







 本文探讨了深度神经网络的对抗性攻击,特别是黑盒场景下,提出了一种基于扩散模型的新型攻击策略DiffAttack。文章利用扩散模型的隐藏能力和迭代降噪特性,创建出不可察觉且可转移的攻击样本。实验结果显示,DiffAttack在保持自然度的同时,显著超越了现有攻击方法在可转移性和抗防御方面的性能。
本文探讨了深度神经网络的对抗性攻击,特别是黑盒场景下,提出了一种基于扩散模型的新型攻击策略DiffAttack。文章利用扩散模型的隐藏能力和迭代降噪特性,创建出不可察觉且可转移的攻击样本。实验结果显示,DiffAttack在保持自然度的同时,显著超越了现有攻击方法在可转移性和抗防御方面的性能。
文章目录
一、文章概览
(一)研究动机
- 深度神经网络对于精心设计的颠覆(“对抗性”)具有较强的敏感性,可能会在实际应用中引发严重错误,因此需要加大对于对抗性攻击的研究;
- 黑盒攻击相对于白盒攻击而言更接近现实世界的场景,因此也更具有研究价值;
- 现有的方法大多采用RGB颜色空间中的Lp范数来衡量扰动的大小,并且取得了一定的成功,但它们仍然存在一些问题:
- Lp范数并不适合用来衡量图像之间的感知距离,因为它不能很好地模拟人类感知的差异。
- 生成的扰动仍然很容易被人眼察觉
- 尽管这些攻击方法可能在原始模型上表现良好,但它们往往在将对抗性样本传递给其他黑盒模型时效果不佳
- 基于Lp范数的对抗攻击也容易受到一些防御机制的影响

- 最新的研究表明,可以通过新的方法来欺骗人类感知,而不必受限于Lp范数的约束,这被称为不受限制的攻击。无限制攻击产生的扰动更多地关注具有高级语义的相对大规模的模式,而不是操纵像素级强度,因此有利于攻击可转移到其他黑盒模型,甚至是被防御的模型。然而,这些方法的可转移性仍然落后于基于像素的方法。
(二)扩散模型
将扩散模型引入对抗性攻击领域的动机主要源于它的两个有益特性:
- 良好的隐蔽性。扩散模型最初是为图像合成而设计的,倾向于生成符合人类感知的自然图像。这种固有的品质与对抗性攻击的不可察觉性要求非常吻合。此外,扩散模型中的迭代降噪过程有助于减少可感知的高频噪声。
- 隐式代理的近似。尽管最初是为图像合成而设计的,但在大规模数据集上训练的扩散模型表现出了显着的判别能力。此功能使我们能够将它们近似为基于传输的攻击的隐式代理模型。利用这种“隐式代理”,我们可以潜在地增强跨不同模型和防御的可转移性。此外,扩散模型的去噪过程类似于强大的净化防御,可以进一步增强我们针对防御机制的攻击的有效性。
(三)文章工作
- 是第一个揭示扩散模型凭借其卓越的生成和隐式判别能力,为创建具有高度不可察觉性和可转移性的对抗性例子。
- 提出DiffAttack,一种新颖的无限制攻击,其中通过仔细的设计利用了扩散模型的良好特性。通过利用交叉和自注意力图并攻击扩散模型的潜力,DiffAttack 既不可察觉又可转移。
- 对各种模型架构、数据集和防御方法进行的广泛实验证明了文章的工作相对于现有攻击方法的优越性。
二、模型方法
(一)问题表述
给定一个干净的图像 x 及其相应的标签 y,攻击者的目标是制造扰动,使分类器 Fθ(θ 表示模型的参数)的决策从正确变为错误:
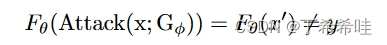
(二)核心思想
提出了一种基于扩散模型的新型无限制攻击:优化现成的预训练扩散模型的潜力
- 建立了一个基本的攻击框架,该框架最初将干净的图像转换为噪声,然后在潜在空间中引入修改。这与现有的图像编辑技术不同,后者操纵引导文本来实现内容编辑。相反,我们直接对扩散模型的潜力进行操作,这可以显着提高攻击的成功率。
- 其次,我们建议偏离文本和图像像素之间的交叉注意力图,通过这种方式,我们可以将扩散模型转换为实际上可以被欺骗和攻击的隐式代理模型。
- 最后,为了避免扭曲最初的语义,具体考虑了包括自注意力约束和反转强度在内的措施。
(三)具体框架
1、DDIM反演技术
DiffAttack框架结合了稳定扩散预训练模型和DDIM反演技术,利用了图像编辑的思想,从而实现了对抗攻击的生成过程。
DDIM反演技术(DDIM Inversion technology)是一种基于扩散过程的反向映射技术。简单来说,这种技术可以将干净的图像映射回扩散的潜空间,实现从原始图像到扩散潜空间的逆向转换过程。这样一来,可以在潜空间中对图像进行修改,然后再将修改后的图像映射回原始图像空间,从而实现对抗攻击的目的。
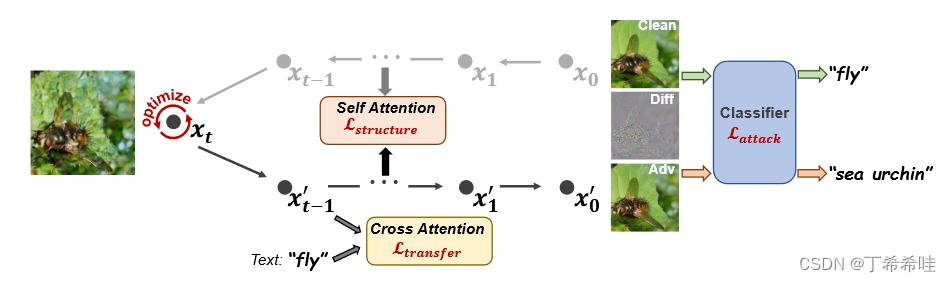
对从 x0(初始图像)到 xt 的几个时间步应用DDIM反演操作。如果我们对 xt 进行确定性去噪过程,则可以预期 x0 的高质量重建:
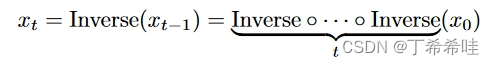
2、扰乱扩散模型中潜在的 x t x_t xt
许多现有的图像编辑技术通过操纵引导文本来实现内容编辑,但是这种方法的可迁移性较弱。因此,文章直接扰乱扩散模型潜在的xt,这可以显着提高攻击的成功率。
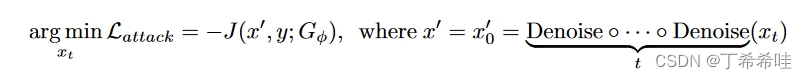
3、偏离文本和图像像素之间的交叉注意力图
在反向潜在变量的重建过程中,交叉注意力图显示了引导文本和图像像素之间的强关系,这证明了预训练扩散模型的潜在识别能力。因此,在海量数据上训练的扩散模型可以近似为隐式识别模型,如果我们精心设计的攻击可以“欺骗”这个模型,我们可以期望提高向其他黑盒的可转移性楷模。
这里交叉注意力中文本和像素之间有很强的关系,而自注意力可以很好地揭示结构。

为了“欺骗”预训练的扩散模型,我们建议最小化以下公式:
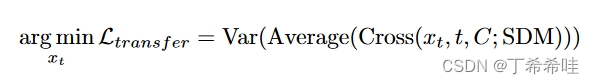
其中Var(·)计算输入的方差,Cross(·)表示去噪过程中所有交叉注意力图的累加,SDM是稳定扩散。其目的是分散扩散模型对标记对象的注意力。通过将注意力均匀地分配到每个像素,我们可以破坏原始的语义关系,确保我们精心设计的对抗性示例能够很好地“欺骗”扩散模型。通过这样的设计,DiffAttack 表现出了隐式的集成特性。
4、内容结构的保护
自注意力控制:
- 扩散模型的自注意会捕获结构信息,忽略图像外观,因此文章建议利用自注意力图来保留结构。
- 设置一个反向潜在变量的副本
x
t
(
f
i
x
)
x_{t(fix)}
xt(fix),它是固定的,没有扰动。通过分别计算
x
t
(
f
i
x
)
x_{t(fix)}
xt(fix)和
x
t
x_{t}
xt的自注意力图(记为
S
t
(
f
i
x
)
S_{t(fix)}
St(fix) 和
S
t
S_t
St),迫使
S
t
S_t
St 接近
S
t
(
f
i
x
)
S_{t(fix)}
St(fix):
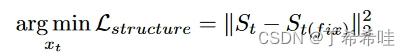
反转强度权衡:
DDIM反演强度过高会影响较多的去噪步骤从而导致严重的失真
DDIM反演强度过低又无法提供足够的攻击空间
扩散模型倾向于在早期的去噪步骤中添加粗略的语义信息(例如布局),而在后期的步骤中添加更精细的细节。因此,文章控制去噪过程后面的反转以保留高级语义,并减少总 DDIM 样本步骤以获得更多编辑空间。
DiffAttack的最终目标函数:
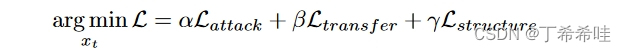
三、实验
(一)实验设置
数据集: ImageNet-Compatible Dataset2 ,之后在 CUB-200-2011和斯坦福汽车上进行了进一步的实验。
模型: 评估了攻击在各种网络结构(包括 CNN、Transformers 和 MLP)中的可转移性。
- CNN: ConvNeXt、ResNet-50 (Res-50)、VGG-19 、Inception-v3 (Inc-v3)和 MobileNet-v2(Mob-v2)。
- Transformers:ViT-B/16 (ViT-B) 、Swin-B、DeiT-B 和 DeiT-S 。
- MLP:Mixer-B/16 (Mix-B) 和 Mixer-L/16 (Mix-L) 。
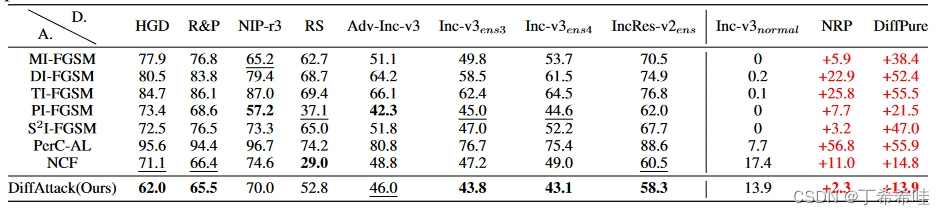
此外考虑了各种防御方法,包括 DiffPure 、RS (Jia et al., 2020)、R&P 、HGD、 NIPS-r3、NRP,和对抗训练模型(Adv-Inc-v3、Inc-v3ens3、Inc-v3ens4 和 IncRes-v2ens)。
实施细节: 利用 DDIM作为stable-diffusion的采样器。步骤数设置为 20,对初始干净图像应用 5 个 DDIM 反转步骤。在反演过程中,引导尺度设置为0,而在去噪过程中,我们将其设置为2.5。为了优化潜在 xt,我们采用 AdamW,学习率设置为 1e−2,迭代次数设置为 30。方程中的权重因子 α、β、γ。 6分别设置为10、10000、100。所有实验均在单个 RTX 3090 GPU 上运行。
评估指标: top-1 准确率用于评估攻击方法的性能,Frechet 起始距离 (FID)作为精心设计的对抗性示例的人类不可感知性的指标。完整参考指标 LPIPS也用于评估感知差异。
(二)正常训练模型的可转移性和不可察觉性比较
将 DiffAttack 在正常训练模型上的性能与其他基于转移的黑盒攻击进行了比较。
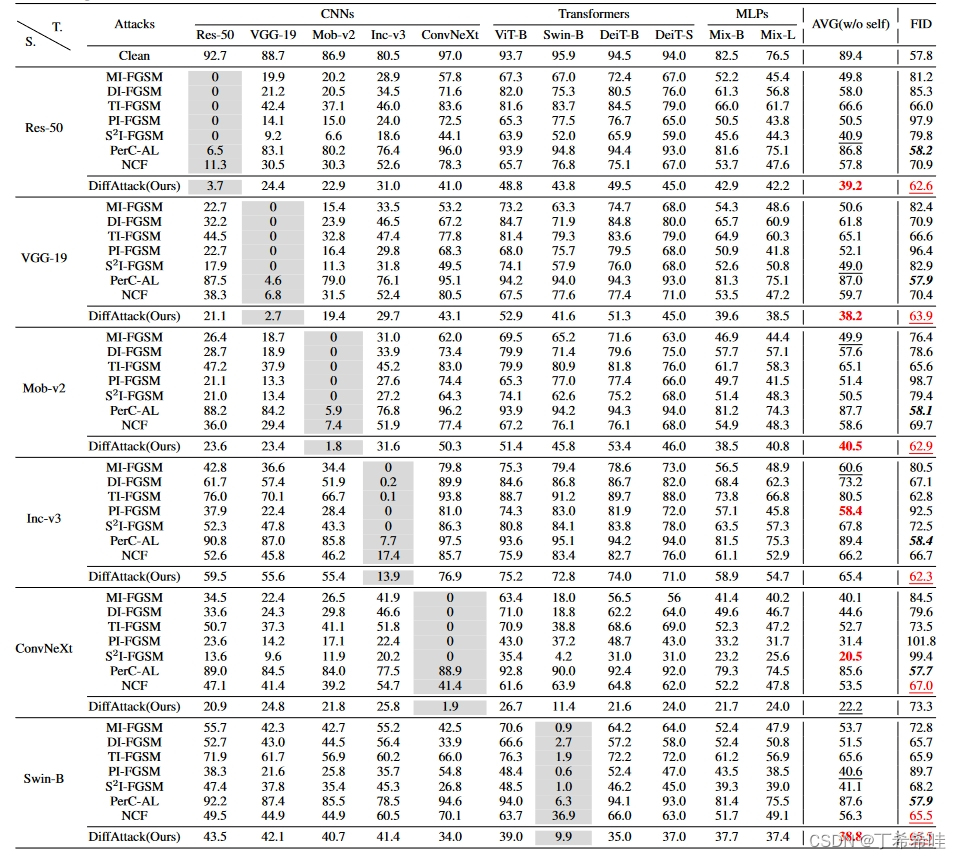
与 MI-FGSM、DI-FGSM、TI-FGSM、PIFGSM 和 S2I-FGSM 相比,文章的攻击更加难以察觉,其中存在容易被察觉的高频噪声。与NCF相比,DiffAttack在色彩空间上更加自然。对于PerC-AL来说,虽然攻击很难被察觉,但如上所述,其可转移性是最差的。因此,文章方法的优越性得到了很好的验证。

(三)防御方法的结果
从结果中可以看出,当应用一些防御措施时,文章的方法可以实现良好的鲁棒性并且优于其他方法。
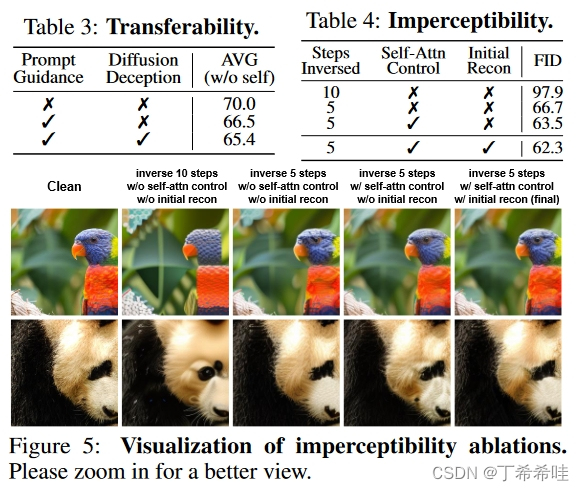
(四)消融实验
表3探究了提示引导、文章的潜在扰动方法和扩散模型中的去噪过程对于可转移性的有效性。表 4 中的结果验证了文章结构保留设计的有效性。随着反演强度和self-attention的控制,FID结果逐渐改善。图5中可视化了结构消融,可以明显地显示出视觉上的改善。可以看出,反转强度的控制有助于保留结构,并且自注意力图的使用可以确保更好的纹理。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









