







Unity开发性能优化关键点总结及复习【草稿2024补】
第一部分 批处理相关知识
一、动态批处理、
要求及相关学习
1、PlayeSeting动态批处理Dynamic Batching开关设置勾上;
2、【不超过900个属性进行动态批处理】【如果你的着色器使用顶点位置,法线和UV值三种属性,模型300顶点以内可以参与动态批处理】(已验证);如果Shader使用了顶点位置、法线、UV0、UV1 和切向量,那么只能动态批处理180个顶点以下的物体【未验证】?
3、面板TotalBatches数据可以作为DrawCall观察的参考;
4、不要随意缩放;未缩放的和缩放的无法动态批处理【未验证】;Y轴方向缩放的和X轴方向缩放的无法动态批处理【未验证】;但是同样都是Y周缩放不同比例的可以动态批处理【未验证】;
5、材质不同不会参与动态批处理;但是多个子模型分别各个子材质案例是不能参与动态批处理,但是如果材质打包在一起,只用1个材质贴图会如何【未试验】
6、拥又LightMap的物体不会进行批处理,触发他们只想LightMap的同一部分。
2024补充:
①不论是表面着色器还是顶点片元着色器,相同shader只有1pass了,但是设置了不同偏移缩放的材质无法合批一起;
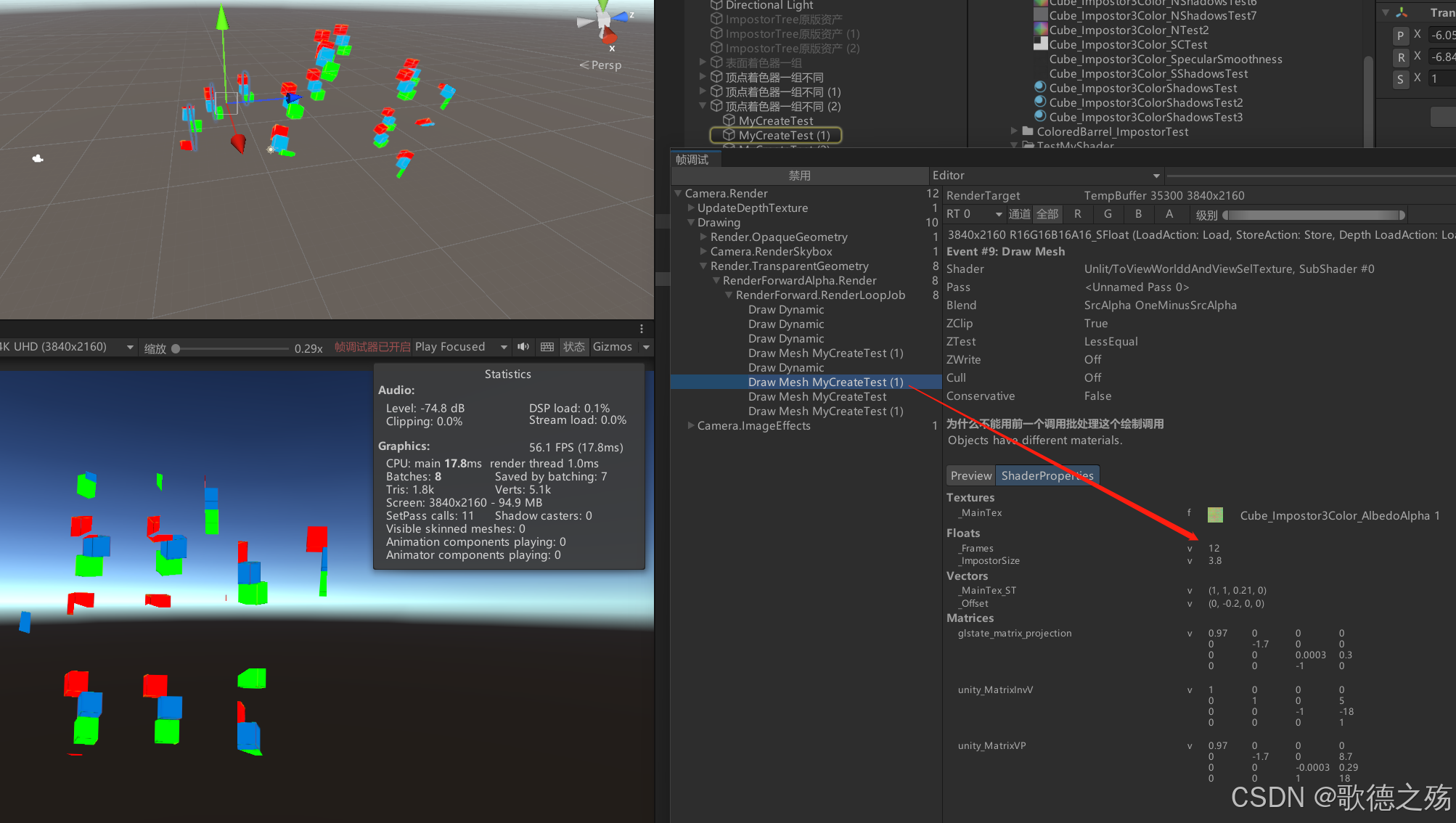
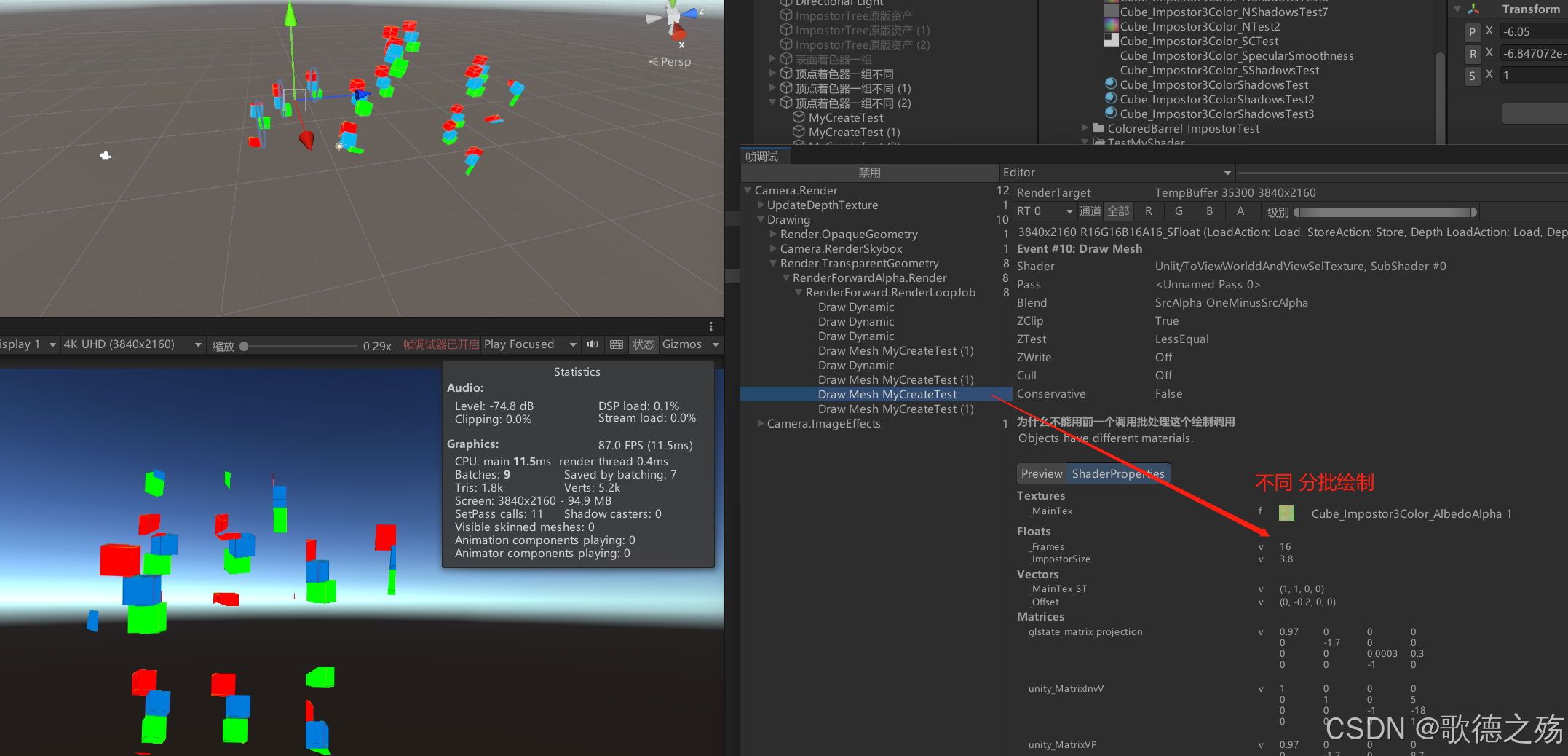
中断情况
GameObject之间如果有镜像变换不能进行合批
使用Multi-pass Shader的物体会禁用Dynamic batching,因为Multi-pass Shader通常会导致一个物体要连续绘制多次,并切换渲染状态。这会打破其跟其他物体进行Dynamic batching的机会
我们知道能够进行合批的前提是多个GameObject共享同一材质,但是对于Shadow casters的渲染是个例外。仅管Shadow casters使用不同的材质,但是只要它们的材质中给Shadow Caster Pass使用的参数是相同的,他们也能够进行Dynamic batching
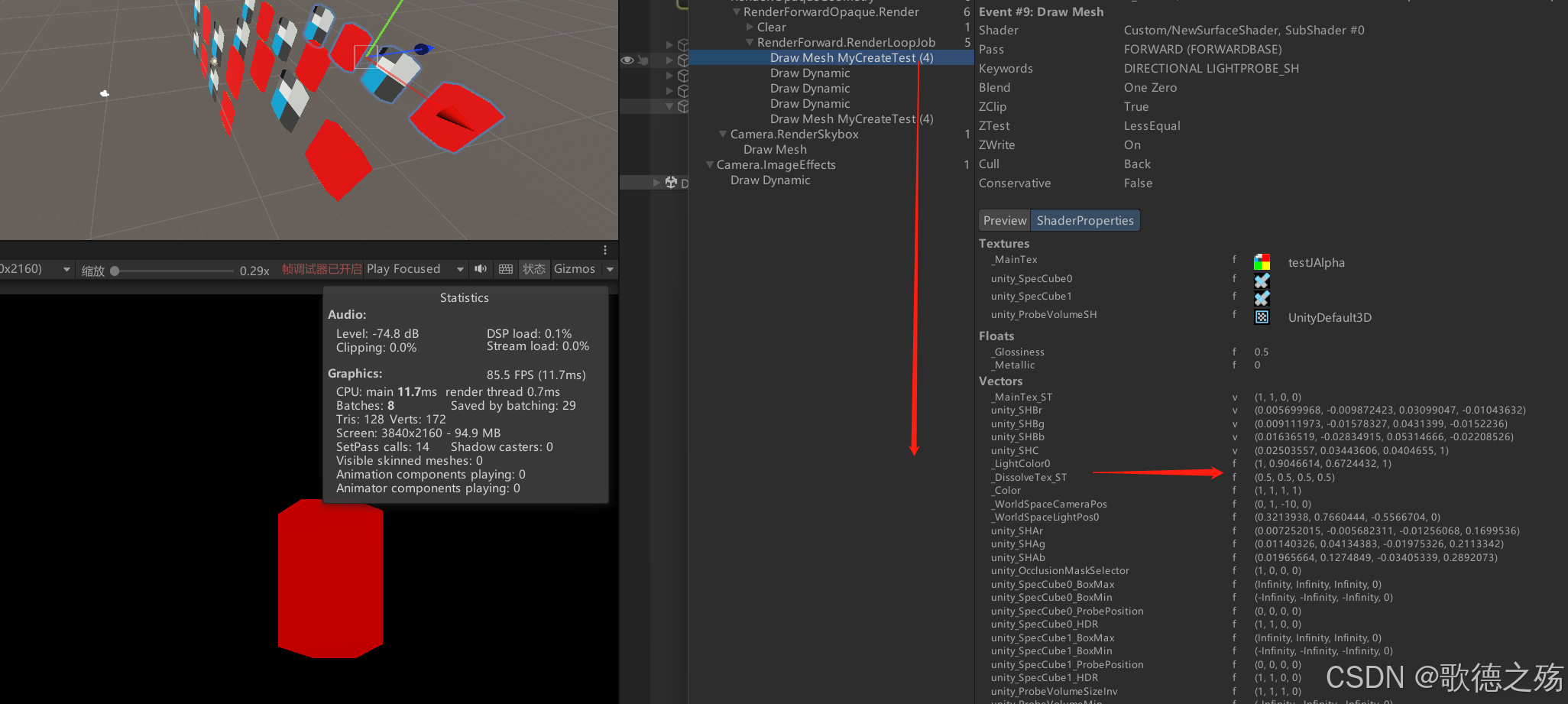
Unity的Forward Rendering Path中如果一个GameObject接受多个光照会为每一个per-pixel light产生多余的模型提交和绘制,从而附加了多个Pass导致无法合批,如下图:
 可以接收多个光源的shader,在受到多个光源是无法合批
可以接收多个光源的shader,在受到多个光源是无法合批
二、静态批处理
1、定义:标明为 Static 的静态物件,如果在使用相同材质球的条件下,在Build(项目打包)的时候Unity会自动地提取这些共享材质的静态模型的Vertex buffer和Index buffer。根据其摆放在场景中的位置等最终状态信息,将这些模型的顶点数据变换到世界空间下,存储在新构建的大Vertex buffer和Index buffer中。并且记录每一个子模型的Index buffer数据在构建的大Index buffer中的起始及结束位置。
https://www.cnblogs.com/gangtie/p/13930657.html
2、静态批处理只是提前把所有的模型顶点变换世界空间下,所以在运行时不需要再次执行顶点变换操作,看似降低了DrawCall实际上只是提前把事情干了。
3、但是静态批处理会有负面影响,就是打包体积会变大,运行是内存也变大【因为提前计算顶点并拷贝了一份在内存中】,所以如果涉及量很多的静态物体还是按需求谨慎一点。
4、使用后无法移动旋转包括动画都无效了。
三、动态批处理和静态批处理 都会被打断的情况
1、位置不相邻且中间夹杂着不同材质的其他物体,不会进行同批处理,这种情况比较特殊,涉及到批处理的顺序,我的另一篇文章有详解
2、拥有lightmap的物体含有额外(隐藏)的材质属性,比如:lightmap的偏移和缩放系数等。所以,拥有lightmap的物体将不会进行批处理(除非他们指向lightmap的同一部分)。
3、Renderer.material的材质被调用修改,会因为这份材质被拷贝而无法参与动态批处理,可以使用Renderer.sharedMaterial来保证材质的共享状态。
4顶点属性要小于900。例如,如果shader中需要使用顶点位置、法线和纹理坐标这三个顶点属性,那么要想让模型能够被动态批处理,它的顶点数目不能超过300。因此,优化策略就是shader的优化,少使用顶点属性,或者模型顶点数要尽可能少。
5使用光照纹理的物体需要小心处理。为了让这些物体可以被动态批处理,需要保证它们指向光照纹理中的同一位置。
四、GPU Instancing
要求及相关学习
1、定义
在使用相同材质球、相同Mesh(预设体的实例会自动地使用相同的网格模型和材质)的情况下,Unity会在运行时对于正在视野中的符合要求的所有对象使用Constant Buffer[5]将其位置、缩放、uv偏移、lightmapindex等相关信息保存在显存中的“统一/常量缓冲器”[6]中,然后从中抽取一个对象作为实例送入渲染流程,当在执行DrawCall操作后,从显存中取出实例的部分共享信息与从GPU常量缓冲器中取出对应对象的相关信息一并传递到下一渲染阶段,与此同时,不同的着色器阶段可以从缓存区中直接获取到需要的常量,不用设置两次常量。比起以上两种批处理,GPU Instancing可以规避合并Mesh导致的内存与性能上升的问题,但是由于场景中所有符合该合批条件的渲染物体的信息每帧都要被重新创建,放入“统一/常量缓冲区”中,而碍于缓存区的大小限制,每一个Constant Buffer的大小要严格限制(不得大于64k)。详细请阅读:

2、要求
无法参与加速情况
1、缩放为负值的情况下,会不参与加速。
2、代码动态改变材质变量后不算同一个材质,会不参与加速,但可以通过将颜色变化等变量加入常量缓冲器中实现[7]。
3、受限于常量缓冲区在不同设备上的大小的上限,移动端支持的个数可能较低。
4、只支持一盏实时光,要在多个光源的情况下使用实例化,我们别无选择,只能切换到延迟渲染路径。为了能够让这套机制运作起来,请将所需的编译器指令添加到我们着色器的延迟渲染通道中。
当在多个光源开启GPU Instancing

批处理中断情况
1、位置不相邻且中间夹杂着不同材质的其他物体,不会进行同批处理,这种情况比较特殊,涉及到批处理的顺序,我的另一篇文章有详解。
2、一个批次超过125个物体(受限于常量缓冲区在不同设备上的大小的上限,移动端数量有浮动)的时候会新建另一个加速流程。
3、物体如果都符合条件会优先参与静态批处理,然后才到GPU Instancing,假如物体符合前者,此次加速都会被打断。


四、SRP Batcher
要求及相关学习
【可以针对不同材质网格】【需是:相同着色器变体!】
1、定义:在使用LWRP或者HWRP时,开启SRP Batcher的情况下,只要物体的Shader中变体一致,就可以启用SRP Batcher加速。它与上文GPU Instancing实现的原理相近,Unity会在运行时对于正在视野中的符合要求的所有对象使用“Per Object” GPU BUFFER(一个独立的Buffer) 将其位置、缩放、uv偏移、lightmapindex等相关信息保存在GPU内存中,同时也会将正在视野中的符合要求的所有对象使用Constant Buffer[5]将材质信息保存在保存在显存中的“统一/常量缓冲器”[6]中。与GPU Instancing相比,因为数据不再每帧被重新创建,而且需要保存进“统一/常量缓冲区”的数据排除了各自的位置、缩放、uv偏移、lightmapindex等相关信息,所以缓冲区内有更多的空间可以动态地存储场景中所有渲染物体的材质信息。由于数据不再每帧被重新创建,而是动态更新,所以SRP Batcher的本质并不会降低Draw Calls的数量,它只会降低Draw Calls之间的GPU设置成本。
SRP Batcher是URP的一种新的合批技术,可以加速CPU,对于DX平台提升比较大,但对于移动平台来说,提升不是很明显,大概1.2倍左右,这部分还根据不同机型有一些差距,感兴趣的可以拿机子去验证。
SRP Batcher是为了解决什么问题诞生的?一个Drawcall被一个新的材质使用的时候,需要准备进行渲染设置工作,这部分耗时是一个drawcall的主要耗时点,所以如果场景有越多的materials,就会有越多的CPU必须使用去设置GPU 数据。传统的优化做法是减少drawcall数量去提升CPU渲染性能,而实际上真正的CPU消耗来自那些设置工作,而不是GPU drawcall本身,Drawcall只是一些Unity向GPU的 command buffer发送的字节数据。

在这里插入代码片
安装好包后右键-》创建-》渲染-》选择相应的


因为不用重新创建Constant Buffer,所以本质上SRP Batcher不会降低Draw Calls的数量,它只会降低Draw Calls之间的GPU设置成本
无法参与加速情况
对象不可以是粒子或蒙皮网格。
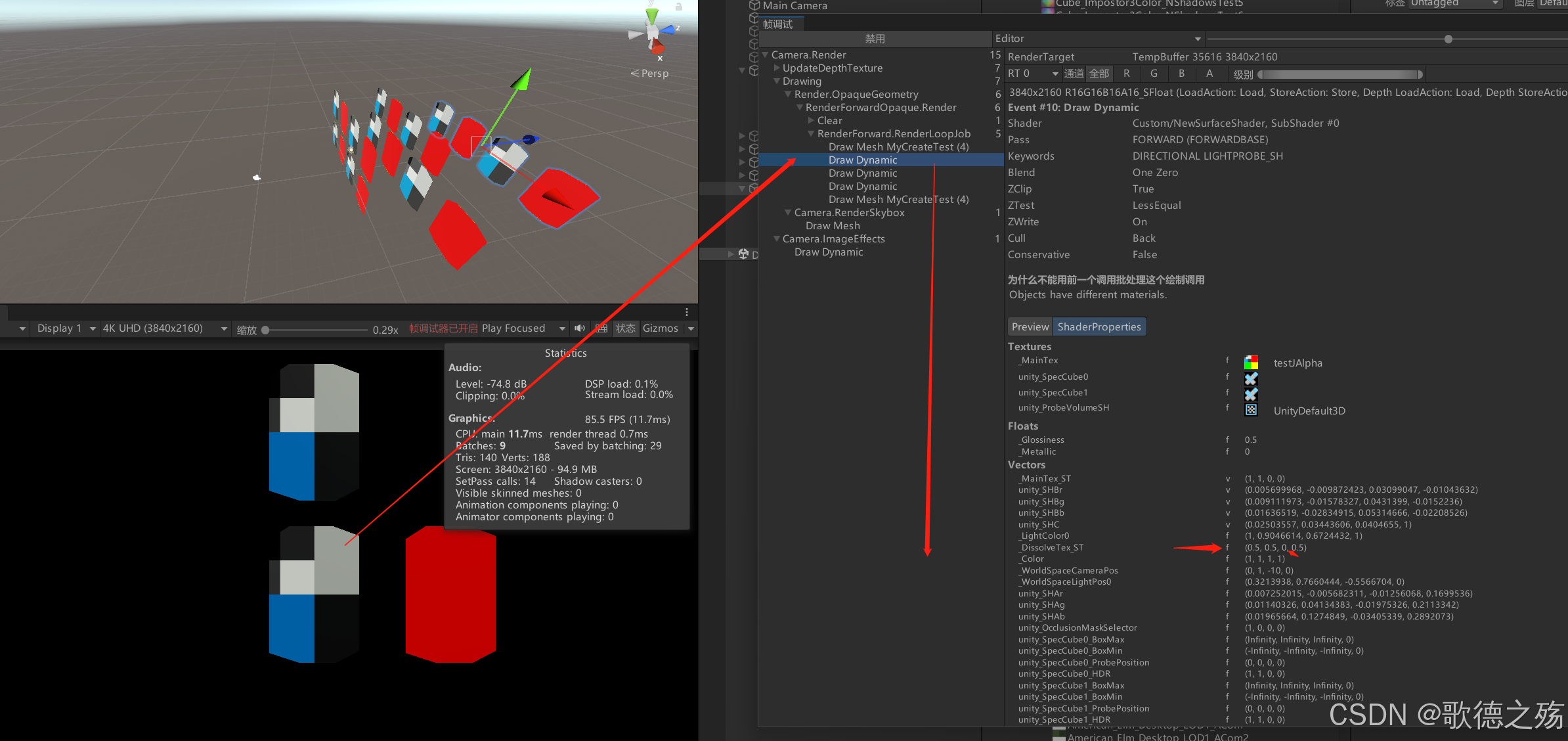
Shader中变体不一致,如下图两个相同Shader的材质,但是因为Surface Options不一致,导致变体不一样而无法合并。

变体不同的不同材质
批处理中断情况
位置不相邻且中间夹杂着不同Shader,或者不同变体的其他物体,不会进行同批处理,这种情况比较特殊,涉及到批处理的顺序,我的另一篇文章有详解。
流程原理


总结:批处理优先级别(都满足情况)
静态批处理 > GPU Instancing > 动态批处理,假如物体符合前两者,此次批处理都会被打断。

第二部分 材质贴图
一、图集和图片
1、png的格式图片相对比较实惠(相同清晰度上容量最小),jpg格式要看压缩比例(容量小的经过压缩清晰度损失),tga(格式太大适合PC端),Dds比png小但是ios不支持(ps软件无此格式徐插件);
2、纹理贴图像素必须是2^n次方大小才能在Unity端最优压缩图片大小,一般手机端256、512、1024用的比较多,1024已经算是奢侈的了。
3、Unity端可以对图片进行格式压缩:常见有RGB…和RGBA… ;前者适用于不透明,后者适用于透明。其中RGBETC2和RGBAETC2只适用OpenGLES3.0的手机(新机基本支持)。
4、UI图片优化通过图集打包来优化,但是因此一个包只需要传输一次,但是这个包里面的内容要确定都是某个渲染图层所需要使用的【NGUI里的Panel层级会影响到,比如2个层级用1个包就是2DrawCall】
https://blog.csdn.net/qq_14939027/article/details/54708264得到验证
材质
1、材质贴图也可以打包图集【未测试】
2、1单通道Shader1材质1DrawCall (可以参与动态批处理) ;双通道Shader无法参与动态批量;【每个双通道材质各增加1DrawCall】
3、多维子材质就是多个材质球,只要其中的Shader是单通道依旧可参与动态批处理;
4、能参与动态批处理的不适合贴图材质合并,会导致动态批处理失败
5、材质贴图合并脚本的效果和静态批处理效果差不多



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











