







关键词:TCN-Transformer的时间序列预测 Transformer的时间序列预测 Pytorch
代码内容:
-
Pytorch实现TCN-Transformer的时间序列预测;、
-
同时包含Transformer的时间序列预测对比试验代码
3.数据集描述,此次实验的数据属性为date(日期)、open(开盘价)、high(最高价)、low(最低价)、close(收盘价)以及volume(成交量),其中,我们要实现股票预测,需要着重对close(收盘价)一列进行探索性分析。
注意事项:默认支持GPU运行,无GPU,自动切换CPU运行!
仿真平台:pycharm + python3.9 + pytorch 2.1.2 + pandas 1.5.3 + numpy 1.20.3
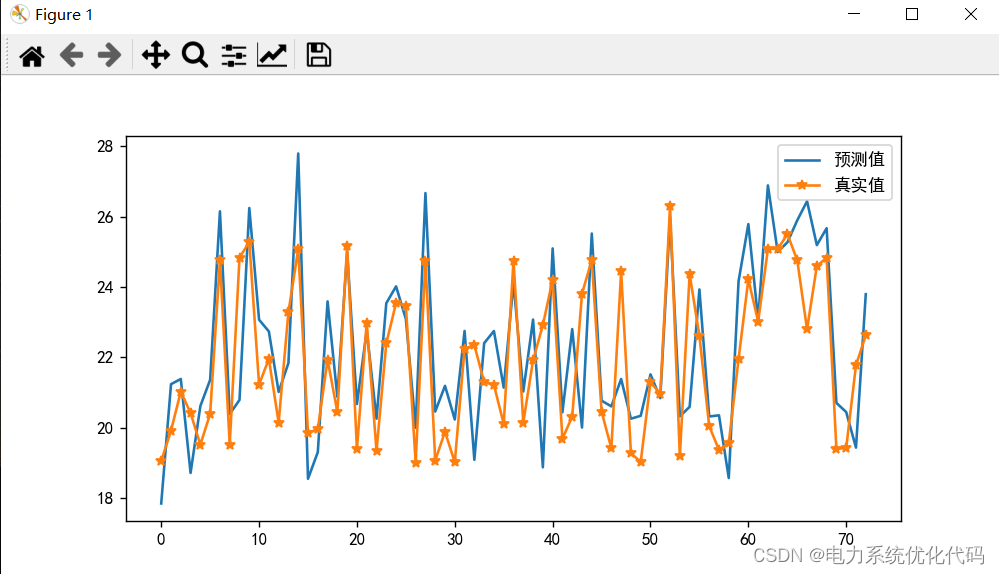
程序仿真效果图:
部分程序代码:
# 需要u'内容'
# 2.定义获取数据函数,数据预处理。去除ID,股票代码,
# 前一天的收盘价,交易日期等对训练集无用的数据
def getData(root, sequence_length, batch_size):
stock_data = pd.read_csv(root)
print(stock_data.info())
print(stock_data.head().to_string())
#首先删除一些对预测close无用的信息
stock_data.drop('id', axis=1, inplace=True) # 删除date
stock_data.drop(labels="ts_code", axis=1, inplace=True)
stock_data.drop(labels="trade_date", axis=1, inplace=True)
stock_data.drop(labels="pre_close", axis=1, inplace=True)
stock_data.drop(labels="change", axis=1, inplace=True)
stock_data.drop(labels="pct_chg", axis=1, inplace=True)
stock_data.drop(labels="amount", axis=1, inplace=True)
print("整理后\n", stock_data.head())
#获取收盘价的最大值与最下值
close_max = stock_data["close"].max() # 收盘价的最大值
close_min = stock_data["close"].min() # s收盘价的最小值
# 2.1对数据进行标准化min-max
scaler = MinMaxScaler()
df = scaler.fit_transform(stock_data)
print("整理后\n", df)
# 2.2构造X,Y
# 根据前n天的数据,预测未来一天的收盘价(close),
# 例如根据1月1日、1月2日、1月3日、1月4日、1月5日的数据
# (每一天的数据包含8个特征),预测1月6日的收盘价。
sequence = sequence_length
x = []
y = []
for i in range(df.shape[0] - sequence):
x.append(df[i:i + sequence, :])
y.append(df[i + sequence, 3])
x = np.array(x, dtype=np.float32)
y = np.array(y, dtype=np.float32).reshape(-1, 1)
print("x.shape=", x.shape)
x=np.transpose(x,(0,2,1))
print("转置后x.shape=", x.shape)
print("y.shape", y.shape)
# 2.3构造batch,构造训练集train与测试集test
total_len = len(y)
print("total_len=", total_len)
trainx, trainy = x[:int(0.90 * total_len), ], y[:int(0.90 * total_len), ]
testx, testy = x[int(0.90 * total_len):, ], y[int(0.90 * total_len):, ]
train_loader = DataLoader(dataset=Mydataset(trainx, trainy), shuffle=True, batch_size=batch_size)
test_loader = DataLoader(dataset=Mydataset(testx, testy), shuffle=True, batch_size=batch_size)
return [close_max, close_min, train_loader, test_loader]
# 3.自己重写数据集继承Dataset
class Mydataset(Dataset):
def __init__(self, x, y):
self.x = torch.from_numpy(x)
self.y = torch.from_numpy(y)
def __getitem__(self, index):
x1 = self.x[index]
y1 = self.y[index]
return x1, y1
def __len__(self):
return len(self.x)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
root = r".\data\300808.SZ.csv"
close_max, close_min, train_loader, test_loader = getData(root, sequence_length=sequence_length, batch_size=batch_size)
print("close_max=,close_min=",close_max,close_min)
print("train_loader=",len(train_loader))
print("test_loader=",len(test_loader))
















 1883
1883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









