






GBDT模型简介
Gradient Boosting Decision Tree,梯度提升树
特点
- 基于简单决策树的组合模型
- 沿着梯度下降的方向进行提升
- 只接受数值型连续变量,需做特征值转化
优点 - 准确度高
- 不易过拟合



分类器性能指标简介
gbm0 = GradientBoostingClassifier(random_state=10)
gbm0.fit(X_train,y_train)
y_pred = gbm0.predict(X_test)
y_predprob = gbm0.predict_proba(X_test)[:,1]
print("try 1: 使用默认参数的测试集")
print ("Accuracy : %.4g" % metrics.accuracy_score(y_test, y_pred))
print( "AUC Score (Testing): %f" % metrics.roc_auc_score(y_test, y_predprob))
GBDT在流失预警模型中的应用
如何调参?
param_test1 = {'n_estimators':range(20,81,10)}
gsearch1 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, min_samples_split=300,
min_samples_leaf=20,max_depth=8,max_features='sqrt', subsample=0.8,random_state=10),
param_grid = param_test1, scoring='roc_auc',iid=False,cv=5)
gsearch1.fit(X_train,y_train)
print("gsearch1.cv_results_")
print(gsearch1.cv_results_)
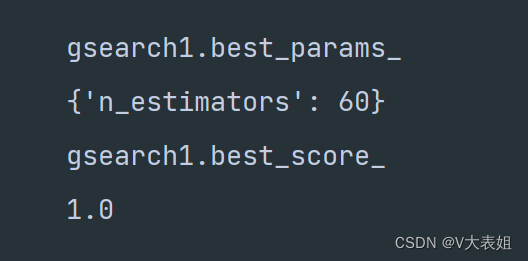
print("gsearch1.best_params_")
print(gsearch1.best_params_)
print("gsearch1.best_score_")
print(gsearch1.best_score_)
和随机森林一样,GBDT也可以给出特征重要性
clf = GradientBoostingClassifier(learning_rate=0.05, n_estimators=70,max_depth=9, min_samples_leaf =70,
min_samples_split =1000, max_features=28, random_state=10,subsample=0.8)
clf.fit(X_train, y_train)
importances = clf.feature_importances_
#sort the features by importance in descending order. by default argsort returing asceding order
features_sorted = argsort(-importances)
import_feautres = [allFeatures[i] for i in features_sorted]
for i in import_feautres:
print(i)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









