




 本文介绍了Keras的函数式API,它允许直接操作张量和使用层作为函数。通过示例展示了如何创建简单的模型以及多输入和多输出模型,如问答模型和多任务预测模型。此外,还讨论了Inception模块和相关架构,如Xception,强调了它们在卷积神经网络中的应用。
本文介绍了Keras的函数式API,它允许直接操作张量和使用层作为函数。通过示例展示了如何创建简单的模型以及多输入和多输出模型,如问答模型和多任务预测模型。此外,还讨论了Inception模块和相关架构,如Xception,强调了它们在卷积神经网络中的应用。
一:引言
现阶段许多模型,如多输入模型,多输出模型,类图模型等等,当我们在调用Keras中的Sequential模型类是无法实现的,因此本文介绍函数式API(functional API)。
二:简介
使用函数式API可以直接操作张量,也可以把层当做函数来使用,接收张量并返回张量。
from keras import Input,layers
input_tensor=Input(shape=(32,))#一个张量
dense=layers.Dense(32,activation='relu') #一个层是一个函数
output_tensor=dense(input_tensor )#他可以在一个张量上调用一个层,返回一个张量
编写一个最简单的示例,展示两种方法:
from keras.models import Sequential,Model
from keras import layers
from keras import Input
seq_model=Sequential()
seq_model.add(layers.Dense(32,activation='relu',input_shape=(64,)))
seq_model.add(layers.Dense(32,activation='relu'))
seq_model.add(layers.Dense(10,activation='softmax'))
#函数式API
input_tensor=Input(shape=(64,))
x=layers.Dense(32,activation='relu')(input_tensor)
x=layers.Dense(32,activation='relu')(x)
output_tensor=layers.Dense(10,activation='softmax')(x)
model=Model(input_tensor,output_tensor)#model类将输入张量和输出张量转换为一个模型
model.summary()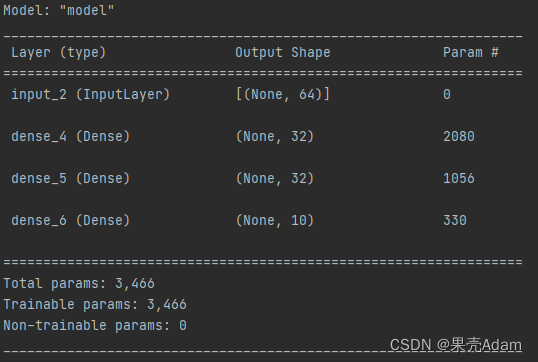
将Model对象实例化只用了一个输入张量和输出张量。Keras会在后台检索从input_tensor到output_tensor所包含的每一层,并将这些层组合成一个类图的数据结构,即一个Model。当然,这种方法有效的原因在于output_tensor是通过对input_tensor进行多次变换得到的。如果利用不相关的输入和输出来构建一个模型,那么会报错。
三:多输入模型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









