







 本文探讨了如何利用深度学习技术,如AGCN和STGCN,精确捕捉花样滑冰选手的骨骼点,以支持比赛分析和运动理解。研究集中在数据集的处理、模型训练与优化,以及在实际场景中的精度评估,展示了在冬奥会视觉项目中的实用价值。
本文探讨了如何利用深度学习技术,如AGCN和STGCN,精确捕捉花样滑冰选手的骨骼点,以支持比赛分析和运动理解。研究集中在数据集的处理、模型训练与优化,以及在实际场景中的精度评估,展示了在冬奥会视觉项目中的实用价值。
花样滑冰选手骨骼点识别(AGCN&STGCN)
紧跟着冬奥会的一个视觉项目,非常有意思。可以检测选手的骨骼点识别。


基于飞桨实现花样滑冰选手骨骼点动作识别大赛采用PaddleVideo中的ST-GCN模型,就能得到还不错的效果。也可以使用优化后的模型AGCN,获取更高的精度。

数据集介绍
本赛题数据集旨在通过花样滑冰研究人体的运动。在花样滑冰运动中,人体姿态和运动轨迹相较于其他运动呈现复杂性强、类别多的特点,有助于细粒度图深度学习新模型、新任务的研究。
在数据集中,所有的视频素材从2017 到2018 年的花样滑冰锦标赛中采集。源视频素材中视频的帧率被统一标准化至每秒30 帧,并且图像大小是1080 * 720 来保证数据集的相对一致性。之后我们通过2D姿态估计算法Open Pose对视频进行逐帧骨骼点提取,最后以.npy格式保存数据集。
训练数据集与测试数据集的目录结构如下所示:
train_data.npy
train_label.npy
test_A_data.npy
test_B_data.npy # B榜测试集后续公开
其中train_label.npy通过np.load()读取后会得到一个一维张量,每一个元素为一个值在0-29之间的整形变量代表动作的标签;data.npy文件通过np.load()读取后,会得到一个形状为N×C×T×V×M的五维张量,每个维度的具体含义如下:
| 维度符号表示 | 维度值大小 | 维度含义 | 补充说明 |
|---|---|---|---|
| N | 样本数 | 代表N个样本 | 无 |
| C | 3 | 分别代表每个关节点的x,y坐标和置信度 | 每个x,y均被放缩至-1到1之间 |
| T | 1500 | 代表动作的持续时间长度,共有1500帧 | 有的动作的实际长度可能不足1500,例如可能只有500的有效帧数,我们在其后重复补充0直到1500帧,来保证T维度的统一性 |
| V | 25 | 代表25个关节点 | 具体关节点的含义可看下方的骨架示例图 |
| M | 1 | 代表1个运动员个数 | 无 |
骨架示例图:

项目环境准备
进入BML主页,点击立即使用
🔗:https://ai.baidu.com/bml/
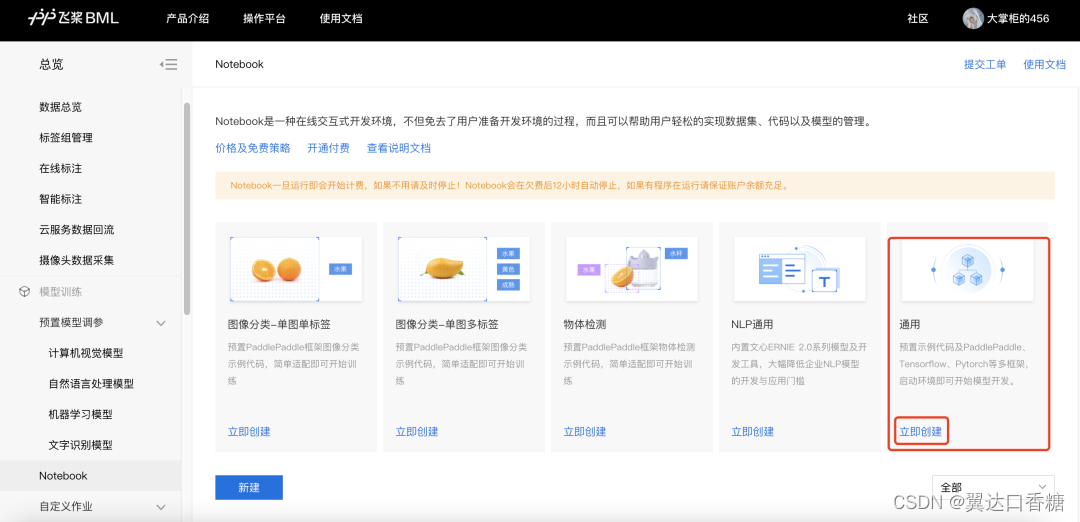
step2:点击Notebook,创建“通用任务”
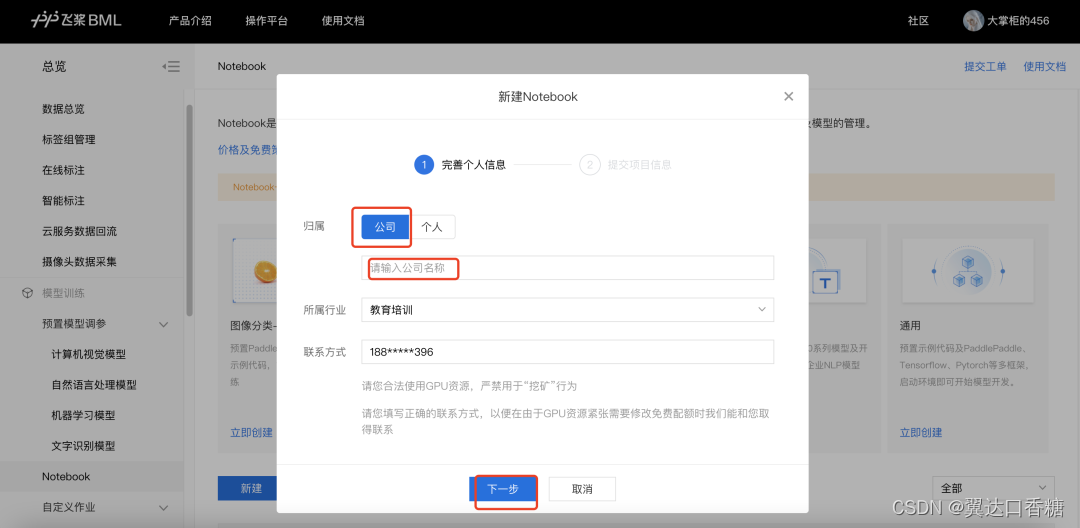
step3:填写任务信息。
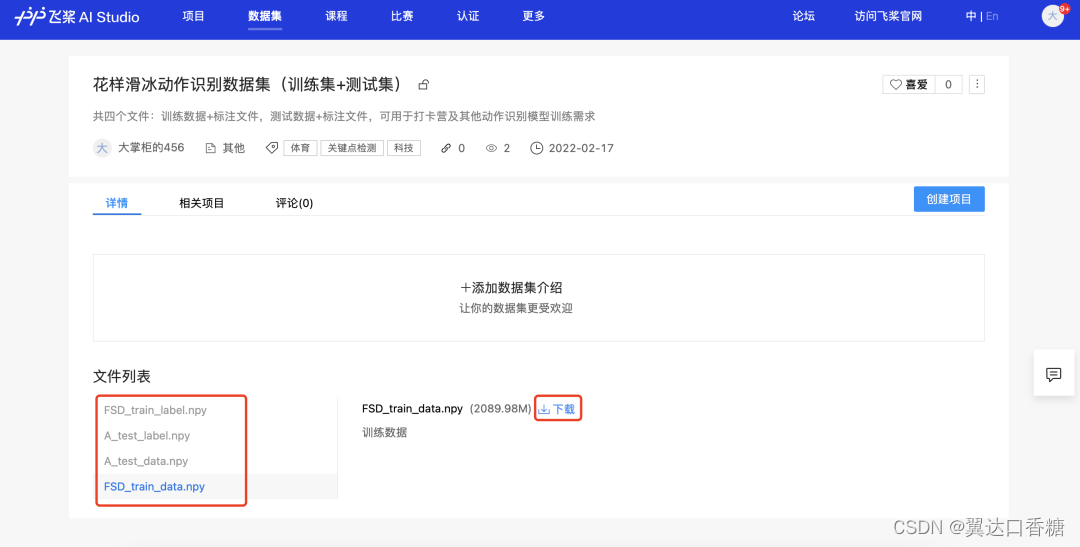
第二步:下载数据集
下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/128506
四个文件都需要下载
第三步:下载任务操作模板
下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/128507
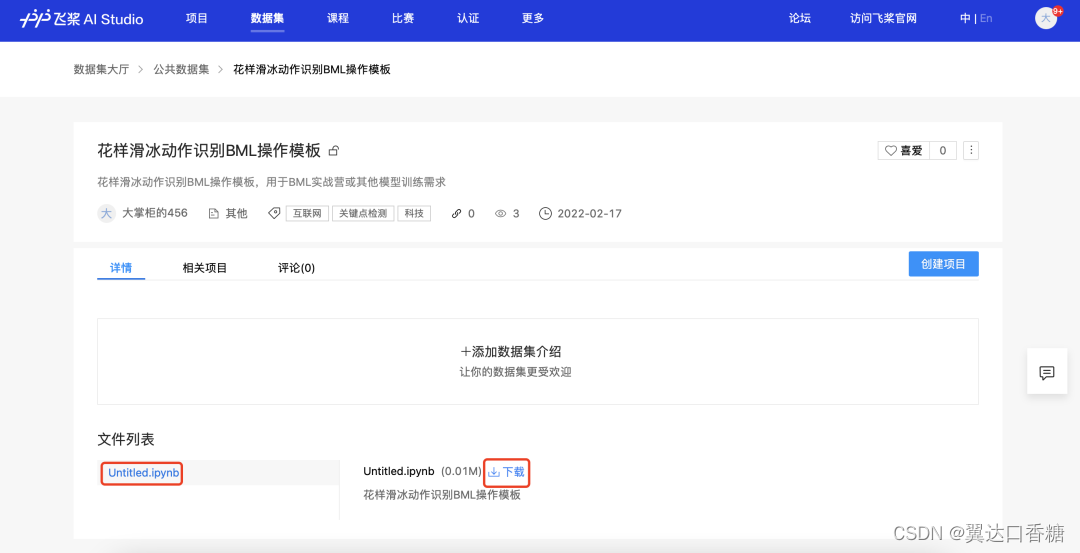
4.上传本次Notebook操作模型、数据集、测试集,共5个文件
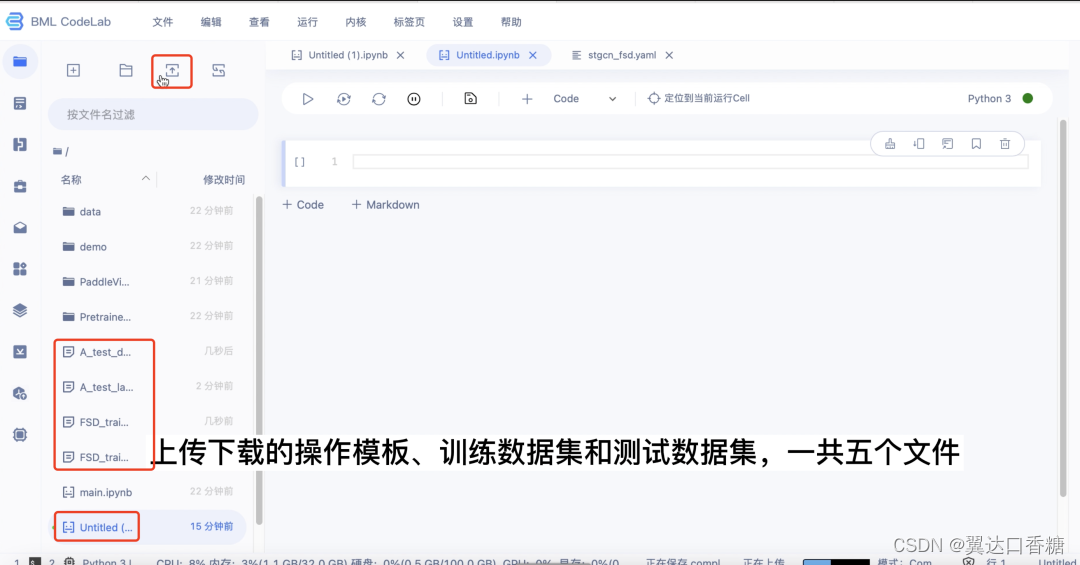
第一步:环境准备
1.下载PaddleVideo、
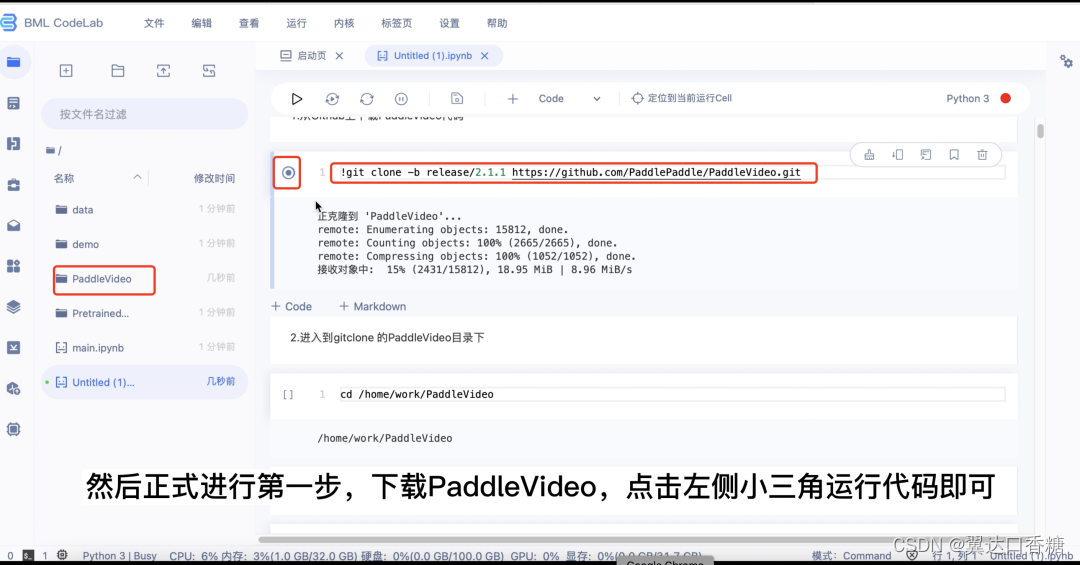
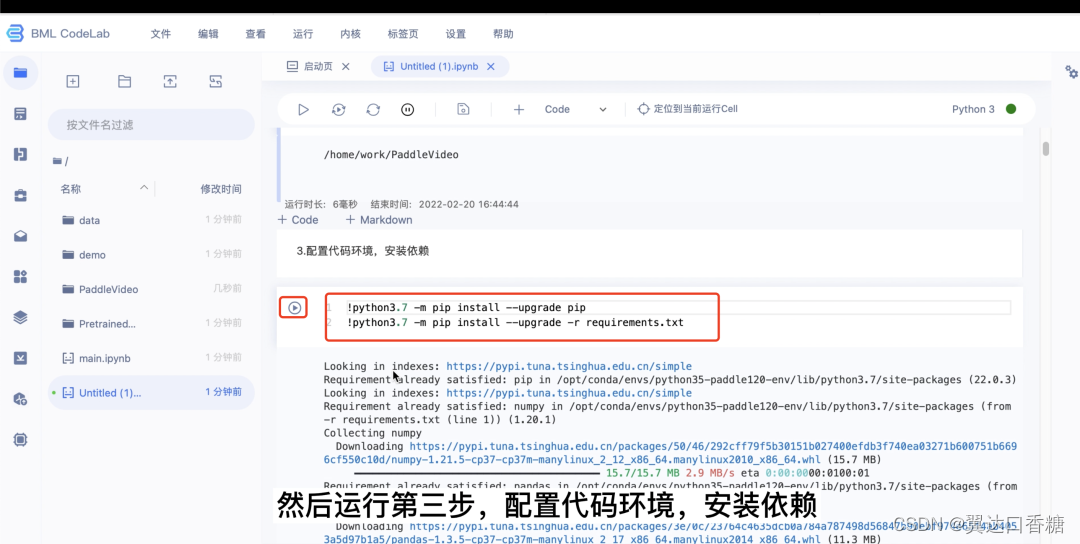
2.安装PaddleVideo的相关依赖
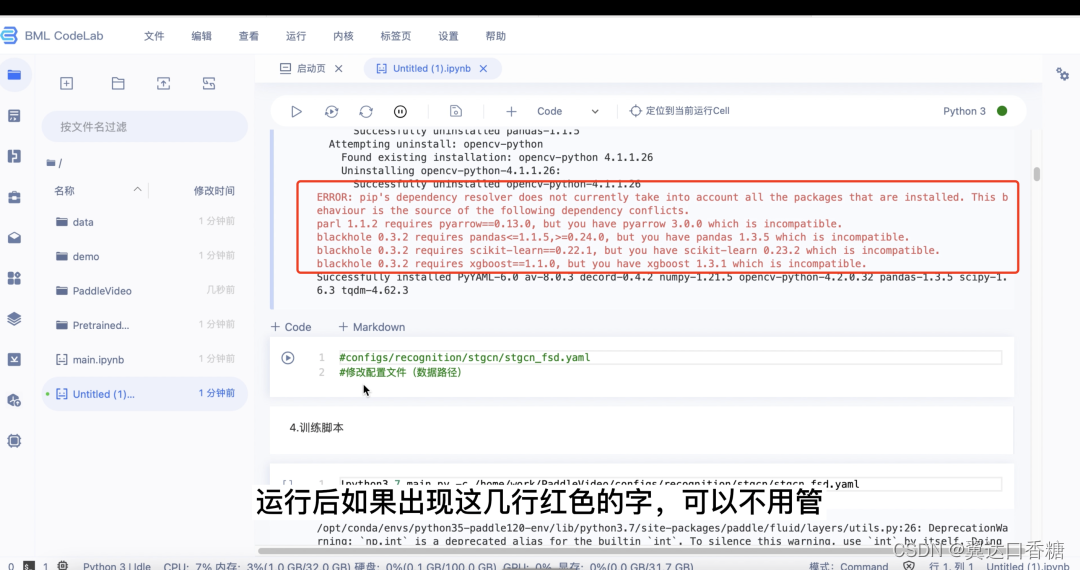
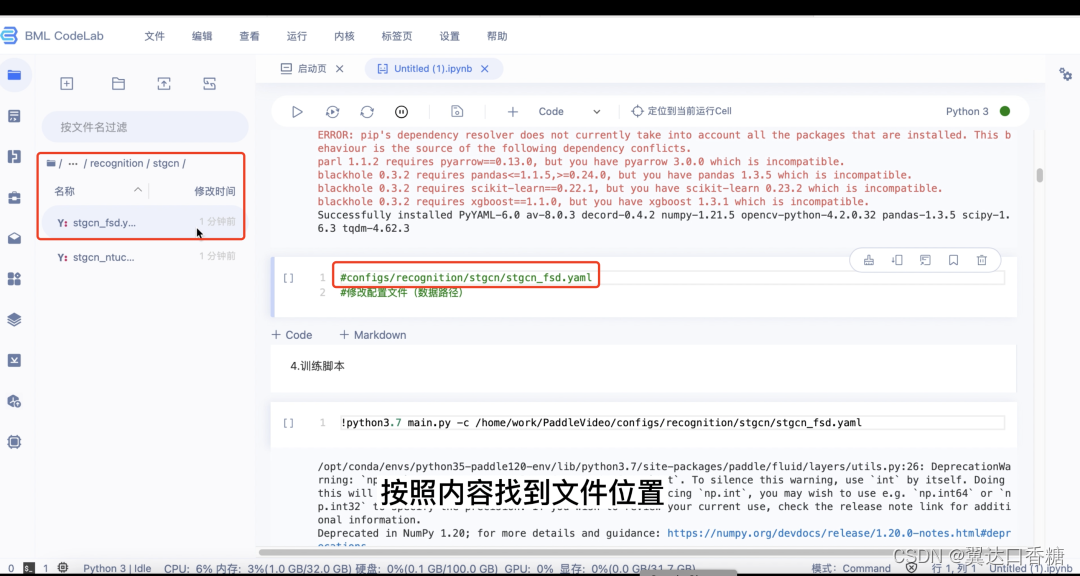
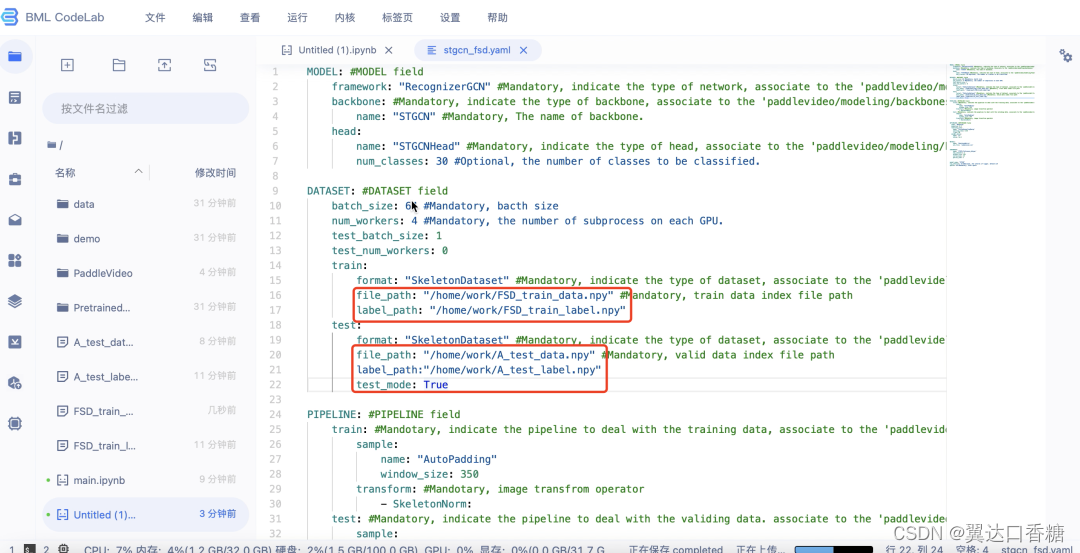
5.修改配置文件(数据路径),找到对应文件,打开,修改训练集和测试集路径
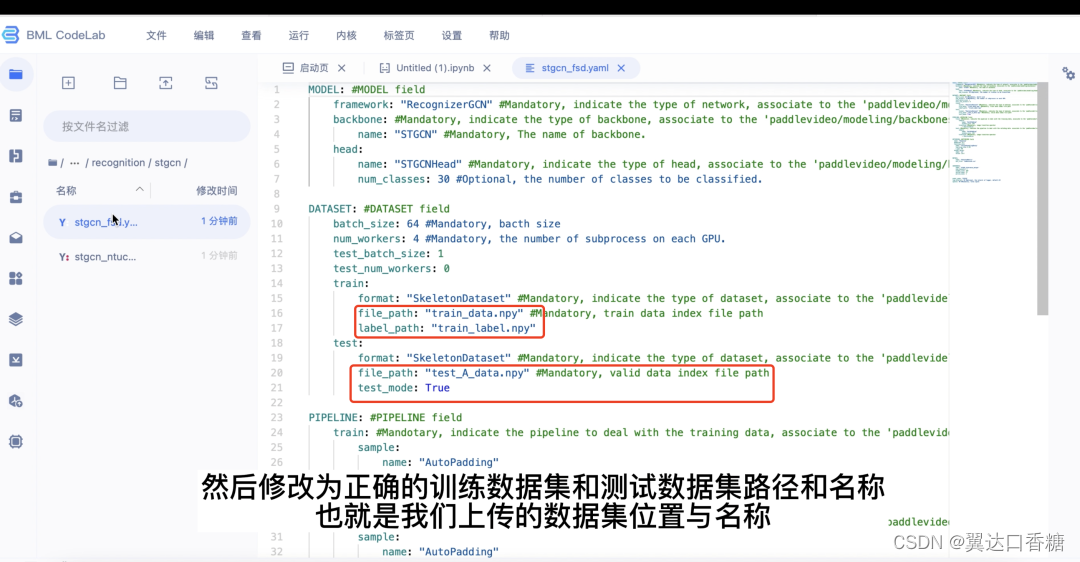
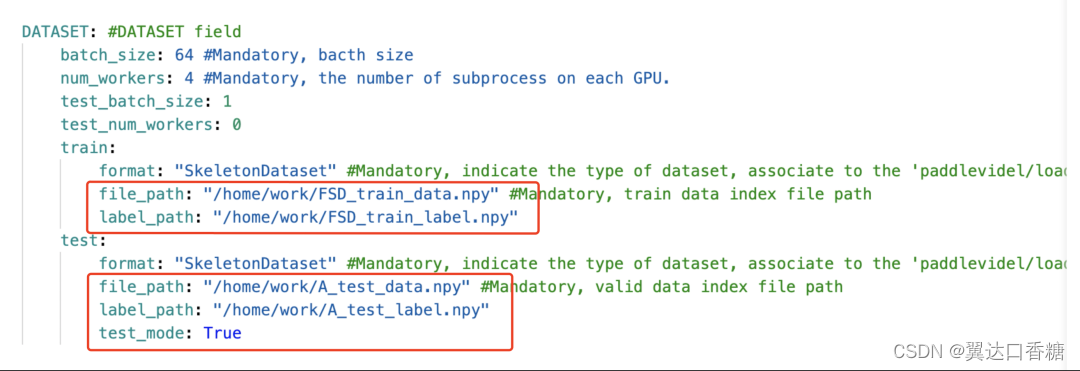
改成这样(必须英文输入)
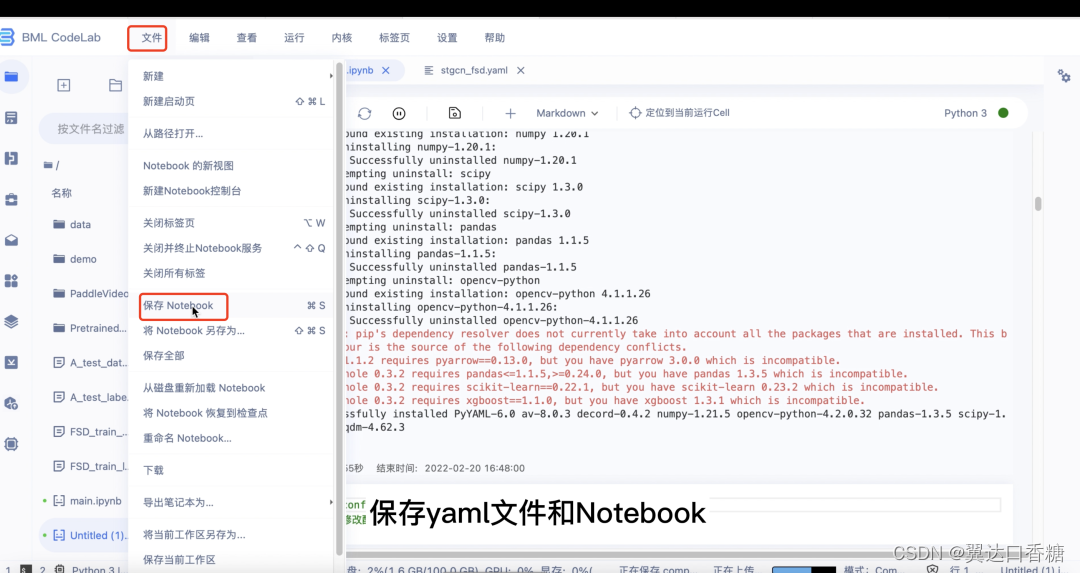
6.保存yaml文件和Notebook文件

模型训练
3.进行模型训练,约需要半小时训练完成。
训练结果保存在PaddleVideo/output文件夹下
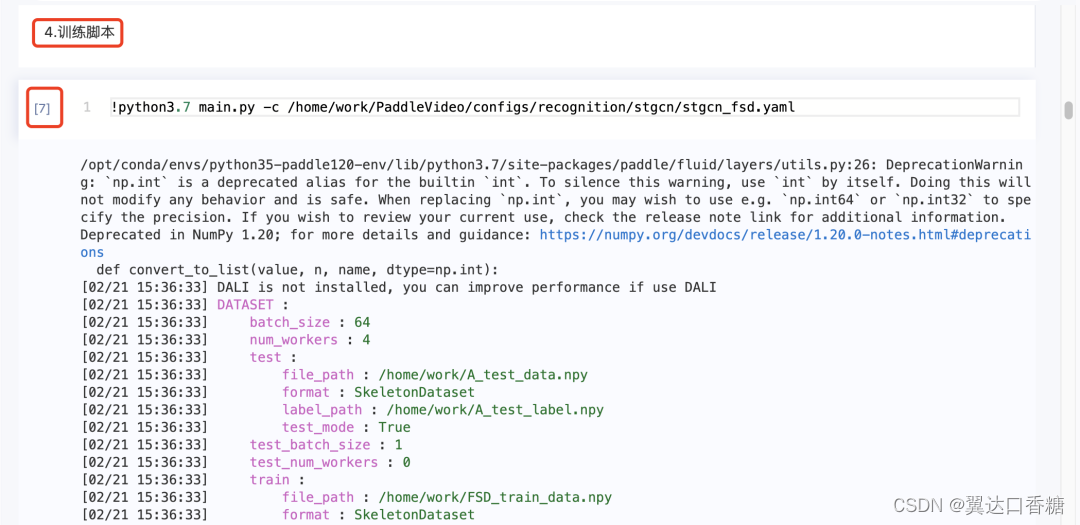
如果你想调整训练参数,可以在configs/recognition/stgcn/stgcn_fsd.yaml文件中找到网络结构与数据路径。
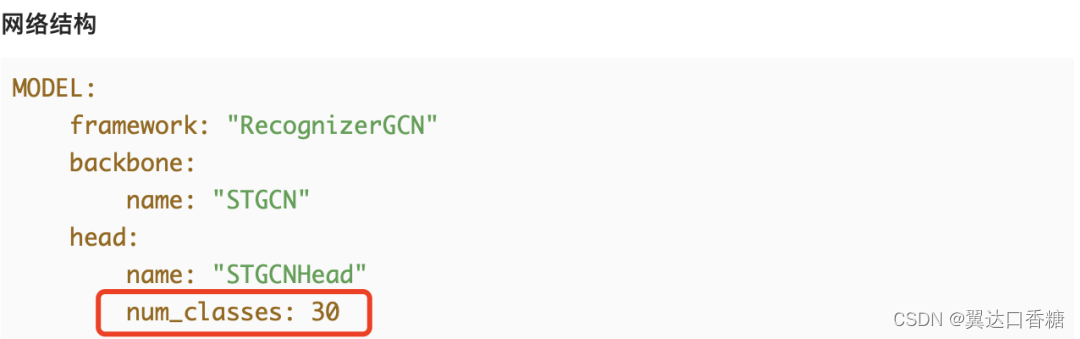
表示我们使用的是ST-GCN算法,framework为RecognizerGCN,backbone是时空图卷积网络STGCN,head使用对应的STGCNHead,数据集分类采用30分类 (用若用户使用10分类数据集,请在此更改为num_classes:10)。
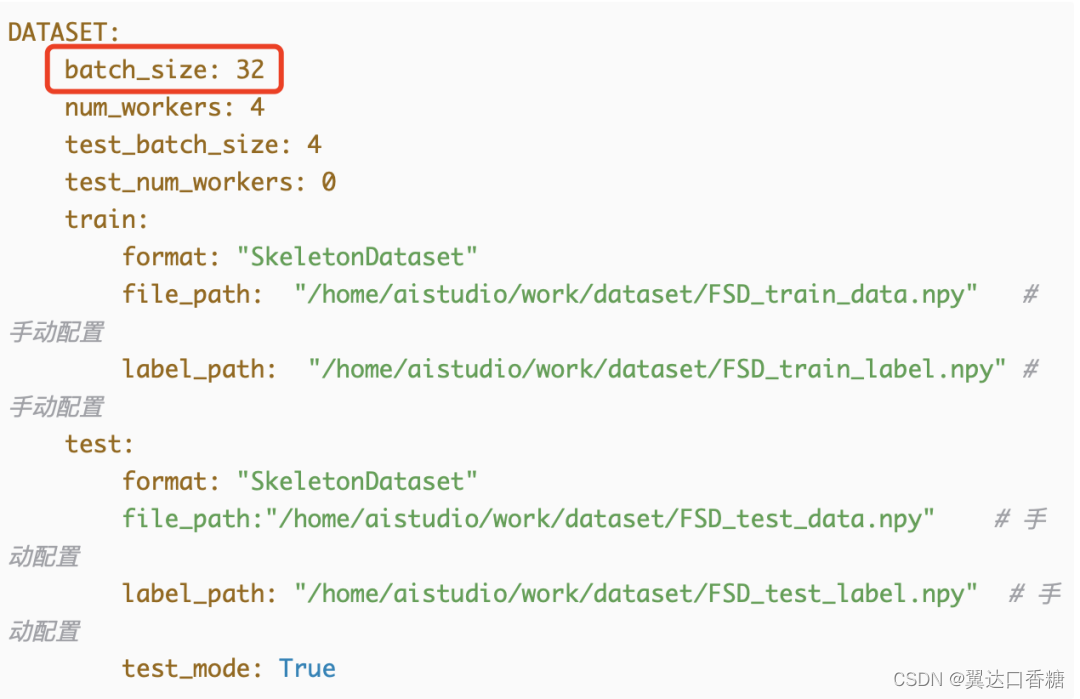
若修改为10分类训练,除了修改数据集路径之外,在上一步网络结构中需要修改num_classes。(可以通过降低batch_size来提升实验效果,但是会加长训练时长)
4.进行模型测试
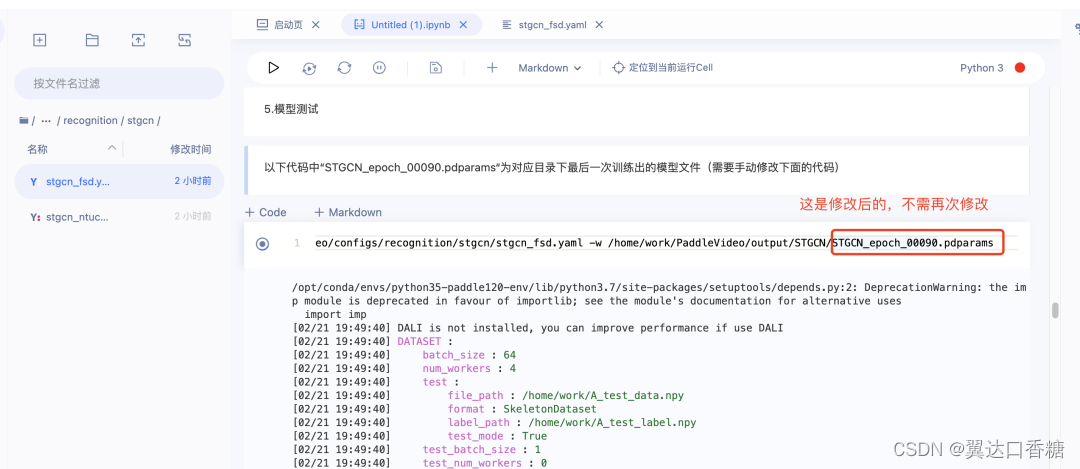
本案例中自带训练权重
通过-c参数指定配置文件,通过-w指定权重存放路径进行模型测试。
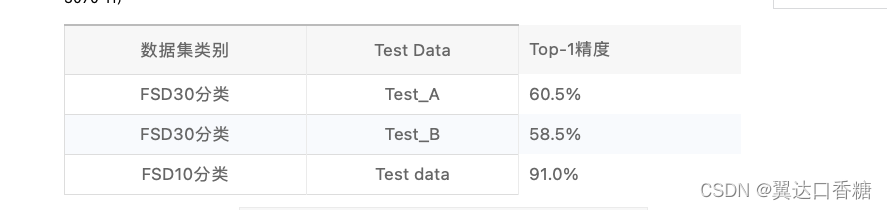
ST-GCN模型实验精度
本案例仅选用优化后单模型ST-GCN进行试验,分别在FSD30分类与10分类的测试集下计算模型精度。模型优化策略选用了数据平均抽帧(降维),随机可学习骨骼点子图划分、通过矩阵拼接替换爱因斯坦求和约定操作。下表展示了ST-GCN模型在不同测试集下实验精度结果(单卡NVIDIA GeForce RTX 3070 Ti)
数据集类别 Test Data Top-1精度
在FSD10分类下需要修改 configs/recognition/stgcn/stgcn_fsd.yaml 文件中num_classes、batch_size等参数。通过修改参数(eg. batch_size:8,16),可以达到91%左右的测试集精度。
模型导出
在安装环境依赖后新增一行代码并运行(在安装环境依赖前也可以),升级一下paddlepaddle
代码:!python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
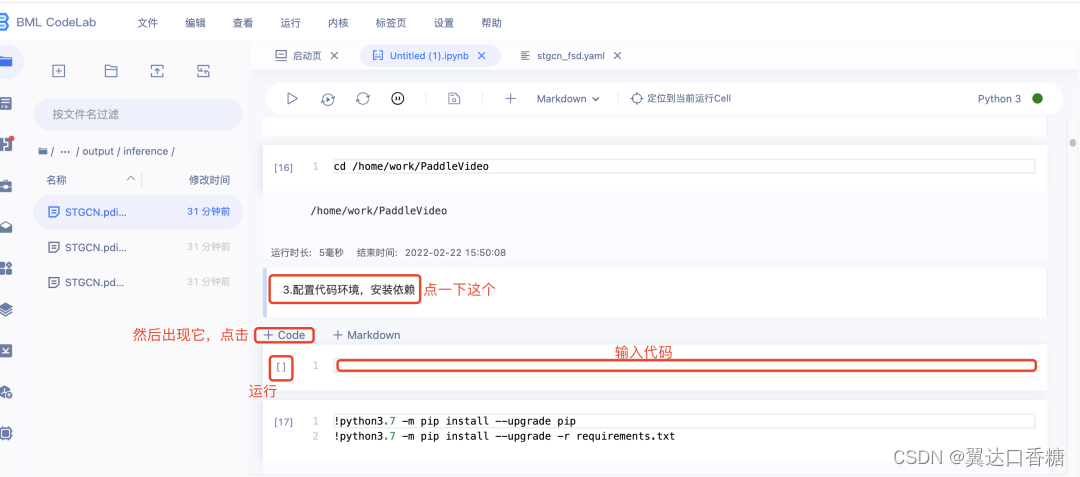
4.进行模型导出,代码有更新,需要替换
更新后的代码:!python3.7 /home/work/PaddleVideo/tools/export_model.py -c /home/work/PaddleVideo/configs/recognition/stgcn/stgcn_fsd.yaml -p /home/work/PaddleVideo/output/STGCN/STGCN_epoch_00090.pdparams -o /home/work/PaddleVideo/output/inference
上述命令将生成预测所需的模型结构文件STGCN.pdmodel和模型权重文件STGCN.pdparams。
代码中的参数含义可参考↓:https://github.com/PaddlePaddle/PaddleVideo/blob/release/2.0.0/docs/zh-CN/start.md#2-模型推理
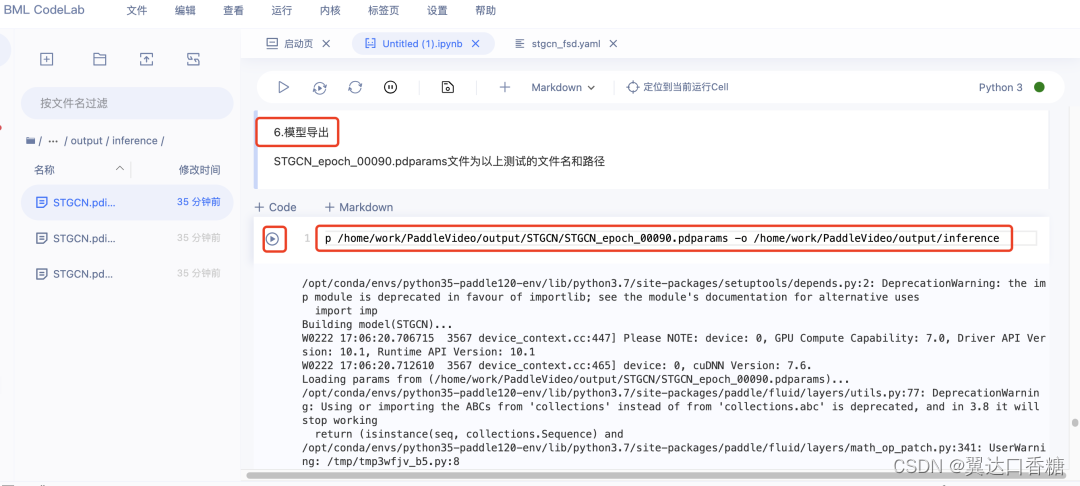
导出后的模型就在 /home/work/PaddleVideo/output/inference里
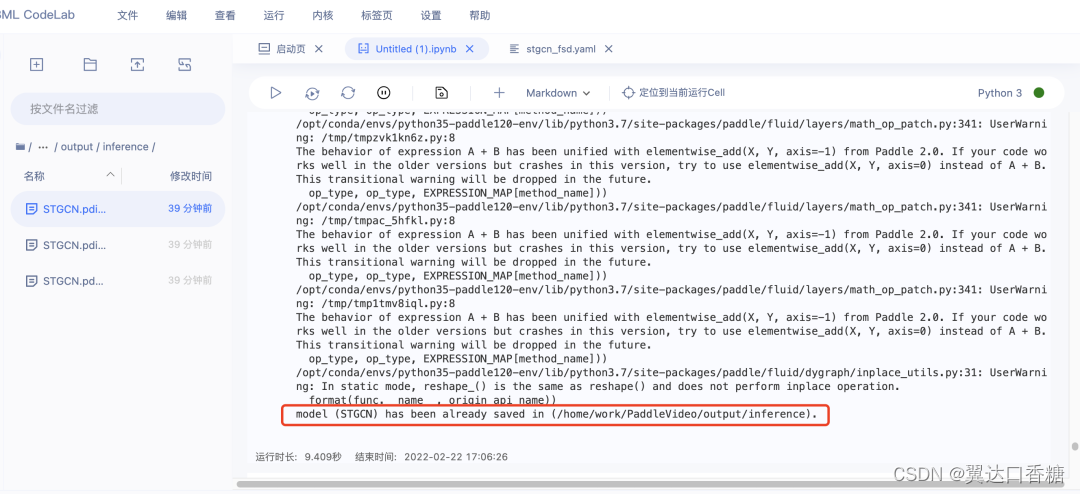
导出成功界面如下
5.进行模型预测,代码有更新,需要替换
更新后的代码:
!python3.7 /home/work/PaddleVideo/tools/predict.py
–input_file /home/work/PaddleVideo/data/fsd10/example_skeleton.npy
–config /home/work/PaddleVideo/configs/recognition/stgcn/stgcn_fsd.yaml
–model_file /home/work/PaddleVideo/output/inference/STGCN.pdmodel
–params_file /home/work/PaddleVideo/output/inference/STGCN.pdiparams
–use_gpu=True
–use_tensorrt=False
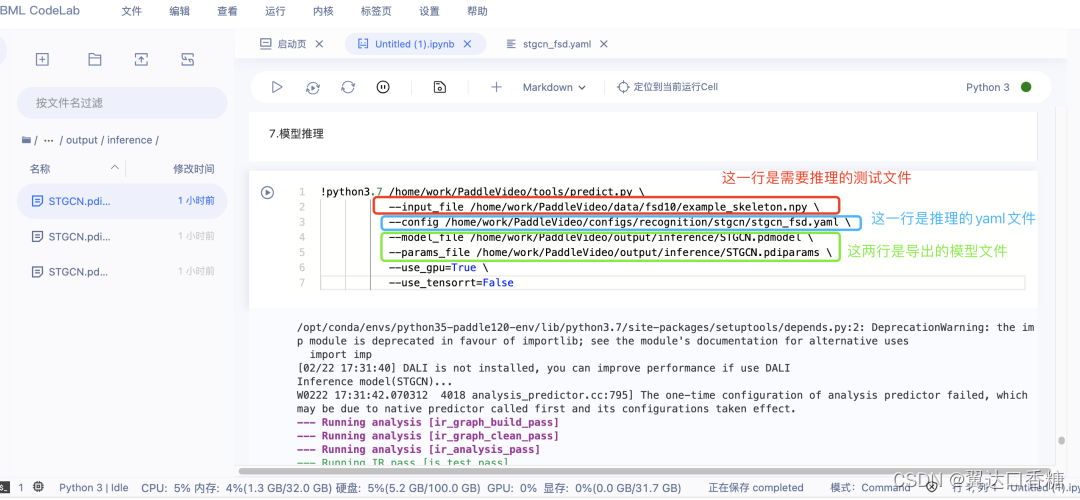
按照上图中的代码注释,确认一下文件名
模型推理成功的截图:
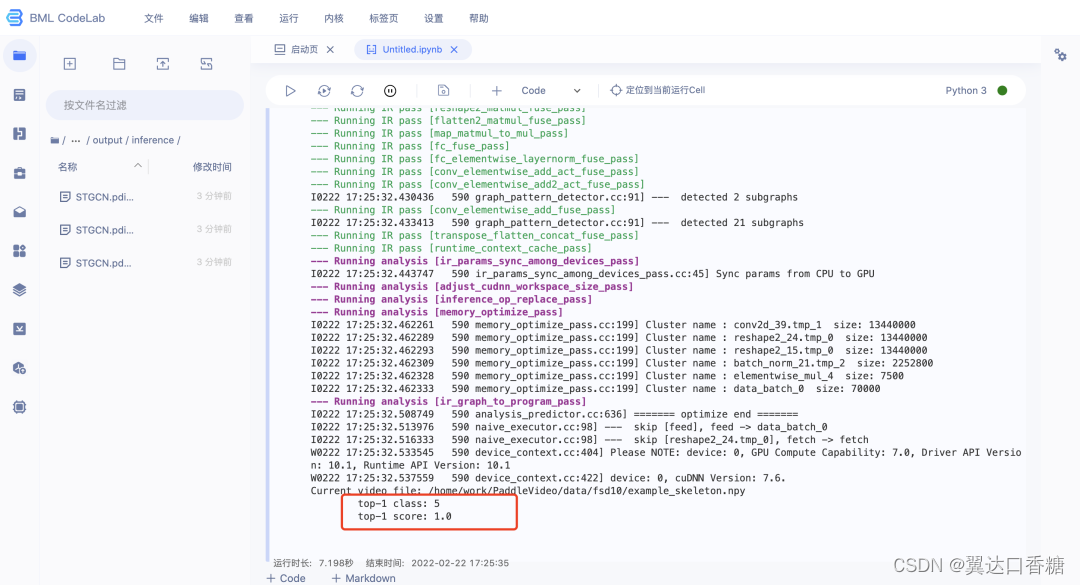
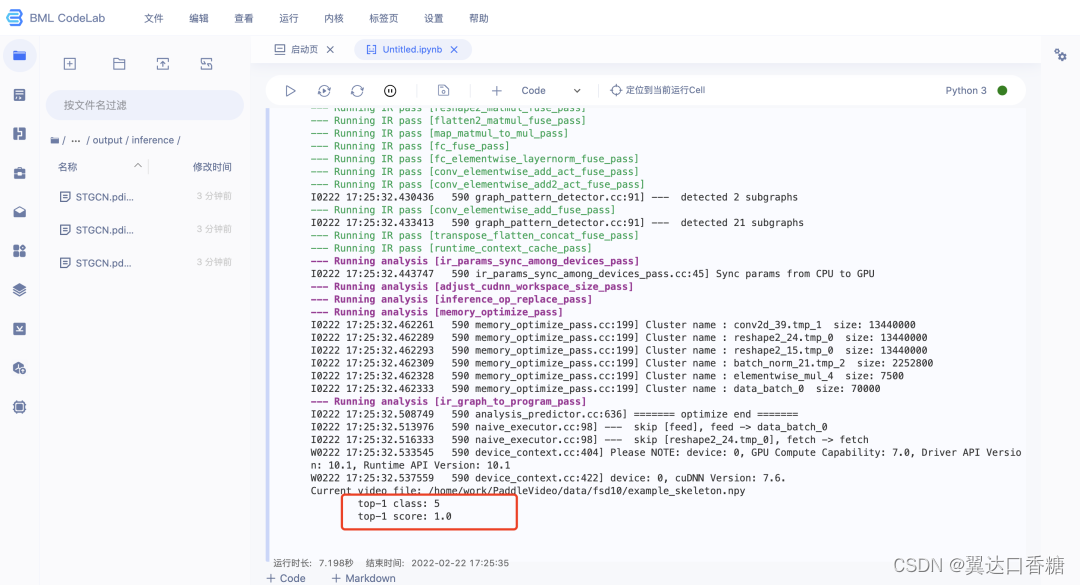



















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











