






目录
前言
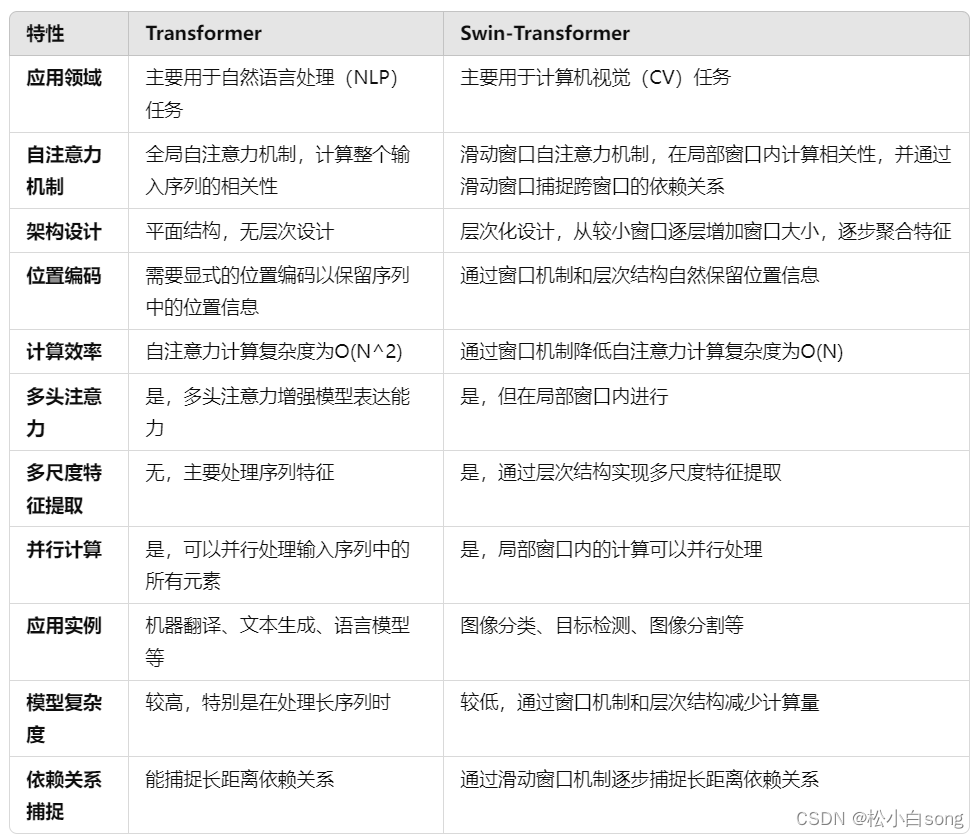
Transformer和Swin-Transformer是两种不同的神经网络架构,它们在结构、应用场景和性能等方面有许多差异。下面详细说明一下它们的区别
一、Transformer
Transformer架构最初由Vaswani等人在2017年提出,主要用于自然语言处理(NLP)任务,如机器翻译、文本生成和语言模型等。其核心思想是基于自注意力机制(Self-Attention Mechanism),可以捕捉输入序列中任意两个位置之间的依赖关系。
主要特点:
- 自注意力机制:Transformer通过自注意力机制计算输入序列中所有词之间的相关性,使得它能够很好地捕捉长距离的依赖关系。
- 多头注意力:通过多头注意力机制,Transformer可以在不同的子空间中进行注意力计算,增强模型的表达能力。
- 位置编码:由于自注意力机制对输入顺序不敏感,Transformer通过添加位置编码(Positional Encoding)来保留序列中词的位置信息。
- 并行计算:与RNN不同,Transformer可以并行处理输入序列中的所有元素,提高了计算效率。
二、Swin-Transformer
Swin-Transformer(Shifted Window Transformer)是微软亚洲研究院在2021年提出的一种新型视觉Transformer架构,主要用于计算机视觉任务,如图像分类、目标检测和图像分割等。Swin-Transformer通过引入窗口机制和层次结构改进了传统Transformer在视觉任务中的表现。
主要特点:
- 滑动窗口注意力(Shifted Window Attention):Swin-Transformer将输入图像划分为不重叠的窗口,并在每个窗口内计算自注意力。通过在不同层之间滑动窗口位置,模型可以捕捉跨窗口的依赖关系。
- 层次结构:Swin-Transformer采用了层次化设计,从较小的窗口开始逐层增加窗口的大小,逐步聚合特征,这种设计类似于传统卷积神经网络(CNN)的金字塔结构。
- 计算效率:由于窗口机制的引入,Swin-Transformer的自注意力计算复杂度从O(N^2)降至O(N),显著提高了计算效率,特别适用于高分辨率图像。
- 多尺度特征提取:Swin-Transformer能够在不同层次提取图像的多尺度特征,提高了模型在视觉任务中的表现。
三、主要区别总结
应用领域:
- Transformer:主要用于NLP任务。
- Swin-Transformer:主要用于计算机视觉任务。
自注意力机制:
- Transformer:全局自注意力机制,对整个输入序列计算相关性。
- Swin-Transformer:局部窗口内的自注意力机制,滑动窗口来捕捉跨窗口的相关性。
架构设计:
- Transformer:平面结构,没有层次设计。
- Swin-Transformer:层次化设计,类似于金字塔结构,从小窗口逐层扩大。
计算效率:
- Transformer:自注意力计算复杂度为O(N^2)。
- Swin-Transformer:通过窗口机制降低自注意力计算复杂度为O(N)。
特征提取:
- Transformer:适合处理序列数据,特征提取相对直接。
- Swin-Transformer:多尺度特征提取,适合处理视觉数据。
四、表格对比

















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









