






你可以把大模型节点想象成一个超级智能的 "文字魔法师"。它就像学校里最会写作文的同学,但比人类厉害很多倍!
这个魔法师能帮你做各种文字工作:
-
写东西:比如广告文案(就像帮奶茶店想宣传语)、作文扩写(把 200 字的梗概变成 800 字的故事)
-
总结归纳:把长文章缩写成要点(像做读书笔记)
-
改写内容:把专业报告改写成通俗易懂的话
它为什么这么厉害?
-
能看懂各种复杂的句子(就像老师能看懂你写的所有作文)
-
可以扮演不同角色(比如用班主任的语气写通知,或用网红博主语气写探店文案)
-
通过 "调参数" 控制效果:就像手机调节亮度,你可以调节:
-
文章长短(像调节水龙头出水量)
-
创意程度(像调节脑洞大小,要正经还是要天马行空)
-
避免重复(像给作文检查器)
-
举个实际例子:
如果你要帮学校社团招新,可以:
-
选择 "活泼有趣" 的模式
-
输入提示:"写一个动漫社招新文案,要吸引新生"
-
调节参数让文字更简短有力 这个魔法师就会生成像:"快来动漫社!cosplay、漫画创作、动漫观影会... 这里能找到你的二次元同好!🎉"
这个工具虽然厉害,但需要你给出清晰的指令(就像你要告诉同学作文要写什么主题),才能得到满意的结果哦!
模型

选择要使用的模型。此节点的输出内容质量很大程度上受模型能力的影响,建议根据实际业务场景选择模型。
支持选择扣子官方、火山方舟系列模型,如豆包系列和最近大火的DeepseekR1、V3等模型。

重点解释一下这些模型的区别:
Pro为全能模型,最好用。
Lite为极速版模型,效果稍微差点,但速度快、便宜
Vision为视觉模型、可以理解图片的意思
工具调用是为调用插件专门定制的模型,需要大模型调用插件时选他
技能
这就像你有一个超级聪明的手机助手,但它原本只会回答书本上的知识。现在我们可以给它安装各种 "技能包"(插件),让它变得更强大。比如说:
-
原本要查天气再推荐穿搭,需要你分两步操作:
-
先问天气助手:"上海今天多少度?"
-
然后告诉穿搭助手:"25 度该穿什么?"
-
现在有了 "技能包",你只需要说:"推荐上海的今日穿搭" 这个超级助手就会自动: ① 先查上海天气 ② 根据温度推荐衣服 整个过程就像有个小秘书在帮你跑腿办事!
这些 "技能包" 包括:
🔌 插件:类似手机 APP(比如天气查询、计算器)
📚 知识库:像给它装了一本百科全书
🔄 工作流:让它学会按顺序处理复杂任务
这样做的好处是:
✓ 它能自己判断什么时候该用什么工具
✓ 处理复杂问题更聪明
✓ 不用手动安排步骤,就像玩游戏开了自动战斗模式
比如你想知道 "东京奥运会中国拿了多少金牌?",它就会自动上网查数据,整理好告诉你,不用你先查数字再让它总结。
点击即可为大模型添加技能
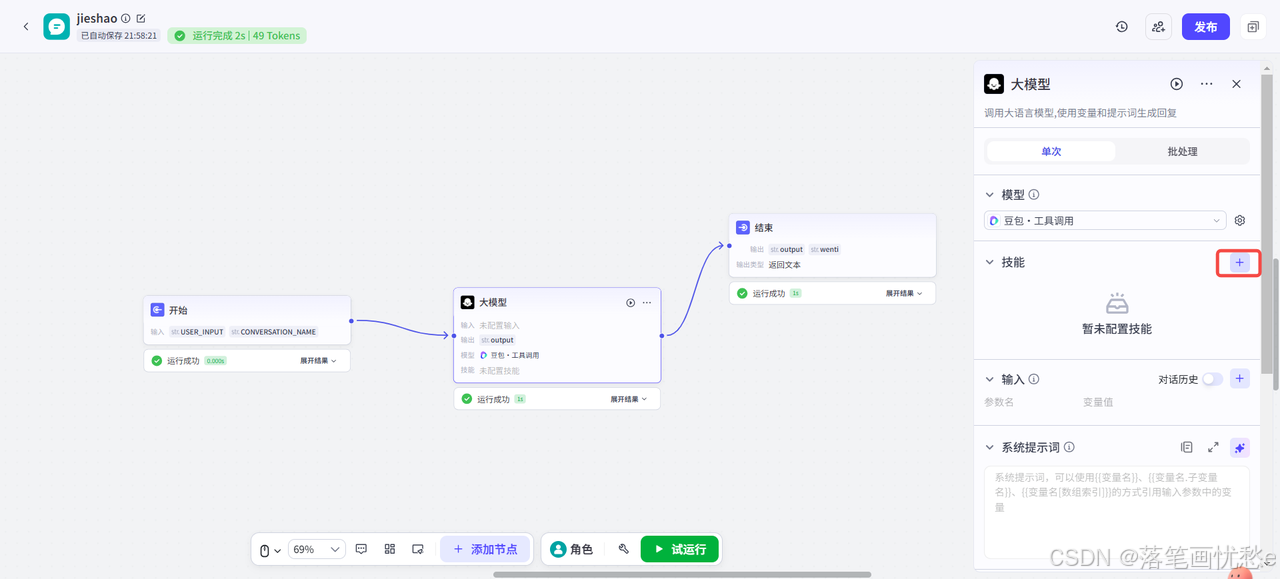
选择需要的插件和工具,点击添加
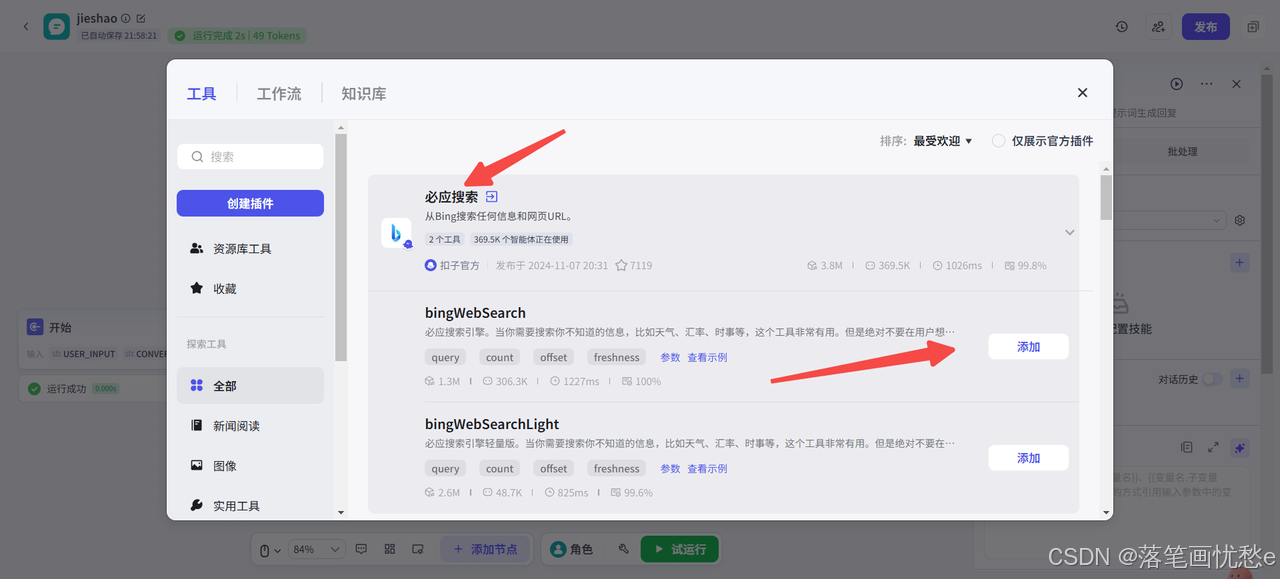
当你不想使用时,把鼠标悬浮在插件上面,接口浮现出删除按钮
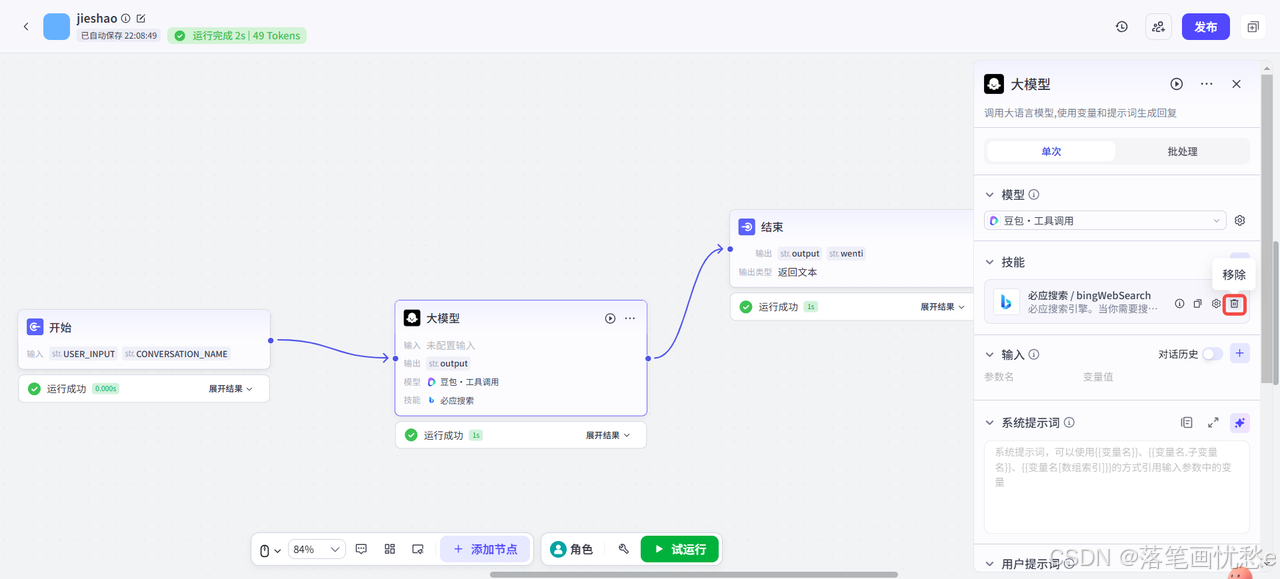
在一些第三方插件中,需要付费调用其他第三方服务,所以插件作者会在插件的输入参数中留下Token字段,用于鉴别该请求由谁发出,用于计费。
就像学校的小卖部:
-
假设你做了一个自动售货机小程序(第三方插件),但里面卖的可乐需要从隔壁超市进货(第三方服务)。每卖出一瓶可乐,你都要给超市付钱。
-
你在小程序里设置了一个 "学生证号码" 栏(Token 字段)。同学们使用时必须输入自己的学生证号,就像去图书馆借书要刷卡一样。
-
每次有人买可乐,系统就会记录:"学号 A123 买了 1 瓶"。月底时,超市根据这些记录找你收可乐钱,你根据记录找对应的同学收钱(或者从他们的预存款里扣)。
-
这样既能防止有人冒用别人的账号买可乐,又能准确统计每个人消费了多少次。就像食堂的饭卡,刷卡才能买饭,而且只能扣自己的钱。
简单说,Token 就像你的学生证,用来证明 "这个操作是我做的",方便系统统计谁用了多少次服务,该收多少钱。
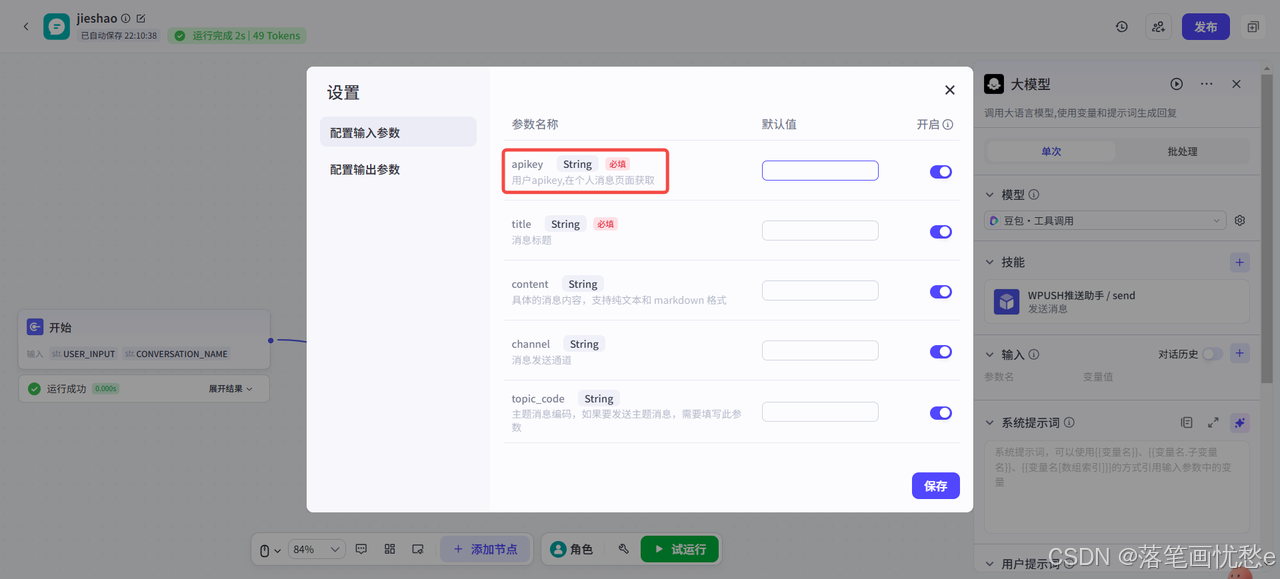
点击这个【设置】图标,即可设置Token参数和一些其他的默认参数
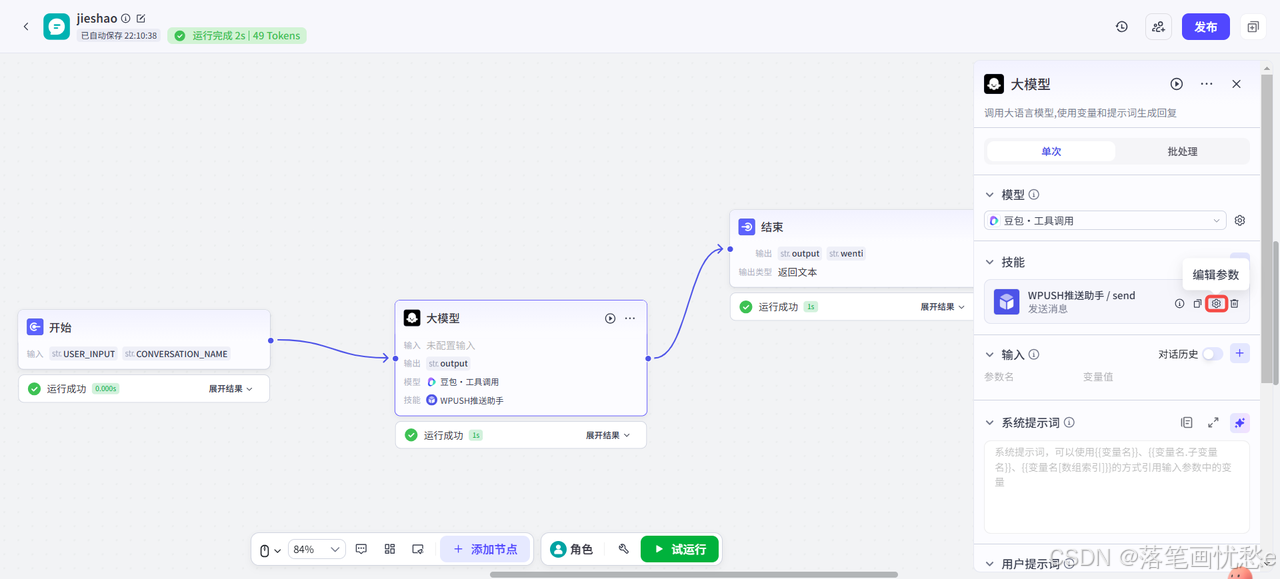
比如在这个插件中,Token的名字为apikey。
下面还有这个参数的介绍,比如从哪里获取这个值。
填写到后面的输入框中即可
大模型节点配置技能,和直接使用插件等技能节点有什么区别?
区别如下:
-
大模型节点配置技能时,模型会根据用户的 Query 自动判断调用技能的时机与方式、判断执行技能时传递给技能的输入,整体流程更加灵活,是模型 Function call 能力的直接体现。
-
直接使用插件等技能节点时,工作流是开发者人工设计并配置的执行流程,调用技能的时机和方式是固定的,技能的输入也是开发者的指定输入内容,如果编排合理,相对于模型配置技能的场景整体效果更加稳定。
简单来说:
1️⃣ 大模型配置技能 → 像有个聪明的助手,它会自己决定什么时候用工具、怎么用,比较灵活(但可能偶尔出错)。
2️⃣ 直接使用插件 → 像按照说明书操作,什么时候用哪个工具、输入什么内容都是提前固定好的,更稳定可靠(但不够灵活)。
举例:就像写作业时,前者是助手自己决定先算数学还是先查资料,后者是你提前规定好必须先用计算器再查词典。
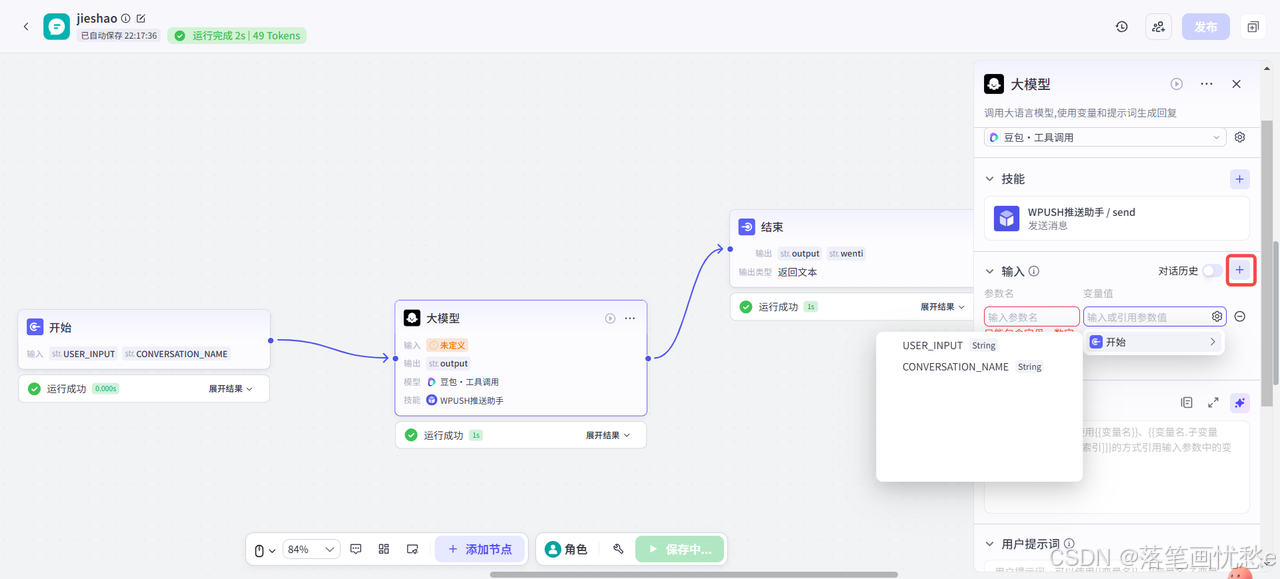
输入参数
需要添加到提示词中的动态内容。系统提示词和用户提示词中支持引用输入参数,实现动态调整的效果。添加输入参数时需要设置参数名和变量值,其中变量值支持设置为固定值或引用上游节点的输出参数。
你可以把提示词想象成数学考试中的填空题模板,比如:
题目:小明有____个苹果,小红给了他____个,现在一共有____个苹果。
这里的空格就是需要动态填写的内容。系统允许我们这样做:
-
参数名:给每个空格起名字,比如「小明原有」「小红给」「总数」
-
变量值:
-
固定值:直接写数字(比如小明原有 = 5)
-
引用上游:用公式计算(比如总数 = 小明原有 + 小红给)
-
举个实际例子:
当老师在出题时:
原始题目:"____同学在____比赛中获得了____名"
通过设置:
{姓名}= 张三(固定值)
{比赛}= 引用体育委员提供的 "最新赛事"
{名次}= 引用上次比赛结果
这样就能自动生成:"张三同学在篮球联赛中获得了第 3 名"
整个过程就像玩拼图:
-
你事先准备好带空格的模板
-
通过不同渠道获取拼图碎片(固定值或其他地方的数据)
-
最后自动拼成完整的句子
这样做的好处是可以重复使用模板,只需更换关键信息,不用每次都重新写整个句子。就像用 PPT 模板做演示文稿,每次只修改标题和图片一样。
点击【➕】号就会添加一个新的参数。
变量值可以写一个固定值或引用其他节点返回的值
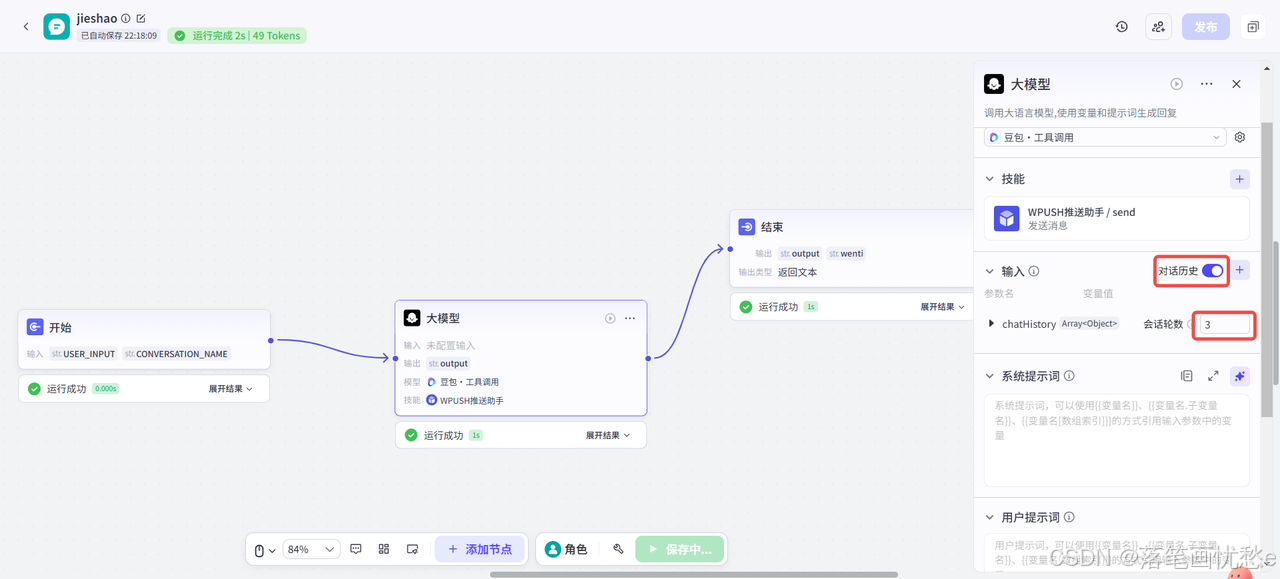
可能你已经注意到这个【对话历史】的开关了
在多轮对话场景中,你还可以开启智能体对话历史。执行此节点时,扣子会将智能体与当前用户的最近多条对话记录和提示词一起传递给大模型,以供大模型参考上下文语境,生成符合当前对话场景的回复。一问一答场景下通常无需开启此功能。
比如你和聊天机器人连续讨论一个故事续写,每次对话都像接力赛一样需要记住前面的内容。这时候 "对话历史" 功能就像给你的聊天机器人一个记忆本,让它记住你们最近聊过的 5-10 句话。这样它回答时会参考之前的对话内容,不会突然跳戏。
但如果是简单问答比如:
你问:"现在几点?"
它答:"下午 3 点。"
这种一问一答就不需要记忆功能,就像你问完就擦掉黑板,下次对话重新开始。
简单来说:需要连续聊天时开启 "记忆本",简单问答时不需要,这样既能保持对话连贯性,又不会浪费资源。
你还可以设置大模型能了解你们几轮对话(一问一答视为一轮)
提示词
模型的系统提示词,用于指定人设和回复风格。支持直接插入提示词库中的提示词模版、插入团队资源库下已创建的提示词,也可以自行编写提示词。
编写系统提示词时,可以引用输入参数中的变量。例如{{variable}}表示直接引用变量,{{变量名.子变量名}}表示引用 JSON 的子变量,{{变量名[数组索引]}}表示引用数组中的某个元素。
你可以把系统提示词想象成给 AI 机器人写一份 "使用说明书"。比如你希望这个 AI 扮演一个幽默的历史老师,或者用二次元风格聊天,就需要在说明书里写好这些要求。
具体来说:
-
制作说明书有 3 种方法:
-
直接套用现成的模板(像填空作文)
-
使用团队共享的模板(像班级共享的范文)
-
自己从头写新模板
-
有个超实用功能叫 "变量填空":
-
用双花括号 {{}} 就能插入动态内容
-
比如: {{姓名}} → 会自动替换成用户的名字 {{学生。数学成绩}} → 调取学生档案里的数学分数 {{好友列表 [0]}} → 显示好友名单里第一个人的名字
举个例子:如果你设置提示词为 "你好 {{姓名}},我是 {{老师}},今天要讲 {{科目}}...",当用户输入姓名 "小明",系统就会自动生成 "你好小明,我是王老师,今天要讲数学..."。
这样就能让 AI 的回复既保持固定风格,又能灵活变化内容啦!就像用乐高积木组合出不同的造型一样。
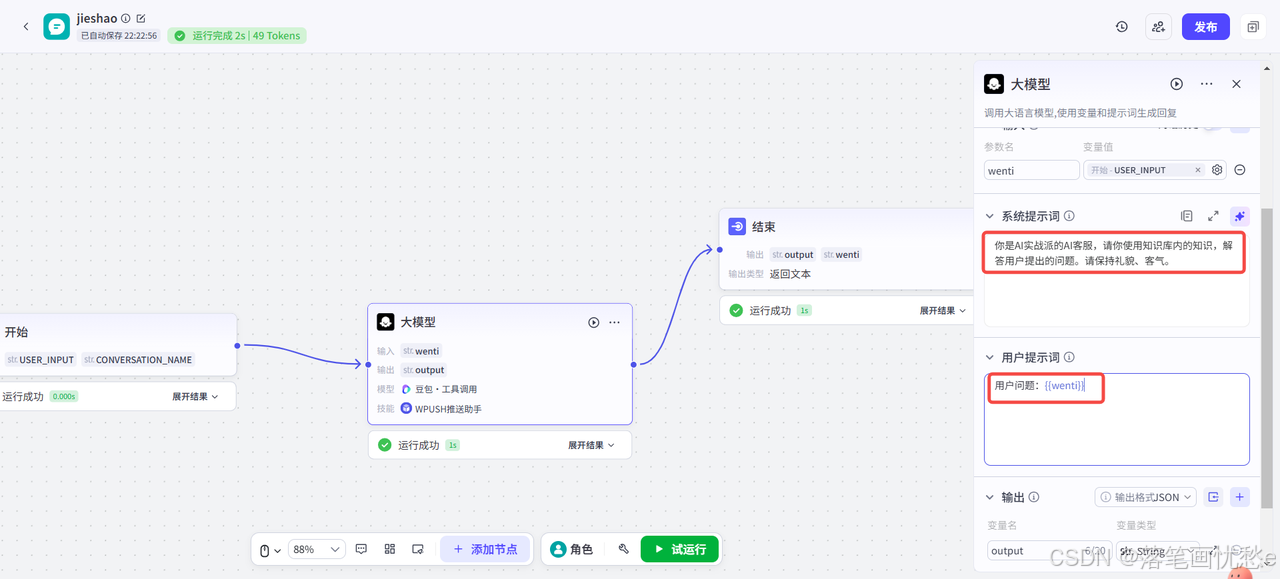
模型的用户提示词是用户在本轮对话中的输入,用于给模型下达最新的指令或问题。用户提示词同样可以引用输入参数中的变量。
输出
指定此节点输出的内容格式与输出的参数。
就像给手机设置不同的主题一样。目前有三种格式可选:
-
纯文本模式(就像记事本):
-
输出就是普通的文字,没有任何格式
-
比如直接回答:"今天的天气是晴天"
-
-
Markdown 模式(类似带格式的笔记):
-
可以用符号加粗、列表等简单排版
-
比如:"注意:今天最高温度 30°C\n1. 带伞 \n2. 涂防晒 "
-
-
JSON 模式(像编程用的数据表格):
-
输出会像表格一样有明确的结构,方便其他程序读取
-
比如: { "天气": "晴", "温度": 30, "建议": ["带伞", "涂防晒"] }
-
特别说明:如果选 JSON 格式,你可以直接粘贴一个例子(比如上面的天气例子),系统就会自动记住这个格式。也可以自己手动添加不同参数,就像给表格添加不同的列。
举个生活中的例子:就像你让同学帮忙记笔记,可以要求他直接手写(文本),用彩笔标重点(Markdown),或者用 Excel 表格整理(JSON)。不同格式适合不同的使用场景。
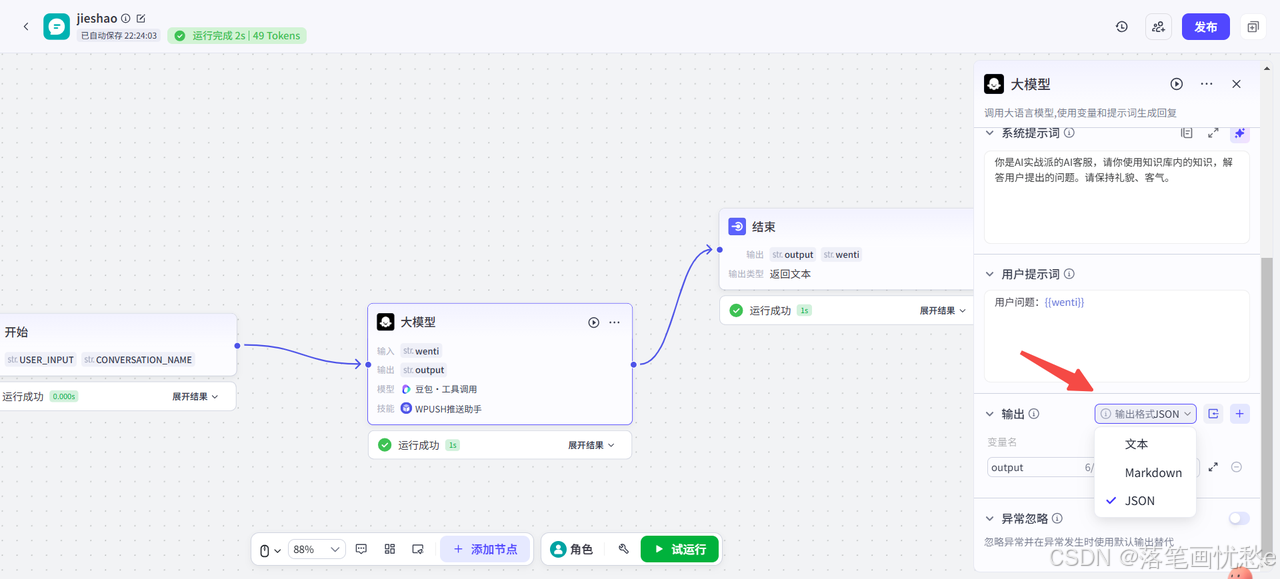
参数的名称和描述有助于模型在参数中正确返回匹配的内容。当存在多个输出参数时,建议为输出参数指定有意义的名称,并设置描述信息。例如用于改写 Query 的模型节点,可以设置输出参数为 new_query,描述是改写后的 Query,另一个参数为 reason,描述是改写原因。
文章转载自:https://gwl1554ppni.feishu.cn/wiki/G8YSwgk7MiW7rbkxCLcc35VjnPf
欢迎关注公众号【AI技术开发者】

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









