







 FedProto是一种针对联邦学习中客户端异构性的新框架,通过使用原型代替梯度进行聚合。每个客户端维护并更新本地原型,以接近全局原型,从而提高模型的优化和泛化能力。这种方法受到原型学习的启发,旨在整合不同数据分布的特征表示,类似于人们交换概念原型以增强知识理解。
FedProto是一种针对联邦学习中客户端异构性的新框架,通过使用原型代替梯度进行聚合。每个客户端维护并更新本地原型,以接近全局原型,从而提高模型的优化和泛化能力。这种方法受到原型学习的启发,旨在整合不同数据分布的特征表示,类似于人们交换概念原型以增强知识理解。
题目:FedProto: Federated Prototype Learning across Heterogeneous Clients
网址:http://arxiv.org/abs/2105.00243

目录
前言
文中说明,联邦学习通过计算传递梯度聚合模型时,客户端之间的异构性通常会阻碍模型优化收敛和泛化性能。故本文提出新的FedProto框架,将梯度替换成为原型,通过计算、聚合从不同客户端收集到的本地原型,然后将全局原型发送回所有客户端,以规范本地模型的训练。对每个客户机进行局部训练的目的是最小化对本地数据的分类损失,同时保持生成的本地原型足够接近相应的全局原型(损失函数最小+正则)。
什么是原型?
文中提到:“受原型学习的启发,在异构数据集上合并原型可以有效地整合来自不同数据分布的特征表示,例如,当我们谈到“狗”时,不同的人会有一个独特的“想象图片”或“原型”来代表“狗”的概念。由于不同的生活体验和视觉记忆,他们的原型可能会略有不同。在人之间交换这些概念特定的原型,使他们能够获得更多关于“狗”概念的知识。将每个FL客户端视为一个类人的智能代理,我们的方法的核心思想是交换原型,而不是共享模型参数或原始数据,这可以自然地匹配人类的知识获取行为。”
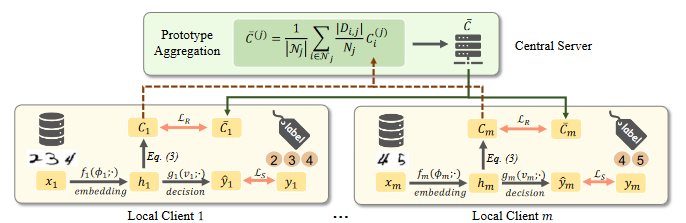
Fedproto框架
fedproto settings
在理解FedProto架构之前,需要理解一些settings:
对于异质数据集联邦学习,其服务器端需要识别全体数据集的样本类别C,C={c1,c2,...,cn},对于客户端而言,只需识别构成C子集的少数几个。
深度学习模型被分为两部分:
1、表示层:通过将样本嵌入到embedding function中将输入的实例x从原始特征空间转换到嵌入空间。第i个客户端的嵌入函数为fi( φi ),由φi参数化。记hi = fi( φi ; x)为x的嵌入。
2、决策层:分类。给定一个监督学习任务,可以通过νi参数化的函数gi( νi )生成对输入样本x的预测。Fi( φi , νi) = gi( νi )。fi ( φi ),我们用ωi表示( φi , νi)【注意这儿的gi( νi )。fi ( φi ),意思是gi( νi )是fi ( φi )的外函数,通过它对嵌入向量进行决策。】
原型:定义一个原型C ( j )来表示C中的第j类。对于第i个客户端,原型是第j类中实例的嵌入向量embedding vector的均值。
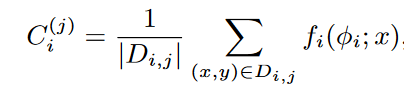
Fedproto算法
优化目标

其中Ls是监督学习的损失和Lr是一个正则化术语,它度量一个局部原型 C(j) 和相应的全局原型 C¯(j) 之间的距离(使用L2距离)。Di是客户端i的数据集大小,N是所有客户端上的实例总数,Nj是所有客户端上属于j类的实例数。
全局聚合
给定一个类j,服务器从一组具有类j的客户端接收原型Ci(j)。在原型聚合操作之后,生成j类的全局原型 C¯(j)
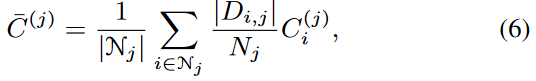
C ( j ) i表示来自客户端i的j类原型,Nj表示具有j类的客户集合。这儿可以看出,除客户端数据集与总数据集占比加权后,用具有j类的客户端数量,做了一次平均(注意区分前面一项和后面一项的Nj)
局部更新
客户端需要更新局部原型,目的是为了使不同的客户端生成一致的原型。为此目的,一个正则化项加入到局部损失函数中,使局部原型Ci(j)能够接近全局原型 C¯i(j) ,同时最小化分类误差的损失。首先,计算本地原型:
其次,计算损失:前一项监督学习下的损失函数,后一项是正则,衡量全局原型与局部原型的距离。
![]()
![]()
伪代码


















 5142
5142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









