







本文并非逐句翻译,添加个人理解与疑惑,如有需要,请自行阅读原文。

Missing Modality Imagination Network for Emotion Recognition with Uncertain Missing Modalities
具有不确定缺失模态的情绪识别的缺失模态想象网络
发表在 ACL-IJCNLP 2021
数据集:IEMOCAP and MSPIMPROV
实验环境:单个Nvidia GTX 1080Ti
在以往的研究中,多模态融合已被证明可以提高情绪识别的性能。然而,在实际应用中,我们经常会遇到模态丢失的问题,而哪些模态会丢失是不确定的。这使得fixed多模态融合在这种情况下失效。
在这项工作中,提出了一个统一的模型,缺失情态想象网络(MMIN),以处理不确定的缺失情态问题。MMIN学习鲁棒联合多模态表示,在给定可用模态的情况下,可以预测任意缺失模态在不同缺失模态条件下的表示。
在两个基准数据集上的综合实验表明,统一的MMIN模型在不确定缺失模态测试条件和全模态理想测试条件下都显著提高了情绪识别性能。
1 Introduction
情态缺失问题是近年来研究较多的问题,现有的解决方法主要是基于学习联合多模态表示,实现所有情态信息的编码。Han等人(Han et al., 2019)提出了一种联合训练方法,该方法隐式融合了来自辅助模态的多模态信息,从而提高了单模态情感识别性能。最近在(Pham et al., 2019;Wang et al., 2020)通过将源模态转换为多个目标模态来学习联合多模态表示,从而提高了性能作为输入的源模态的。(如果有音频(a)、视觉(v)和文本(t)三种模态,则系统需要在6个缺失模态条件下训练6个模型{a}、{v}、{t}、{a,v}、{a,t}和{v,t},再加上在全模态数据下训练1个模型。)
然而,这些方法只能处理源模态输入到训练模型的场景。需要为不同的缺失模态情况构建不同的模型。此外,基于顺序翻译的模型需要翻译和生成视频、音频和文本,这些内容很难训练,特别是在训练样本有限的情况下(Li et al., 2018;Pham et al., 2019)。
Contributions:
1)为了提高情感识别系统在不确定缺失模态测试条件下的鲁棒性,提出了一种统一的缺失模态想象网络(MMIN)模型
2)基于成对多模态数据,采用级联残差自编码器(CRA)和循环一致性学习设计了一个cross-modality imagination,学习鲁棒联合多模态表示。
2 Related Work
多模态情感识别
以前的许多工作都集中在融合多模态信息以提高情感识别性能上。提出了基于时间注意的方法,利用注意机制基于帧级或词级时间序列选择性地融合不同的模态,如门控多模态单元(GMU) (Aguilar等,2019)、多模态对齐模型(MMAN) (Xu等,2019)和多模态注意机制(cLSTM-MMA) (Pan等,2020)。这些方法使用不同的单模态子网络对每个模态的上下文表征建模,然后使用多模态注意机制有选择地融合不同模态的表征。Liang等人(Liang et al., 2020)提出了一种半监督多模态(SSMM)情绪识别模型,该模型使用跨模态情绪分布匹配来利用未标记数据来学习鲁棒表示并实现最先进的性能。
模态缺失问题
现有的模态缺失问题的方法主要分为三类。
第一组的特点是数据增强方法,该方法随机删除输入以模拟缺失模态情况(Parthasarathy和Sundaram, 2020)。
第二组基于生成方法,在给定可用模态的情况下直接预测缺失模态(Li et al., 2018;Cai et al., 2018;Suo et al., 2019;Du等人,2018)。
第三组旨在学习可以包含这些模态相关信息的联合多模态表示(Aguilar等人,2019;Pham等人,2019;Han等人,2019;Wang et al., 2020)。
数据增强方法
Parthasarathy等人(Parthasarathy和Sundaram, 2020)提出了一种策略,在活动期间随机删除视觉输入在片段或帧水平上模拟真实世界的缺失模态场景进行视听多模态情感识别,提高了缺失模态条件下的识别性能。
生成方法
Tran et al. (Tran et al., 2017)提出级联残差自编码器(CRA),利用自编码器结构上的残差机制,可以获取损坏的数据并估计一个函数来很好地恢复不完整的数据。Cai等人(Cai et al., 2018)提出了一种编码器-解码器深度神经网络,在给定可用模态(磁共振成像,MRI)的情况下生成缺失模态(正电子发射断层扫描,PET),生成的PET可以提供补充信息,以提高对阿尔茨海默病的检测和跟踪。
学习联合多模态表示
Han等人(Han et al., 2019)提出了一种由两个特定模态编码器和一个共享分类器组成的联合训练模型,该模型将音频和视觉信息隐式融合为联合表示,提高了单模态情感识别的性能。Pham等人(Pham et al., 2019)提出了一种基于顺序翻译的模型来学习源模态和多个目标模态之间的联合表示。源模态编码器的隐向量作为联合表示,提高了源模态的情感识别性能。Wang et al. (Wang et al., 2020)遵循这种基于翻译的方法,提出了一种更高效的基于转换器的翻译模型,将文本特征转换为声学特征,将文本特征转换为视觉特征。此外,上述两种基于翻译的模型采用了前向翻译和后向翻译的训练策略,以确保联合表示能最大限度地保留所有模态的信息。
3 Method
给定一组视频片段S,我们使用x = (xa, xv, xt)来表示视频片段S∈S的原始多模态特征,其中xa, xv和xt分别表示声学,视觉和文本模态的原始特征。|S|表示集S中视频片段的个数。我们表示目标集Y = {yi}|S| i=1, yi∈{0,1,…, C},其中yi为视频的目标段si的情感类别和|C|是情感类别的数量。
我们提出的方法旨在识别具有完整模态或仅具有部分模态的每个视频片段si的情感类别yi,例如图1所示的示例,当缺少视觉模态时,仅存在声学和文本模态。

3.1 Missing Modality Imagination Network
为了学习鲁棒联合多模态表示,本文提出了一个统一的模型——缺失模态想象网络(MMIN),该模型可以处理实际应用场景中不同的不确定缺失模态条件。
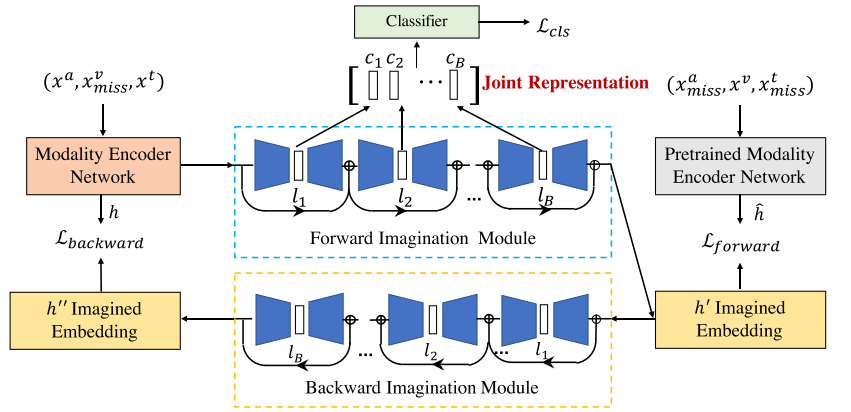
图2展示了提出的MMIN模型的框架,它包含三个主要模块:
- 1)用于提取模态特定嵌入的模态编码器网络;
- 2)基于级联残差自编码器(CRA)和循环一致性学习的想象模块,用于在给定相应可用模态表示的情况下想象缺失模态的表示。收集CRA中自编码器的潜在向量,形成联合多模态表示;
- 3)基于联合多模态表示的情感分类器预测情感类别。
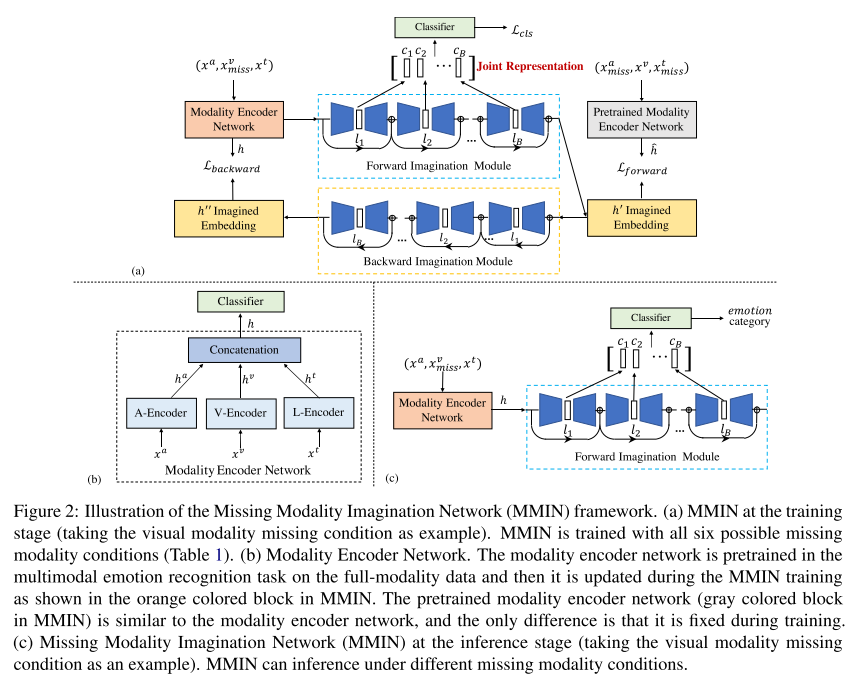
(a)训练阶段的MMIN(以视觉模态缺失情况为例)。MMIN用所有六种可能缺失的模态条件进行训练(表1)。
(b)模态编码器网络。模态编码器网络在多模态情绪识别任务中对全模态数据进行预训练,然后在MMIN训练过程中进行更新,如图MMIN中的橙色块所示。预训练的模态编码器网络(MMIN中的灰色块)与模态编码器网络相似,唯一不同的是它在训练时是固定的。
(c)推理阶段的缺失模态想象网络(MMIN)(以视觉模态缺失情况为例)。MMIN可以在不同的缺失模态条件下进行推理。
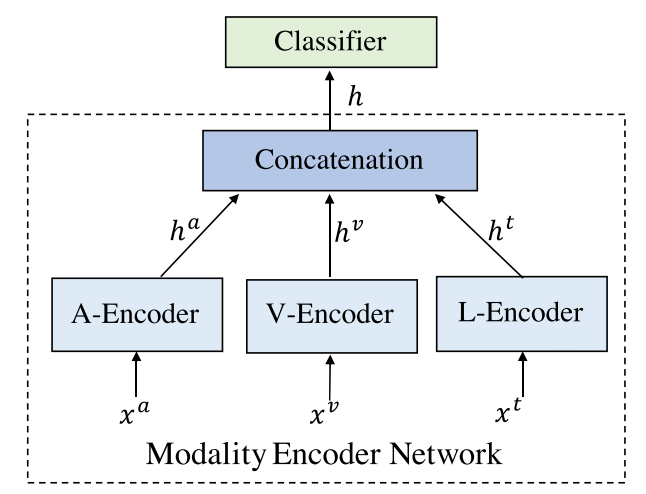
3.1.1 Modality Encoder Network
模态编码器网络用于基于原始模态特征 x 提取特定模态的话语级别嵌入。
如图 2(b) 所示,首先在多模态情感识别模型中预训练模态编码器网络,然后在 MMIN 模型内进一步训练。我们将每个模态的模态特定嵌入定义为 ha = EncA(xa),hv = EncV(xv),ht = EncT(xt),其中 EncA、EncV 和 EncT 分别代表声学、视觉和文本编码器,ha、hv 和 ht 分别代表相应编码器生成的特定模态嵌入。
个人理解:模态编码器实质上是由三个不同模态(声学、视觉和文本)的编码器组合而成的。
3.1.2 Missing Modality Condition Creation
给定具有所有三种模态(xa, xv, xt)的训练样本,有6种不同的可能缺失模态条件,如表1所示。

我们可以在每个缺失情态条件下建立一个跨情态对(可用、缺失),其中可用和缺失分别表示可用和相应的缺失情态。为了确保统一的模型能够处理各种缺少模态的情况,我们对模态编码器网络强制采用统一的三元输入格式(xa, xv, xt)。
在缺失模态条件下,相应缺失模态的原始特征被零向量代替。例如,在视觉模态缺失条件下,可用模态的统一格式输入格式为(xa, xv miss, xt),其中xv miss指零向量。在缺失模态训练条件下,输入包括统一三联体格式的可用模态和缺失模态的跨模态对(如表1所示)。这些跨模态对的多模态嵌入可以表示为(以视觉模态缺失条件为例)
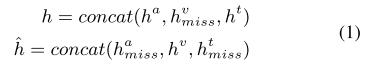
其中,ha miss, hv miss和ht miss表示相应模态缺失时的特定模态嵌入,由相应模态编码器以输入零向量产生。
3.1.3 Imagination Module
提出了基于自编码器的想象模块,用于根据可用模态的多模态嵌入来预测缺失模态的多模态嵌入。期望通过跨模态想象学习到稳健的联合多模态表示。
如图所示,采用了级联残差自编码器(CRA)结构,该结构具有足够的学习能力,比标准自编码器具有更稳定的收敛性。
CRA结构是通过连接一系列残差自编码器(RAs)构建的。进一步采用循环一致性学习和一个带有两个独立网络的耦合网络架构来执行两个方向的想象,包括向前(可用 → 缺失)和向后(缺失 → 可用)的想象方向。
具体来说,使用一个包含B个残差自编码器RA的CRA模型,每个RA用φk表示,每个RA的计算可定义为:
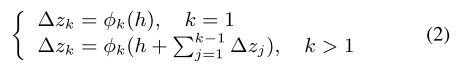
其中h是基于统一跨模态对的公式(Eq.(1))的可用模态提取的多模态嵌入,∆zk表示第k个RA的输出。
以视觉模态缺失情况为例(如上图所示),前向想象的目的是基于可用的声学模态和文本模态来预测缺失视觉模态的多模态嵌入。前向想象多模态嵌入表示为:
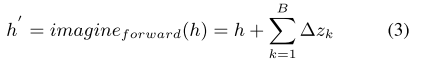
其中imagine(·)表示想象模块的功能。
后向想象的目的是在前向想象多模态嵌入的基础上预测可用模态的多模态嵌入。后向想象的多模态嵌入表示为:
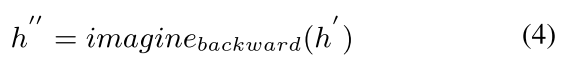
3.1.4 Classifier
我们收集前向想象模块中每个自编码器的潜在向量并将它们连接在一起形成联合多模态表示:![]() ,其中ck为自编码器在第k个RA中的潜在向量。
,其中ck为自编码器在第k个RA中的潜在向量。
基于联合多模态表示R,我们计算概率分布q为:
![]()
式中fcls(·)表示由多个全连接层组成的情感分类器。
Q:关于3.1.4节使用潜在向量而不使用生成的多模态嵌入的原因
在3.1.4节中,分类使用的是前向想象模块中每个自编码器的潜在向量连接在一起形成的联合多模态表示,而不是直接使用前向想象模块生成的多模态嵌入。
这样设计的主要理由是潜在向量提供了一个更抽象和压缩的信息表示,能够捕获跨模态之间更深层次的关联性。通过这种方式,每个自编码器不仅重建其输入数据,还通过学习在不同模态间的内在联系来优化联合表示。这样的联合表示有助于模型在处理不确定的缺失模态时,更好地进行情绪分类,因为它集成了所有可用模态的信息,增强了模型对缺失数据的适应性和鲁棒性。
3.2 Joint Optimization
MMIN训练的损失函数包括三部分:
情绪识别损失Lcls、前向想象损失Lforward、后向想象损失Lbackward:
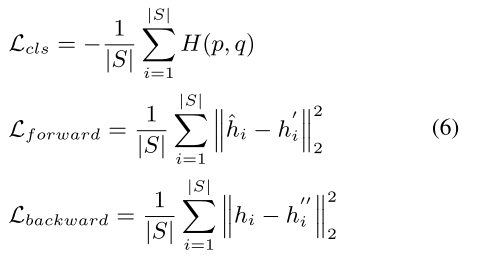
式中,p为独热标签的真实分布,q为式(5)中计算的预测分布。H(p, q)是分布p和q之间的交叉熵。hi^和hi'是模态编码器网络提取的真值表示,如Eq.(1)所示。
我们将这三种损失合并为如下的联合目标函数,共同优化模型参数:
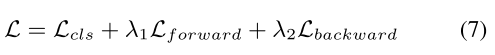
其中λ1和λ2分别为Lforward和Lbackward的加权超参数。
Q:以缺失视觉模态举例,MMIN的输入是将视觉模态变为零向量,然后预测缺失视觉模态的多模态嵌入,那为什么预训练网络和MMIN输入不同?不是要看预测的这个视觉模态的正确度吗,为什么用的是缺失音频和文本模态作为输入?
为了评估MMIN预测的准确性,我们需要一个基准或“真实”的情感状态表示,这通常来自一个已经在完整模态数据上训练好的网络。这个网络知道每个模态(包括视觉模态)应该如何贡献情感状态的表示。但我们不能直接用这个网络的输出作为MMIN的目标,因为这个输出是基于所有模态都可用的情况得出的,而MMIN面临的是某些模态缺失的情况。
因此,为了创建一个公平的比较,我们也会在预训练网络中故意丢失同样的模态数据。在这种情况下,我们丢弃的是音频和文本模态,只保留视觉模态。这样,预训练网络的输出代表了仅基于视觉模态时的“理想”情感状态表示。我们可以将MMIN预测的情感状态(在没有真实视觉数据的情况下预测得到的)和这个“理想”状态进行比较。这种比较使我们能够评估MMIN在只有视觉信息时预测情感状态的能力,并指导它学习在缺少其他模态信息时如何更好地进行预测。
总结来说,使用互补的输入(在预训练网络中保留视觉模态而丢弃其他模态)的目的是为MMIN提供一个可靠的目标,以便它能够学习在相反条件下(在预训练网络中保留其他模态而丢弃视觉模态)如何预测缺失的模态。这确保了MMIN学习到的是在特定模态缺失时如何补偿这一缺失,而不仅仅是在所有模态都可用时如何表现情感状态。
4 Experiments
4.1 Datasets
我们在两个基准多模态情绪识别数据集上评估了我们提出的模型,即交互式情绪二元动作捕捉(IEMOCAP) (Busso等人,2008)和MSP-IMPROV (Busso等人,2016)。两个数据集的统计结果如表2所示。
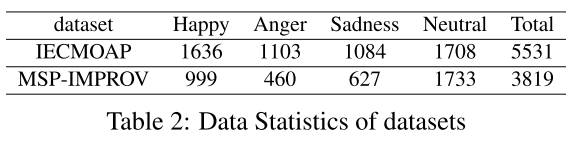
IEMOCAP 包含5个二元对话会话的录制视频。在每个会话中,有多个脚本剧本和一名男性和一名女性演讲者之间的自发对话,数据库中总共有10名演讲者。我们遵循(Xu et al., 2019;Liang et al., 2020),形成四类情绪识别设置。
MSP-IMPROV 包含记录片段视频在二元对话场景与12个演员。我们首先删除短于1秒的视频。然后在“其他即兴”组中选取在即兴场景中录制的带有快乐、愤怒、悲伤或中性标签的视频,形成四类情绪识别设置。
4.1.1 缺失模态训练集
我们首先将包含所有三种模态的原始训练集定义为全模态训练集。在全模态训练集的基础上,我们构造了另一个包含跨模态对的训练集来模拟可能的缺模态情况,并将其定义为缺模态训练集,用于训练所提出的MMIN。每个训练样本生成6个不同的跨模态对(表1)。因此,生成的跨模态对的数量是全模态训练样本数量的6倍。
4.1.2 缺失模态测试集
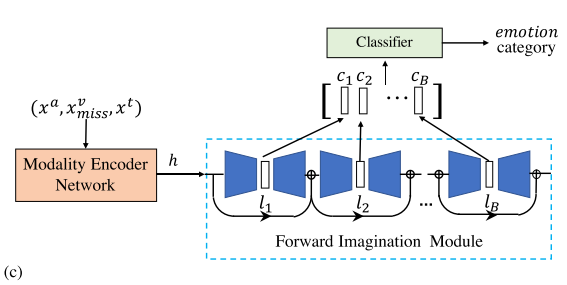
我们首先将包含所有三种模态的原始测试集定义为全模态测试集。为了评估该方法在不确定缺失模态条件下的性能,我们分别构建了6个不同的缺失模态测试子集,对应于6种可能的缺失模态条件。例如,在推理阶段,在图2(c)所示的视觉模态缺失条件下,一个模态缺失测试样本的统一格式的原始特征为(xa, xv miss, xt)。我们将所有六个缺失模态测试子集组合在一起,并将其表示为缺失模态测试集。
4.2 原始特征
提取我们遵循(Liang et al., 2020;Pan et al., 2020)并提取每个模态的帧级原始特征。
声学特征:使用OpenSMILE工具包(Eyben et al., 2010)配置“IS13 ComParE”提取帧级特征,其性能与(Liang et al., 2020)中使用的IS10话语级声学特征相似。我们将特征表示为“ComParE”,特征向量为130维。
视觉特征:我们使用预训练的DenseNet提取面部表情特征,它是基于面部表情识别加(FER)语料库(Barsoum et al., 2016)训练的。我们将面部表情特征表示为“Denseface”。“Denseface”是基于视频帧中检测到的人脸的帧级序列特征,其特征向量为342维。
文本特征:我们使用预训练的BERT-large模型(Devlin et al., 2019)提取上下文词嵌入,该模型是最先进的语言表示之一。我们将单词嵌入表示为“Bert”,特征是1024维的。
4.3 高级别特征编码器
为了为想象模块生成更高效的句子级特定于情态的表示,我们针对不同的情态设计了不同的情态编码器。
声学模态编码器(EncA):我们应用长短期记忆(LSTM)网络(Sak等人,2014)来捕获基于顺序帧级原始声学特征xa的时间信息。然后基于LSTM隐藏状态,利用最大池化方法得到话语级声学嵌入。
视觉模态编码器(Visual Modality Encoder, EncV):采用与EncA相似的方法对序列帧级面部表情特征xv进行编码,得到话语级视觉嵌入hv。
文本语态编码器(EncT):我们使用TextCNN (Kim, 2014)来获得基于顺序词级特征xt的话语级文本嵌入。
4.4 Recognition Baselines
我们的基线模型采用如上图所示的结构,该结构基于全模态训练集进行训练,我们将其作为我们的全模态基线。
为了提高系统对缺失模态问题的鲁棒性,一种直观的解决方案是将缺失模态条件下的样本添加到训练集中。因此,我们将缺失模态训练集和全模态训练集集合在一起训练基线模型,并将其用作我们的增强基线。
4.5 实现细节

表3给出了我们的实现细节。我们分别在IEMOCAP和MSP-IMPROV上使用10倍和12倍说话人独立交叉验证来评估模型。
对于IEMOCAP的实验,我们进行了四个会话训练,剩下的部分由演讲者分成验证集和测试集。
对于MSPIMPROV,我们取10个说话人的话语进行训练,剩下的2个说话人按说话人分为验证集和测试集。
每个实验我们用最多100个epoch来训练模型。我们在验证集上选择最佳模型,并在测试集上报告其性能。为了证明模型的稳健性,我们对每个模型运行三次,以减轻参数随机初始化的影响,并对模型比较进行显著性检验。所有模型都使用Pytorch深度学习工具包实现,并在单个Nvidia GTX 1080Ti显卡上运行。
对于IEMOCAP的实验,我们使用了两个评价指标:加权精度(WA)和非加权精度(UA)。由于MSP-IMPROV上情绪类别的不平衡,我们使用f-score作为评价指标。
说话人独立交叉验证是一种评估模型性能的方法,特别适用于语音相关的任务,如情感识别。在这种交叉验证方法中,数据集被分成多个折(fold),每个折中包含不同的说话人的数据。然后,模型在每个折上进行训练,并在其他折上进行测试,确保模型在未见过的说话人的数据上进行泛化。这样可以更准确地评估模型在真实场景中的性能表现,而不会受到特定说话人的影响。
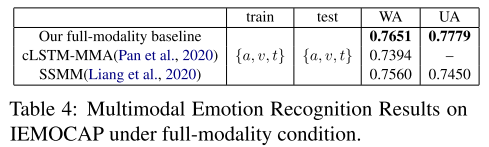
4.6 全模态基线结果
我们首先将我们的全模态基线与几种最先进的全模态条件下的多模态识别模型进行比较。表4的结果显示,我们的全模态基线优于其他最先进的模型,这证明我们的模态编码器网络可以为多模态情感识别提取有效的表示。
4.7不确定缺失模态结果
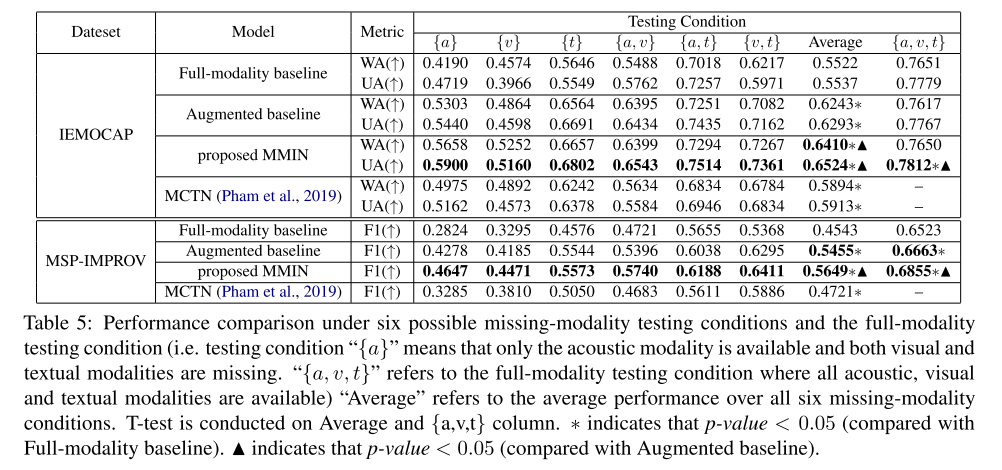
表5给出了我们提出的MMIN模型在不同缺失模态测试条件和全模态测试条件下的实验结果。
在IEMOCAP上,与表4中的“全模态基线”结果相比,我们看到在不确定的缺失模态测试条件下,性能显著下降,这表明在全模态条件下训练的模型对缺失模态问题非常敏感。
将缺失模态训练集和全模态训练集结合起来训练基线模型的直观解“增强基线”在缺失模态测试条件下比全模态基线有明显改善,说明数据增强有助于缓解训练和测试数据不匹配的问题。
更值得注意的是,在所有可能的缺失模态测试条件下,我们提出的MMIN显著优于全模态基线和增强基线。在全模态测试条件下,即使MMIN模型不使用全模态训练数据,它也优于这两个基线。
结果表明,所提出的MMIN模型能够学习到鲁棒联合多模态表示,从而在不同失模态和全模态测试条件下都能获得一致的较好的性能。这是因为我们提出的MMIN方法不仅具有数据增强能力,而且可以学习到更好的联合表示,从而可以保留其他模态的信息。
我们进一步分析了不同缺失模态条件下的性能。
与增强基线相比,我们的MMIN模型在一个模态可用条件下({a}, {v}或{t})取得了显著的改进,特别是对于弱模态{a}和{v}。即使对于强模态组合(如{a, t}),它也比增强基线带来了一些改进。
这些实验结果表明,通过MMIN学习的联合表示确实从其他模态中学习了互补信息,以补偿弱模态。表5中的底部块显示了MSP-IMPROV数据集上的性能比较。在不同的缺失模态和全模态测试条件下,我们提出的MMIN模型再次显著优于两个基线,这表明MMIN在不同数据集上具有良好的泛化能力。
我们还比较了MCTN (Pham等人,2019)模型,该模型是解决模态缺失问题的最先进模型。就像MCTN一样不能在一个统一的模型中处理不同的失态条件,所以我们必须在每个失态条件下训练一个特定的模型。
对比结果表明,我们提出的MMIN模型不仅可以用统一的模型处理不同的缺失模态和全模态测试条件,而且在所有缺失模态条件下都能始终优于MCTN模型。
4.8 消融研究
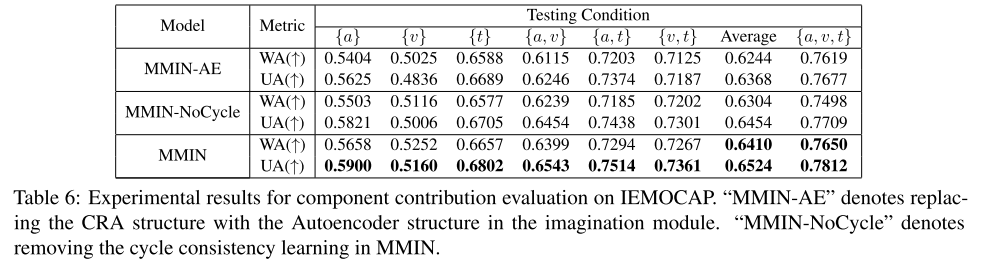
我们通过实验来消融不同成分在MMIN中的贡献,包括想象模块的结构和循环一致性学习。
想象模块的结构。我们首先研究了不同网络结构对想象模块性能的影响。具体来说,我们对MMIN中的自编码器和CRA结构进行了比较,我们采用相同的参数尺度来保证比较的公平性。如表6所示,在不同的缺模态和全模态测试条件下,采用自编码器结构“MMIN-AE”的想象模块的性能都比采用CRA结构的想象模块差。性能比较表明,CRA比Autoencoder模型具有更强的想象能力。
循环一致性学习。为了评估循环一致性学习在MMIN中的影响,我们使用第4.3节中描述的特征,并遵循(Pham et al., 2019)中的训练设置进行MCTN实验。MCTN模型不能在全模态测试条件下进行评估,因为目标模态不能为None。我们使用有或没有循环一致性学习的MMIN进行了实验。如表6所示,未经循环一致性学习训练的模型在所有条件下的性能都有所下降,这表明循环一致性学习可以增强想象能力,学习到更鲁棒的联合多模态表示。
4.9 MMIN核心能力分析
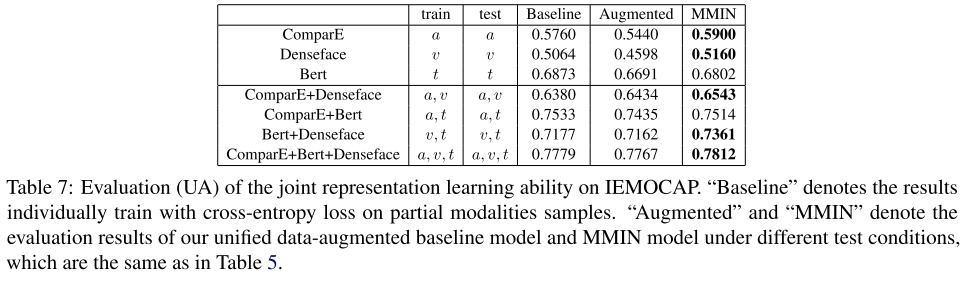
我们在IEMOCAP上进行了详细的实验,以证明我们的MMIN模型的联合表征学习能力和想象能力。
联合表示学习能力:
由于联合表示希望保留多个模态的信息,我们通过实验来评估MMIN的联合表示学习能力。我们将MMIN与基线模型在模态匹配条件下进行比较,其中训练数据和测试数据包含相同的模态。
如表7所示,与基线模型相比,MMIN达到了相当甚至更好的性能,这说明MMIN具有学习有效联合多模态表示的能力。我们还注意到数据增强模型不能打败相应匹配的部分模态基线模型,这表明数据增强模型不能学习联合表示。
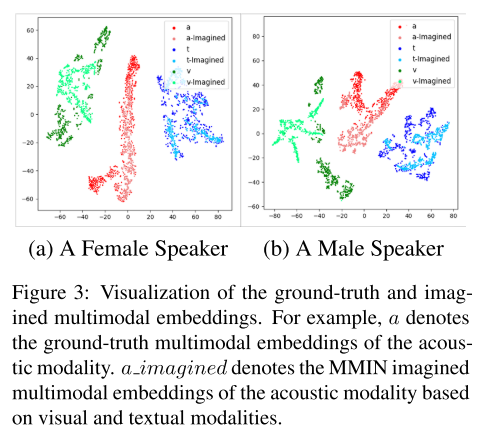
想象能力:
图3可视化了使用t-SNE的男说话者和女说话者的真多模态嵌入(图2中的h)和MMIN想象的多模态嵌入(图2中的h)的分布(Maaten和Hinton, 2008)。我们观察到的分布地面真值嵌入和想象嵌入非常相似,尽管视觉模态嵌入的分布略有偏差,但这主要是因为该数据集的视觉模态质量较差。这表明MMIN可以基于可用模态来想象缺失模态的表示。
结论
本文提出了一种新的统一的多模态情感识别模型——缺失模态想象网络(MMIN),以提高真实应用场景中不确定缺失模态条件下的情感识别性能。该算法通过级联残差自编码器和循环一致性学习,通过跨模态想象学习鲁棒联合多模态表示。在两个公共基准数据集上的大量实验证明了我们提出的模型的有效性和鲁棒性,在不确定的缺失模态和全模态条件下,该模型都明显优于其他基线。在未来的工作中,我们将探索进一步改进鲁棒联合多模态表示的方法。
Some Q/A
其训练过程包括以下几个步骤:
- 模态编码器训练:首先,独立训练每种模态的编码器,将原始数据(如语音、图像、文本)转换成模态特定的嵌入(向量表示)。
- 构造缺失模态数据集:按照文章中提到的六种可能的模态缺失情况,构造包含缺失模态的训练数据。例如,如果缺失视觉数据,那么就将视觉模态的数据部分替换为零向量,同时保留其他模态的数据。
- 统一模型训练:使用上述的所有训练数据(完整的和缺失模态的)来训练MMIN模型,让模型学会如何预测缺失的模态数据,并且在有缺失模态的情况下依旧能够准确识别情感。
- 验证:通过在验证数据集上评估模型的性能来调整模型参数。验证数据集也包括完整的和缺失模态的情况。
这个训练过程的结果是一个统一的模型,它不仅能处理完整模态的数据,也能应对任何一种模态缺失的情况,而不需要为每种缺失情况训练独立的模型。这增强了模型的泛化能力,使其能在实际应用中更加鲁棒和可靠。
Q:这个模型是怎么得到预测结果的?通常来说不是都得使用多模态融合之后得到预测结果吗?
A:
这个模型得到预测结果的过程比较特别,它涉及了对缺失模态的“想象”或预测。在通常的多模态融合中,确实是需要将所有模态的数据结合起来进行情感识别。但在MMIN模型中,由于某些模态可能缺失,模型就需要学会如何在没有全部信息的情况下进行有效的预测。以下是其预测结果的获得过程:
-
提取特征: 首先,对于每种模态的输入数据(如音频、视觉和文本),通过模态编码器提取特征,获得每种模态的嵌入(即向量表示)。
-
模态缺失处理: 如果某个模态的数据缺失,MMIN会用零向量替换该模态的嵌入,并利用其他模态的嵌入来“想象”或预测缺失模态的嵌入。
-
联合多模态表示: 接着,将所有模态的嵌入(无论是实际的还是想象的)结合起来形成一个联合的多模态表示。在这个过程中,来自自编码器的潜在向量也会被包括进来。
-
情感分类: 最后,这个联合多模态表示被送入一个情感分类器中,以预测当前输入数据的情感类别。
所以,尽管模型的一部分工作流程和传统的多模态融合类似,MMIN的独特之处在于它能够在模态数据不完整的情况下,通过学习和预测来弥补缺失的信息,从而保持情感识别的准确性。这种方法为处理现实世界中常见的模态缺失问题提供了一种有效的策略。
Q:为什么不用考虑数据的对齐?
A:
在多模态学习中,数据对齐通常是一个关键问题,因为它确保不同模态的数据可以准确地关联到相应的时间点或上下文。然而,在这篇文章提出的MMIN模型中,主要关注的是情感识别任务,而且使用的是句子级别的表示,这可能是以下几个原因使得数据对齐不是主要关注点:
-
句子级别表示: 在句子级别,所有的模态数据通常被假设为在时间上已经对齐。例如,一段话的音频,它的文本转录,以及说话时的面部表情被认为是同步的,因为它们都描述了同一个句子或语句。
-
抽象级别: MMIN处理的是相对高级的特征表示,而不是原始的、未处理的模态数据。在这个层次上,不同模态的特征已经被编码成向量形式,具有内在的对齐性。
-
想象模块: MMIN的核心是一个想象模块,它通过已有模态来预测缺失模态的嵌入。这个过程关注的是从可用模态学习缺失模态特征的表示,而不是不同模态之间的时序对齐。
-
自编码器的使用: 自编码器在设计上能够处理非对齐的数据,它们能从输入数据中学习到一个压缩的、稳健的特征表示,这减少了对精确对齐的依赖。
-
数据集特性: 使用的数据集可能已经在某种程度上处理了对齐问题,或者数据集的特性使得对齐不是一个关键问题。
-
模型的健壮性: MMIN模型的设计目的是为了能够在模态数据不完整时仍然表现良好,这需要模型具有一定程度的容错能力,即使在一定程度上的非对齐情况下也能工作。
综上所述,虽然数据对齐在多模态学习中通常很重要,但MMIN模型特有的结构和目标使得它在处理情感识别任务时可以不将数据对齐作为主要焦点。在更复杂的多模态任务中,对数据的精确对齐可能会更加重要。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











