







4月 得了甲流,症状不是很严重,但一直流鼻涕。回想去年到现在,我似乎只做了一点点东西,今年的压力还是蛮大的诶。好在是疫情放开了,西安这几天也逐渐暖和起来,去年的阴霾一扫而光,希望诸君能和我一起努力加油!
6月 又改了一下,之前读不懂现在懂了一些,反反复复的读一篇论文真的很有用,这篇文章写的真的是很好说!!!!!!
继上篇:【FedAvg论文笔记】&【代码复现】_fedavg代码_爽爽不会编程的博客-CSDN博客
目录
Fedprox论文笔记
首先上【FedProx】论文链接:https://arxiv.org/abs/1812.06127
1、系统异质性与统计异质性
介绍了联邦学习的关键挑战:
1、系统异质性(参与训练的设备硬件条件、网络环境、电池效率等差异导致的模型更新速度、模型稳定、模型收敛问题,和后面的设备算力相对应)
2、统计异质性(在FL过程中,各client方数据经常以Non-IID形式存在)
2、FedAvg介绍
先介绍FedAvg:在client本地增加计算量,而通信时只进行加权聚合操作。具体细节参考我的上篇博客:【FedAvg论文笔记】&【代码复现】_fedavg代码_爽爽不会编程的博客-CSDN博客
FedAvg的缺点:
1、不允许参与设备根据底层的系统执行可变的轮次(就是本地局部迭代轮次E是固定的),故算力不同的设备迭代固定E轮次的时间不同,这对后面服务区等待聚合局部模型肯定会有影响嘛。
2、某些设备在规定时间位未达到收敛会被服务器“丢弃”。
3、FedProx公式解释
- 在definition1中:
第一:加入近端项
是为了限制局部模型不能偏离全局模型过远。
第二:加入约束条件
是对用于解决FedAvg中局部迭代轮次E固定这个问题,这个不等式的目的就是不管这个设备k局部迭代了多少轮,只要满足我这个约束条件就达到聚合条件。)
再通过求解目标函数
满足不等式
的非精确解𝑤∗即可得到一个可容忍算力差异和数据异质的非精确模型𝑤∗。
- 在definition2 中:主要是细化了在第t轮,第K个设备的
此时需要优化的局部目标函数为
,求非精确解需满足的约束条件为
。
求目标函数的梯度
与约束右侧的梯度
,故约束条件可写为:
可发现
的作用,它控制着求解非精确解的精确程度,它越小代表求得的非精确解越精确。
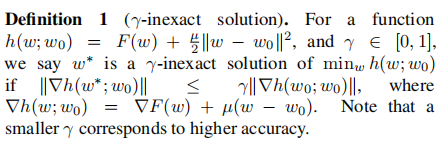
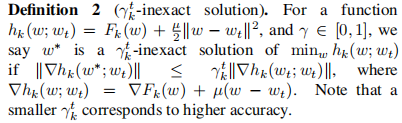
添加近端项的目的:
在局部子问题上添加一个近端项,以有效地限制变量局部更新的影响。
其实可以这么想,由于数据异质性,每个客户端client上的数据集相比于总数据集,它的样本都是不完备的,那基于这不完备的数据集训练的局部模型也是不具有代表性的,故需要添加一个正则项来调整局部目标函数,使局部模型与全局模型的差距不要那么大。
而这个正则项就是本文中所提的近端项
还有种理解就是,算力差异的设备加上本地数据集样本较少,较多轮次的局部迭代让训练的局部模型过拟合。
PROX的局部目标函数为:
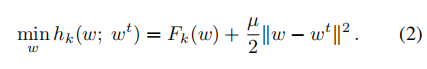
接下来就是整个FedProx的伪代码啦!
首先是随机选取K个客户端client,在第t轮第k个client为例:
首先在第t+1轮开始阶段,服务器下发第t轮的全局模型给W𝑡客户端,客户端K对目标函数:
求在约束条件
下的非精确解𝑤∗,此时有:
而在服务器聚合阶段是没有什么改动的,只是收集第t+1轮各个客户端的局部模型
,进行了平均聚合得到新一轮的全局模型而已:

4、FedProx 收敛性分析
4.1 local dissimilarity局部不相似性
引入局部不相似性来证明收敛性。

所有的局部函数相同时,B(w)=1,而在联邦学习中考虑数据的IID,故B(w)>1
在大样本极限下,所有局部函数Fk(w)对每个w收敛于相同的期望风险函数,则B (w)→1
B (w)≥1和B (w)的值越大,局部函数之间的差异性越大
随后又引出了 局部函数不相似但有界来作为局部函数收敛的假设。
5、实验部分
用到的数据集: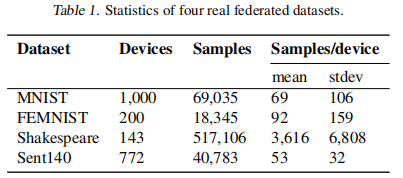
5.1系统异质性对比实验
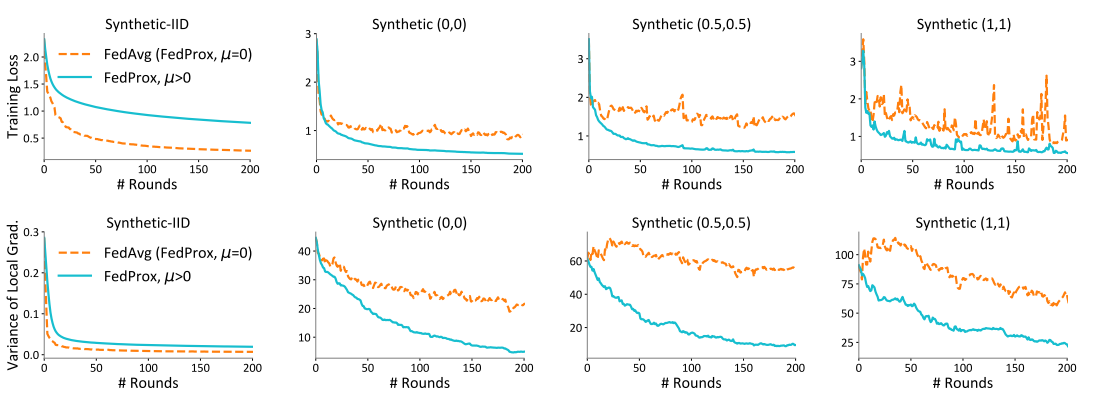
实验设定了规定的局部迭代轮次E=20,再将低于E的轮次随机的分配0%,50%,90%的客户端。(这个操作为假设系统异质性,为了对比FedAvg中未到达指定轮次会被简单粗暴的丢弃掉,而在FedProx中会通过求解非精确解使得迭代轮次非固定,进而避免被丢弃,u=0代表着没有加入近端项。)
可以看到在各个数据集上,随着没有到达E轮次的设备越来越多(从0%~90%),FedAvg算法的收敛性也变得非常不稳定。随着数据集的类别增多,数据异质性增大,FedProx收敛性能也变差,但加入近端项后𝜇≠0的FedProx的稳定性和鲁棒性有所增加。
可看到影响收敛性的关键参数为:局部迭代轮数E,是否加入近端项𝜇≠0

5.2数据异质性对比实验
规定固定的迭代轮次E,随着从左到右数据异质性的增加,FedAvg算法的收敛性越来越不稳定,但𝜇≠0的FedProx算法对收敛起到了稳定性作用。值得注意的是,在最左侧数据为独立同分布时,未加入近端项(𝜇=0)时,FedProx没有FedAvg的收敛速度快,但加入近端项(𝜇>0)时,收敛速度才有了显著提升。
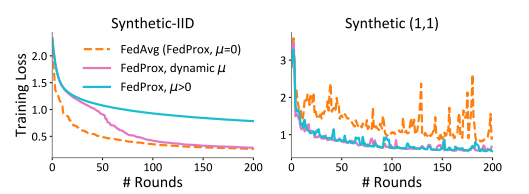
上面的实验说明这个𝜇是真的很重要!!但如何选取一个合适的𝜇呢?
文中提到:一个大的µ可能会通过迫使更新接近起点来减缓收敛速度,而一个小的µ可能不会有任何影响。
这个实验进行一个自适应的µ的选取:当损失增加时,增加0.1,当连续5轮损失减少时,µ减少0.1。图中在独立同分布iid数据集上,紫色的线(自适应µ)相较于设定固定的µ值,具有更快的收敛速度。在非独立同分不的数据集上,自适应的µ值也可以达到和固定µ一样的稳定性。
如何选择µ值?
在近端项中如何选取惩罚常数µ,启发式方法是当看到损失增加时增加µ,当看到损失减少时减少µ。
最后,作者还提了一嘴差异度量与µ之间的关系:
我们观察到增加µ导致局部函数Fk之间的差异较小,并且差异度量与训练损失是一致的。因此,差异性越小,说明收敛性越好,这可以通过适当地设置µ来实现
6、Conclusion
(1)利用r-非精确解解决了FedAvg中E固定引起部分算力不足导致“掉队”的系统异质性问题。
(2)Proximal term,利用近端项中和在Non-IID情况下局部训练模型偏离初始模型,产生差距较大的统计异质性情况。
代码
首先上链接:litian96/FedProx (github.com)
多说两句,从GitHub上面下载后,导入到pycharm中,最好看一下requirement中,项目的环境配置和需要的package。比如这个FedProx项目所依赖的环境是 文件requirements中所写的版本,如果pycharm中常用的interpret是其他版本的python和tensorflow,那肯定得在anaconda基础上再建立一个适配这个项目的虚拟环境。也可以直接在终端输入,配置。这些其实都在github中的readme文件中pip install -r requirements.txt。注意,仔细阅读readme文件对于新手来说十分重要!!!!!
我直接把适配的指令写出来:
第一步,建立虚拟环境:
conda create -n python35 python==3.5(python35是我的虚拟环境的名字)
第二步,激活虚拟环境python35
activate python35第三步,将当前目录地址切换到该项目文件夹下,输入:
pip install -r requirements.txt这儿如果报错就是pip没更新,西可以先更新pip,或者也可以用conda install。
如果下载速度慢的话,可以使用国内镜像源(清华或者其他的:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package














 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









