






https://arxiv.org/pdf/2006.03654.pdf https://arxiv.org/pdf/2006.03654.pdf
https://arxiv.org/pdf/2006.03654.pdf
引言
(Decoding-enhanced BERT with disentangled attention) 改善BERT和RoBERTa
1. disentangled attention: 每个词 用两个向量表示 content【内容】/ position【位置】
2. mask encoder--- 在encoder部分合并 absolute position,在decoding layer 预测masked tokens
核心:
1. disentagled attention
和bert每个word 在输入层被表示成一个向量【是content和position embedding的和】不同
Deberta用了两个向量分别表示 content 和position
attention weight 用disentangled matrics 计算(基于contents,和 relative position)
2. enhanced mask decoder
设计任务和bert一样,都是MLM(fill - in - the blank)
disentangled attention 考虑到了相对的位置和contents,但没有绝对位置
结合了absolute position in a sentence 在softmax layer前
根据单词内容和位置的聚合上下文嵌入解码被屏蔽的单词
ARCHITECTURE
1. disentangled attention
For a token at position i in a sequence, we represent it using two vectors,
![]() represent its content and relative position with the token at position j, respectively
represent its content and relative position with the token at position j, respectively
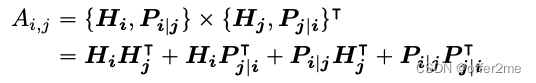
attention weight 是 四个attention score的和
standard self-attention:
k as the maximum relative distance,
as the relative distance from token i to token j:
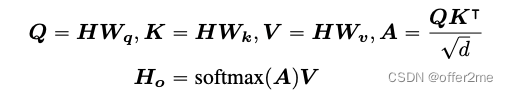
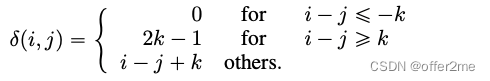
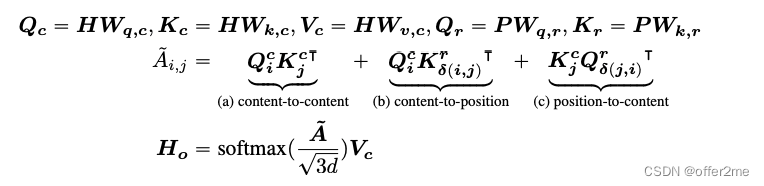

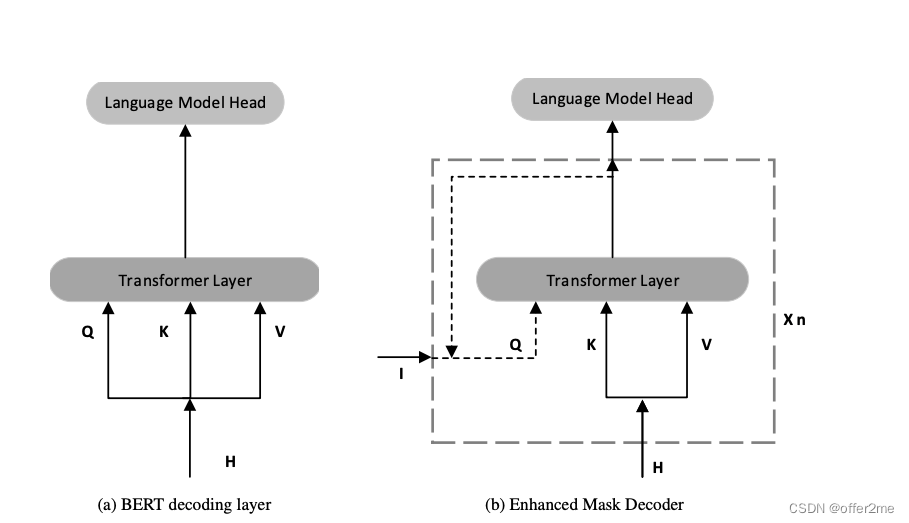
2. ENHANCED MASK DECODER
针对absolute position
文中举出absolute position为什么需要?如果是一个sentence “a new store opened beside the new mall” 这里的“store”和“mall”都是masked的,如果只用relative positions 和sorrounding words是局限的,因为new store 和new mall 是同样的relative position
bert的做法: absolute positions 做为输入层
对于不同的positional_embedding_type,有三种操作:
absolute:默认值,这部分就不用处理;
relative_key:对key_layer作处理,将其与这里的positional_embedding和key矩阵相乘作为key相关的位置编码;
relative_key_query:对key和value都进行相乘以作为位置编码。源码: transformers/modeling_bert.py at main · huggingface/transformers · GitHub
# ... if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query": seq_length = hidden_states.size()[1] position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1) position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1) distance = position_ids_l - position_ids_r positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1) positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility if self.position_embedding_type == "relative_key": relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding) attention_scores = attention_scores + relative_position_scores elif self.position_embedding_type == "relative_key_query": relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding) relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding) attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key # ...“原始的BERT存在预训练和微调不一致问题。预训练阶段,隐层最终的输出输入到softmax预测被mask掉的token,而微调阶段则是将隐层最终输出输入到特定任务的decoder。这个decoder根据具体任务不同可能是一个或多个特定的decoder,如果输出是概率,那么还需要加上一个softmax层。"
Deberta的做法:
在transformer layer后,softamx层结合absolute position 做masked token prediction
Deberta 得到relative positions 在transofrmer layer中,仅仅使用absolute position 作为补充信息















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









