







目录
RepVGG: Making VGG-style ConvNets Great Again
论文链接:RepVGG: Making VGG-style ConvNets Great Again(CVPR2021)
摘要
(1)提出了一种简单但功能强大的卷积神经网络架构,它具有类似 VGG 的推理时间主体,仅由 3x3 卷积和 ReLU 的堆栈组成,而训练时间模型具有多分支拓扑。
(2)这种训练时间和推理时间架构的解耦是通过结构重新参数化技术实现的,因此该模型被命名为 RepVGG。
INTRODUCTION—简介
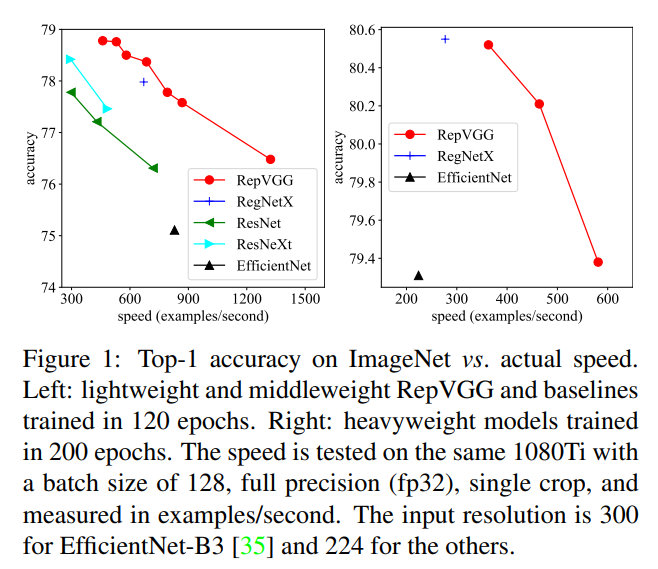
上图横坐标是推理速度,也可以简单地理解为FPS,越大越好。左侧是训练了120epochs的,右边是训练了200个epochs的。
下图中,图(B)是训练时的结构,采用的网络是多分支的,而在推理图©所示的单路的网络结构,而从图(B)转换到图©就是结构重参数化的过程。
结构重参数化:分支的参数进行重参数化,合为一个分支来进行的。
效果:推理的速度要比多分支网络快很多,并且精度也比单分支的网络更高。
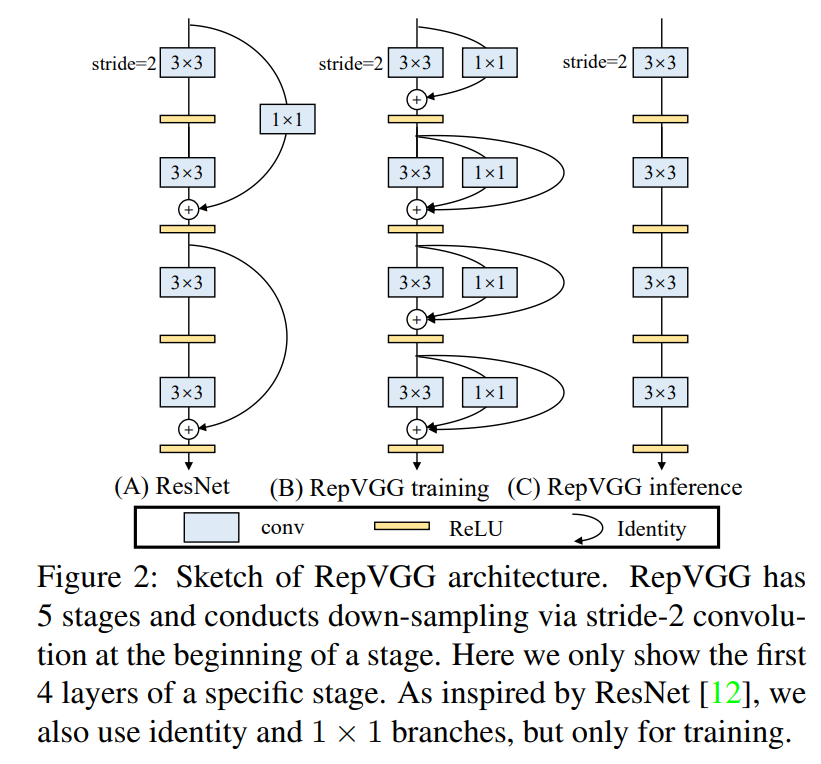
RepVGG Block
整个RepVGG网络结构很简单,就是不断地堆叠RepVGG Block。
下图中,左图为stride=2进行下采样时的RepVGG Block结构,右图为stride=1时的RepVGG Block结构(和上图(B)中结构一致)。
在不进行下采样时,RepVGG Block有三个分支,分别是卷积核为3 x 3的主分支、卷积核为1x1的shortcut分支和只含BN层的shortcut分支,然后将它们的输出进行Add操作。
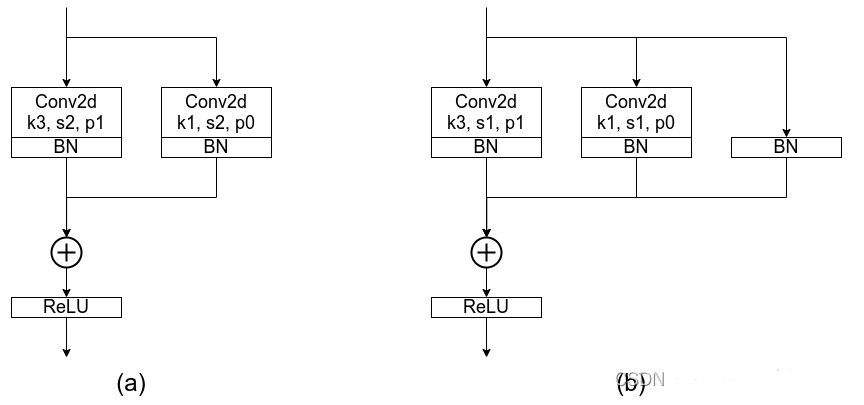
为什么训练时要设置多分支的网络结构?
像GoogleNet、ResNet、DenseNet都采用了多分支结构,并且对应的结果也表明采用多分支结构可以增强模型的表征能力。
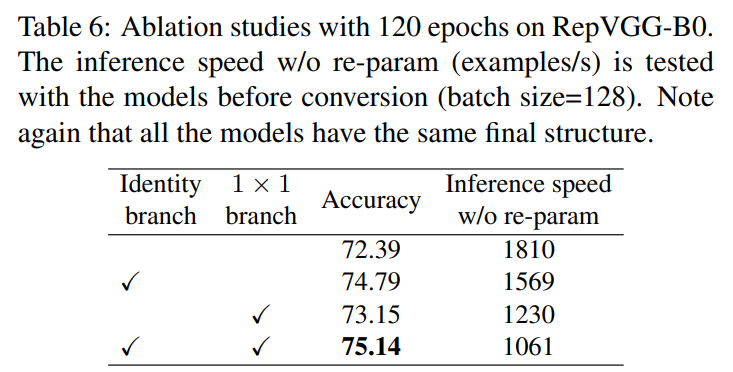
下表的原作者做的一个消融实验表示出不管加入哪个分支都能提点,同时添加提点效果最好。
为什么在推理时要把多分支模型转换成单路模型?且为什么单分支结构会比多分支结构速度快了将近一倍?
更快:主要是考虑到模型在推理时硬件计算的并行程度以及MAC(memory access cost)。
- 并行度(主要指的是计算设备的利用率):对于多分支模型,硬件需要分别计算每个分支的结果,有的分支计算的快,有的分支计算的慢,而计算快的分支计算完后只能干等着,等其他分支都计算完后才能做进一步融合,这样会导致硬件算力不能充分利用,或者说并行度不够高。
- MAC:每个分支都需要去访问一次内存(获取特征图),计算完后还需要将计算结果存入内存(不断地访问和写入内存会在IO上浪费很多时间)。
- 从算子的角度理解:在进行3 x 3卷积,1 x 1卷积、恒等映射和Add操作的时候都需要启动kernel,在GPU运算中每次启动kernel都需要时间,在模型中启动kernel的次数越多,消耗的时间也就越多。
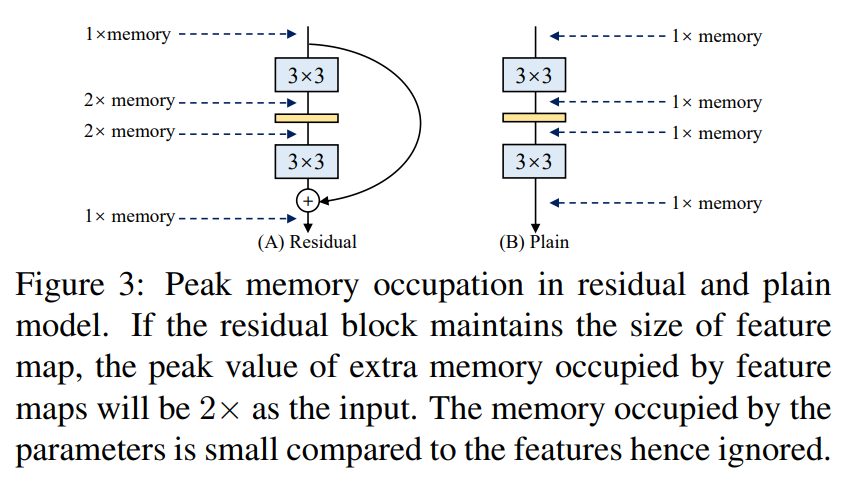
更省内存:在图3当中,作者举了个例子,如图(A)所示的Residual模块,假设卷积层不改变channel的数量,那么在主分支和shortcut分支上都要保存各自的特征图或者称Activation,那么在add操作前占用的内存大概是输入Activation的两倍,而图(B)的Plain结构占用内存始终不变。
更灵活:对于多分支的模型,由于结构复杂,剪枝很麻烦,非常受限,而对于Plain结构的模型就相对灵活很多,剪枝也更加方便。
除此之外,在多分支转化成单路模型后很多算子进行了融合(比如Conv2d和BN融合),使得计算量变小了,而且算子减少后启动kernel的次数也减少了(比如在GPU中,每次执行一个算子就要启动一次kernel,启动kernel也需要消耗时间)。而且现在的硬件一般对3x3的卷积操作做了大量的优化,转成单路模型后采用的都是3x3卷积,这样也能进一步加速推理。
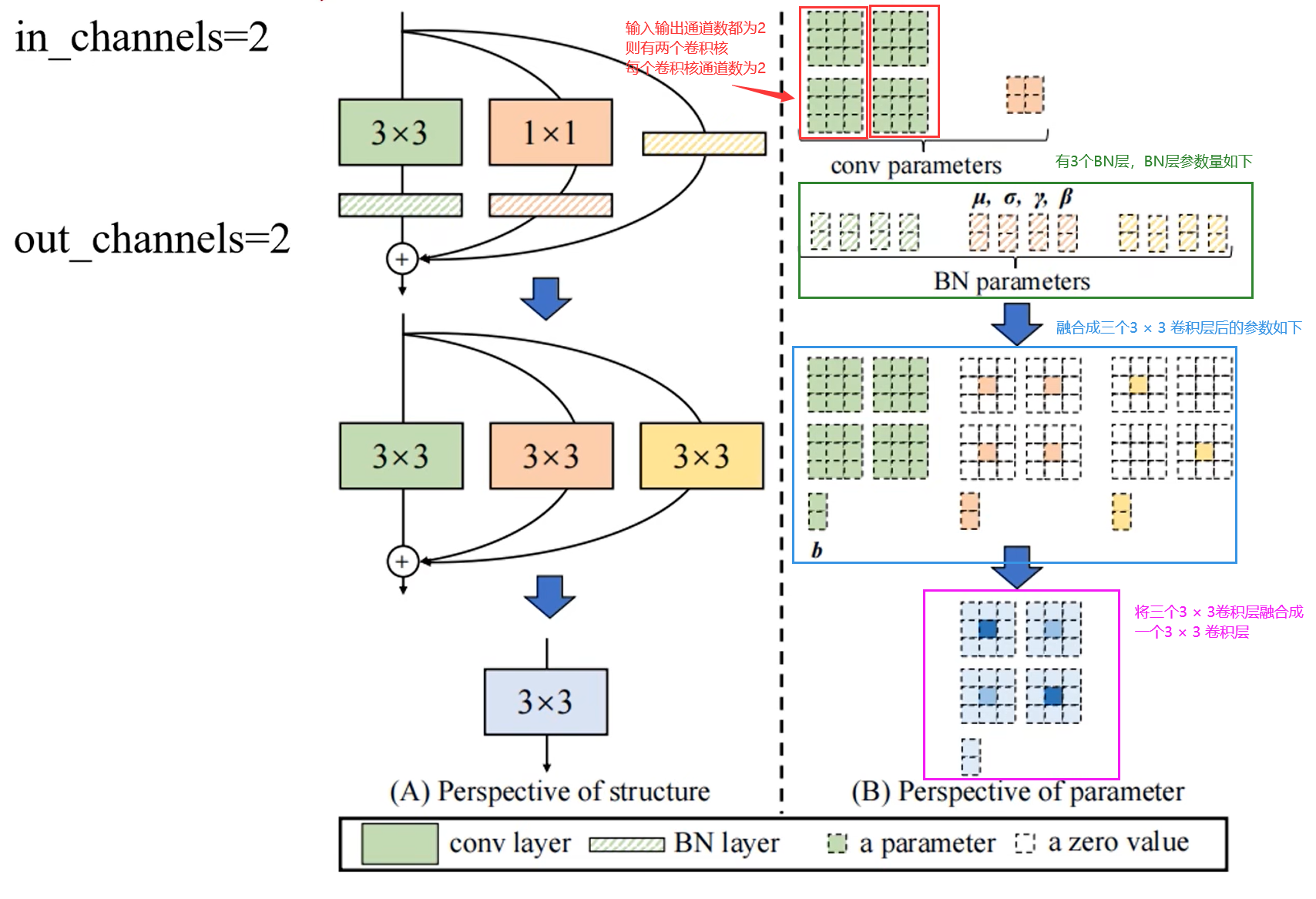
Model Re-parameterization – 模型重参数化
流程:
- 将三个分支中的卷积算子和BN算子都融合为卷积算子(一个卷积核加一个偏置的形式);
- 将三个分支上的卷积算子都化为3 x 3卷积核和偏置的形式,相加得到最终的主分支上的结果。

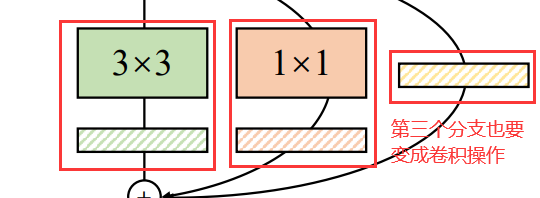
融合Conv2d和BN,将三个分支上的卷积算子和BN算子都转化为卷积算子(包括卷积核和偏置)
首先是BN层的计算公式:主要包含4个参数:μ(均值)、σ2(方差)、γ和β,其中μ和σ2是训练过程中统计得到的,γ和β是训练学习得到的,ϵ是一个非常小的常量,防止分母为零。
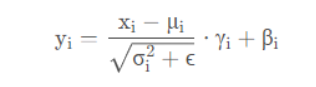
下面这条是BN的等价转换公式,左项表示通过BN层之后,第i个通道的数据;**右项括号内的被减数M表示输入到BN层的特征图中,对应第i个通道的值。**这里忽略了ϵ。
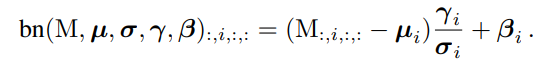
而输入BN层的特征图是由卷积层得到的,卷积层本质上其实就是一个加权求和的过程,所以把BN层中的权重与卷积层的权重相乘(两个层的权重融合就相当于卷积层和BN层进行了融合),表示如下:(其中W′ 和b ′ 是新的权重和偏置,也就是卷积层和BN层融合后的新参数)
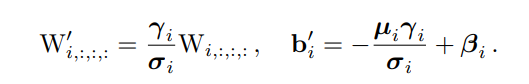
当 1≤𝑖≤𝐶2 ,都满足下面公式,该公式同样适用于identity 分支,因为 identity 可以视作 1×1 卷积。
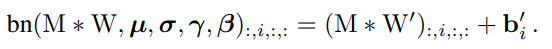
了解了上述原理之后,针对三个分支的具体融合如下:
1.第一个分支直接按上述步骤融合即可;
2.第二个分支先对1 × 1 的卷积核padding一圈0变成3 × 3的卷积核,也能通过上述流程融合。(注意:由于输入输出通道不变,在卷积过程中还要在设置padding =1,也就是卷积过程中外面有两圈0)
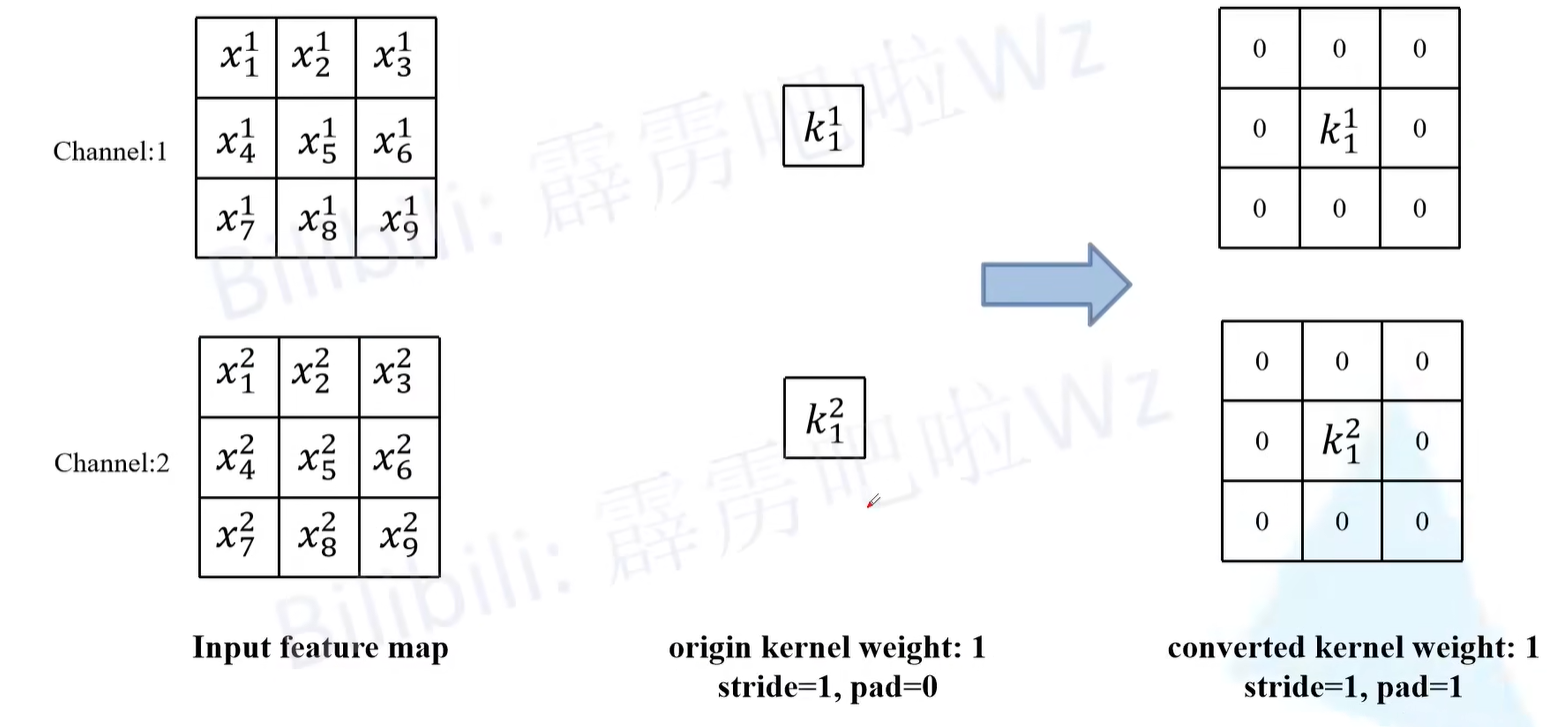
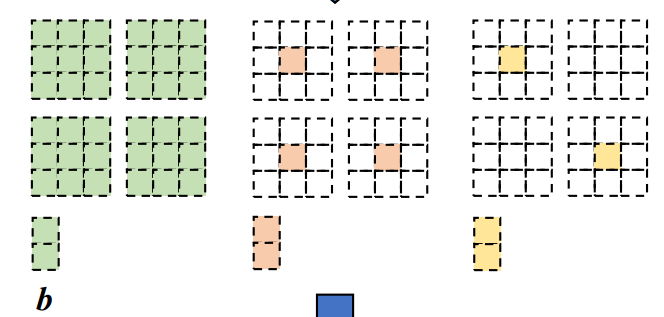
3.对于BN层来说本身是没有卷积核的,可以通过添加一个只进行恒等映射的3 x 3卷积核,使输入输出特征图不变。卷积核如下图虚线框内所示,框内左侧为第一个卷积核、右侧为第二个卷积核。第一个卷积核的结果和输入特征图的channel1一样,第二个卷积核的结果和输入特征图的channel2一样,然后通过concat就得到输出结果,输入输出就保持一致了。
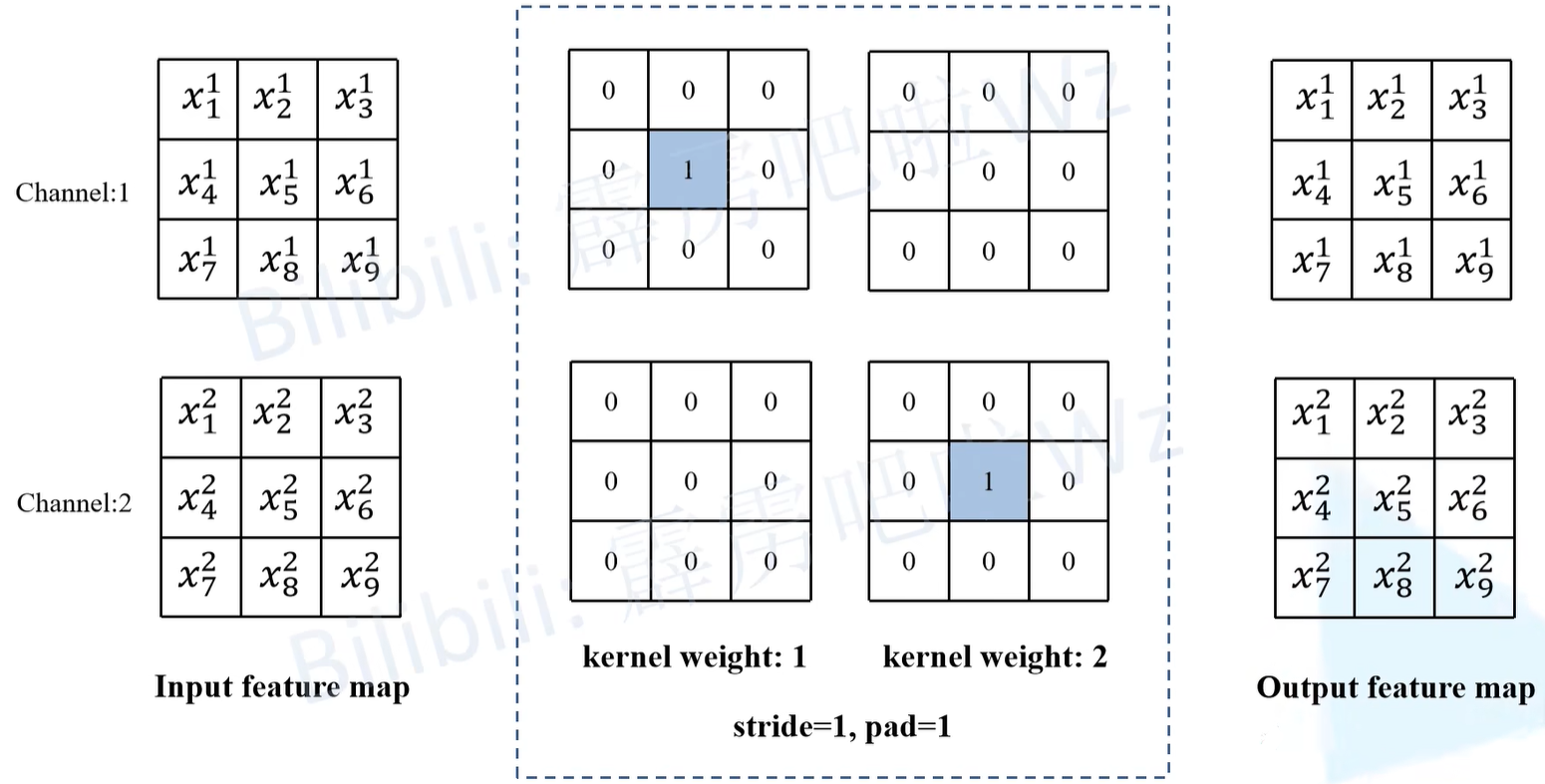
此时再会看原论文中这张参数图就很好理解了。
多分支融合(将三个stride、padding都一致的3 × 3 卷积层融合成一个3 × 3 卷积层)
将这三个分支的 3×3 卷积核(参数和偏置)相加(elemen twise-add),得到融合后卷积层的 3×3 卷积核,结构重参数化就完成了。
如下图,I表示输入特征图,K和B分别代表各个卷积层的权重参数和偏置。

此时的参数表示如下图。
Architectural Specification – 结构配置
深度控制:从下表2可以看出-A版本的模型Stage重复次数较少,也就是-A版本的模型网络较浅,-B结构网络较深。
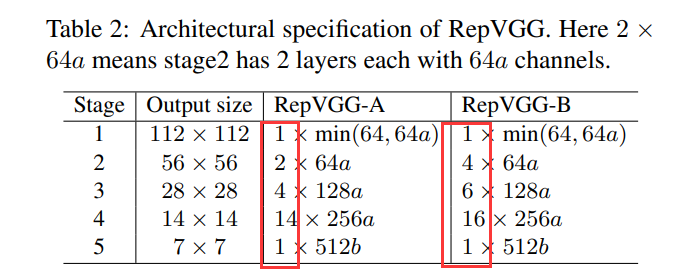
宽度控制:下表3中表示相同Stage但是a和b不同对应的版本也不同,a和b具体控制了哪个stage的宽度可以从上表2中看出(b只控制stage5的宽度)。
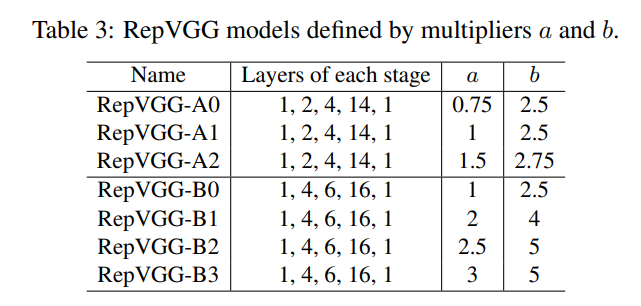
其中RepVGG-Bxgy配置是在RepVGG-B的基础上加入了组卷积(Group Convolution),其中gy表示组卷积采用的groups参数为y,注意并不是所有卷积层都采用组卷积,根据源码可以看到,是从Stage2开始(索引从1开始)的第2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26的卷积层采用组卷积。
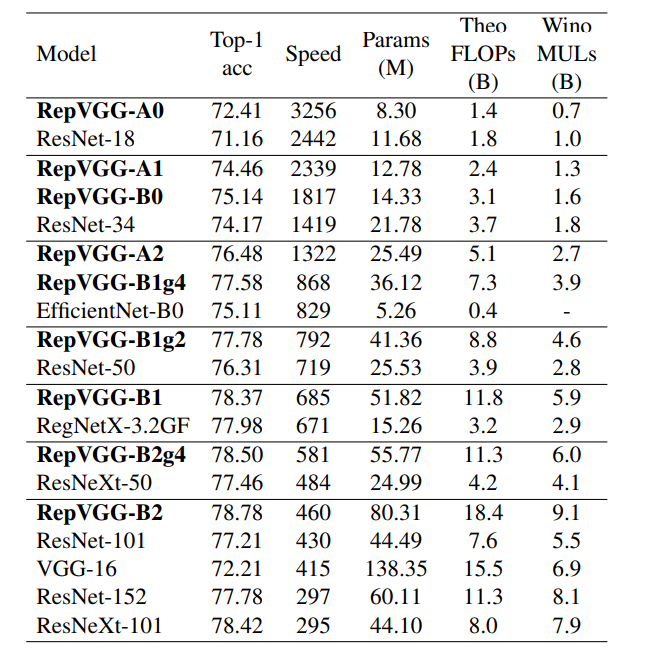
下表是一些其他的对比。
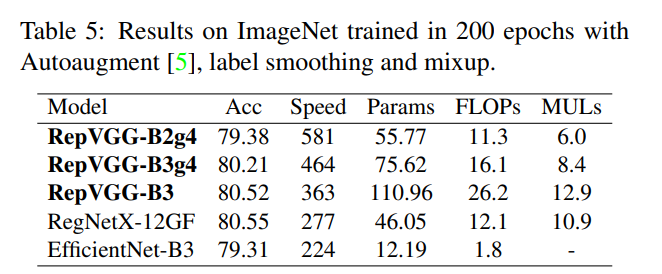
总结
优点:
本文的核心技术其实就一个 – 结构重参数化,通过这项技术实现了更快、更省内存、更灵活的网络架构RepVGG,这是一个由3 × 3 conv 和 ReLU 简单堆叠的架构,特别适合适用于 GPU 和专用推理芯片。通过结构重新参数化方法,它达到了 80% 以上的 top-1ImageNet 上的准确率,并显示出良好的速度准确度与最先进的模型相比的权衡。
不足:
- 最后需要注明的是,
RepVGG是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。在低算力设备上,可能不如 MobileNet 和 ShuffleNet 系列适用。 - 并且
RepVGG的推理模型很难使用后量化方法 (Post-Training Quantization,PTQ),比如,使用简单的INT8 PTQ,ImageNet 上的RepVGG模型的准确性会降低到54.55%。
原因:RepOpt 对重参数化结构量化困难的问题进行了研究,发现重参数结构的分支融合和吸 BN 操作,显著放大了权重参数分布的标准差。而异常的权重分布又会产生了过大的网络激活层数值分布,从而进一步导致该层量化损失过大,因此模型精度损失严重。















 6081
6081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









