







二郎神系列开新坑啦,Deberta系列上新。
从19年Roberta开源以来,Roberta应该算是使用者最多的Encoder结构模型,简单、效果好,使用起来十分方便,在过去的两年内,基于Roberta(Bert)结构上的改进也层出不穷,也不乏效果还不错的,Deberta就是其中之一。
Deberta是微软在2021年开源的模型,在论文中DeBERTa: Decoding-enhanced BERT with Disentangled Attention中,微软提出了基于注意力解耦机制的解码增强型BERT,在SuperGlue中成功登顶并且超越人类水平。短短一年,Deberta已经迭代了三个版本,但是在中文领域上的相关工作还比较少,“封神榜”大模型开源计划致力于各种前沿的SOTA模型中文领域的应用,目前已经开源40+中文预训练模型。
Deberta一共有三个版本,其中v1,v2在DeBERTa: Decoding-enhanced BERT with Disentangled Attention中提出,而v3版则是在单独的一篇DeBERTa V3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing中提出。
其中v3版本跟v1、v2区别较大,本文将就Deberta V2版本的实现以及我们在Deberta上的尝试做一个简单的介绍。
论文解读
从论文的标题上我们就不难看出,Decoding-enhanced BERT with Disentangled Attention,其中两个关键词分别是:
- Disentangled Attention:解耦注意力,在Bert模型中,Word embedding主要是由Content embedding和Position embedding简单加和得到的,在Deberta中,把Content和Position embedding做了解耦,Word embedding依旧由Content embedding和Position组成,而不是简单的加和,具有更强的表示能力。
- Decoding-enhanced:解码增强,在Bert模型中,预训练的MASK任务在finetuning的时候会和下游任务冲突,在Deberta中设计了一个十分迷你的预测模型来做MASK解码,来避免预训练任务和下游任务上的不一致
我们分别来看看这两个优化点到底是怎么实现的。
Disentangled Attention 解耦注意力
对于一句话位置为i的token,他可以用两个vector {Hi} 和 {Pi|j} 来表示,分别蕴含Content信息和相对于位置j的相对位置编码,那么对于i,j 位置的token,注意力可以表示为
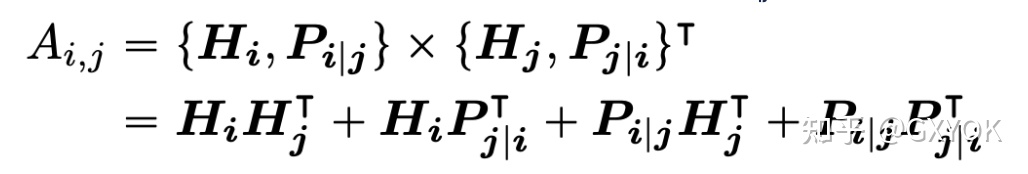
注意力公式
相当于拆解成了四个注意力机制,分别是:
- 内容到内容 content-to-content
- 内容到位置 content-to-position
- 位置到内容 position-to-content
- 位置到位置 position-to-position
在这里,Deberta使用的是Self-Attention with Relative Position Representations论文中的相对位置编码,在计算attention时使用了单独的position embedding,其实就等价于在计算content-to-content、content-to-position。作者认为在相对位置编码中,由内容到位置和位置到内容同样重要,需要完整的保留这俩矩阵才能很好的建模语言模型,所以position-to-content,由于使用了相对位置编码,position-to-position就没有意义了,所以在算注意力的时候把这一项给丢掉了。
其中相对位置的设计如下,k表示最大的相对位置
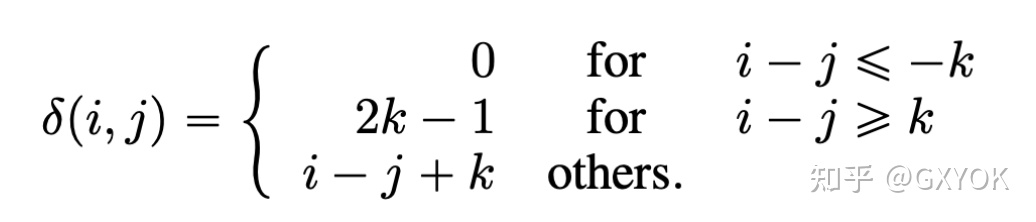
相对距离表示
基于相对位置的设计,解耦注意力的公式如下:
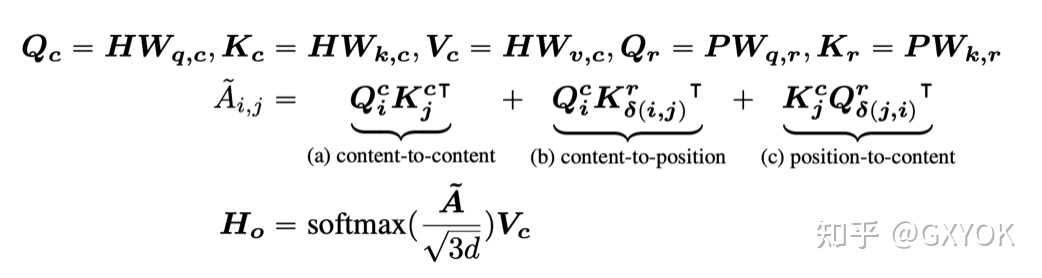
解耦注意力公式
其中,Qc、Kc、Vc 分别是通过Wq,c、Wk,c、Wv,c三个权重在内容向量上生成的投影,那么相对的 Qr和 Kr 就是在位置向量上生成的投影。P是全局的一个相对位置矩阵,在前向过程中保持不变。引用前几版deberta论文里面的图,画的很直接:
在原论文也直接给了伪代码实现:

伪代码
Enhanced Mask Decoder And Absolute Word Positions 增强型掩码编码器和绝对位置编码
在原文中给了一个例子, "a new store opened beside the new mall",如果只有相对位置编码,让模型去预测store和mall不太合理,因为对于这两个词来说前面都是“new”,所以在deberta中,为了让模型更合理的理解store和mall的位置关系,在最后做MASK解码的时候,把绝对位置编码直接加在了隐层上,另外这个绝对位置编码只会在预训练的时候使用,在下游任务不会用到这个位置编码。
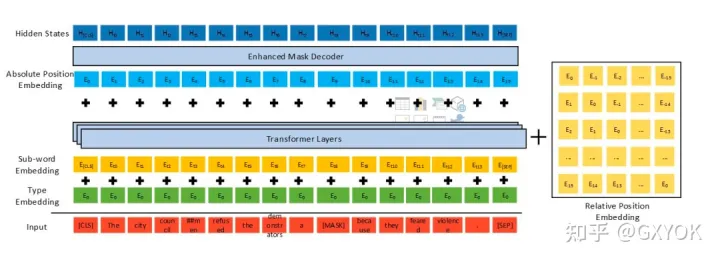
那么我们说的解码增强是怎么实现的,我们直接看网络结构:
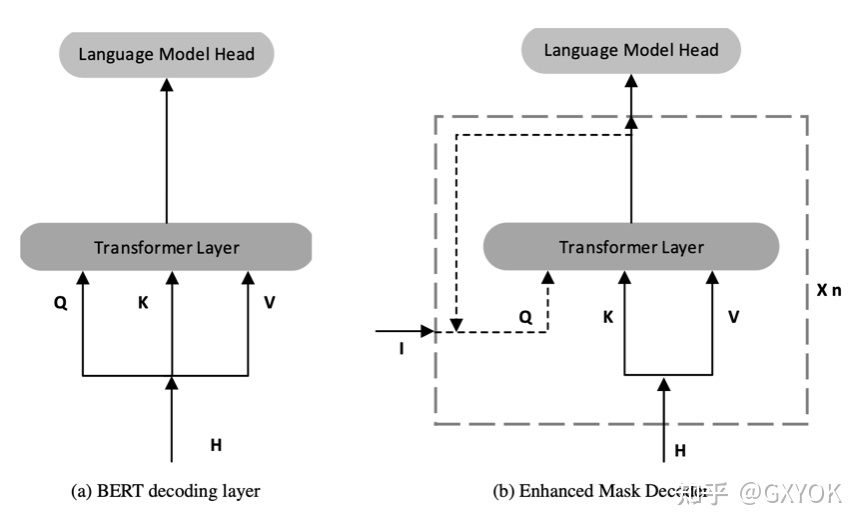
增强解码器设计
跟Bert的对比,最主要的区别是右边用了一个xN的Transformer Layer作为Enhanced Mask Decoder(EMD),相当于用增加网络层数的方法来增加模型的解码能力,比如说12层的Bert,用最后两层transformer layer来做解码,可以看作一个Encoder-Decoder的结构,在Deberta的实验中,baseline使用的是12层的Bert-base模型,Deberta-Base使用11层layer作为encoder,使用2层参数共享的layer作为EMD decoder,由于参数共享实际上也就是一层,在预训练结束后再把这一层作为第12层接到11层的encoder后面,作为一个跟Bert-base相同结构相同体量的模型。
消融实验
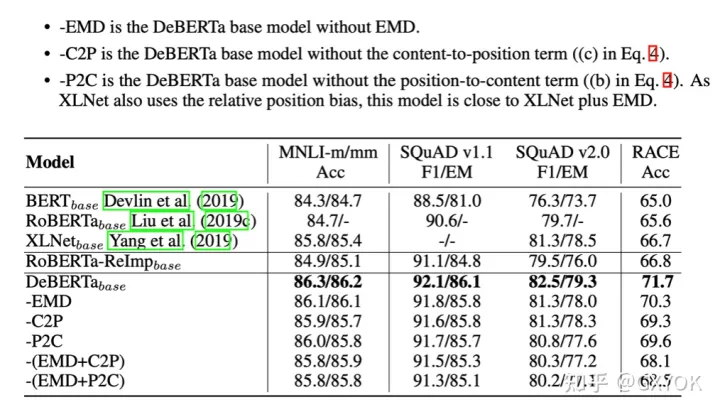
消融实验
在原论文中,做了完整的消融实验,可以看到原论文中提出的两个优化方法解耦注意力机制和EMD解码增强都有一定的效果提升,其中解耦注意力机制提升明显。
整体论文里面细节比较多,甚至代码里面也有部分论文中没有提到的细节,所以十分建议读者自行阅读论文以及源码。
模型开源
本系列计划开源多个模型,包括
IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-Chinese 下载地址
IDEA-CCNL/Erlangshen-DeBERTa-v2-320M-Chinese 下载地址
IDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese 下载地址
IDEA-CCNL/Erlangshen-DeBERTa-v2-1.4B-Chinese 敬请期待
IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-Chinese是我们二郎神系列Deberta结构开源的第一个模型,基于DeBERTa-V2-Base修改,在预训练任务上,我们使用Bert形式的Whole Word Mask,随机MASK掉15%的token,在这15%里面另外有10%的token保持不变,10%的token随机从词表里选取另一词替换,其余的80%用[MASK] token替代。
训练数据基于悟道开源的180G数据,总共过了10亿 samples。
另外原论文中选用SentencePiece做做分词器,在我们之前的尝试中,发现中文场景下SentencePiece的表现并不是很好,所以这里使用的BertTokenizer作为分词器。
Xlarge 目前总共过了700M+ samples,已经得到了不错的效果,甚至在部分任务上比我们之前效果最好的13亿Erlangshen-MegatronBert更好,十分欢迎大家尝试,在实际使用中几乎可以无损替换Roberta结构的任务。
使用方式
通过下面的代码可以快速开始体验
from transformers import AutoModelForMaskedLM, AutoTokenizer, FillMaskPipeline
import torch
tokenizer=AutoTokenizer.from_pretrained('IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-Chinese', use_fast=false)
model=AutoModelForMaskedLM.from_pretrained('IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-Chinese')
text = '生活的真谛是[MASK]。'
fillmask_pipe = FillMaskPipeline(model, tokenizer)
print(fillmask_pipe(text, top_k=10))下游Finetune
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM
cd Fengshenbang-LM
pip install --editable .
fengshen-pipeline text_classification train --model='IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-Chinese' --datasets='IDEA-CCNL/AFQMC' --gpus=0 --texta_name=sentence1 --strategy=ddp使用封神的pipeline,可以快速启动AFQMC的finetune任务,其他任务只需要按照我们的形式预处理一下数据即可。
实验评估(更新中)

跟Erlangshen-MegatronBert-1.3B模型比起来,参数量小接近50%,在OCNLI、CMNLI任务上表现更优,同时相比roberta-wwm-ext-large有更好的效果,欢迎大家直接来尝试。

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









