







01
JoyGen
JoyGen 开源工具由京东和香港大学的团队联合开发,专注于音频驱动的3D深度感知说话人脸视频编辑。
简单来说,JoyGen 可以通过音频输入生成逼真的 3D 说话人脸视频,甚至可以对人脸表情和细节进行深度调整。
它特别适合像虚拟主播生成、AI互动视频制作这样的场景。更厉害的是,这个项目不仅提供了完整的推理代码,还支持个性化训练,适应不同的应用需求。
🚀 实现原理
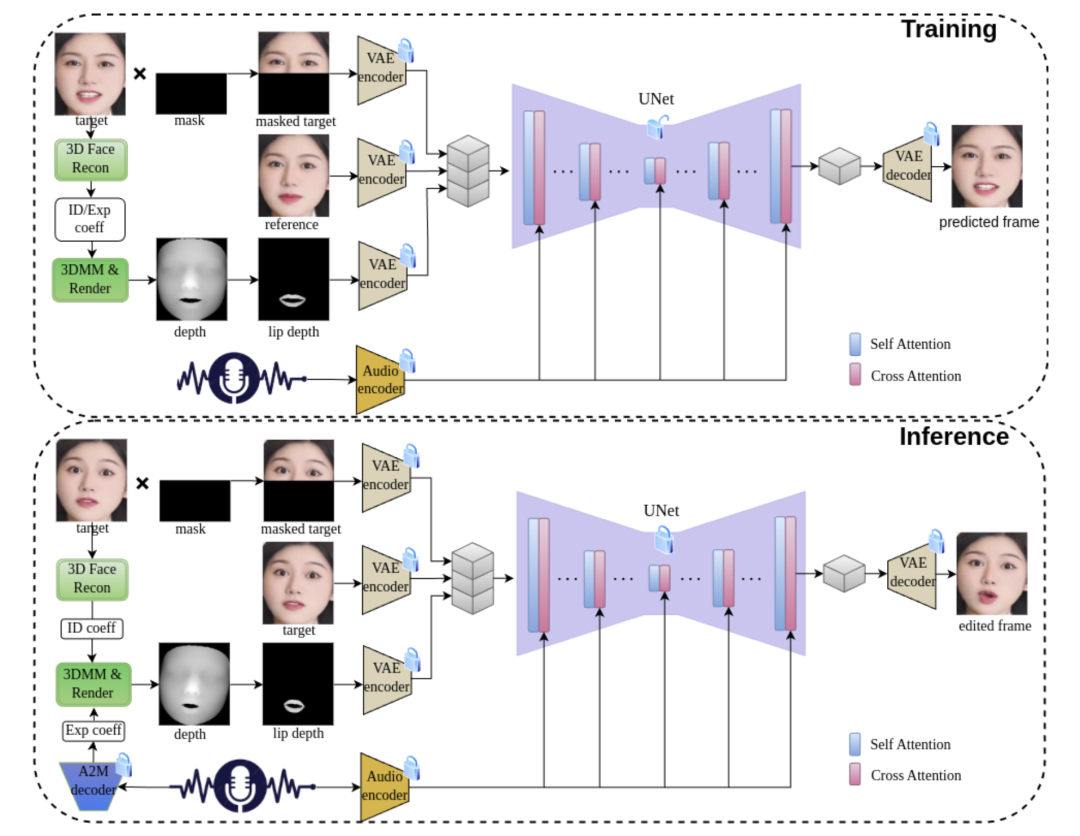
JoyGen 框架分为两个阶段:
首先,3D 重建模型和音频运动模型分别预测身份和表情系数。然后,通过将音频特征与面部深度图相结合,我们为面部生成中的精确唇音同步提供全面监督。
此外,开发者还构建了一个包含 130 小时高质量视频的中文说话人脸数据集。JoyGen 在开源 HDTF 数据集和我们精选的数据集上进行训练。实验结果表明,JoyGen 在唇音同步和视觉质量上表现卓越。
 项目信息
项目信息
① 该开源项目于上周刚刚开源,基于论文《JoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing》
② 目前该开源项目没有提供可以直接使用的应用,需要自行部署和体验。可以基于如下开源地址自行体验
开源地址:https://github.com/JOY-MM/JoyGen02
Hallo3
复旦大学和百度联合推出的项目,这个开源框架可以将静态人像变为高度动态、栩栩如生的动画,凭借强大的扩散变换器网络,为影视、虚拟形象和互动内容制作提供了全新的解决方案。
选择一张你喜欢的照片,录制你想要的语音内容。Hallo3 会自动将你的照片和语音结合,生成一个动态的动画。
可以看看下面的案例,面部表情还是动态细节要想达到非常自然还得再下点功夫。
 项目信息
项目信息
① 该开源项目于上周刚刚开源,基于论文《Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks》
② 目前该开源项目没有提供可以直接使用的应用,需要自行部署和体验。可以基于如下开源地址自行体验
开源地址:https://github.com/fudan-generative-vision/hallo303
LatentSync
字节跳动和北交大开源了一项黑科技:LatentSync。它可以实现视频中人物唇部动作与音频的精准同步,让你的视频说话更自然!
让视频中的人物说出你想要的话,LatentSync 可以帮你实现这些愿望。
原视频:
优化后:
🚀 实现原理
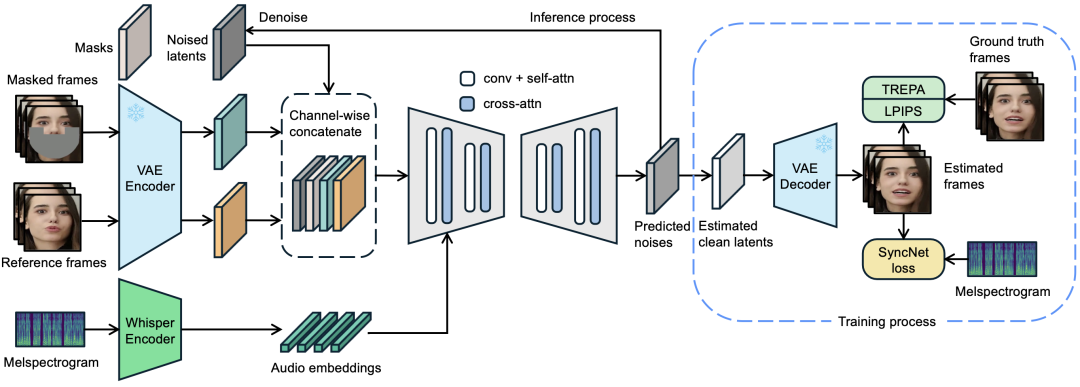
它基于音频条件潜在扩散模型,它可以将音频信号转换为嵌入表示,并通过交叉注意力层将其集成到 U-Net 模型中,从而直接生成与音频匹配的唇部动作。
这种端到端的设计避免了中间运动表示的需要,减少了误差的累积,提高了唇同步的精确度。
LatentSync还引入了Temporal REPresentation Alignment(TREPA)机制,利用大型自监督视频模型提取的时间表示,使生成的帧与真实帧对齐,从而增强时间一致性。
这意味着,生成的视频不仅唇同步准确,而且在时间上保持连贯,不会出现跳帧或卡顿现象。
开源地址:https://github.com/bytedance/LatentSync

















 57
57

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









