






Concurrency and Synchronization
duke
个人学习笔记,希望能得到更多交流。
<–more–>
Lecture 2
what is multi-programming?
multiple programs running simultaneously on one CPU. 多个程序同时在一个CPU上跑
what is process?
Unit of allocation 分配的单元
what is thread?
Unit of execution 处理的单元
每一个process可以有多个threads,每一个thread都属于一个process
会有多一个units of execution,我们想要他们share a single pool of resources
操作系统提供了illusion of isolated machine access (virtualization)
如何创建出多个processors的假象?
- multiplex threads in time on the CPU (or CPUs) 各种线程
- each “virtual CPU” needs a structure to hold: (PC, SP, registers)
- 如何把virtual CPU转移到下一个?(save当前的PC, SP和寄存器在current state block, load PC, SP和寄存器从new state block里)
- 什么触发了context switch(转移到下一个CPU): timer, voluntary yield, I/O, other things
Process Execution
A process is created by OS via system calls,process是被OS通过system call创建的
fork: make excat copy of this process and run 创建copy并且运行
- form parent and child relationship between old and new process 形成老新进程之间的父子关系
- return value of fork indicates the difference fork的返回值表示差异
- child return 0, parent returns child’s PID 子进程return0,父进程return子进程的PID
A process may also create and start execution of threads by system call or using a library.进程可以创建和执行线程通过syscall或者使用lib。
Concurrent Program
并发程序指多个线程同时执行,有多种方式
- 时间分片:在一个CPU上,具有一个硬件线程。这意味着CPU会在多个线程之间切换执行,每个线程运行一小段时间(时间片)。time-slice,上课时的例子,一条线上的切换
- 同一时间在单个CPU上的多个硬件线程:这通常是指像Intel的超线程技术,一个CPU核心可以同时执行多个线程。
- 在多个CPU上的多个硬件线程:这涉及到多个CPU核心,每个核心可能有一个或多个硬件线程,这是多核处理器或称为对称多处理器(SMP)系统。
线程之间通过协作完成任务。
线程之间如何交流?
- recall they share a process context,他们共享一个进程,code,static data,heap
- read and write same memory读写相同内存
Concurrent Processing

Concurrent Executions
例子:有两个thread,都是想给变量x加上1: x = x+1
那期待的结果应该是x=2
- 但是由于execution是OS并行的,所以我们并不知道那个先操作
- What may appear as a single instruction is indeed a set of machine-dependent steps at a lower abstraction level 在较低的抽象层次上,看似一条指令的东西实际上是一组与机器相关的步骤
A correct Computation

进程和线程的schedule是cpu在OS上执行的,所以没有prediction可以made当context switches are done
这种情况就是可以出现正常结果的
但是每个thread的三步也可能不是在一起进行的,假如是分开的就可能会出现不对的情况,如下

Remember registers are not shared. Only x is shared. 这就是为什么最后的结果是1。
Serializability 可串行性
如果并发的操作调度产生的结果(状态)可以通过完全顺序的执行产生,那么它(在一般意义上)就是可序列化的
A concurrent schedule of operations (in a general sense) is serializable if it produces a result (state) that can be produced with a fully sequential execution
Race Conditions
以上这些例子发生的原因就是race condition的存在
what is race condition: result of computation by concurrent processes/threads depends on the precise timing of the execution of the sequence of instructions of one thread relative the others 并发进程/线程的计算结果取决于一个线程相对于其他线程执行指令序列的精确时间
这导致了有时候结果是正确的,有时候是错的,这是无法预测的,所以需要避免着这种情况。
how to deal with race conditions
- wait long enough, the other thread will finish
- use
sleep()for waiting and avoiding interference
但是使用delay只能hide这个问题,不能彻底的解决这个问题
这个问题的本质是:
- problems of multiple processes of threads performing read/write ops on shared data (variables, array locations, objects)
Those parts of the computation that act on shared variable and that can generate non-serializable executions are called critical sections 就是这些act on shared variable 和generate在non-serializable execution被叫做critical sections
- Critical section is each set of operations we want to be executed atomically, i.e., as if they were a single operation, with no interruption
- A program may have several critical sections
Synchronizing Process/threads
Critical SectionsConcurrent threads can synchronize by making their progress conditional to the state of special shared variables that protects the access to the critical section
- Before executing instructions in the critical section, a thread of execution checks the variable that protects the section
- The value of the variable indicates whether another thread of execution is inside (i.e., executing) the critical section or not
- When a thread of execution is inside the critical section, no other thread will be allowed to enter the critical section.
- When a thread of execution completes the execution of the critical section, it changes the value of the variable to signal that access is allowed.
比如通过flag,monitors,semaphores来判断后面能不能使用或者正常的execution。
Lecture 3
Semaphores
旗语 semaphores are variables used to solve critical section problems and to achieve process synchronization in multi-processing environments. 信号量是在多进程环境中用于解决临界段问题和实现进程同步的变量。
本质来说就是一个计数器,计数器为正数的时候,如果线程要求获取semaphore,就同意,并且计数器递减。当线程结束释放信号量并增加计数器。
假如semaphore的初始值是N,那就最多允许N个线程并发执行临界区
二进制信号量就是初始值为1的信号量,被称为lock or mutex
lock(x_lock);
x = x+1;
unlock(x_lock);
global synchronization
- BARRIER (name, num)
- thread will wait at barrier call until num threads arrive
- built using lower-level primitives
- separate phases of computation
- Example use:
- N threads are adding elements of an array into a sum
- Main thread is to print sum
- Barrier prevents main thread from printing sum too early
- use barrier synchronization only as needed 仅在需要时使用屏障同步
- heavyweight operation from performance perspective 从性能角度进行重量级操作
- Exposes load imbalance in threads leading up to a barrier 暴露线程中的负载不平衡导致屏障
Peterson’s algorithm
mutual exclusion for 2 threads 两个线程的互斥 即在任一时刻只允许一个线程进入关键区域
int turn;
int interested[2]; // initialized to 0
void lock (int process) { // process is 0 or 1
int other = 1 – process; // know the other process ID
interested[process] = TRUE; // indicate interest
turn = process;
while (turn == process && interested[other] == TRUE) {} ;
}
// Post: turn != process or interested[other] == FALSE
void unlock (int process) {
interested[process] = FALSE;
}
这个算法使用两个全局变量:
int turn;用来指示哪个线程应该等待进入关键区域。int interested[2];一个大小为 2 的数组,用于指示两个线程中的每一个是否有兴趣进入关键区域。通常初始化为 0。
还有两个函数:
void lock(int process)线程调用此函数来尝试获取锁。process 是一个标识线程的整数(在这里是 0 或 1)。other 变量用来获取另一个线程的索引(1 - process)。这个函数首先将interested[process]设置为 TRUE 表示当前线程想要进入关键区域,然后设置 turn 为 process。接着进入一个 while 循环,该循环一直持续到另一个线程不感兴趣或者它允许当前线程进入关键区域(即它的 turn 不等于 process)。void unlock(int process)线程在离开关键区域时调用此函数来释放锁。它通过将interested[process]设置为 FALSE 来实现。
函数退出只有在以下两种情况下发生:
interested[other] == FALSE:要么另一个进程没有竞争锁,要么它刚刚调用了 unlock()。turn != process:另一个进程正在竞争锁,已经将 turn 设置为自己,并将在 while 循环中被阻塞。
所以当process想要访问该区域的时候,就需要调用lock(process)以获取其状态,假如是可以进入的,就会直接通过while循环进入,假如被占用了,就会在while处变成死循环,这时候假如占用该区域的unlock(other)了,也就是把这块释放出来了,while循环就会结束,该process就可以顺利进入了。
help from hardware
software solution有缺点:tricky2实现,需要考虑不同的方法for不同的memory consistency models
Most processors provide atomic operations 大多数处理器提供原子操作
multi-threaded programming
如何实现?
C: pthreads, C++: std::thread or boost::thread
What will the threads execute? 线程什么时候执行
- Typically spawned to execute a specific function 通常为执行特定功能而生成
What is shared vs private per thread?
- recall address space
- thread-local storage
Pthreads
看ppt03 page37
C++ threads
看ppt03 page47
Lecture 4 IPC
inter-process communication
cooperation
若干个线程或进程并行处理,共同完成一个task
他们如何沟通?
- threads of the same process: shared memory
- recall they share a process context: code, static data, heap
- can read and write same memory: variables, arrays, structures
- 要是线程不在同一个进程中呢?
- don’t have access to each other’s memory
models for IPC
- Shared memory: 统一进程中的不同线程,或者不同的进程之间也可以使用比如memory mapped files (mmap)
- Message passing: 使用OS作为intermediary, files, pipes, FIFOs, messages, signals

shared memory vs message passing
- shared memory
- advantages: fast, easy to share data
- disadv: need synchronization, be tricky to eliminate race conditions 需要同步,难以消除race condition
- message passing
- advantages
- trust not required between sender and receiver (receiver can verify)
- set of shared data is explicit 共享数据集是显式的
- OS handles synchronization系统处理同步问题
- disadv
- Explicit programming support needed to share data
- Performance overhead
shared memory across processes
differernt OSes have different APIs for this
UNIX: system V shared memory, shared mappings, POSIX shared memory
还是需要同步
mmap
#include <sys/mman.h>
int * mmap(void * addr, size_t length, int prot, int flags, int fd, off_t offset);
creates new mapping in virtual address space of caller 创建一个新的mapping在caller的虚拟地址空间中
- addr:mapping开始的地址
- length; 距离开始的偏移量
- etc
- return:return value是mapping被made的地址
mmap operation
- kernal takes an open file (given by fd) 核takes一个打开的文件
- maps that into process address space maps进程地址空间里
- in unallocated space between stack & heap regions
- thus also maps file into physical memory
- creates one to one correspondence between a memory address and a word in the file
- useful even apart from the context of IPC
- Multiple (even non-related) process can share mem
munmap
#include <sys/mman.h>
int munmap(void *addr, size_t length)
removes mapping from process address space
用来remove
#include <sys/mman.h>
int msync(void *addr, size_t length, int flags);
Flushes file contents in memory back out to disk
• addr: address of the mapping
• length: # bytes in mapped region
• flags: control when the update happens
synchronization
taking it further
this requreid some work
- creat file in file system
- open the file & init it
there is a better way is just sharing mem across a fork()
- anonymous memory mapping
use mmap flags of MAP_SHARED | MAP_ANON
- file descriptor will be ignored also offset
- memory init to 0
- alternative approach: open / dev / zero & mmap it
can anonymous approach work across non-related processes?
只被mmapcall的进程或者子进程访问
There’s no way for another process to map the same memory because that memory can not be referred to from elsewhere since it is anonymous
message passing
message between processes, facilitated by OS
有几种方法
- files,可以打开不同进程之间的相同文件,open the same file between processes, 通过读写file的info来交流,但是比较难合作
- pipes
- FIFOS
- other types of messages
pipes
pipe是双向的
可以作为IPC在线程或者进程之间
returns value是pipefd[0] is the read end, pipefd[1] is the write end
kernel support
- data written to write end is buffered by kernel until read
- data is read in same order as it was written
- no synchronization needed (kernel provides this)
- must be related processes
还可以用pipes去链接沟通进程
Networking Introduction
我们已经知道了wires和buses被用于在一个机器内进行交流,那么多个machines之间应该如何交流呢
很复杂,那我们应该如何管理?abstraction
A computer network is a group of interconnected computers
为什么要计算机网络?为了share resource, communication between users applications
分离client和server,把PC和互联网链接
network structure
routers and switches (intermediate nodes) allow sharing
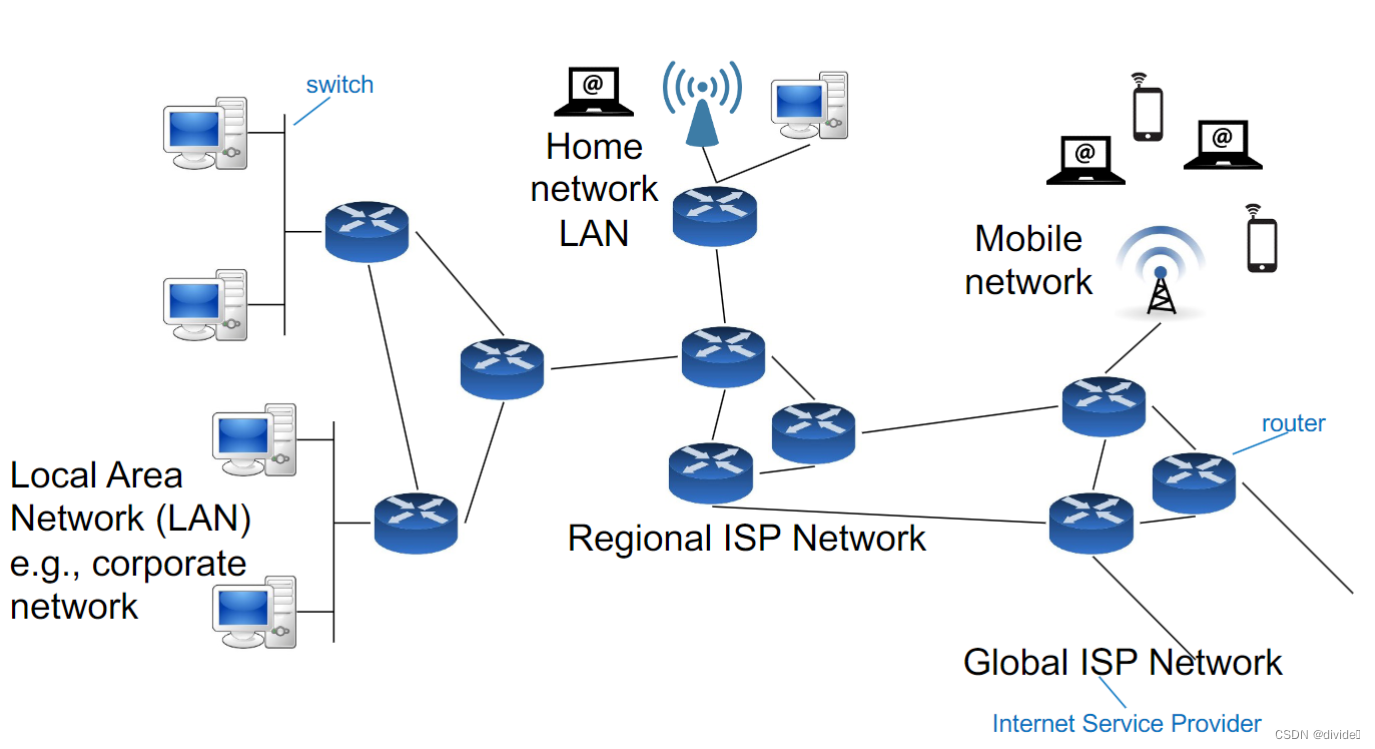
Network endpoints run applications programs: web browser, email client, ftp, ssh, etc.
有两种节点之间的交流方法
- client-server model
- peer to peer model (decentralized 去中性化)
主要问题为:
3. 数据如何在端点中传播通过网络
4. 网络link如何share communication
有两个分享的策略
- circuit switching 电路交换
- create & allocate dedicated path for a transmission 创建并分配专用的传输数据
- from one endpoint to another through a series of routers / switches 从路由器的一个端点到另一个端点
- 老化电话网络就是这样的
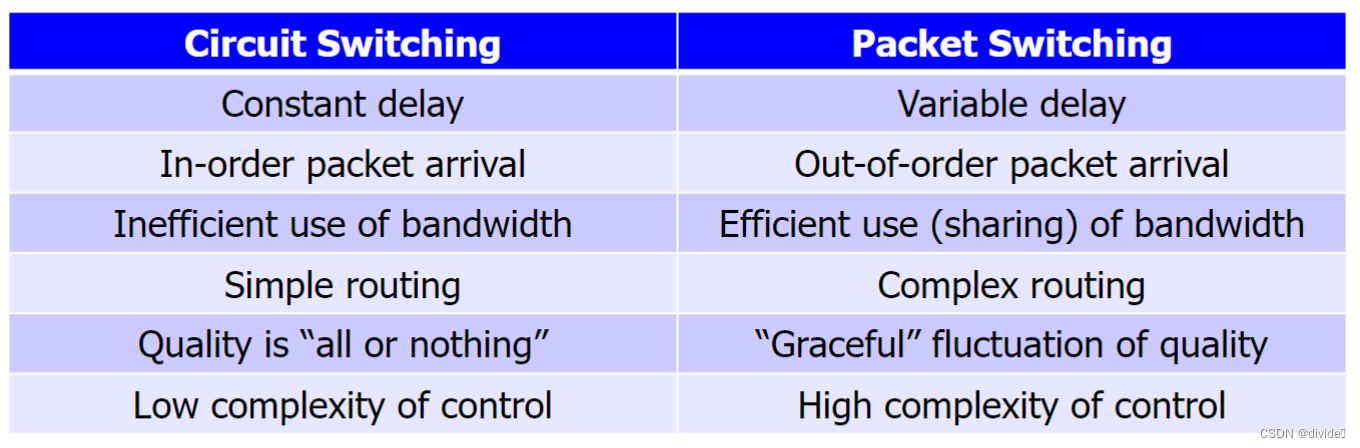
- packet switching 包交换
- divide each message up into a sequence of packets 把每个message分为一个序列的小包
- packets sent from one network node the next 小包从一个网络节点到另一个,节点比如路由器
- each router decides the destination for the next hop based on its information about the network structure 每一个路由决定了下一跳的节点,通过network结构上的信息
- eventually, packets of the message should arrive at destination 最终,包会到达终点
circuit switching
reserve end2end resources for each transmission 为每次传输预留端到端的资源(链路带宽,路由器资源)
性能可以保证,但是需要有setup和teardown过程
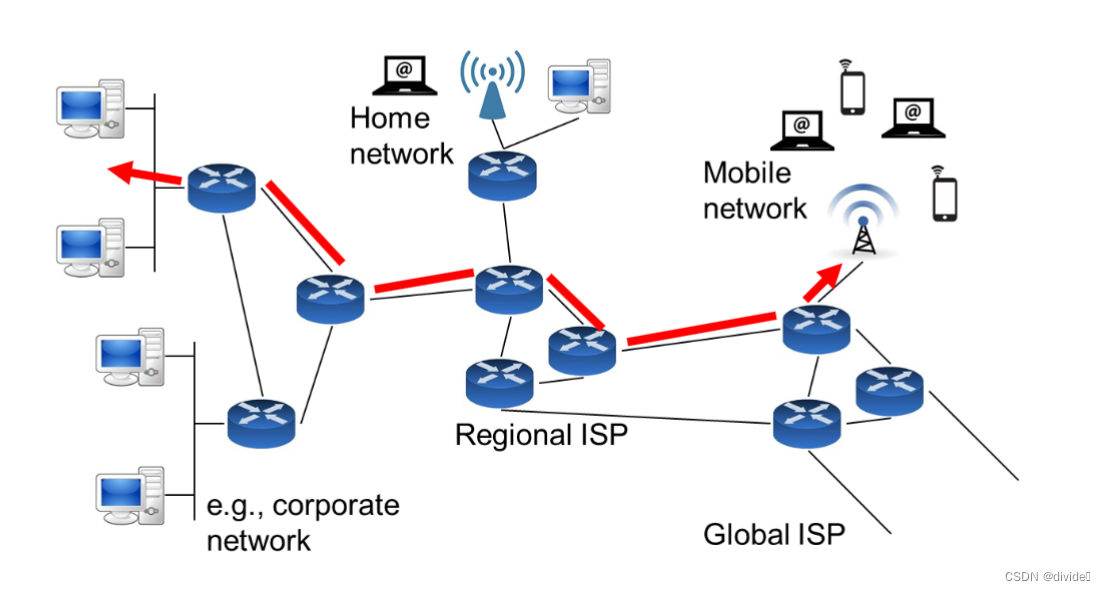
实现电路交换的过程
- establish the end to end circuit 实现端对端电路
- communication 发送消息通过网络
- close circuit (deallocate resources 解除分配资源)
假如没有端对端电路需要实现,比如缺少可用资源,会进行重试,比如电话中的忙线声
circuit-switched networks
经常效率不高
因为电路的容积是在整个连接期间被分配
传输通常不会在持续时间内充分利用信道
建立电路也有延迟
网络建立后对用户是透明的 (就像有一条专用线路连接到目标端点)
data可以通过有传播延迟的固定速率传输
所以如何建立电路交换呢?
multiplexing
- routers and links can carry multiple communications, 可以同时带有多重交流(假如每个交流只是用总带宽的一部分的话)
- need a machanism to divide network resources into pieces 需要一个机制去把网络资源分为一部分一部分的
- 如何分呢?使用multiplexing 好几种
- frequency division multiplexing FDM
- time division multiplexing TDM
- code division multiplexing CDM
- motivation 动机
- carry multiple signals on a single medium携带多个信号在一个中间体上
- more efficient use of transmission medium 使传输中间体的效率更高
TDM
divide time into frames; and framse into slots 将时间划分为帧; 并将帧放入槽中
each transmission stream gets a relative slot poisition within a frame 每一个传输流得到一个相关的槽位在一个帧里
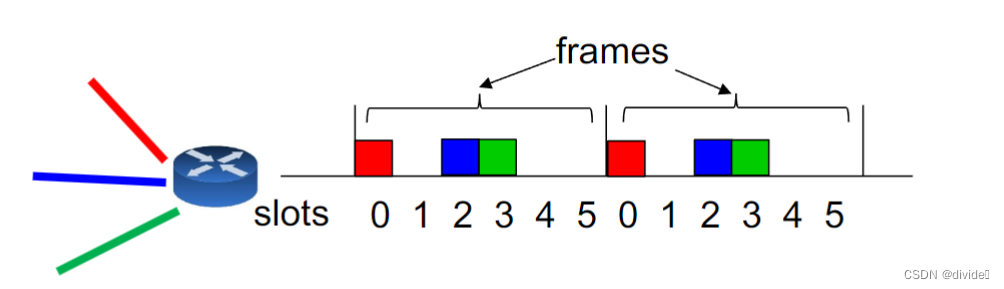
require synchronization between sender and receiver需要发送者和接收者之间的同步
因为是传输数字信号,需要再次组装,所以时间有先后,组装的时候也需要按照时间的先后进行组装
FDM
separate frequency spectrum of the medium into overlapping, smaller frequency bands 将介质的频谱分成重叠的较小频带
a channel is allocated to a smaller frequency band: has access to that frequency band for the entire life of circuit
可以把TDM和FDM组合起来
利用FDM去分频率光谱 use FDM to divide frequency spectrum
使用 TDM 对每个频段内时隙的信道进行时间切片 use TDM to time-slice channels across slots within each band
Packet-switched routers 包交换路由
multiplex with queues in the router
demultiplex using packet header info (metadata): destination: toward endpoint 通过路由把发送向不同的终点的包进行分配
queueing in packet routing
- 会出现新的effect
- variable delay = queueing delay + processing delay + propagation delay + transmission delay 可变延迟 = 排队延迟 + 处理延迟 + 传播延迟 + 传输延迟
- packet loss: when packet arrive to a router with a full queue, they are dropped 包被通过queue传输的时候,可能会drop
ordering会被packet routing影响:
因为packets of a stream 会在不同的时间到的到达目的地,以不同的顺序
因为msg被拆分为了碎片放在了不同的frame里,所以在网络中走的路线是不同的
sample packet format
一个简单的例子:
- header
- source address (SA)
- destination address (DA)
- sequence number (packet index within a transmission) need to reconstruct data at destination需要在终点处重组data结构
- data
- trailer: for example: CRC (cyclic redundancy check) for error detection
三大部分一共五小部分组成
layering / abstraction
a stack of layers of abstraction
有两种分层方法:OSI和TCP/IP
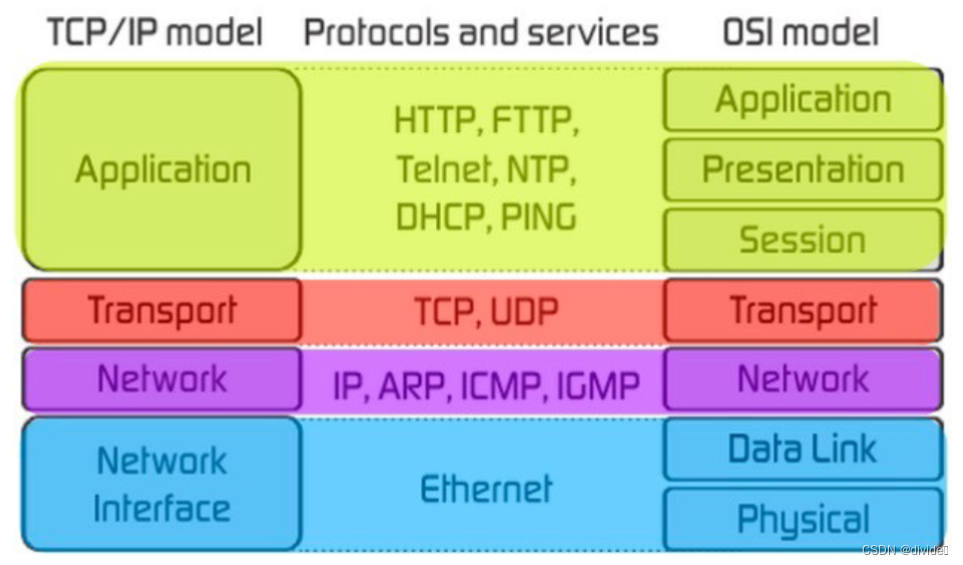
OSI是open systems interconnection,这是理论模型,记忆方法是all people seem to need data processing
application, presentation, session, transport, network, datalink, physical
TCP/IP transmission control protocol and the internet protocol,这是一个practical model
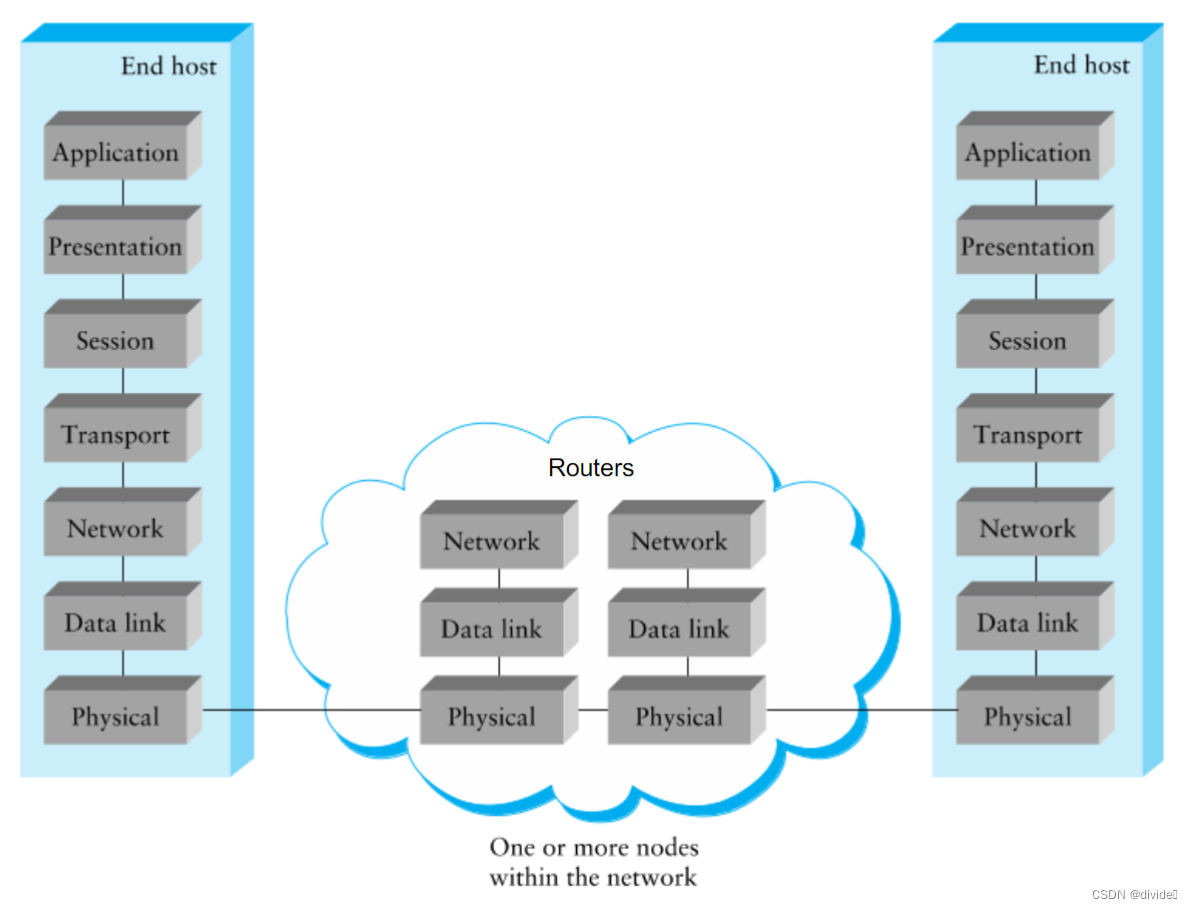
路由器上只有三层,终端上有七层
协议结构
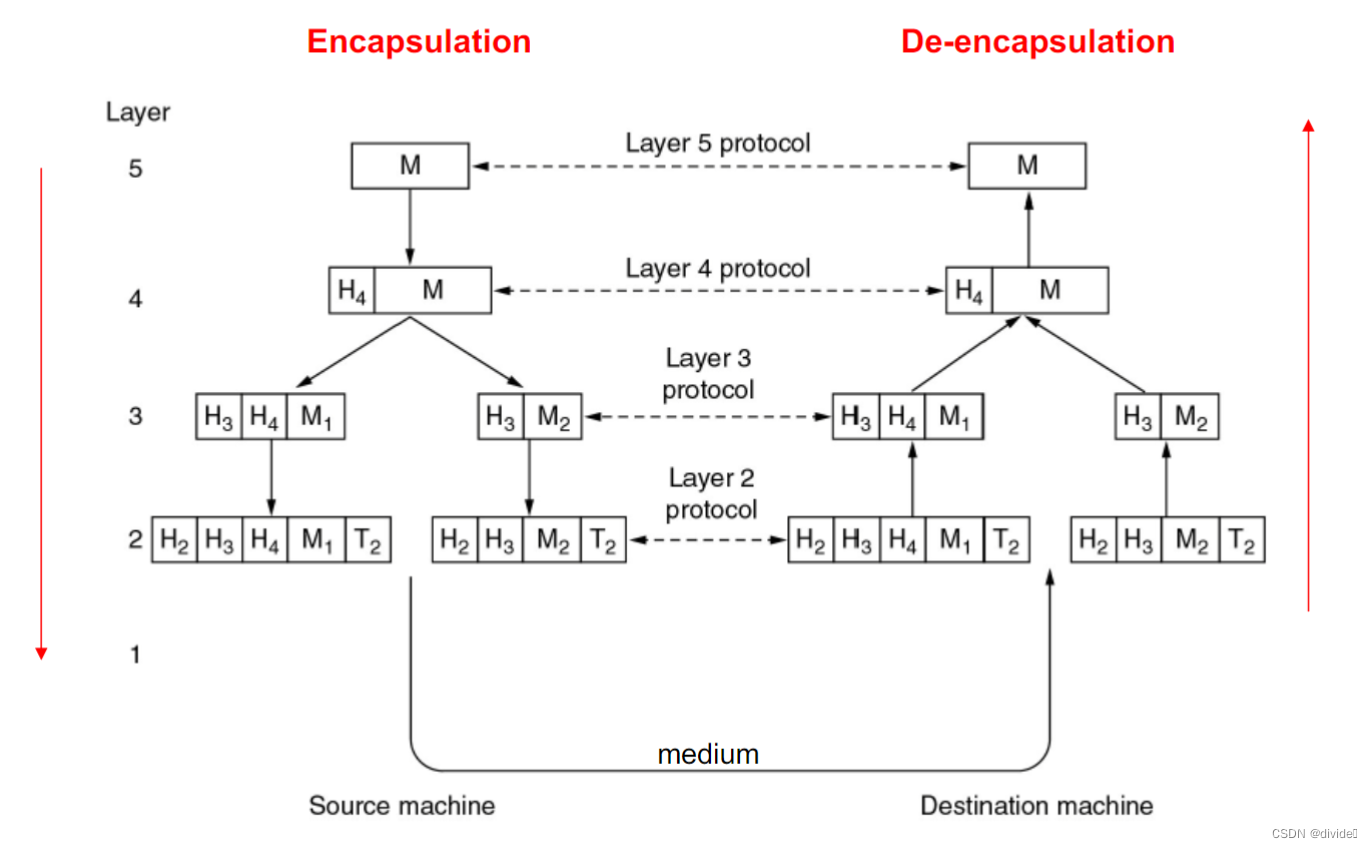
Protocol
每一个抽象层的交流都是通过协议
协议定义了
- message format
- order of messages sent/receiced
- action to take on message transmission/receipt
OSI
layer1: physical layer
encoding of bits to send over a single physical link 编码后的bits传输通过一个物理链接
example: ethernet, 802.11 Wifi
layer2: link layer
把一系列的bits打包和传输通过单个子网
提供了MAC地址 local (physical) addressing
经常,技术支持广播,每一个在网络或者子网中的节点接受packets
比如wifi
MAC地址是用48bits并烧入网卡,全球统一
layer1-2 demo ARP address resolution protocol
如何使用第三层的ip地址转化为第二层的mac地址?
- can inquire to see known MAC address
- can use OUI first 3 bytes to check manufacturer of devices
layer3
第三层是链接多个子网之间的桥梁,提供节点之间的端对端链接
bridges multiples subnets to provide end to end connectivity between nodes.
提供global addressing logical:IP address
只提供best-effort delivery of data 没有重发机制,丢了概不负责
layer4 transport layer
endtoend communication between processes
提供不同的服务
- TCP 可靠
- UDP 不可靠
this is the layer that applications talk with
IP+port number
layer5-7
communication of whatever you want
can use whatever transports are convenient / appropriate
freely structured
比如
skype: L4 UDP
SMTP: email TCP
HTTP: web TCP
online games: TCP or UDP
Socket
what about communication across distributed processes?
use network sockets
what is an IP address?
- logical address (OSI layer 3 address) to identify network device
- 32 bits for IPv4
- 128 for IPv6
what is a MAC address?
- physical address (layer 2 address)
- 48 bits, in hex
what is port number?
- logical application/process identifier (layer 4 address)
- 16 bits
what is a physical interface/port?
physical plug/socket/outlet on the device where your connection medium connets
network sockets
- network interface is logically identified by an IP address
- processes attach to ports to use network services
- port attachment is done with
bind()operation
- socket = IP address : port number
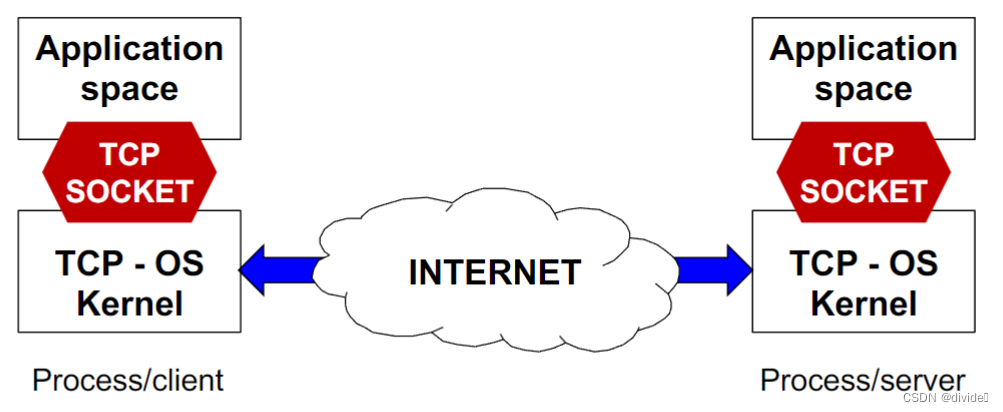
A socket is an abstract interface that the OS provides to the application level for communicating through the network
是一个抽象接口操作系统提供给应用等级用来交流通过网络
- the details of the interface depend on the OS
- communicating through the network means communicating to the Transport layer of the protocol pile
#include <sys/socket.h>
client-server model
常见的交流模型在网络系统中
client通常和服务器交流
服务器可以会有多个clients
交流是通过layer4 tcp or udp
client需要知道
服务器地址 address of the server
存在可以提供所需服务的设备 existence of a server providing the desired service
server does not need know about the existence of clinets and clients and their addresses 服务器不需要知道客户的存在和客户的地址
他等客户主动向他请求服务
it responds using the addresses in the request packets
- the source address in the client’s request would become the destination address in the server’s response 请求来的时候里面的地址可以作为服务结束之后发回去的地址
TCP
transmission control protocol
为端对端byte stream设计over unreliable network不可靠的网络
robust against failures and charging network properties
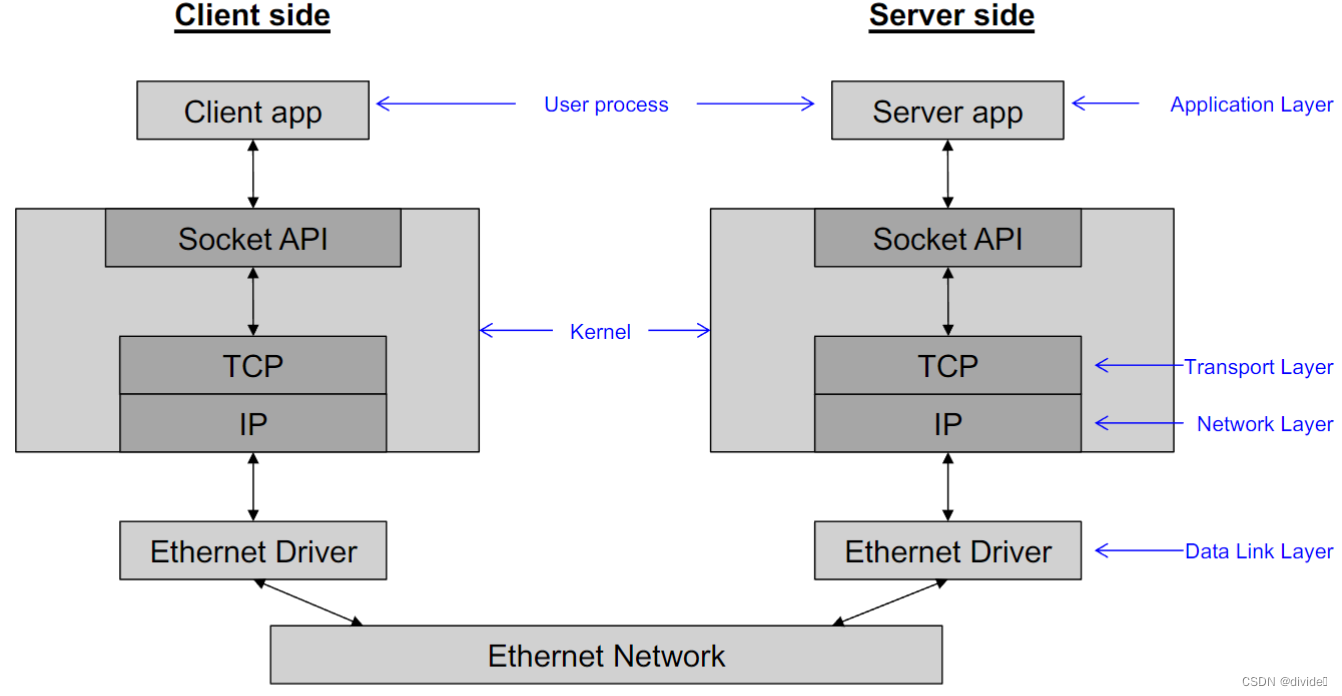
TCP
breaks up data into pieces that can fit in 1 ethernet frame with IP + TCP headers
hanldes retransmissions & re-ordering
TCP is a connection-oriented transport layer
provides error-free, reliable communication
setup
两个节点进程创建终点 套接字
每一个套接字都有ip地址,端口号
api方法被用于创建和交流在套接字上
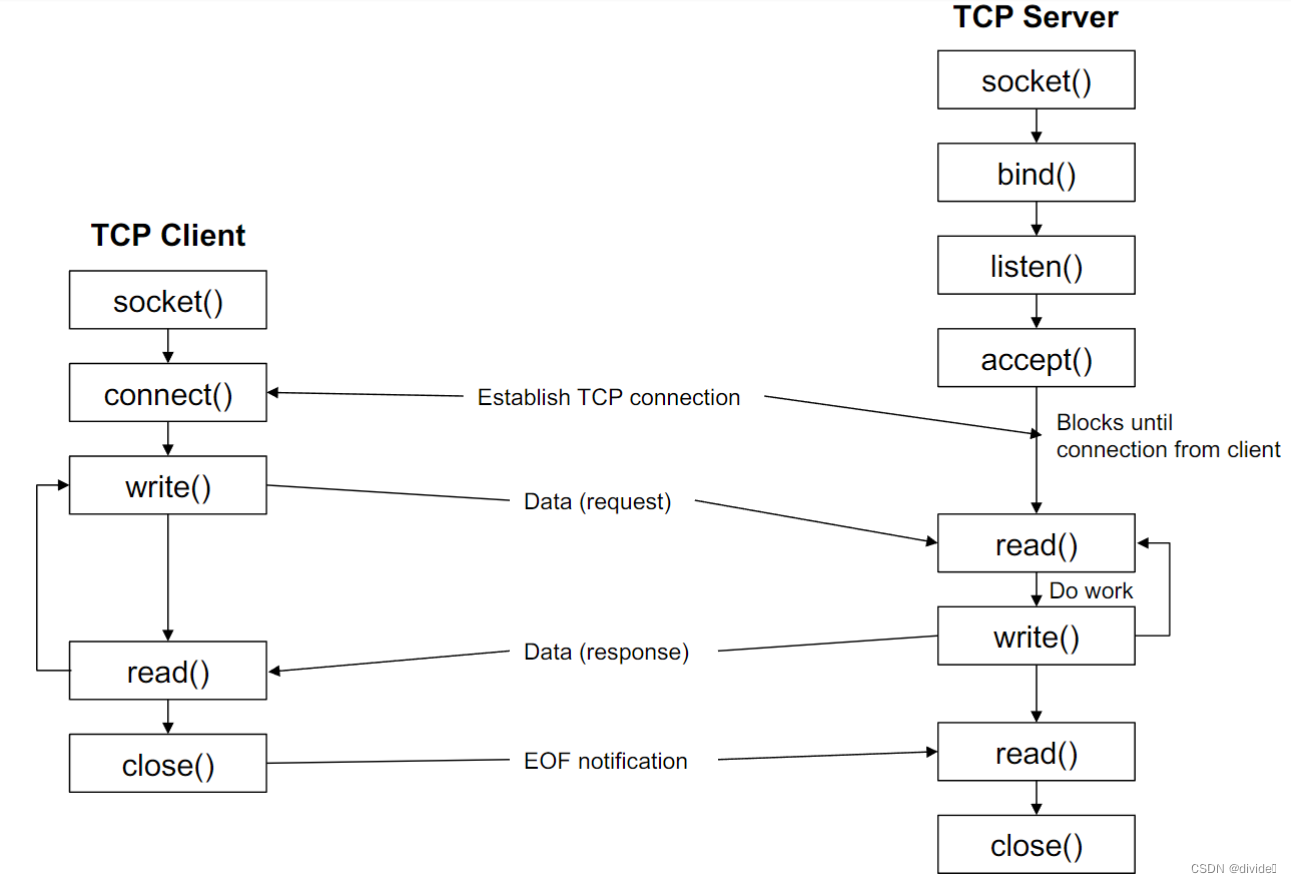
int socket(int domain, int type, int protocol)
create an endpoint for communication and returns a fd that refers to that endpoints
return -1 on failure
int bind(int sockfd, const struct sockaddr * addr, socklen_t addrlen)
after creation a socket does not have a associate address
bind() creates the association socket-address
returns 0 on success, -1 on failure
Networking - link layer
layer1: physical layer
encoding of bits to send over a single physical link 编码后的bits被单个物理link传送
layer2: link layer
- framing and transmission of a collection of bits into individual messages sent across a single subnetwork. framing和transmission一系列bits成个体信息然后通过单个子网
- provides local/physical addressing (MAC address)
- may involve multiple physical links
- often the technology supports broadcast 通常技术支持广播
- 比如现代ethernet,Wi-Fi
物理层
传递信息在this link需要牵涉到以下
- transmission media
- properly encoding bits for transmission
- sharing the media among distinct transmissions
data link layer (layer2)
algorithms for communication between adjacent machines两个相邻机器之间的交流的算法
- communication that is both: reliable and fast
- adjacent machines means machines directly connected by a communication channel
看起来比较简单,但是errors in bit transmissions can happen, finite data rates and bit propagation delays have impact on effciency.比特传输时会出现错误,有限的数据率和比特传输延迟会影响效率
layer2的服务
- provide service interface to the network layer (layer3) 给网络层提供服务接口
- provide physical address (MAC) 提供物理地址
- handle errors during transmission 传递时处理错误
什么是framing 其实有点像封装(假如要翻译的话)
- recieve packets down from network layer 从上面的网络层接受packets(layer3是网络层)
- break packet up into frame; add headrs and trailer to each 把packet切成frame,加头加尾
- send frames across transmission medium (layer1) 把加好头尾的frame送到layer1去
从上层接受packets,然后把packet拆分为frame,加头加尾
相反的操作发生在接受端
对面在layer1接受到frame,送到第二层去头去尾,在合并成packet送到第三层
第二层服务:面向网络层的(layer3)
transfer data provided by network layer on one machine to the network layer on another machine
将一台机器上的网络层提供的数据传输到另一台机器上的网络层
但是实际的传输是在layer1 physical layer进行的
比较常见的链路层服务:
- unacknowledged connectionless service 未确认的无连接服务
- send frames from src to destination where dest does not acknowledge 从src往dest发frame,但是dest并不知道
- if frame is lost due to noise, no attempt to detect or recover 假如frame丢失了,不会有探测和重传
- 对于低错误率通道或实时流量很有用 useful for low error rate channels or real time traffic 比如ethernet
- acknowledged connectionless service 确认的无连接服务
- still no connection established, but dest acknowledges (ack) each frame 依然没有连接实现,但是dest会ack每一个frame
- sender will resend frames if no acked within a time limit 假如一段时间内没有收到ack,sender就会再次发送frame,说明有重传机制了
- layer2 ack is a optimization, not a requirement (why? layer 4 does it) 第二层的ack不是需求,是优化
- 对于unreliable channels 比较好,比如wireless
- acknowledged connection-oriented service 确认的连接服务
- 最精确的服务
- src和dest先establish a connection
- each frame sent over connection is numbered and acked by dest 每一个通过连接发送的frame都是标号的并且由dest ack的
- guaratees each frame is recieved exaclty once and in the proper order 保证所有的frame接收到后只有一个并且正确的顺序 (无连接的服务可能因为ack丢失而导致src反复发送相同的frame)
三个阶段
- connection is established 连接实现
- 1 or more frames are transmitted 一个或多个frame被传送
- connection is released 连接断开,buffer 变量等被释放
layer 2 services - framing
link layer sends stream of bits across physical layer 链路层在物理层中传输bits流
bits可能会丢失也可能会被alter values
链路层可以侦查修改错误的bits
framing
Abstraction
layer2 sees layer3’s bits as just a sequence of bits.
切开,加头加尾,再去layer1传送
character count
不靠谱,假如有一个错了,就会导致后面的count都错了

byte stuffing
bit stuffing
is applied on the frame payload by the sender
is the operation of including in the payload info that does not make part of the payload itself
假如我的header和tail都是六个连续的1,那么假如frame里也有大于等于六个连续的1,不就会被错误额断开了吗?
这时候我就给在frame里每次出现5个连续的1的地方,都插入一个0,保证不会有六个连续的1出现
接受者拿到之后第一件事去调所有的六个1(header + tail)再去掉所有连续5个1后面的一个1,就可以得到正确的info
layer2 services - error control
packet loss是由第四层的tcp控制的
第二层处理的是bits相关的错误
correction is more expensive than detection 改正比探测更贵 (就开销位数而言 overhead bits checksum)
tradeoff这就只能开始均衡,比较可靠的就用便宜的侦查,不怎么可靠的就用修改
hamming distance 哈明距离
is the number of bit differences between two binary strings
011010
011110
hamming distance: 1
011010
101011
hamming distance: 3
假如两个bits string有一个哈明距离d, 说明可以通过反转d位(错误)把这个字符串变成另外一个
一个frame应该是 n = m + r bits:
- m = data bits (message) m是message
- r = redundant bits (parity) r是校验码
- n-bit chunk is called a codeword n是两个加在一起的块
- a code is the set of all valid codewords n that obey certain rules for r based on m
错误控制:奇偶校验
add a single reduendant bit to the message
只能处理一位错误
奇数位错误可以探测
Hamming distance of the code is the minimum Hamming distance between any 2 valid codewords
当这个概念应用于编码理论时,尤其是在错误检测和错误校正的背景下,“Hamming distance of the code” 是指在一个编码方案中,任意两个有效编码字(codewords)之间的最小Hamming距离。换句话说,它是在所有有效编码字对中找到的最小差异数量。这个最小的Hamming距离对于理解编码方案的错误校正能力非常重要。
例如,如果一个编码方案的Hamming距离为3,这意味着你必须改变任何有效编码字中的至少3个位才能得到另一个有效的编码字。这也意味着,如果一个编码字在传输过程中出现了1位或2位的错误,我们仍然可以准确地识别出原始的编码字,因为没有其他有效的编码字与其Hamming距离小于3。因此,这个编码方案可以检测并校正最多2位的错误。
error detection and correction properties
with a code of hamming distance d:
we can detect d-1 single bit errors 少一位就可以检测出来错误,再多一位就彻底变成另外一个codeword了
we can correct (d-1)/2 single bit errors 这以内的错误是可以检查出来并改正的
Valid codewords are so far apart that with d single-bit errors, the original valid codeword is still the “closest”
举例个例子
有4个valid codewords
0000000000, 0000011111, 1111100000, 1111111111
m(message)is 00, 01, 10, 11 respectively
hamming distance is 5
detect 4 single bit errors
correct 2 single bit errors
假如接受者收到0000000111,最大的可能性原来是0000011111(2位错误)closest distance
但是也有可能是0000000000(3位错误)
Principles
what is we want to correct any single-bit errors?
how many bits would r be?

【官方双语】汉明码Pa■t1,如何克服噪■
data link layer performance
what we want
- small latency
- high throughput
what is latency 数据从源端到目的端所需的时间
- 传播延迟(Propagation Delay):信号在媒介中传播需要一定的时间,这个时间依赖于媒介的长度和信号在媒介中的传播速度。
- 传输延迟(Transmission Delay):这是将数据从一个设备发送到连接媒介所需的时间,它取决于数据的大小和发送设备的传输速率。
- 处理延迟(Processing Delay):数据在节点(如交换机或路由器)处理过程中可能会遇到的延迟,如检查数据的错误,确定数据包的路由等。
- 排队延迟(Queuing Delay):数据在传输前在缓存中等待处理或传输的时间。这个时间可以因为网络拥塞、缓冲区大小、数据包优先级等因素而变化。
sending frames bandwidth bits/s
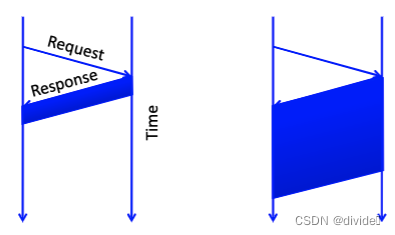
for small transfers, latency more important
for bulk throughput more important
Performance Metrics
Throughput: number of bit received/unit of time
goodput: useful bits received per unit of time
latency: how long for message to across network (processing+queueing+transmission+propagation)
jitter: variation in latency
processing: per message, small, limits throughput
queueing: highly variable, offered load vs. outgoing bandwidth
transmission: size/bandwidth
propagation: distance/ speed of light
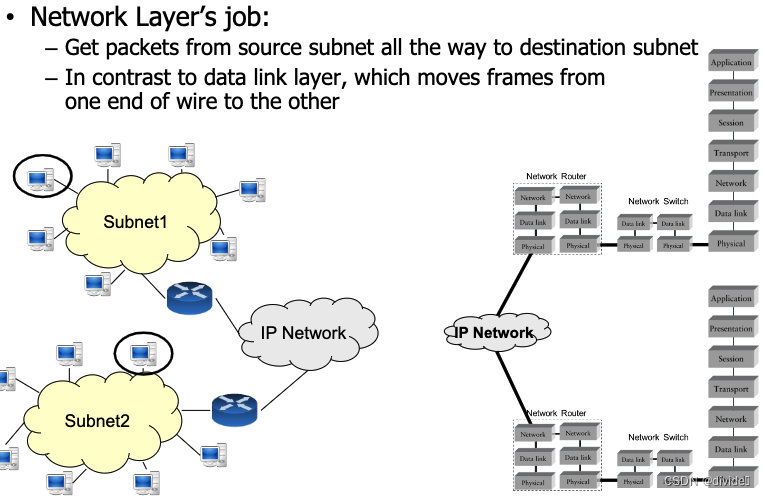
Network layer
layer3
network layer’s job:
- get packets from src subnet all the way to dest subnet (从一个子网到另外一个子网)
- in contrast to data link layer, which moves frames from one end of wire to the other 与链路层相反,把frame从wire的一头移到另外一头
交换机和路由器的区别?
交换机在链路层,路由器在网络层。
交换机用于lan内的交流,路由器用于子网和子网之间的交流
交换机使用MAC地址在LAN内转发frame,路由器使用IP地址在subnet之间转发packet
交换机的转发速度一般比路由器快,因为交换机是基于硬件的转发,而路由器需要通过软件路由算法
network layer (layer3)
must:
be aware of the topology of subnets知道子网的拓扑结构
maintain a view of the topology of subnets
choose appropriate path through the different networks,给交流找一个好的path,避免overload some communication paths and routers
provides services to transport layer with these goals
- services independent of router technology
- hides number, type, and topology of routers from other layers
example: internet and IP network protocol: connectionless service
ATM: connection-oriented service
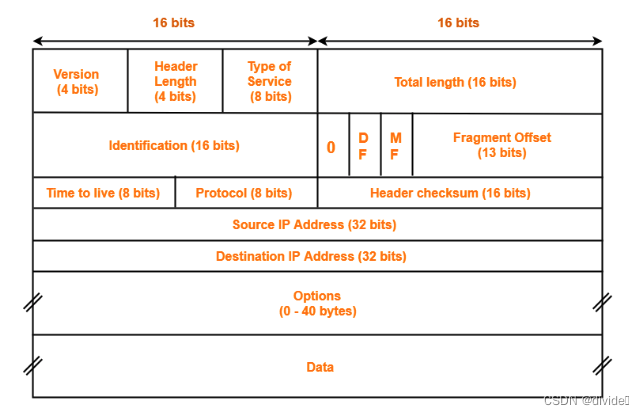
IPv4
Routing: routing table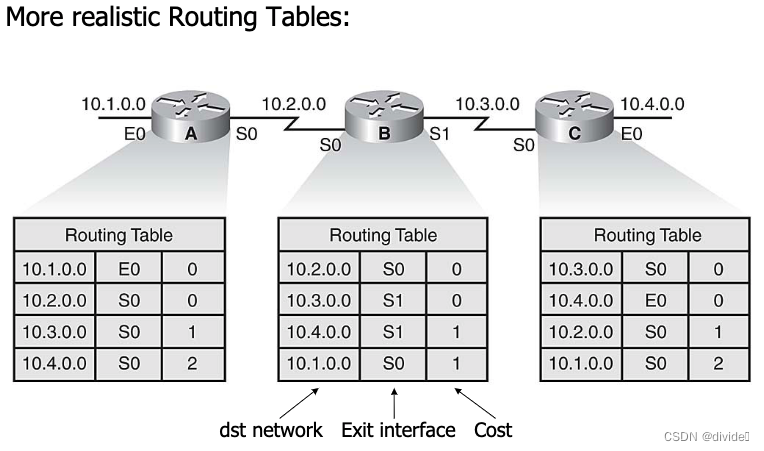
routing algorithm:
- determine which output interface/network an incoming packet goes out on
- maybe a new decision for every incoming packet
routing vs forwarding:
- forwarding: check routing table to find appropriate outgoing interface for packet 转发:检查路由表找到合适的接口给包裹
- routing: initialize and update routing tables 路由:初始化和更新路由表
desirable routing algorithm properties:
correctness, simplicity, robustness, stability, fairness, optimality
adaptive vs non-adaptive routing (aka dynamic vs static)
- dynamic routing changes according to the used routing algorithm to reflect topology, current traffic. 动态的根据使用的路由算法改变拓扑,和当前流量
- static routing is when network administrators manually set fixed specific routes for specific destinations 静态的是网络管理员人为的设定了特殊的路由给特殊的目的地
routing is organized in two levels
- intra-domain routing 内部域路由 within a domain
- inter-domain routing 域间路由 between domain
内部区域路由大多依赖动态路由算法
域间路由大多依赖静态路由
动态路由
2 classes of intra-domain routing algorithms:
- Distance Vector (bellman-ford shortest path algorithm) 距离向量
- send best-known path info to neighbors. can figure out optimal routes over time 发送最已知的路径信息给邻居
- require only local state 只需要当地状态
- harder to debug
- can suffer from loops
- link state (迪杰斯特拉,prim最短路径算法)
- send adjacency info to neighbors. Each router builds map of network over time, then runs shortest-path algorithm locally 把相邻信息发送给邻居,每一个节点都有整个路由的网络
- each node has global view of the network
- simpler to debug
- requires global state, which limits scalability















 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









