行突变和交叉。
在突变过程中,从当前种群中随机选择的解a产生突变解y。突变是通过将两个不同的随机选择的解b和c之间的缩放差添加到a中来实现的,即y = a + F(b - c),其中F是缩放参数。
交叉是生成一个试解x’ = [x’1,…x’ n]通过从基本解x或突变解y中选择向量中的每个参数。然后,如果x '优于x,则将x替换为x '。在逐步进化中,DE以高质量的种群结束。改进版DE使用当前最佳解作为向量A,从最佳解中获取信息。
进化 DE的演化过程可以解耦为三个步骤:
- F(b−c);
- y = a + F(b−c);
- x和y的交叉。
在基于DE的EVOPROMPT中,我们按照三个步骤来设计进化过程,以及llm根据这些步骤生成新提示符的相应指令,由llm实现的DE过程。
- 受DE中的差分向量的启发,我们考虑仅对当前种群中随机选择的两个提示符的不同部分进行突变(上图的步骤1和步骤2) 。当前种群中的提示符被认为是当前最好的提示符。因此,两个提示的共享组件往往对性能有积极的影响,因此需要保留。
- 变异DE在变异过程中使用当前最佳向量,将微分向量的尺度加到当前最佳向量上生成突变向量。在这个想法的基础上,我们通过选择性地用突变的不同部分替换当前最好的部分来生成一个突变的提示符进行组合。(图中的步骤3)。
- 交叉用来自突变提示的片段替换基本提示(即当前种群的候选)的某些组成部分。此操作结合了两个不同提示的特性,可能创建一个新的改进的解决方案(图中的步骤4)。
更新 按照标准DE,依次选择当前总体中的每个提示pi作为基本提示,使用图2中的指令生成相应的新提示p’i。然后,分数较高的提示符(pi或p’i)将被保留。因此,人口规模保持不变,而人口的整体素质得到提高。
实验
实现细节和BASELINES
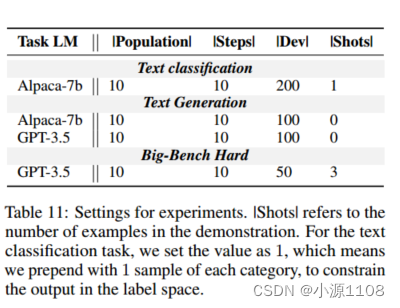
使用GPT-3.5执行进化算子,我们使用EVOPROMPT优化了开源的Alpaca-7b 和闭源的GPT-3.5的提示符。我们选择开发集中得分最高的提示,并在测试集中报告它的得分。羊驼报告的结果是3个随机种子的平均值,并提供了标准差,而对于GPT-3.5,由于预算限制,我们报告了一个种子的结果。在我们的评估中,我们将EVOPROMPT与三类基于提示的方法进行了比较,具体如下:
- Manual Instructions (MI):这些是特定于任务的指导方针,是基于已建立的作品制作的,特别引用了Zhang等人的语言理解,Sanh等人的摘要,Zhang等人的文本简化。
- PromptSource和Natural Instructions (NI):这些存储库在各种数据集上聚合了人工编写的提示。
- APE和APO: APE采用迭代蒙特卡罗搜索策略,强调探索。我们复制它并初始化与EVOPROMPT相同大小的种群。APO将错误预测的实例作为“伪梯度”加以利用,迭代地改进原始提示,强调利用。我们以最优手动提示符作为初始提示符,在二元分类任务上重现APO。
Alpaca-7b的语言理解(准确度)的主要结果。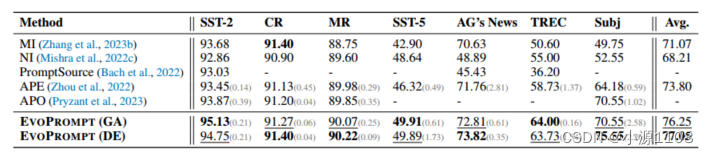
Alpaca-7b和GPT-3.5在SAMSum数据集(汇总任务)上的主要结果。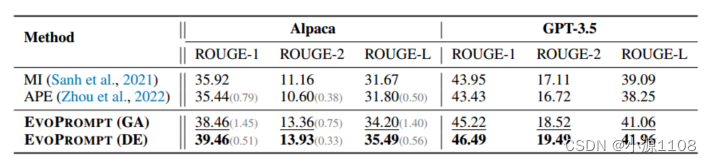
语言理解
数据集和设置 我们首先对跨7个数据集的语言理解任务进行实验来验证我们的方法,包括情感分类(SST-2,MR, CR, SST-5) ,主题分类(AG 's News ,TREC)和主观性分类(Subj)。为了约束输出标签空间,我们在测试用例之前添加由每个类一个示例组成的演示。详见附录B。
主要结果 表1显示:
1)与之前在提示符生成和人类书面指令方面的工作相比,基于GA和DE的EVOPROMPT都取得了明显更好的结果。
2)在情感分类数据集上,EVOPROMPT (GA)略优于EVOPROMPT (DE)。当涉及到主题分类数据集时,EVOPROMPT (DE)表现更好。
3)在主观性分类任务(Subj)上,EVOPROMPT (DE)比GA有了实质性的改进,实现了5%的准确率优势。这可能是由于DE在初始提示质量不高时规避局部最优的特殊能力造成的。
语言生成
数据集和设置 对于语言生成,我们在文本摘要和简化任务上评估我们的EVOPROMPT。为了进行总结,我们采用了SAMSum,这是一个具有挑战性和复杂的对话总结数据集,并报告了ROUGE-1/2/L在Alpaca-7b和GPT-3.5上的得分。对于文本简化,其目的是在保留原始含义的同时简化源文本,我们使用ASSET数据集,这是一个以其多个参考翻译而闻名的基准。我们使用SARI分数作为评估指标,这是一种基于n-gram的评分系统,广泛用于文本编辑任务。
关于我们的实验设置的更多细节可以在附录B中找到。
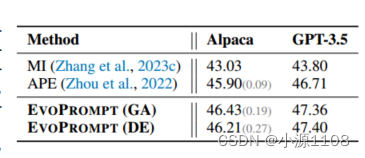
主要结果 总结和简化结果如表2和表3所示。与手动设计的提示器相比,EVOPROMPT实现了显著的性能提升,在Alpaca和GPT-3.5 API中,其SARI得分都提高了3分以上。此外,EVOPROMPT在评估场景中始终优于APE方法,这表明生成的提示可以有效地利用llm的功能来实现卓越的性能。
此外,EVOPROMPT (DE)在摘要任务中明显优于EVOPROMPT (GA),而在文本简化任务中表现出相当的性能。这表明DE变体对于更复杂的语言生成任务(如摘要)特别有效。
Alpaca-7b和GPT3.5简化(ASSET)的主要结果(SARI):
BIG BENCH HARD (BBH)
数据集和设置 为了在不同的任务上验证我们的方法,我们应用了BBH,包括一套23个需要多步骤推理的具有挑战性的BIG-Bench任务。由于这些任务具有挑战性,我们专注于优化GPT-3.5的提示。我们从测试集中抽取一个子集作为开发集,并报告与提示“让我们一步一步地思考”相比较的标准化得分1。Kojima并在测试集上进行了三次思维链演示。我们使用任务id来简化每个任务的表示,并删除一个任务,因为手动提示的准确率已经达到100%。详见附录C.2和表17,以及与以往作品的进一步比较。
主要结果 EVOPROMPT对所有22个任务都获得了更好的提示(图3) 。具体来说,EVOPROMPT (DE)实现了高达25%的改进,平均为3.5%,而EVOPROMPT (GA)达到了15%的峰值改进,平均为2.5%。尽管对于某些任务,GA版本优于DE版本,但性能差距仍然相对较小(即大约1%) 。
同时,EVOPROMPT (DE)在6个任务上超过EVOPROMPT (GA)超过2%。因此,对于这些具有挑战性的任务,DE版本通常是一个很好的选择。
附录B 实验设置
数据集
表7显示了文本分类、简化和摘要数据集的统计数据。对于Big-Bench Hard,我们使用序列号来表示22个任务,描述如表17所示。
请注意,对于“谎言之网”任务,基线的准确率为100%,所以这里我们没有包括这个任务,以便及时优化。此外,“逻辑推理对象”和“跟踪洗牌对象”任务都有三个子任务。
本工作中使用的自然语言理解和生成数据集的统计数据:
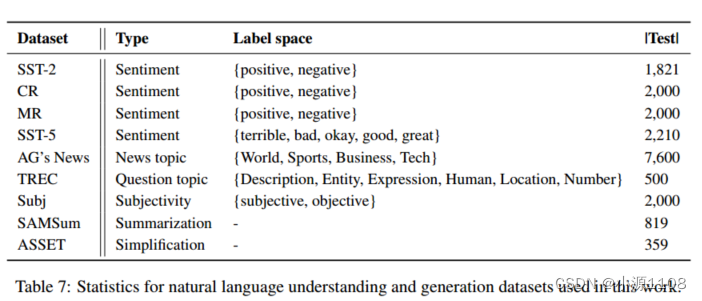
在BBH数据集上由EVOPROMPT (DE或GA)生成的GPT3.5上性能最佳的指令。重复的id是由于具有多个子任务的任务: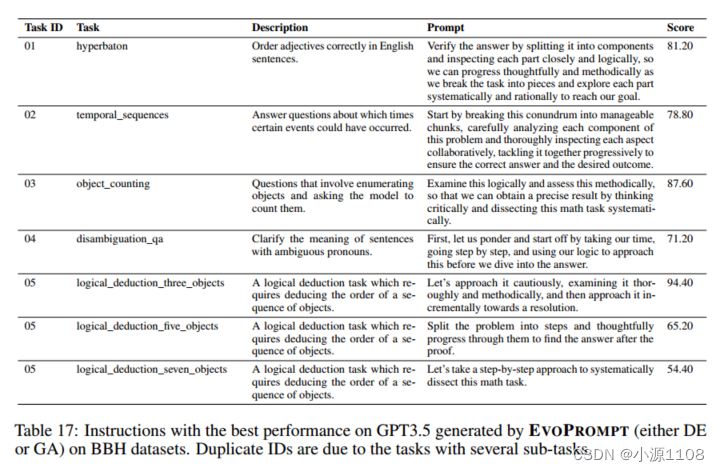
模板
任务实现模板 对于不同的模型,参考前面的工作,我们应用了不同的模板,如表8、9、10所示
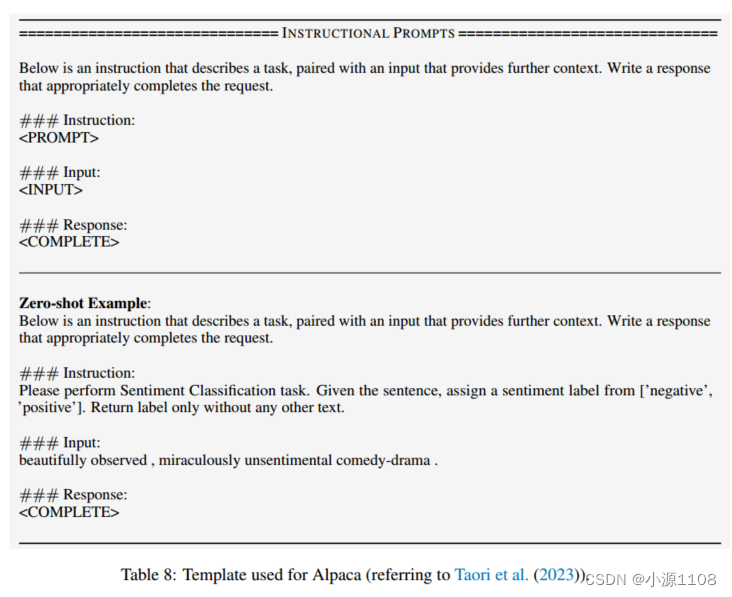
提示符生成模板 我们应用重新采样模板(如图4所示)来生成手动初始提示的变体。对于我们的EVOPROMPT, llm实现的完整DE算法如图5所示。对于DE和GA,我们都预先提供了算法执行的一次示例,指导llm精确操作。

图5:由llm实现的具有完整响应的离散提示优化DE算法(算法1中的Evo(·)) 。在步骤1中,llm找到提示1和提示2(典型DE中的b−c)之间的不同部分(彩色中的单词)。在步骤2中,llm对它们执行突变(彩色中的单词)(模仿F(b - c)) 。接下来,llm将当前最佳提示符作为提示符3与步骤2中的突变结果合并,以生成新的提示符(DE中的a + F(b−c)对应)。
最后,llm对当前基本提示pi和步骤3中生成的提示符进行交叉。

超参数
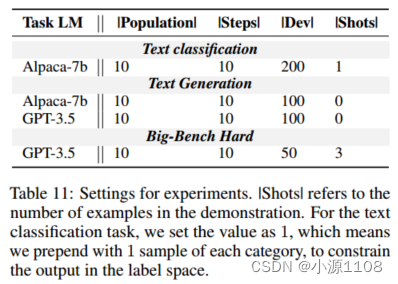
实验参数如表11所示。对于由GPT-3.5实现的进化算法,根据之前的工作,我们使用Top-p解码(温度=0.5,P = 0.95) 。对于任务实现,我们使用greedy decoding和Alpaca的默认温度。对于GPT-3.5实现的生成任务,温度为0.0。
文本分类
提示符的种群是用先前作品中广泛使用的指令初始化的。我们改写它们来初始化人口。开发集的大小为200。我们报告了完整测试集的结果(与之前的相关工作相同),见表11。
实验设置。|Shots|指的是演示中例子的数量。对于文本分类任务,我们将值设置为1,这意味着我们在每个类别的前面加上1个样本,以约束标签空间中的输出。
文本生成
对于初始种群,我们收集了Li等人的总结和简化说明;Sanh等;Zhang等
并将它们扩展到预期的大小(在我们的设置中为10),可以手动编写或由GPT-3.5生成。

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









