






策略梯度法
- 策略近似及其优势
- 在之前的学习中,总是依赖于动作价值函数的学习,可以称为间接强化学习
- 在策略梯度方法中,通过直接对策略进行参数化,对策略参数进行学习,称为直接强化学习
- 使用这种方法的优势有:
- 动作选择更具有柔性,任何动作选择不是非1即0,而是对应一个概率
- 对于最优策略是一个随机策略的情景,策略近似相较于动作价值求解更具优势,可以以不同的概率选择随机策略
- 策略梯度定理
- 在分幕式问题中,性能指标可以用策略下初始状态的状态价值定义
- 其梯度的求解具有很好的理论基础,具体证明见P321
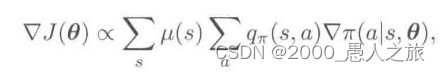
- REINFORCE:蒙特卡洛策略梯度
- 蒙特卡洛的精髓便是用均值代替期望
- 分别把真实状态、动作引入进来,把对随机变量所有可能取值的求和运算替换为求策略下的期望,再对期望进行采样
- 推到下得到随机梯度上升:
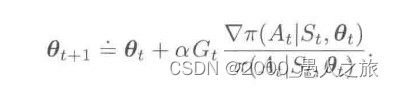
- 带有基线的REINFORCE
- 蒙特卡洛算法虽然有较好的收敛特性,但由于方差问题,其收敛速度较慢
- 出于此考虑,可以在价值估计时添加一基线来减小方差
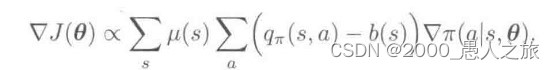
-
- 这里可以使用状态价值函数作为基线,也可以证明这种情况下方差的值最小
- “行动器-评判器”方法(Actor-Critic RL)
- 在上一步采用基线时,并没有用于自举操作(用后继各个状态的价值估计值来更新当前某个状态的价值估计值)
- 使用时序差分算法可以改善蒙特卡洛方法大方差的缺陷,提高收敛速度
- 这里便可以使用时序差分的单步、多步算法:
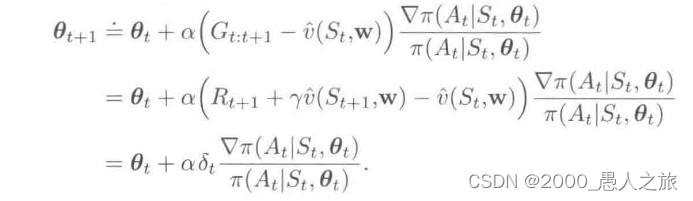
- 持续性问题的策略梯度
- 对于持续性问题,首先要重新定义性能
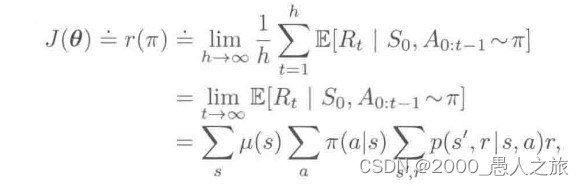
-
- 证明见P331















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









