






GAT论文解析
论文信息
- 论文标题: Graph Attention Networks
- 论文地址: https://arxiv.org/pdf/1710.10903.pdf
- 代码地址: https://github.com/PetarV-/GAT
- 发表时间: ICLR 2018
- 作者单位: University of Cambridge
- 作者:Petar Velickovic, Yoshua Bengio .etc
- 代码:https://github.com/Diego999/pyGAT
核心观点:GAT (Graph Attention Networks) 采用 Attention 机制来学习邻居节点的权重, 通过对邻居节点的加权求和来获得节点本身的表达.
下面三篇论文递进关系:
- Semi-Supervised Classification with Graph Convolutional Networks,ICLR 2017,图卷积网络 https://arxiv.org/abs/1609.02907
- Graph Attention Networks,ICLR 2018. 图注意力网络,就是此篇文章所解析的论文 https://arxiv.org/abs/1710.10903
- Relational Graph Attention Networks ,ICLR2019 关联性图注意力网络,整合了GCN+Attention+Relational
- 从GNN到GCN再到GAT
- GNN:权重依靠人为设定或学习得到
- GCN:依赖于图结构决定更新权重。 H ( l + 1 ) = σ ( D ^ − 1 / 2 A ^ D ^ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)}=\sigma(\hat{D}^{−1/2}\hat{A}\hat{D}^{−1/2}H^{(l)}W^{(l)}) H(l+1)=σ(D^−1/2A^D^−1/2H(l)W(l))
- GAT:GAT是对于GCN在邻居权重分配问题上的改进。注意力通过Multi-head Attention 进行学习,相比于GCN的更新权重纯粹依赖于图结构更具有合理性。
- 贡献
- 引入masked self-attentional layers 来改进前面图卷积graph convolution的缺点
- 对不同的相邻节点分配相应的权重,既不需要矩阵运算,也不需要事先知道图结构
- 四个数据集上达到state of the art的准确率Cora、Citeseer、Pubmed、protein interaction
图注意力网络(Graph Attention Networks, GAT),处理的是图结构数据。它通过注意力机制(Attention Mechanism)来对邻居节点做聚合操作,实现了对不同邻居权重的自适应分配,大大提高了图神经网络的表达能力。
前期知识
概率论:基本的概率论知识掌握条件概率的概念
注意力机制:深度学习中的attention机制,Transformer中的multi-head
消息传递:图神经网络的消息传递方式,汇聚每个节点邻域中的特征
深度学习: SGDdropout等基本原理
图注意网络:空间域的图神经网络
In conclusion: 图注意网络(GAT)通过引入注意力机制,允许每个节点根据其邻居节点的特征分配不同的权重,从而在图结构数据上实现了更高效、灵活和精确的建模。它适用于处理inductive任务,并具有更好的表示能力,因此在图神经网络领域取得了显著的成果。
- 图注意网络(Graph Attention Network,GAT)是一种**基于空间域的图神经网络,其与传统的图卷积网络(GCN)等方法不同之处在于引入了注意力机制**。
在传统的图卷积网络中,需要使用预先构建好的图进行复杂的计算,而GAT不需要使用拉普拉斯等矩阵,仅通过节点的一阶邻居来更新节点特征,从而实现了更高效的图神经网络。
- GAT的((核心是使用了masked self-attention层)),该层允许每个节点根据其邻居节点的特征为其分配不同的权值。这意味着每个节点在更新特征时可以根据其邻居节点的重要性进行加权,从而更好地捕捉节点之间的复杂关系。通过这种注意力机制,GAT能够更灵活地建模图数据,适用于更广泛的图结构和任务。
相比于传统的图卷积网络,GAT具有以下优势:
- 适用于inductive任务:传统的图卷积网络擅长处理transductive任务,即训练和测试使用相同的图数据,而无法完成inductive任务,即训练和测试使用不同的图数据。而GAT仅需要一阶邻居节点的信息,因此可以处理更广泛的图数据,实现inductive任务。
- 不同邻居节点的权重学习:传统的图卷积网络对于同一个节点的不同邻居在卷积操作时使用相同的权重,而GAT通过注意力机制允许为不同的邻居节点学习不同的权重。这使得GAT可以更精确地捕捉节点之间的重要关系,提高了模型的表现能力。
注意力机制
注意力机制是深度神经网络(DNN)中的一种重要机制,其灵感来源于人类处理信息的方式。由于人类的信息处理能力有限,我们往往会选择性地关注信息的一部分,忽略其他不太重要的信息。
类似地,注意力机制的目标是对给定的信息进行权重分配,将注意力集中在对系统来说最重要的信息上,从而使得网络可以更加关注重要的部分并进行重点加工。
Attention函数的本质可以被描述为**一个查询(query)到一系列(键key-值value)对的映射。**
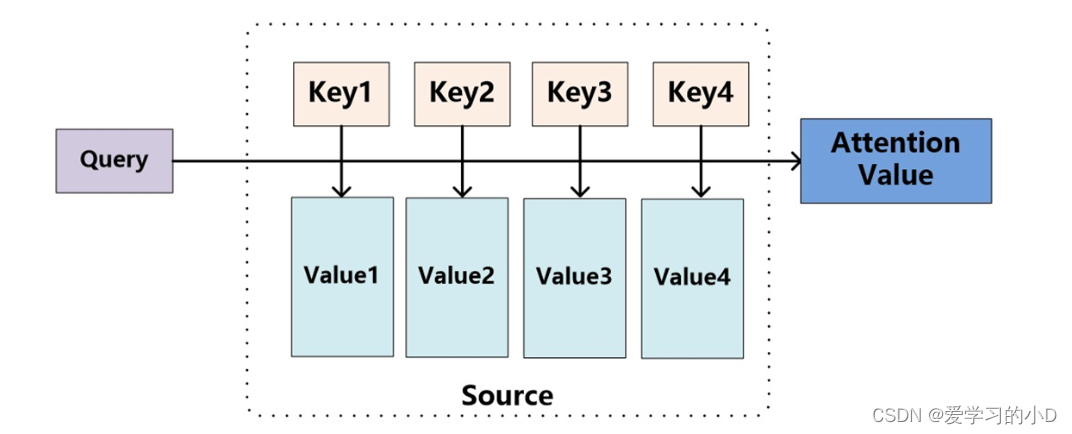
-
其中,有一个待处理的信息源Source和一个表示条件或先验信息的Query。信息源中包含多种信息,我们将每种信息都表示成键值对(Key-Value)的形式,其中Key表示信息的关键信息,Value表示该信息的具体内容。注意力机制的目标是根据Query,从信息源Source中提取与Query相关的信息,即Attention Value。
-
A t t e n t i o n ( Q u e r y , S o u r c e ) = ∑ i s i m i l a r i t y ( Q u e r y , K e y i ) ⋅ V a l u e i Attention(Query,Source)=\sum_isimilarity(Query, Key_i)\cdot Value_i Attention(Query,Source)=i∑similarity(Query,Keyi)⋅Valuei
-
上式中Query,Key,Value,Attention Value在实际计算时均可以是向量形式。 Similarity(Query,Key_i) \text{Similarity(Query,Key\_i)} Similarity(Query,Key_i) 表示Query向量和Key向量的相关度,最直接的方法是可以取两向量的内积<Query, Key_i>(用内积去表示两个向量的相关度是DNN里面常用的方法,对于两个单位向量,如果内积接近1,代表两向量接近重合,相似度就高)。
-
上式表明注意力机制就是对所有的Value信息进行加权求和,权重是Query与对应Key的相关度。
-
图注意力层(Graph Attentional Layer)
图注意力层(Graph Attentional Layer,GAL)是图注意力网络(Graph Attention Networks,GAT)中的核心组件,用于在图数据上实现节点的信息聚合和更新。图注意力层通过引入注意力机制来为每个节点分配不同的权重,从而将重要的邻居节点的信息更多地融入到目标节点中,实现动态的特征选择和提取。
通过图注意力层的多次迭代,可以对节点的特征进行层层传递和更新,从而逐步提取图中节点的高层次特征信息。图注意力层的主要优点是可以自适应地学习节点之间的权重,而不需要预先构建图结构,因此适用于图数据的不同任务,例如节点分类、链接预测、图分类等。
- 根据注意力机制里面的三要素:Query, Source, Attention Value,可以将Query设置为当前中心节点的特征向量,将Source设置为所有邻居的特征向量,将Attention Value设置为中心节点经过聚合操作后的新的特征向量。
- 对于一个 N N N节点的图,我们一共会构造 N N N个图注意力网络,因为每一个节点都需要对于其邻域节点训练相应的注意力。而图注意力网络的层数 K K K则根据需要决定。我们在这里先分析 K = 1 K = 1 K=1,即一个单层图注意力网络的工作原理。
- 设图中任意节点 v i v_i vi在第 l l l 层所对应的特征向量为 h i , h i ∈ R d ( l ) h_i ,h_i\in R^{d^{(l)}} hi,hi∈Rd(l) , d ( l ) d^{(l)} d(l)表示节点的特征长度,经过一个以注意力机制为核心的聚合操作之后,输出的是每个节点新的特征向量 h i ′ ∈ R d ( l + 1 ) h'_i\in R^{d^{(l+1)}} hi′∈Rd(l+1), d l + 1 d^{l+1} dl+1表示输出的特征向量的长度。将这个聚合操作成为图注意力层(Graph Attention Layer, GAL)。
- 单层图注意力网络的输入为一个向量集
h
=
{
h
1
⃗
,
h
2
⃗
,
.
.
.
,
h
N
⃗
}
,
h
i
⃗
∈
R
F
h=\{\vec{h_1},\vec{h_2},...,\vec{h_N}\}, \vec{h_i}\in R^F
h={h1,h2,...,hN},hi∈RF ,输出为一个向量集$ h’={\vec{h’_1},\vec{h’_2},…,\vec{h’_N}}, \vec{h’_i}\in R^{F’}
。即通过图注意力层后,原本的节点信息
。即通过图注意力层后,原本的节点信息
。即通过图注意力层后,原本的节点信息\vec{h_i}
被更新为
被更新为
被更新为\vec{h’_i}
。为了使得网络能够从原始输入中提取更深层次的信息,通常设
。为了使得网络能够从原始输入中提取更深层次的信息,通常设
。为了使得网络能够从原始输入中提取更深层次的信息,通常设F’>F$,即
图注意力层是一个将信号升维的网络。
下图为节点 v i v_i vi的单层图注意力网络的其中一个邻居节点 v j v_j vj的结构表示:
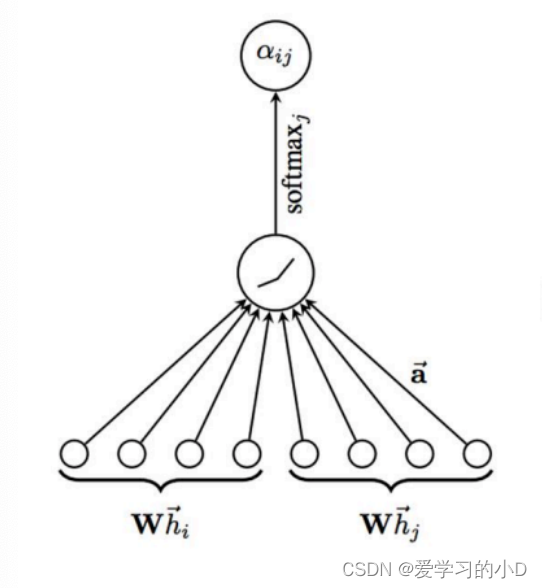
以一个节点为中心,考虑它的邻居节点作为源节点。以下是图注意力层的详细讲解:
输入:假设当前图中有N个节点,每个节点的特征向量为 h i ∈ R F h_i \in \mathbb{R}^{F} hi∈RF,其中 F F F是特征的维度。每个节点的特征向量表示了节点的信息。
聚合操作:对于节点 v i v_i vi,我们考虑其邻居节点 v j v_j vj的特征向量 h j h_j hj,其中 j ∈ N ~ ( v i ) j \in \tilde N(v_i) j∈N~(vi), N ~ ( v i ) \tilde N(v_i) N~(vi)表示节点 v i v_i vi的一阶邻居节点集合。我们使用注意力权重 α i j \alpha_{ij} αij来衡量节点 v i v_i vi和其邻居节点 v j v_j vj之间的关联程度。注意力权重通过以下公式计算:
α i j = exp ( L e a k y R e L U ( a ⃗ T [ W h i ⃗ ∣ ∣ W h j ⃗ ] ) ) ∑ v k ∈ N ( v i ) ~ exp ( L e a k y R e L U ( a ⃗ T [ W h i ⃗ ∣ ∣ W h j ⃗ ] ) ) \alpha_{ij}=\frac{\exp{(LeakyReLU(\vec{a}^T[W\vec{h_i}||W\vec{h_j}])})}{\sum_{v_k\in \tilde{N(v_i)}}{\exp{(LeakyReLU(\vec{a}^T[W\vec{h_i}||W\vec{h_j}]))}}} αij=∑vk∈N(vi)~exp(LeakyReLU(aT[Whi∣∣Whj]))exp(LeakyReLU(aT[Whi∣∣Whj]))
其中, W W W是待学习的权重矩阵, a ⃗ \vec{a} a是待学习的向量,LeakyReLU是激活函数。这个公式将节点 v i v_i vi和邻居节点 v j v_j vj的特征映射到新的表示空间,并计算它们之间的相关度。通过LeakyReLU激活函数,可以允许一些负相关度的信息传递。
注意力权重归一化:对于每个节点 v i v_i vi,通过softmax函数将其与邻居节点的注意力权重进行归一化,使得所有邻居节点的注意力权重加和为1,这样做的目的是确保所有邻居节点的信息都能被合理地融入到目标节点 v i v_i vi中。
特征更新:根据归一化后的注意力权重 α i j \alpha_{ij} αij,对节点 v i v_i vi的邻居节点特征向量 h j h_j hj进行加权求和,得到节点 v i v_i vi的新特征向量 h i ′ h'_i hi′。该特征向量通过激活函数进行非线性变换,从而得到最终的更新后的节点特征。
h i ′ ⃗ = σ ( ∑ v j ∈ N ~ ( v i ) α i j W h j ⃗ ) \vec{h'_i}=\sigma{(\sum_{v_j\in \tilde N(v_i)}\alpha_{ij}W\vec{h_j}}) hi′=σ(vj∈N~(vi)∑αijWhj)
其中, σ \sigma σ表示激活函数。这个操作将节点 v i v_i vi与其邻居节点的信息聚合起来,得到一个新的特征向量 h i ′ ⃗ \vec{h'_i} hi′,表示节点 v i v_i vi在图中更新后的特征。
-
对于节点 v i v_i vi,考虑其邻居节点 v j v_j vj到 v i v_i vi的注意力权重的计算过程。输入为两个向量 h i ⃗ , h j ⃗ ∈ R F \vec{h_i}, \vec{h_j}\in R^F hi,hj∈RF ,为了将它们变换到 R F ′ R^{F'} RF′,引入一个待学习的权重矩阵 W ∈ R F ′ × F W\in R^{F'\times F} W∈RF′×F,以及一个待学习的向量$\vec{a}\in R^{2F’} 。
-
做两个运算:$ W*\vec{h_i}和W* \vec{h_j} ,得到两个 ,得到两个 ,得到两个R^{F’}$维向量
-
计算节点 v i v_i vi在节点 v j v_j vj上的注意力值 e i j = a ( W h i ⃗ , W h j ⃗ ) e_{ij}=a (W\vec{h_i},W\vec{h_j}) eij=a(Whi,Whj),也就是邻居节点 v j 到 v i v_j到v_i vj到vi的权重系数,其中 W ∈ R d ( l + 1 ) × d ( l ) W\in R^{d^{(l+1)}\times d^{(l)}} W∈Rd(l+1)×d(l)是该层节点特征变换的权重参数。 a ( ⋅ ) a(\cdot) a(⋅)是计算两个节点相关度的函数,原则上可以计算图中任意一个节点到节点 v i v_i vi的权重系数,为了简化计算,将其限制在一阶邻居内,需要注意的是在GAT中,作者将每个节点也视为自己的邻居。
-
最后对于节点 v i v_i vi的所有邻居节点求得 e e e后,利用softmax完成注意力权重的归一化操作。
-
关于 a a a的选择,可以用向量的内积来定义一种无参形式的相关度计算$ <W\vec{h_i},W\vec{h_j}> ,也可以定义称一种带参的神经网络层,只要满足 ,也可以定义称一种带参的神经网络层,只要满足 ,也可以定义称一种带参的神经网络层,只要满足a :R{d{(l+1)}}\times R{d{(l+1)}} \rightarrow R$,即输出一个标量值表示二者的相关度即可。作者选择了一个单层的全连接层:
e i j = L e a k y R e L U ( a [ W h i ⃗ ∣ ∣ W h j ⃗ ] ) e_{ij}=LeakyReLU(a [W\vec{h_i}||W\vec{h_j}]) eij=LeakyReLU(a[Whi∣∣Whj]) -
其权重参数 a ∈ R 2 d ( l + 1 ) a\in R^{2d^{(l+1)}} a∈R2d(l+1),激活函数为LeakyReLU。另外,为了更好分配权重,需要将与所有邻居计算出的相关度进行统一的归一化处理,具体形式为softmax归一化:
α i j = s o f t m a x j ( e i j ) = exp e i j ∑ v k ∈ N ~ ( v i ) e x p ( e i k ) \alpha_{ij}=softmax_j(e_{ij})=\frac{\exp{e_{ij}}}{\sum_{v_k\in \tilde N(v_i)}exp(e_{ik})} αij=softmaxj(eij)=∑vk∈N~(vi)exp(eik)expeij -
α \alpha α是权重系数,通过上式的处理,保证所有邻居的权重系数加和为1。
-
完整的权重系数的计算公式为:
α i j = exp ( L e a k y R e L U ( a ⃗ T [ W h i ⃗ ∣ ∣ W h j ⃗ ] ) ) ∑ v k ∈ N ( v i ) ~ exp ( L e a k y R e L U ( a ⃗ T [ W h i ⃗ ∣ ∣ W h j ⃗ ] ) ) \alpha_{ij}=\frac{\exp{(LeakyReLU(\vec{a}^T[W\vec{h_i}||W\vec{h_j}])})}{\sum_{v_k\in \tilde{N(v_i)}}{\exp{(LeakyReLU(\vec{a}^T[W\vec{h_i}||W\vec{h_j}]))}}} αij=∑vk∈N(vi)~exp(LeakyReLU(aT[Whi∣∣Whj]))exp(LeakyReLU(aT[Whi∣∣Whj])) -
在归一化所有节点的注意力权重后,就可以通过图注意力层进行节点的信息提取了。整个网络的输出值 h i ′ ⃗ \vec{h'_i} hi′
-
计算公式如下(其中 σ \sigma σ表示激活函数):
- h i ′ ⃗ = σ ( ∑ v j ∈ N ~ ( v i ) α i j W h j ⃗ ) \vec{h'_i}=\sigma{(\sum_{v_j\in \tilde N(v_i)}\alpha_{ij}W\vec{h_j}}) hi′=σ(vj∈N~(vi)∑αijWhj)
-
多头图注意力层
多头图注意力层是图神经网络中的一种扩展,用于增强注意力机制的表达能力。它引入了多组相互独立的注意力机制,每组注意力机制都可以学习不同的节点关联和特征权重,从而在节点信息聚合过程中考虑更多的相关性。
多头图注意力层的优势在于能够学习多组不同的注意力机制,使得模型可以充分考虑不同节点之间的相关性和重要性。**通过增加注意力头数 K K K,可以进一步提高模型的表达能力。**这种多头机制使得图神经网络能够适应更复杂的图结构,更好地捕捉节点之间的关联信息,从而在图数据的任务中取得更好的性能。
-
为了进一步提升注意力层的表达能力,可以加入多头注意力机制(multi-head attention),即对上式调用K组相互独立的注意力机制,然后将输出结果拼接在一起:
h i ′ ⃗ = ∣ ∣ k = 1 K σ ( ∑ v j ∈ N ~ ( v i ) α i j ( k ) W ( k ) h j ⃗ ) \vec{h'_i}=||_{k=1}^K \sigma{(\sum_{v_j\in \tilde N(v_i)}\alpha_{ij}^{(k)}W^{(k)}\vec{h_j}}) hi′=∣∣k=1Kσ(vj∈N~(vi)∑αij(k)W(k)hj) -
其中, ∣ ∣ || ∣∣表示拼接操作, α i j ( k ) \alpha_{ij}^{(k)} αij(k),是第 k k k组注意力机制计算出的权重系数, W ( k ) W^{(k)} W(k)是对应的学习参数。当然,为了减少输出的特征向量的维度,可以将拼接操作替换成平均操作。
-
增加多组相互独立的注意力机制,使得多头注意力机制能够将注意力的分配放到中心节点与邻居节点之间多处相关的特征上,可使得系统的学习能力更加强大。
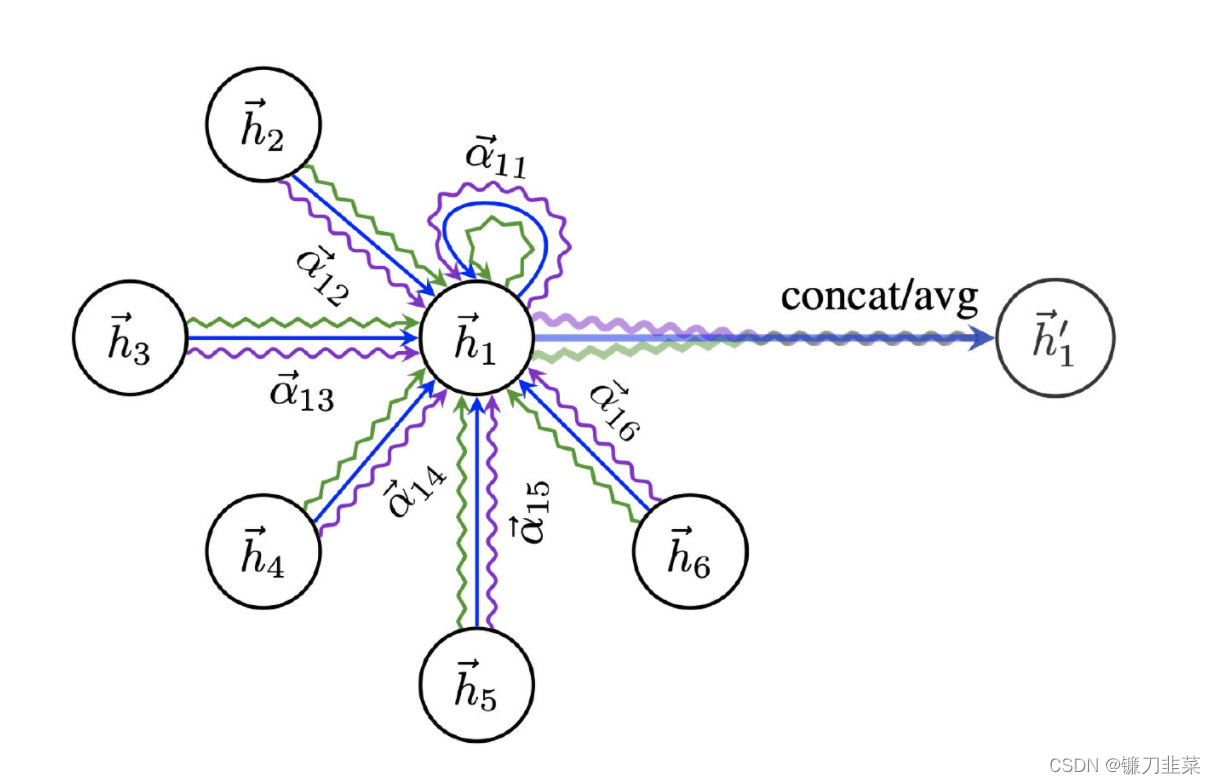
输入:假设当前图中有N个节点,每个节点的特征向量为 h i ∈ R F h_i \in \mathbb{R}^{F} hi∈RF,其中 F F F是特征的维度。每个节点的特征向量表示了节点的信息。
多头注意力机制:为了增强注意力层的表达能力,引入多组相互独立的注意力机制。每组注意力机制都由一个不同的权重矩阵 W ( k ) ∈ R F ′ × F W^{(k)} \in \mathbb{R}^{F' \times F} W(k)∈RF′×F和注意力系数向量 a ⃗ ( k ) ∈ R 2 F ′ \vec{a}^{(k)} \in \mathbb{R}^{2F'} a(k)∈R2F′组成,其中 F ′ F' F′是输出特征的维度, k k k表示第 k k k组注意力机制。
注意力权重计算:对于节点 v i v_i vi的每一组注意力机制 k k k,按照之前讲解的注意力机制公式,计算出相应的注意力权重 α i j ( k ) \alpha_{ij}^{(k)} αij(k),用于衡量节点 v i v_i vi与其邻居节点 v j v_j vj之间的关联程度。
特征更新:对于节点 v i v_i vi,对其所有的注意力机制 k k k,分别根据对应的注意力权重 α i j ( k ) \alpha_{ij}^{(k)} αij(k)对邻居节点特征进行加权求和,并进行激活函数的非线性变换。最后,将所有组的注意力机制输出结果拼接或平均,得到节点 v i v_i vi的新特征向量 h i ′ ⃗ \vec{h'_i} hi′。
h ⃗ i ′ = c o n c a t ( σ ( ∑ v j ∈ N ~ ( v i α i j ( 1 ) W ( 1 ) h ⃗ j ) , σ ( ∑ v j ∈ N ~ ( v i α i j ( 2 ) W ( 2 ) h ⃗ j , . . . , σ ( ∑ v j ∈ N ~ ( v i α i j ( K ) W ( K ) h ⃗ j ) \vec h_i'=concat(\sigma(\sum_{v_j\in \tilde N(v_i}\alpha_{ij}^{(1)}W^{(1)}\vec h_j),\sigma(\sum_{v_j\in \tilde N(v_i}\alpha_{ij}^{(2)}W^{(2)}\vec h_j,...,\sigma(\sum_{v_j\in \tilde N(v_i}\alpha_{ij}^{(K)}W^{(K)}\vec h_j) hi′=concat(σ(vj∈N~(vi∑αij(1)W(1)hj),σ(vj∈N~(vi∑αij(2)W(2)hj,...,σ(vj∈N~(vi∑αij(K)W(K)hj)
其中, σ \sigma σ表示激活函数,concat表示拼接操作。注意,也可以将拼接替换为平均操作,以减少输出特征的维度。
-
上图为一个三层图注意力网络(K=3),不同的颜色表示不同注意力计算过程,计算完成后,将上述结果进行拼接或者平均操作。多层注意力机制存在的意义在于:不同的特征可能需要分配不同的注意力权重,如果仅仅用单层注意力层,则对于该邻域节点的所有属性都采用了相同的注意力权重,这样将会减弱模型的学习能力。
-
图注意力层比GCN里面的图卷积层多了一个自适应的边权重系数的维度。回到GCN的核心过程 L ~ S Y M X W \tilde L_{SYM}XW L~SYMXW,可以将 L ~ s y m \tilde L_{sym} L~sym分拆成两个部分,引入一个权重矩阵 M ∈ R N × N M\in R^{N\times N} M∈RN×N,然后核心过程就变成 ( A ~ ⊙ M ) X W (\tilde A \odot M)XW (A~⊙M)XW。由此看出,图注意力模型比GCN多了一个可以学习的新维度——边上的权重系数。
-
在之前的模型中,这个权重系数矩阵是图的拉普拉斯矩阵,而图注意力模型可以对其进行自适应的学习,并且通过运用注意力机制,避免引入过多的学习参数。这使得图注意力模型具有高效的表达能力。从图信号处理角度看,这种机制相当于学习出一个自适应的图位移算子,对应一种自适应的滤波效应。同时和GraphSAGE模型一样,图注意力模型的计算也保留了非常完整的局部性,一样可以进行归纳学习。
注意,特殊情况,如果我们将多层注意力网络应用到最后一层(输出层),应该将公式改为
h
i
′
⃗
=
σ
(
1
K
∑
k
=
1
K
∑
v
j
∈
N
~
(
v
i
)
α
i
j
k
W
k
h
j
⃗
)
\vec{h'_i}=\sigma{(\frac{1}{K} \sum_{k=1}^K \sum_{v_j\in \tilde N(v_i)}\alpha_{ij}^{k}W^{k}\vec{h_j}})
hi′=σ(K1k=1∑Kvj∈N~(vi)∑αijkWkhj)
论文结构
- 摘要 Abstract:介绍背景及提出GAT模型,图卷积神经网络网络模型。在节点特征从邻居汇聚的时候考虑权重,适用于直推式和归纳式
- Introduction:介绍图的广泛应用,以及如何将卷积操作应用到图上,介绍基于空域和频域的两类方法,介绍注意力机制,引出本文的模型GAT
- GAT Architecture:GAT模型结构并和之前的模型做对比
- Conclusion:总结提出了的GAT模型使用了注意力机制,邻居汇聚时考虑不同的权重同时具有归纳式学习的能力,讨论几种未来方向如模型可解释性和图的分类。
- Evaluation:实验部分,数据集介绍,baselines选取,直推式和归纳式两种实验方式,图的节点分类效果对比
论文翻译
摘要
我们提出了图注意力网络(GAT),这是一种对图结构数据进行操作的新型神经网络架构,利用屏蔽自注意力层来解决基于图卷积或其近似的现有方法的缺点。通过堆叠节点能够参与其邻域特征的层,我们可以(隐式)为邻域中的不同节点指定不同的权重,而不需要任何类型的昂贵的矩阵运算(例如求逆)或依赖于了解预先的图形结构。通过这种方式,我们同时解决了基于谱的图神经网络工作的几个关键挑战,并使我们的模型易于适用于归纳和传导问题。我们的 GAT 模型已在四个已建立的转导和归纳图基准上取得或匹配最先进的结果:Cora、Citeseer 和 Pubmed 引文网络数据集,以及蛋白质相互作用数据集(其中测试图在训练期间保持不可见) 。
1 简介
-
卷积神经网络(CNN)已成功应用于解决图像分类(He et al., 2016)、语义分割(J´egou et al., 2017)或机器翻译(Gehring et al., 2016)等问题),其中底层数据表示具有类似网格的结构。
-
【数据比较规整】,比如一句话有前后顺序,长度不一样也能padding;图片也是上下左右的pixel
图结构每个点的度不一样——于是使用了local filters(类似于像素转换,邻居有影响)
-
-
这些架构通过将其应用到所有输入位置,有效地**重用具有可学习参数的本地滤波器**。
-
然而,许多有趣的任务涉及无法以网格状结构表示的数据,而是位于不规则域中的数据。 3D 网格、社交网络、电信网络、生物网络或大脑连接组就是这种情况。此类数据通常可以以图表的形式表示。
-
文献中已经多次尝试扩展神经网络以处理任意结构的图。早期工作使用递归神经网络来处理图域中表示为有向无环图的数据(Frasconi 等人,1998;Sperduti 和 Starita,1997)。 Gori 等人介绍了图神经网络(GNN)。 (2005) 和斯卡塞利等人。 (2009)作为递归神经网络的推广,可以直接处理更一般的图类,例如循环图、有向图和无向图。 GNN 由一个迭代过程组成,该过程传播节点状态直至达到平衡;接下来是神经网络,它根据每个节点的状态生成输出。这一想法被李等人采纳并改进。 (2016),建议在传播步骤中使用门控循环单元 (Cho et al., 2014)。
-
尽管如此,人们对将卷积推广到图域越来越感兴趣。这个方向的进展通常分为spcetral方法和non-spectral方法。
谱方法 spectral approaches
即Semi-Supervised Classification with Graph Convolutional Networks,ICLR 2017这篇文章中的方法
- Finally, Kipf & Welling (2017) simplified the previous method by restricting the filters to operate in a 1-step neighborhood around each node.在每个节点周围对卷积核做一阶邻接近似。但是此方法也有一些缺点:
- 必须基于相应的图结构才能学到拉普拉斯矩阵L
- 对于一个图结构训练好的模型,不能运用于另一个图结构(所以此文称自己为半监督的方法)
非谱方法 non-spectral approaches
- One of the challenges of these approaches is to define an operator which works with different sized neighborhoods and maintains the weight sharing property of CNNs. 即每个节点的相邻链接数量是不一样的,如何能设置相应的卷积尺寸来保证CNN能够对不同的相邻节点进行操作。下文这种方法运用GraphSAGE, 取得了不错的结果
- William L Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on largegraphs. Neural Information Processing Systems (NIPS), 2017.
- 这种方法是将相邻节点设置为固定的长度,然后进行specific aggregator,例如mean over all the sampled neighbors’ feature vectors, or the result of feeding them through a recurrent neural network。这种方法在几个大的benchmarks上取得了非常好的效果。
- 一方面,谱方法使用图的谱表示,并已成功应用于节点分类的背景下。在布鲁纳等人。 (2014),卷积运算是通过计算拉普拉斯图的特征分解在傅立叶域中定义的,从而导致潜在的密集计算和非空间局部滤波器。这些问题在后续的工作中得到了解决。赫纳夫等人。 (2015)引入了具有平滑系数的光谱滤波器的参数化,以使它们在空间上局部化。后来,德弗拉德等人。 (2016) 提出通过拉普拉斯图的切比雪夫展开来近似滤波器,从而无需计算拉普拉斯的特征向量并产生空间局部滤波器。最后,Kipf & Welling (2017) 通过限制滤波器在每个节点周围的 1 步邻域中运行来简化了之前的方法。然而,在所有上述spectral方法中,学习的滤波器取决于拉普拉斯特征基,而拉普拉斯特征基又取决于图结构。因此,在特定结构上训练的模型不能直接应用于具有不同结构的图。
- 另一方面,我们有non-spectral方法(Duvenaud et al., 2015;Atwood & Towsley, 2016;Hamilton et al., 2017),它们直接在图上定义卷积,对空间上邻近的组(close neighbors)进行操作。这些方法的挑战之一是定义一个**与不同大小的邻域(different sized neighborhoods一起工作并保持CNN 权重共享属性的算子(the weight sharing property of CNNs)。在某些情况下,这需要学习每个节点度数的特定权重矩阵(Duvenaud et al., 2015),使用转换矩阵的幂来定义邻域,同时学习每个输入通道和邻域度数的权重(Atwood & Towsley, 2016),或提取并规范化包含固定数量节点的邻域(Niepert 等人,2016)。蒙蒂等人。 (2016) 提出了混合模型 CNN (MoNet),这是一种空间方法,可将 CNN 架构统一推广到图。最近,汉密尔顿等人 (2017) 介绍了 GraphSAGE,一种以归纳方式计算节点表示的方法**。该技术的工作原理是对每个节点的固定大小的邻域进行采样,然后对其执行特定的聚合器(例如所有采样的邻域的特征向量的平均值,或者通过循环神经网络馈送它们的结果)。这种方法在多个大规模归纳基准测试中取得了令人印象深刻的性能。
- **注意力机制**几乎已经成为许多基于序列的任务中事实上的标准(Bah danau et al., 2015; Gehring et al., 2016)。注意力机制的好处之一是它们允许处理可变大小的输入,专注于输入中最相关的部分以做出决策。当注意力机制用于计算单个序列的表示时,通常称为自注意力或内部注意力。事实证明,与循环神经网络(RNN)或卷积一起,自注意力对于机器阅读(Cheng et al., 2016)和学习句子表示(Lin et al., 2017)等任务非常有用。然而,瓦斯瓦尼等人。 (2017)表明,自注意力不仅可以改进基于 RNN 或卷积的方法,而且足以构建一个强大的模型,在机器翻译任务上获得最先进的性能。
- 注意力机制 self-attention
- 优点:可以处理任意大小输入的问题,并且关注最具有影响能力的输入。
- 注意力机制再RNN与CNN之中,都取得了不错的效果,并且可以达到state of the art的性能。
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017
- 受这项最近工作的启发,我们引入了一种基于注意力的架构来执行图结构数据的节点分类。这个想法是通过关注其邻居并遵循自注意力策略来计算图中每个节点的隐藏表示。注意力架构有几个有趣的特性:(1)操作高效,因为它可以跨节点邻居对并行化; (2)通过给邻居指定任意权重,可以应用于具有不同度数的图节点; (3)该模型直接适用于归纳学习问题,包括模型必须泛化到完全看不见的图的任务。我们在四个具有挑战性的基准上验证了所提出的方法:Cora、Citeseer 和 Pubmed 引文网络以及归纳蛋白质-蛋白质相互作用数据集,实现或匹配最先进的结果,突出了基于注意力的模型的潜力处理任意结构的图。
- 值得注意的是,正如 Kipf & Welling (2017) 和 Atwood & Towsley (2016) 一样,我们的工作也可以重新表述为 MoNet 的一个特定实例 (Monti et al., 2016)。此外,我们跨边缘共享神经网络计算的方法让人想起关系网络(Santoro et al., 2017)和 VAIN(Hoshen, 2017)的公式,其中对象或代理之间的关系通过采用成对聚合共享机制。同样,我们提出的注意力模型可以与 Duan 等人的作品联系起来。 (2017)和丹尼尔等人。 (2017),它使用邻域注意力操作来计算环境中不同对象之间的注意力系数。其他相关方法包括局部线性嵌入 (LLE) (Roweis & Saul, 2000) 和记忆网络 (Weston et al., 2014)。 LLE 在每个数据点周围选择固定数量的邻居,并学习每个邻居的权重系数,以将每个点重建为其邻居的加权和。第二个优化步骤提取点的特征嵌入。记忆网络也与我们的工作共享一些联系,特别是,如果我们将节点的邻域解释为记忆,记忆网络用于通过关注其值来计算节点特征,然后通过将新特征存储在记忆网络中来进行更新。相同的位置。
2 GAT 架构
在本节中,我们将介绍用于构造任意图注意网络的构建块层(通过堆叠该层),并直接概述与神经图处理领域的先前工作相比其理论和实践的优点和局限性。
- 方法特性
- The idea is to compute the hidden representations of each node in the graph, by attending over its neighbors, following a self-attention strategy. 针对每一个节点运算相应的隐藏信息,在运算其相邻节点的时候引入注意力机制:
- 高效:针对相邻的节点对,并且可以并行运算
- 灵活:针对有不同度(degree)的节点,可以运用任意大小的weight与之对应。(这里我们解释一个概念,节点的度degree:表示的是与这个节点相连接的节点的个数)
- 可移植:可以将模型应用于从未见过的图结构数据,不需要与训练集相同。
2.1 图注意力层Graph Attention layer
输入
目的是学到每个点的embedding, h ⃗ i \vec h_i hi是一个F维的向量
- 输入:针对的是N个节点,按照其输入的feature预测输出的feature。
- h = { h ⃗ 1 , h ⃗ 2 , … 。。。 , h ⃗ N } , h ⃗ i ∈ R F h = \{\vec h_1,\vec h_2,…。 。 。 , \vec h_N \},\vec h_i \in R^F h={h1,h2,…。。。,hN},hi∈RF
- N为节点的个数,F为feature的个数,这表示输入为N个节点的每个节点的F个feature
- h ′ = h ⃗ 1 ′ , h ⃗ 2 ′ , . . . , h ⃗ N ′ , h ⃗ i ′ ∈ R F ′ h' = {\vec h'_1,\vec h'_2 ,..., \vec h'_N },\vec h'_i \in R^{F'} h′=h1′,h2′,...,hN′,hi′∈RF′
- 表示对这N个节点的 F’ 个输出,输出位N个节点的每个节点的F’个feature
- 矩阵X,input 特征是:h(N*F的维度)——N个点,每个点有F个固有特征(attributes)
- 邻接矩阵:表示两个点之间是否有边,或者边的weight是多少
- F’一般不等于F,F‘是输入维度,F是embedding输出维度
特征提取和注意力机制
为了得到相应的输入与输出的转换,我们需要根据输入的feature至少一次线性变换得到输出的feature,所以我们需要对所有节点训练一个权值矩阵: W ∈ R F ′ × F W\in R^{F'×F} W∈RF′×F,这个权值矩阵就是输入与输出的F个feature与输出的F’个feature之间的关系。
We then perform self-attention on the nodes—a shared attentional mechanism,针对每个节点实行self-attention的注意力机制,机制为 α : R F ′ × F − > R \alpha :R^{F'×F}->R α:RF′×F−>R
注意力互相关系数为attention coefficients: e i j = α ( W h ⃗ i , W h ⃗ j ) e_{ij}=\alpha (W\vec h_i,W\vec h_j) eij=α(Whi,Whj)
- 这个公式表示的节点 j 对于节点 i 的重要性,而不去考虑图结构性的信息
- 如前面所言,向量h就是 feature向量
- 下标i,j表示第i个节点和第j个节点
作者通过masked attention将这个注意力机制引入图结构之中,masked attention的含义 :只计算节点 i i i 的相邻的节点 j j j
节点 j j j 为 j ∈ N i j\in N_i j∈Ni,其中 N i N_i Ni为 节点 i i i的所有相邻节点。为了使得互相关系数更容易计算和便于比较,我们引入了softmax对所有的i的相邻节点j进行正则化: α i j = s o f t m a x j ( e i j ) = e x p ( e i j ) ∑ k ∈ N i e x p ( e i j ) \alpha_{ij}=softmax_j(e_{ij})=\frac{exp(e_{ij})}{\sum_{k\in N_i}exp(e_{ij})} αij=softmaxj(eij)=∑k∈Niexp(eij)exp(eij)
实验之中,注意力机制a是一个单层的前馈神经网络,通过权值向量来确定 α ⃗ ∈ R 2 F ′ \vec \alpha \in R^{2F'} α∈R2F′,并且加入了 LeakyRelu的非线性激活,这里小于零斜率为0.2。(这里我们回顾下几种Relu函数,relu:小于0就是0,大于零斜率为1;LRelu:小于零斜率固定一个值,大于零斜率为1;PRelu:小于零斜率可变,大于零斜率为1;还有CRelu,Elu,SELU)。注意力机制如下:
α i j = e x p ( L e a k y R e L U a ⃗ T [ W h ⃗ i ∣ ∣ W h ⃗ j ] ) ) ∑ k ∈ N i e x p ( L e a k y R e L U a ⃗ T [ W h ⃗ i ∣ ∣ W h ⃗ k ] α_{ij} = \frac{exp (LeakyReLU \vec a^T [W\vec h_i|| W\vec h_j ]))}{\sum_{ k\in N_i} exp (LeakyReLU ~ \vec a^T [W \vec h_i|| W\vec h_k]} αij=∑k∈Niexp(LeakyReLU aT[Whi∣∣Whk]exp(LeakyReLUaT[Whi∣∣Whj])),也是我们前面需要得到的注意力互相关系数
e i j = a ( W h ⃗ i , W h ⃗ j ) e_{ij} = a(W\vec h_i,W\vec h_j ) eij=a(Whi,Whj)
- 模型权重为: α ⃗ ∈ R 2 F ′ \vec \alpha \in R^{2F'} α∈R2F′
- 转置表示为T
- concatenation 用 || 表示
- 公式含义就是权值矩阵与F’个特征相乘,然后节点相乘后并列在一起,与权重 α ⃗ ∈ R 2 F ′ \vec \alpha \in R^{2F'} α∈R2F′相乘,LRelu激活后指数操作得到softmax的分子。
def forward(self, x): # [B_batch,N_nodes,C_channels] B, N, C = x.size() # h = torch.bmm(x, self.W.expand(B, self.in_features, self.out_features)) # [B,N,C] h = torch.matmul(x, self.W) # [B,N,C] a_input = torch.cat([h.repeat(1, 1, N).view(B, N * N, C), h.repeat(1, N, 1)], dim=2).view(B, N, N, 2 * self.out_features) # [B,N,N,2C] # temp = self.a.expand(B, self.out_features * 2, 1) # temp2 = torch.matmul(a_input, self.a) attention = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(3)) # [B,N,N] attention = F.softmax(attention, dim=2) # [B,N,N] attention = F.dropout(attention, self.dropout, training=self.training) h_prime = torch.bmm(attention, h) # [B,N,N]*[B,N,C]-> [B,N,C] out = F.elu(h_prime + self.beta * h) return out
Output features
通过上面,运算得到了正则化后的不同节点之间的注意力互相关系数normalized attention coefficients,可以用来预测每个节点的output feature:
h ⃗ i ′ = ∣ ∣ k = 1 K σ ( ∑ j ∈ N i α i j k W k h ⃗ j ) \vec h'_i =||_{k=1}^K \sigma (\sum_{j∈N_i} \alpha^k_{ij}W^k \vec h_j) hi′=∣∣k=1Kσ(j∈Ni∑αijkWkhj)
- 我们再回顾一下含义,W为与feature相乘的权值矩阵
- a为前面算得的注意力互相关系数
- σ \sigma σ为非线性激活
- 遍历的j 表示所有与i 相邻的节点
- 这个公式表示就是,该节点的输出feature与与之相邻的所有节点有关,是他们的线性和的非线性激活
- 这个线性和的线性系数是前面求得的注意力互相关系数
multi-head attention
multi-head attention与下面这个工作类似:
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
在上面的output feature加入计算multi-head的运算公式:
h ⃗ i ′ = ∣ ∣ k = 1 K σ ( ∑ j ∈ N i α i j k W k h ⃗ j ) \vec h'_i =||_{k=1}^K \sigma (\sum_{j∈N_i} \alpha^k_{ij}W^k \vec h_j) hi′=∣∣k=1Kσ(j∈Ni∑αijkWkhj)
concate操作为||
第k个注意力机制为 ( α k ) (\alpha^k) (αk)
共大K个注意力机制需要考虑,小k表示大K中的第k个
输入特征的线性变换表示为 W k W^k Wk
最终的输出为h’ 共由KF’ 个特征影响
例如,K=3时候,结构如下
例如此图,节点1在邻域中具有多端注意机制,不同的箭头样式表示独立的注意力计算,通过连接或平均每个head获取 h1
对于最终的输出,concate操作可能不那么敏感了,所以我们直接用K平均来取代concate操作,得到最终的公式:
h ⃗ i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h ⃗ j ) \vec h'_i = \sigma (\frac{1}{K}\sum_{k=1}^K \sum_{j∈N_i} \alpha^k_{ ij}W^k\vec h_j) hi′=σ(K1k=1∑Kj∈Ni∑αijkWkhj)

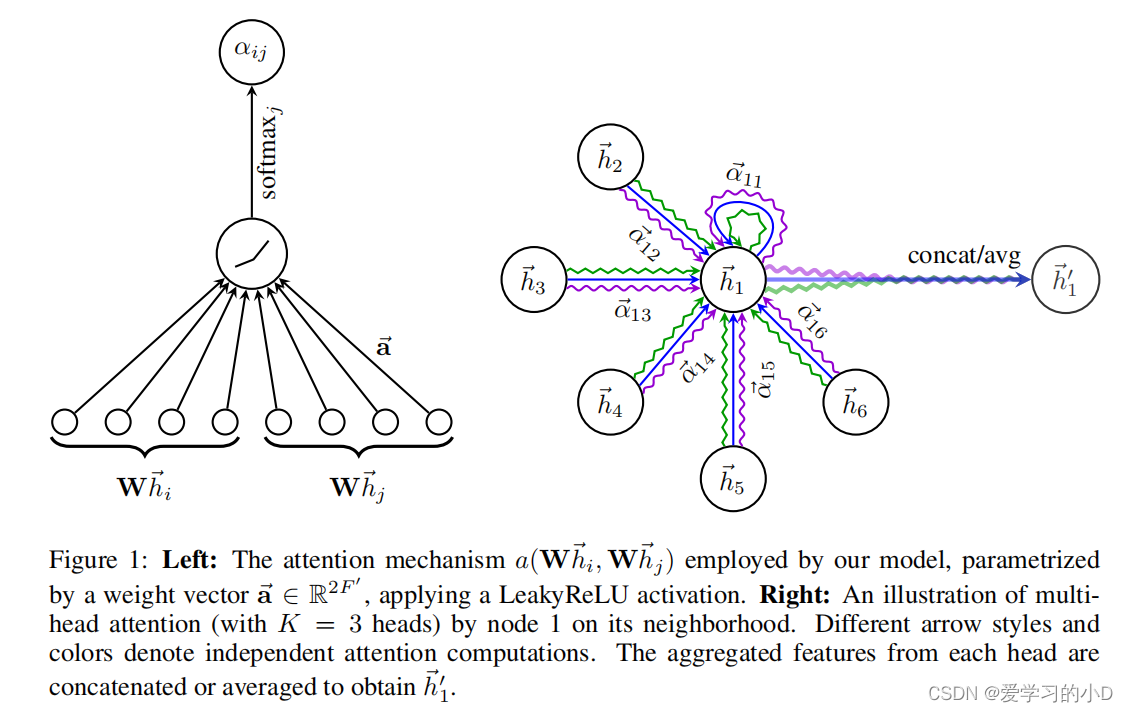
- 我们将从描述单个图注意力层开始,它是我们实验中使用的所有 GAT 架构中使用的唯一层。我们使用的特殊注意力设置密切遵循 Bahdanau 等人的工作。 (2015)——但是该框架对于注意力机制的特定选择是不可知的。我们层的输入是一组节点特征, h = { h ⃗ 1 , h ⃗ 2 , … 。。。 , h ⃗ N } , h ⃗ i ∈ R F h = \{\vec h_1,\vec h_2,…。 。 。 , \vec h_N \},\vec h_i \in R^F h={h1,h2,…。。。,hN},hi∈RF ,其中 N N N 是节点数, F F F 是每个节点中的特征数。该层生成一组新的节点特征(可能具有不同的基数 F ′ F' F′ ), h ′ = h ⃗ 1 ′ , h ⃗ 2 ′ , . . . , h ⃗ N ′ , h ⃗ i ′ ∈ R F ′ h' = {\vec h'_1,\vec h'_2 ,..., \vec h'_N },\vec h'_i \in R^{F'} h′=h1′,h2′,...,hN′,hi′∈RF′ ,作为其输出。为了获得足够的表达能力将输入特征转换为更高级别的特征,至少需要一种可学习的线性变换。为此,作为初始步骤,将由权重矩阵 W ∈ R F ′ × F W ∈ R^{F ' ×F} W∈RF′×F 参数化的共享线性变换应用于每个节点。然后,我们对节点执行自注意力——一种共享注意力机制 a : R F ′ × R F ′ → R a : R^{F'} × R^{F'} → R a:RF′×RF′→R 计算注意力系数
e i j = a ( W h ⃗ i , W h ⃗ j ) e_{ij} = a(W\vec h_i,W\vec h_j ) eij=a(Whi,Whj)
- 该系数表明节点 j j j 的特征对节点岛。在其最一般的表述中,该模型允许每个节点参与其他每个节点,从而丢弃所有结构信息。我们通过执行屏蔽注意力将图结构注入到机制中——我们只计算节点 j ∈ N i j ∈ N_i j∈Ni 的 e i j e_{ij} eij ,其中 N i N_i Ni 是图中节点 i i i 的某个邻域。在我们所有的实验中,这些将恰好是 i (包括 i ) i(包括 i) i(包括i)的一阶邻居。为了使不同节点之间的系数易于比较,我们使用 softmax 函数对 j j j 的所有选择进行标准化:
α i j = s o f t m a x j ( e i j ) = e x p ( e i j ) ∑ k ∈ N i e x p ( e i k ) α_{ij} = softmax_j (e_{ij}) = \frac{exp(e_{ij} )} { \sum_{k\in N_i} exp(e_{ik})} αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)
- 在我们的实验中,注意力机制 a 是一个单层前馈神经网络,由权重向量 ~ a ∈ R2F 0 参数化,并应用 LeakyReLU 非线性(负输入斜率 α = 0.2)。完全展开后,注意力机制计算的系数(如图 1(左)所示)可表示为:
α i j = e x p ( L e a k y R e L U a ⃗ T [ W h ⃗ i ∣ ∣ W h ⃗ j ] ) ) ∑ k ∈ N i e x p ( L e a k y R e L U a ⃗ T [ W h ⃗ i ∣ ∣ W h ⃗ k ] α_{ij} = \frac{exp (LeakyReLU \vec a^T [W\vec h_i|| W\vec h_j ]))}{\sum_{ k\in N_i} exp (LeakyReLU ~ \vec a^T [W \vec h_i|| W\vec h_k]} αij=∑k∈Niexp(LeakyReLU aT[Whi∣∣Whk]exp(LeakyReLUaT[Whi∣∣Whj]))
-
其中 ⋅ T ^{·T} ⋅T 表示转置, ∣ ∣ || ∣∣ 是串联运算。
-
一旦获得,归一化注意力系数将用于计算与其相对应的特征的线性组合,作为每个节点的最终输出特征(在可能应用非线性之后,σ):
-
h ⃗ i ′ = σ ( ∑ j ∈ N i ( α i j ) W h ⃗ j ) \vec h_i'=\sigma(\sum_{j \in N_i(\alpha_{ij})}W\vec h_j) hi′=σ(j∈Ni(αij)∑Whj)
-
为了稳定自注意力的学习过程,我们发现扩展我们的机制以采用多头注意力是有益的,类似于 Vaswani 等人。 (2017)。具体来说,K个独立注意力机制执行等式4的变换,然后将它们的特征连接起来,得到以下输出特征表示:
h ⃗ i ′ = ∣ ∣ k = 1 K σ ( ∑ j ∈ N i α i j k W k h ⃗ j ) \vec h'_i =||_{k=1}^K \sigma (\sum_{j∈N_i} \alpha^k_{ij}W^k \vec h_j) hi′=∣∣k=1Kσ(j∈Ni∑αijkWkhj)
-
其中 k k k 表示串联, α i j k α^k_{ij} αijk 是由第 k k k 个注意力机制$ (a^k )$ 计算的归一化注意力系数, W k W^k Wk 是相应的输入线性变换的权重矩阵。请注意,在此设置中,最终返回的输出 h ′ h' h′ 将由每个节点的 K F ′ KF' KF′ 特征(而不是 F ′ F' F′ )组成。特别是,如果我们在网络的最后(预测)层上执行多头注意力,串联就不再明智了——相反,我们采用平均,并延迟应用最终的非线性(通常是用于分类问题的 softmax 或逻辑 sigmoid ) 直到那时:
-
h ⃗ i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h ⃗ j ) \vec h'_i = \sigma (\frac{1}{K}\sum_{k=1}^K \sum_{j∈N_i} \alpha^k_{ ij}W^k\vec h_j) hi′=σ(K1k=1∑Kj∈Ni∑αijkWkhj)
-
多头图注意力层的聚合过程如图 1(右)所示。
2.2 与相关工作的比较
算法复杂度低
GAT运算得到F’个特征需要的算法复杂度 O ( ∣ V ∣ F F ′ + ∣ E ∣ F ′ ) O(|V |F F' + |E|F' ) O(∣V∣FF′+∣E∣F′)
- F’:为输出特征的个数
- F:为输入特征的个数
- |V| :节点的个数
- |E|:节点之间连接的个数
并且引入K之后,对于每个head的运算都独立并且可以并行
更好鲁棒性
与GCN的不同在于,GAT针对不同的相邻节点的重要性进行预测,模型具有更好的性能并且对于扰动更加鲁棒。
不需要整张Graph
引入注意力机制之后,只与相邻节点有关,即共享边的节点有关,无需得到整张graph的信息。
- 即使丢失了i,j之间的链接,则不计算 α i j \alpha_{ij} αij即可
- 可以将模型运用于inductive learning,更好解释性,即使graph完全看不到completely unseen,也可以运行训练过程
比LSTM更强
The recently published inductive method of Hamilton et al. (2017) samples a fixed-size neighborhood of each node, in order to keep its computational footprint consistent; this does not allow it access to the entirety of the neighborhood while performing inference. Moreover, this technique achieved some of its strongest results when an LSTM (Hochreiter & Schmidhuber, 1997)-based neighborhood aggregator is used. This assumes the existence of a consistent sequential node ordering across neighborhoods, and the authors have rectified it by consistently feeding randomly-ordered sequences to the LSTM. Our technique does not suffer from either of these issues—it works with the entirety of the neighborhood (at the expense of a variable computational footprint, which is still on-par with methods like the GCN), and does not assume any ordering within it.
2017年Hamilton提出的inductive method为每一个node都抽取一个固定尺寸的neighborhood,为了计算的时候footprint是一致的(指的应该是计算的时候处理neighborhood的模式是固定的,不好改变,因此每次都抽样出固定数量的neighbor参与计算),这样,在计算的时候就不是所有的neighbor都能参与其中。此外,Hamilton的这个模型在使用一些基于LSTM的方法的时候能得到最好的结果,这样就是假设了每个node的neighborhood的node一直存在着一个顺序,使得这些node成为一个序列。但是本文提出的方法就没有这个问题,每次都可以将neighborhood所有的node都考虑进来,而且不需要事先假定一个neighborhood的顺序
与MoNet的对比
As mentioned in Section 1, GAT can be reformulated as a particular instance of MoNet (Monti et al., 2016). More specifically, setting the pseudo-coordinate function to be u(x, y) = f(x)kf(y), where f(x) represent (potentially MLP-transformed) features of node x and k is concatenation; and the weight function to be wj(u) = softmax(MLP(u)) (with the softmax performed over the entire neighborhood of a node) would make MoNet’s patch operator similar to ours. Nevertheless, one should note that, in comparison to previously considered MoNet instances, our model uses node features for similarity computations, rather than the node’s structural properties (which would assume knowing the graph structure upfront). GAT可以看做一个MoNet的特例。
第 2.1 小节中描述的图注意力层直接解决了先前使用神经网络对图结构数据进行建模的方法中存在的几个问题:
- 在计算上,它非常高效:自注意力层的操作可以可以在所有边上并行化,并且输出特征的计算可以在所有节点上并行化。不需要特征分解或类似的昂贵的矩阵运算。单个GAT注意力头计算F0特征的时间复杂度可以表示为 O ( ∣ V ∣ F F ′ + ∣ E ∣ F ′ ) O(|V |F F' + |E|F' ) O(∣V∣FF′+∣E∣F′),其中 F F F是输入特征的数量, ∣ V ∣ 和 ∣ E ∣ |V |和|E| ∣V∣和∣E∣分别是图中的节点数和边数。这种复杂性与图卷积网络 (GCN) 等基线方法相当(Kipf & Welling,2017)。应用多头注意力将存储和参数要求乘以 K 倍,而各个头的计算是完全独立的并且可以并行化。
- 与GCN 不同,我们的模型允许(隐式)为同一邻域的节点分配不同的重要性,从而实现模型容量的飞跃。此外,分析学习到的注意力权重可能会带来可解释性方面的好处,就像机器翻译领域的情况一样(例如 Bahdanau 等人(2015)的定性分析)。
- 注意机制以共享的方式应用于图中的所有边,因此它不依赖于对全局图结构或其所有节点(的特征)的预先访问(许多现有技术的限制)。这有几个理想的含义:
- – 该图不需要是无向的(如果边 j → i j → i j→i不存在,我们可以简单地省略计算 α i j α_{ij} αij)。
- – 它使我们的技术直接适用于归纳学习,包括在训练期间完全看不到的图表上评估模型的任务。
- Hamilton 等人最近发表的归纳法。 (2017) 对每个节点的固定大小邻域进行采样,以保持其计算足迹一致;这不允许它在执行推理时访问整个邻域。此外,当使用基于 LSTM(Hochreiter & Schmidhuber,1997)的邻域聚合器时,该技术取得了一些最强的结果。这假设跨邻域存在一致的顺序节点排序,并且作者通过一致地将随机排序的序列输入 LSTM 来纠正它。我们的技术不会遇到这些问题——它适用于整个邻域(以可变的计算足迹为代价,这仍然与 GCN 等方法相同),并且不假设其中有任何顺序。
- 如第 1 节所述,GAT 可以重新表述为 MoNet 的特定实例(Monti 等人,2016)。更具体地说,将伪坐标函数设置为 u ( x , y ) = f ( x ) ∣ ∣ f ( y ) u(x, y) = f(x)||f(y) u(x,y)=f(x)∣∣f(y),其中 f ( x ) f(x) f(x)表示节点 x x x 的(可能是 MLP 变换的)特征, k k k 是级联;并且权重函数为 $w_j (u) = softmax(MLP(u)) $(在节点的整个邻域上执行 softmax)将使 MoNet 的 patch 算子与我们的类似。然而,应该注意的是,与之前考虑的 MoNet 实例相比,我们的模型使用节点特征进行相似性计算,而不是节点的结构属性(假设预先知道图结构)。
我们能够生成一个利用稀疏矩阵运算的 GAT 层版本,将存储复杂性降低到节点和边数量的线性,并能够在更大的图形数据集上执行 GAT 模型。然而,我们使用的张量操作框架仅支持 2 阶张量的稀疏矩阵乘法,这限制了当前实现的层的批处理能力(特别是对于具有多个图的数据集)。妥善解决这一制约因素是今后工作的重要方向。根据现有图形结构的规律性,在这些稀疏场景中,与 CPU 相比,GPU 可能无法提供主要的性能优势。还应该注意的是,我们模型的“感受野”的大小受到网络深度的上限(与 GCN 和类似模型类似)。然而,诸如跳跃连接(He et al., 2016)之类的技术可以很容易地应用于适当扩展深度。最后,跨所有图边的并行化,尤其是以分布式方式,可能涉及大量冗余计算,因为邻域通常在感兴趣的图中高度重叠。
3 评估
实验分成两部分,transductive learning(半监督学习)和inductive learning(归纳学习)。模型用了两层的GAT
我们在四个已建立的基于图的基准任务(传导性和归纳性)上对 GAT 模型与各种强基线和以前的方法进行了比较评估,在各个领域实现或匹配最先进的性能他们全部。本节总结了我们的实验设置、结果以及对 GAT 模型提取的特征表示的简要定性分析。
3.1 数据集
- Transductive learning:我们利用三个标准引文网络基准数据集——Cora、Citeseer 和 Pubmed(Sen 等人,2008)——并严格遵循 Yang 等人的转导式实验设置。 (2016)。在所有这些数据集中,节点对应于文档,边缘对应于(无向)引用。节点特征对应于文档的词袋表示的元素。每个节点都有一个类标签。我们只允许每个类使用 20 个节点进行训练,但是,根据转导设置,训练算法可以访问所有节点的特征向量。训练模型的预测能力在 1000 个测试节点上进行评估,我们使用 500 个额外节点进行验证(与 Kipf 和 Welling (2017) 使用的节点相同)。 Cora 数据集包含 2708 个节点、5429 个边、7 个类以及每个节点 1433 个特征。 Citeseer 数据集包含 3327 个节点、4732 个边、6 个类以及每个节点 3703 个特征。 Pubmed 数据集包含 19717 个节点、44338 个边、3 个类和每个节点 500 个特征。
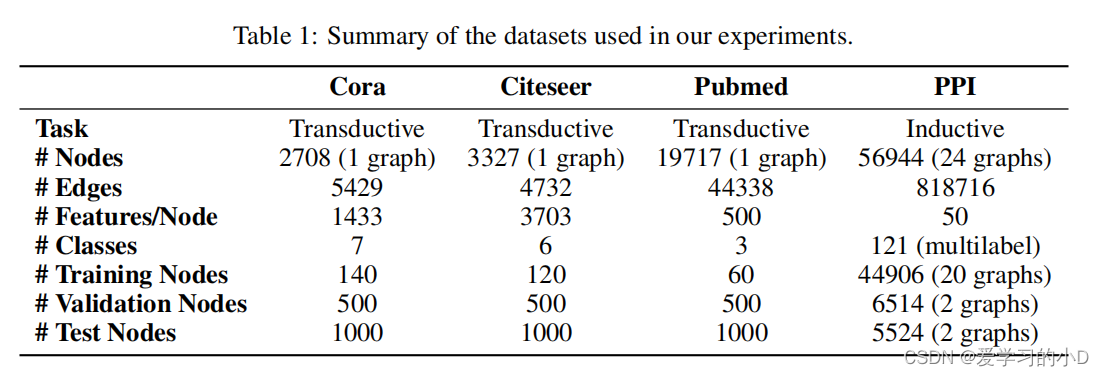
- Inductive learning 归纳学习:我们利用蛋白质-蛋白质相互作用(PPI)数据集,该数据集由对应于不同人体组织的图表组成(Zitnik&Leskovec,2017)。该数据集包含 20 个用于训练的图表、2 个用于验证的图表和 2 个用于测试的图表。至关重要的是,在训练期间测试图仍然完全未被观察到。为了构建图表,我们使用了 Hamilton 等人提供的预处理数据。 (2017)。每张图的平均节点数为 2372。每个节点有 50 个特征,由位置基因集、基序基因集和免疫学特征组成。从基因本体论中,每个节点集有 121 个标签,这些标签是从分子特征数据库(Subramanian 等人,2005)收集的,并且一个节点可以同时拥有多个标签。表 1 给出了数据集有趣特征的概述。
3.2 最先进的方法
- Transductive learning对于转导式学习任务,我们与指定的相同的强基线和最先进的方法进行比较在 Kipf & Welling (2017) 中。这包括标签传播(LP)(Zhu et al., 2003)、半监督嵌入(SemiEmb)(Weston et al., 2012)、流形正则化(ManiReg)(Belkin et al., 2006)、基于skip-gram的方法图嵌入(Deep Walk)(Perozzi et al., 2014)、迭代分类算法(ICA)(Lu & Getoor, 2003)和 Planetoid(Yang et al., 2016)。我们还直接将我们的模型与 GCN 进行比较(Kipf & Welling,2017),以及利用高阶切比雪夫滤波器的图卷积模型(Defferrard 等人,2016),以及 Monti 等人提出的 MoNet 模型。 (2016)。
- Inductive learning 对于归纳学习任务,我们与 Hamilton 等人提出的四种不同的监督 GraphSAGE 归纳方法进行了比较。 (2017)。这些提供了多种方法来聚合采样邻域内的特征:GraphSAGE-GCN(将图卷积式操作扩展到归纳设置)、GraphSAGE-mean(取特征向量的元素平均值)、GraphSAGE-LSTM(通过将邻域特征输入 LSTM 进行聚合)和 GraphSAGE 池(对由共享非线性多层感知器转换的特征向量进行元素最大化操作)。其他转导方法要么在归纳设置中完全不合适,要么假设节点被增量添加到单个图中,从而使它们无法用于在训练期间完全看不到测试图的设置(例如 PPI 数据集)。此外,对于这两项任务,我们提供了每节点共享多层感知器(MLP)分类器(根本不包含图结构)的性能。
3.3 实验设置
- Transductive learning :对于转导式学习任务,我们应用了两层 GAT 模型。其架构超参数已在 Cora 数据集上进行了优化,然后重新用于 Cite seer。第一层由 K = 8 个注意力头组成,每个注意力头计算 F0 = 8 个特征(总共 64 个特征),后面是一个指数线性单元 (ELU) (Clevert et al., 2016) 非线性。第二层用于分类:计算 C 个特征(其中 C 是类数)的单个注意力头,然后是 softmax 激活。为了应对较小的训练集大小,在模型中广泛应用了正则化。在训练期间,我们应用 λ = 0.0005 的 L2 正则化。此外,p = 0.6 的 dropout(Srivastava 等人,2014)应用于两个层的输入以及归一化注意力系数(关键的是,这意味着在每次训练迭代时,每个节点都暴露于随机采样的邻里)。与 Monti 等人观察到的类似。 (2016),我们发现 Pubmed 的训练集大小(60 个示例)需要对 GAT 架构进行轻微更改:我们应用了 K = 8 个输出注意头(而不是 1 个),并将 L2 正则化加强到 λ = 0.001。除此之外,该架构与 Cora 和 Citeseer 使用的架构相匹配。
- Inductive learning:归纳学习 对于归纳学习任务,我们应用了三层 GAT 模型。前两层均由 K = 4 个注意力头组成,计算 F0 = 256 个特征(总共 1024 个特征),后面是 ELU 非线性。最后一层用于(多标签)分类:K = 6 个注意力头,每个注意力头计算 121 个特征,对这些特征进行平均,然后进行逻辑 sigmoid 激活。该任务的训练集足够大,我们发现不需要应用 L2 正则化或 dropout——但是,我们已经成功地在中间注意力层中使用了跳跃连接(He et al., 2016)。我们在训练期间使用 2 个图的批量大小。为了严格评估在这种情况下应用注意力机制的好处(即与接近 GCN 等效的模型进行比较),我们还提供了使用恒定注意力机制 a(x, y) = 1 时的结果,其中相同的架构——这将为每个邻居分配相同的权重。
两个模型均使用 Glorot 初始化(Glorot & Bengio,2010)进行初始化,并使用 Adam SGD 优化器(Kingma & Ba,2014)进行训练,以最小化训练节点上的交叉熵,Pubmed 的初始学习率为 0.01,Pubmed 的初始学习率为 0.005。对于所有其他数据集。在这两种情况下,我们对验证节点上的交叉熵损失和准确性(传导)或微 F1(归纳)分数都使用早期停止策略,耐心为 100 epochs1。
3.4 结果
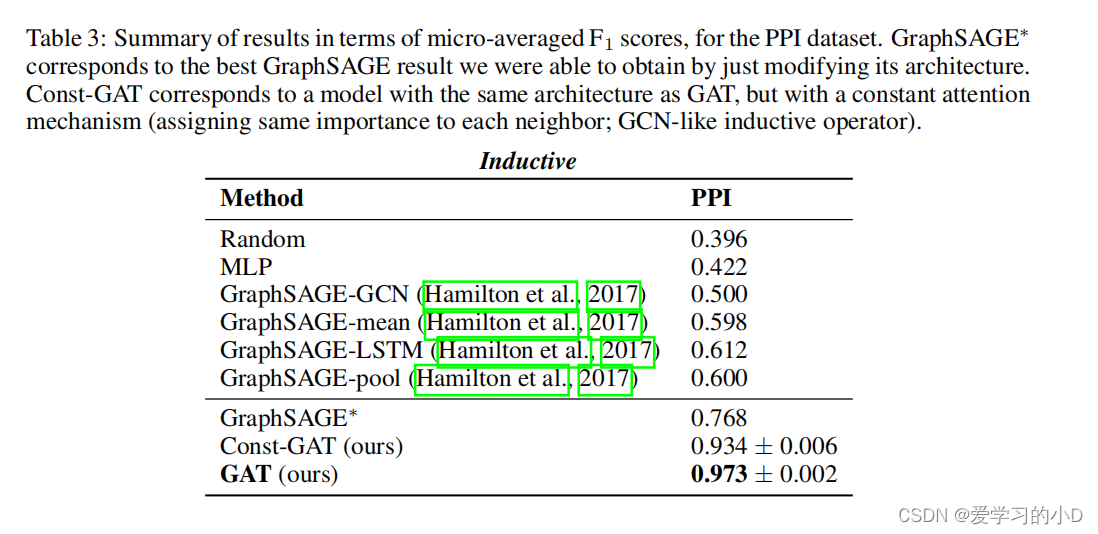
我们的比较评估实验的结果总结在表 2 和表 3 中。
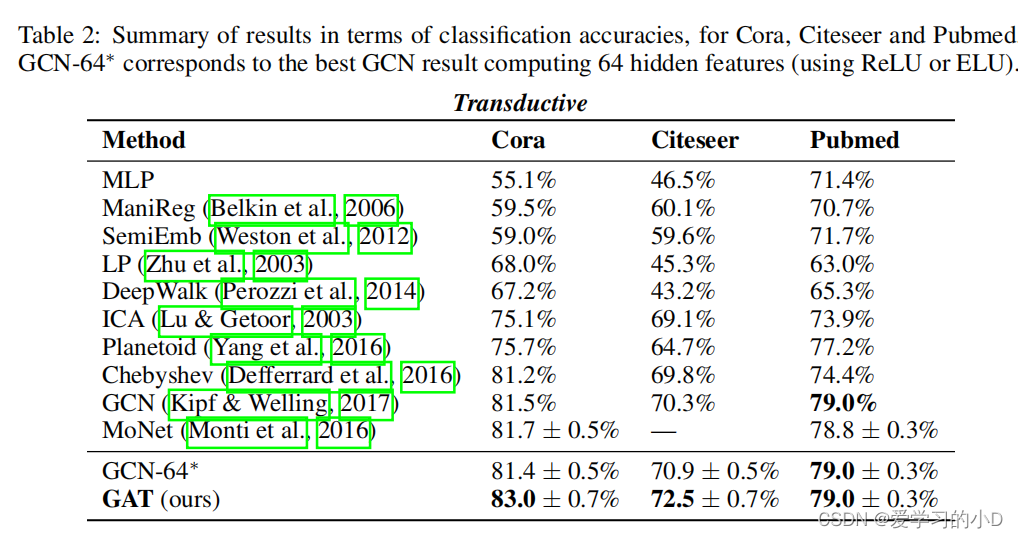
- 对于传导任务,我们报告 100 次运行后我们方法的测试节点上的平均分类精度(带标准差),并重用已经报告的指标在 Kipf & Welling (2017) 和 Monti 等人中。 (2016)最先进的技术。具体来说,对于基于切比雪夫滤波器的方法(Defferrard et al., 2016),我们提供了阶数 K = 2 和 K = 3 的滤波器的最大报告性能。为了公平地评估注意力机制的好处,我们进一步评估一个计算 64 个隐藏特征的 GCN 模型,尝试 ReLU 和 ELU 激活,并在 100 次运行后报告(作为 GCN-64*)更好的结果(这是所有三种情况下的 ReLU)。
- 对于归纳任务,我们报告两个未见过的测试图的节点上的微平均 F1 分数,在 10 次运行后取平均值,并重用 Hamilton 等人中已经报告的指标。 (2017)其他技术。具体来说,当我们的设置受到监督时,我们将与监督的 GraphSAGE 方法进行比较。为了评估在整个邻域中聚合的好处,我们进一步提供(作为 GraphSAGE* )我们能够通过修改 GraphSAGE 的架构来实现的最佳结果(这是使用具有 [512, 512 ,726]每层计算的特征和用于聚合邻域的 128 个特征)。最后,我们报告了持续关注 GAT 模型(作为 Const-GAT)的 10 次运行结果,以公平地评估关注机制相对于类似 GCN 的聚合方案(具有相同架构)的好处。
- 我们的结果成功地证明了在所有四个数据集上实现或匹配的最先进的性能 - 符合我们的预期,如第 2.2 节中的讨论所述。更具体地说,我们能够在 Cora 和 Cite seer 上分别比 GCN 提高 1.5% 和 1.6%,这表明为同一邻域的节点分配不同的权重可能是有益的。值得注意的是 PPI 数据集上实现的改进:我们的 GAT 模型比我们能够获得的最佳 GraphSAGE 结果提高了 20.5%,这表明我们的模型有潜力应用于归纳设置,并且更大的预测能力可以通过观察整个社区来发挥作用。此外,它相对于 Const-GAT(具有持续注意力机制的相同架构)提高了 3.9%,再次直接证明了能够为不同邻居分配不同权重的重要性。
- 学习到的特征表示的有效性也可以进行定性研究——为此,我们提供了 t-SNE (Maaten & Hinton, 2008) 转换特征表示的可视化,这些特征表示是由预训练的 GAT 模型的第一层提取的Cora 数据集(图 2)。该表示在投影的 2D 空间中表现出明显的聚类。请注意,这些集群对应于数据集的七个标签,验证了模型在 Cora 七个主题类别中的区分能力。此外,我们可视化标准化注意力系数的相对强度(所有八个注意力头的平均值)。正确解释这些系数(如 Bahdanau 等人 (2015) 所执行的)将需要有关所研究的数据集的进一步领域知识,并留待将来的工作
4 结论
-
我们提出了图注意力网络(GAT),这是一种新颖的卷积式神经网络,它利用屏蔽的自注意力层对图结构数据进行操作。在这些网络中使用的图注意层计算效率高(不需要昂贵的矩阵运算,并且可以在图中的所有节点上并行化),允许(隐式)为邻域内的不同节点分配不同的重要性,同时处理不同的节点大小的邻域,并且不依赖于预先了解整个图结构,从而解决了以前基于谱的方法的许多理论问题。我们利用注意力的模型已经成功地在四个成熟的节点分类基准中实现或匹配最先进的性能,包括传导性和归纳性(特别是用于测试的完全不可见的图)。
-
图注意力网络有一些潜在的改进和扩展,可以在未来的工作中解决,例如克服 2.2 小节中描述的实际问题,以便能够处理更大的批量大小。一个特别有趣的研究方向是利用注意力机制对模型的可解释性进行彻底的分析。此外,从应用的角度来看,扩展该方法以执行图分类而不是节点分类也将是相关的。最后,扩展模型以合并边缘特征(可能指示节点之间的关系)将使我们能够解决更多种类的问题。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









