







论文题目:《Federated Optimization in Heterogeneous Networks》
论文地址:https://arxiv.org/pdf/1812.06127.pdf
论文代码、数据地址:github.com/litian96/FedProx
Abstract
联邦学习两个关键挑战:
- 系统异质性(system heterogeneity): 网络中每个设备上的系统特性的显著可变性(通信、计算、存储能力不同,可能导致更新不同步等问题,影响训练效率)
- 统计异质性(statistical heterogeneity): 网络中每个设备上的不一致分布的数据(数量不同、质量不同、特征不同、Non-IID等,影响模型精度)
异质性:其实就是差异、差别。
为解决异质性,提出:FedProx 框架
FedProx:FedAvg 的泛化和重新参数化
证明了:
- FedProx 在一组真实的联邦数据集上比 FedAvg 更强大的收敛
- 在高度异构的环境中,相对于FedAvg,FedProx表现出明显更稳定、更准确的收敛行为,平均提高了22%的绝对测试精度。
1. Introduction
联邦学习两个关键挑战:系统异质性、统计异质性
开山之作应对异质性和高通信成本的方法:允许本地更新和低参与的优化方法 即 FedAvg 。
限制:FedAvg 虽然在异构环境取得了经验上的成功,But!没有完全解决异质性。
-
系统异质性限制:FedAvg 不允许参与设备根据其底层系统约束执行可变数量的本地工作,而是经常简单地丢弃在指定时间窗口内无法计算 E epochs 的设备。(对于系统异构,如果等待落后的局部模型会拖慢整个系统的训练速度,而抛弃落后的局部模型可能会损失全局模型的准确率,很显然 FedAvg 是后者。)
-
统计异质性限制:当数据在设备间分布不一致时,FedAvg 存在经验差异,很难从理论上进行分析,因此缺乏收敛性保证来表征其行为。(利用实验结果证明了 FedAvg 算法的效果,但没有从理论上分析其收敛速率等指标。)
提出:FedProx 一种联邦优化算法,从理论和经验上解决异质性挑战。
关键:系统和统计异质性之间存在相互作用。
问题:无论是丢弃落后者(如 FedAvg)还是天真地合并来自落后者的部分信息(如 FedProx 中的近端项设置为0),都会隐含地增加统计异质性,并可能对收敛行为产生不利影响。
缓解方案:在目标函数中添加一个近端项,提供收敛性保证。
经验证明:在高度异构的环境中,这些修改提高了异构网络中联合学习的稳定性和总体准确性,平均提高了22%的绝对测试准确性。
贡献:
- 提出框架 FedProx 。
- 推导考虑统计和系统异质性的 FedProx 框架的收敛保证。
- 在一组合成和真实联邦数据集上对 FedProx 进行全面的经验评估。
实验结果:说明和验证了理论分析,证明了在异构网络中 FedProx 优于 FedAvg 。
2. Background and Related Work
略
3. Federated Optimization:Methods
在本节中,介绍了最近的联邦学习方法(包括FedAvg)背后的关键要素,然后概述了提出的框架FedProx。
联邦学习方法用于:处理收集数据的多个设备和协调整个联邦网络的全局学习目标的中央服务器。
目标是尽量减少目标函数(全局平均损失 f ( w ) f(w) f(w)):
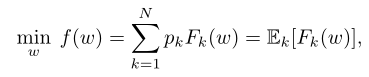
N N N 表示设备数量, p k p_k pk 表示设备 k k k 的数据样本集合( p k ≥ 0 p_k≥0 pk≥0,并且和为1), n k n_k nk 表示 p k p_k pk 的数量, F k ( w ) F_k(w) Fk(w) 表示 p k p_k pk 上的平均损失。
一般来说,本地目标函数可以衡量(在不同设备可能不同的)数据分布 D k D_k Dk 带来的本地损失,即 F k ( w ) : = E x k ∽ D k [ f k ( w ; x k ) ] F_k(w):=E_{x_k\backsim{D_k}}[f_k(w;x_k)] Fk(w):=Exk∽Dk[fk(w;xk)]。
因此,可以设置 p k = n k n p_k=\frac{n_k}{n} pk=nnk,其中 n n n 是所有设备的数据样本的总数。
在本文中,假设 F k ( w ) F_k(w) Fk(w) 是非凸的。
联邦优化减少通信的一种常见技术是:
- 在每个设备上,使用基于设备数据的局部目标函数作为全局目标函数的替代。在每次外部迭代时,选择设备的子集,并使用局部求解器来优化每个选定设备上的局部目标函数。
- 设备将其本地模型更新传送到中央服务器,中央服务器将其聚合并相应地更新全局模型。
在这种情况下实现灵活性能的关键是:可以不精确地解决每个局部目标。
这允许根据执行的局部迭代次数(与更精确的局部解相对应的附加局部迭代)来调整局部计算量与通信量。
定义 1( γ γ γ-不精确解): 对于函数 h ( w ; w 0 ) = F ( w ) + µ 2 ∣ ∣ w − w 0 ∣ ∣ 2 h(w;w0)=F(w)+\frac{µ}{2}||w− w_0||^2 h(w;w0)=F(w)+2µ∣∣w−w0∣∣2 和 γ ∈ [ 0 , 1 ] γ∈ [0,1] γ∈[0,1],如果 ∣ ∣ ∇ h ( w ∗ ; w 0 ) ∣ ∣ ≤ γ ∇ h ( w 0 ; w 0 ) ||∇h(w^∗;w_0)||≤ γ∇h(w_0;w_0) ∣∣∇h(w∗;w0)∣∣≤γ∇h(w0;w0),其中 ∇ h ( w ; w 0 ) = ∇ F ( w ) + µ ( w − w 0 ) ∇h(w;w_0)=∇F(w)+µ(w−w_0) ∇h(w;w0)=∇F(w)+µ(w−w0),则 w ∗ w^∗ w∗ 是 m i n w h ( w ; w 0 ) min_wh(w;w_0) minwh(w;w0) 的 γ γ γ-不精确解。请注意,较小的 γ γ γ 对应于较高的精度。
在分析中使用 γ γ γ-不精确性来测量每轮局部解算器的局部计算量。
由于系统条件可变,不同的设备可能在解决局部子问题方面取得不同的进展,因此,允许 γ γ γ 随设备和迭代而变化是很重要的。
3.1 FedAvg
具体分析可见:https://blog.csdn.net/weixin_43235581/article/details/127427921
在联邦平均 FedAvg 中
- 设备 k k k 处的全局目标函数的局部代替函数是: F k ( ⋅ ) F_k(·) Fk(⋅)
- 设备 k k k 处的局部求解器是:随机梯度下降 SGD
- 每个设备上使用的学习速率和局部 epochs 相同
在每一轮中选择了总设备 N N N 中的一个子集 k k k ( k < < N ) (k<<N) (k<<N),并在本地运行 SGD E 个周期,然后对结果模型的更新进行平均。

McMahan等人根据经验表明:正确调整 FedAvg 的优化超参数 至关重要。
特别是,FedAvg 中的本地 epochs 在收敛中起着重要作用:
- 一方面,执行更多的局部 epochs 允许更多的局部计算、潜在地减少通信,这可以大大提高通信受限网络中的总体收敛速度。
- 另一方面,对于不同的(异构的)局部目标函数 F k F_k Fk,更多的局部 epochs 可能导致每个设备朝向其局部目标的最优值,而不是潜在地损害收敛性甚至导致方法发散的全局目标。
此外,在具有异构系统资源的联邦网络中,将本地 epochs 的数量设置过高可能会增加设备在给定通信周期内无法完成训练的风险,因此必须退出该过程。
因此,在实践中,重要的是找到一种方法:
- 将本地 epochs 设置为高(以减少通信)。
- 同时也允许稳健的收敛。
更重要的是,作为本地数据和可用系统资源的函数,在每次迭代和每个设备上,本地 epochs 的 “最佳”设置可能会发生变化。
事实上,比强制规定固定数量的本地时间段更自然的方法是:允许时间段根据网络的特性而变化,并通过考虑这种异质性仔细合并解决方案。
3.2 拟议框架: FedProx
FedProx VS FedAvg:
同:在每一轮中选择一个设备的子集,执行本地更新,然后对这些更新进行平均以形成全局更新。
异:
-
容忍部分工作(针对系统异构)
联邦网络中的不同设备在计算硬件、网络连接和电池水平方面通常具有不同的资源限制。
因此,像 FedAvg 一样,强制每个设备执行相同数量的工作是不现实的。
在 FedProx 中:允许根据可用的系统资源在设备之间本地执行不同数量的工作,然后聚合从掉队者发送的部分解决方案(与丢弃这些设备相比)。
换言之,FedProx 没有在整个训练过程中为所有设备假设统一的 γ γ γ,而是隐式地适应不同设备和不同迭代的可变 γ γ γ。
以下正式定义了设备 k k k 在迭代 t t t 中的 γ k t γ_k^t γkt 不精确性,这是定义1的自然扩展。
定义 2:( γ k t γ_k^t γkt 不精确解): 对于函数 h k ( w ; w t ) = F ( w ) + µ 2 ∣ ∣ w − w t ∣ ∣ 2 h_k(w;w_t)=F(w)+\frac{µ}{2}||w− w_t||^2 hk(w;wt)=F(w)+2µ∣∣w−wt∣∣2 和 γ ∈ [ 0 , 1 ] γ∈ [0,1] γ∈[0,1],如果 ∣ ∣ ∇ h k ( w ∗ ; w t ) ∣ ∣ ≤ γ k t ∇ h ( w t ; w t ) ||∇h_k(w^∗;w_t)||≤ γ_k^t∇h(w_t;w_t) ∣∣∇hk(w∗;wt)∣∣≤γkt∇h(wt;wt),其中 ∇ h k ( w ; w t ) = ∇ F ( w ) + µ ( w − w t ) ∇h_k(w;w_t)=∇F(w)+µ(w−w_t) ∇hk(w;wt)=∇F(w)+µ(w−wt),就称 w ∗ w^\ast w∗是 m i n w h k ( w ; w t ) min_wh_k(w;w_t) minwhk(w;wt) 的 γ k t γ_k^t γkt 不精确解。注意,较小的 γ k t γ_k^t γkt 对应于较高的精度。
类似于定义1, γ k t γ_k^t γkt 测量在第 t t t 轮时为解决设备 k k k 上的局部子问题执行了多少局部计算。局部迭代的可变次数可以看作是 γ k t γ_k^t γkt 的代表。
-
近端项(针对数据异构)
尽管容忍跨设备执行的不均匀工作量有助于缓解系统异构性的负面影响,但过多的本地更新仍可能导致方法因底层数据异构而出现分歧。
建议:在局部子问题中添加一个近端项,以有效地限制可变局部更新的影响。
设备 k k k 使用其选择的局部解算器来近似最小化以下目标 h k h_k hk,而不是仅最小化局部函数 F k ( ⋅ ) F_k(·) Fk(⋅):
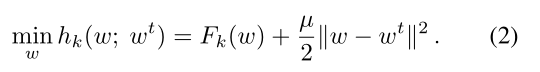
(这个近端项应该就是在 F k ( w ) F_k(w) Fk(w) 后加的那一项)
引入近端项后,设备在本地训练后得到的模型参数 w w w 将不会与初始时的服务器参数 w t w^t wt 偏离太多。
(近端项则会对偏离全局模型太多的局部模型进行惩罚)
可以看出来,当 μ = 0 μ = 0 μ=0 时,FedProx 客户端的优化目标就与 FedAvg 一致。
近端项的优点:
-
通过限制局部更新更接近初始(全局)模型来解决统计异质性问题,而无需手动设置局部 epochs 的数量。
-
允许安全地合并由系统异构性导致的可变数量的本地工作。
总结算法2中 FedProx 的步骤:


近端项的独特性:
- 用于解决联邦网络中的异构性。
- 分布式环境中解决时的创新性:
- 非IID分区数据
- 使用任何局部求解器
- 跨设备的变量不精确更新
- 每轮活动的设备子集
这些假设对于在现实的联合场景中提供这种框架的特性至关重要。
由于 FedProx 仅对 FedAvg 进行了轻量级修改,这使得能够对广泛使用的 FedAvg 方法的行为进行推理,并能够将 FedProx 轻松集成到现有的包/系统中,如TensorFlow Federated 和 LEAF(TFF)。
FedAvg = FedProx(满足以下条件时)
- µ = 0 µ=0 µ=0
- 本地解算器为 SGD
- 跨设备和更新轮次的 γ γ γ 为常数(即本地epoch的数量)
即,FedAvg 是 FedProx 的一个特例
事实上,FedProx 更加通用,因为:它允许跨设备执行部分工作,并允许在每个设备上使用任何本地(可能是非迭代)求解器。
本文主要是在原论文基础上进行标记标注,简要解析推荐这篇博客:
这是其中截图:

4. FedProx:Convergence Analysis
(注:Convergence Analysis 收敛性分析)
FedAvg 和 FedProx 本质上是随机算法:在每一轮中,只有一小部分设备被采样以执行更新,并且在每个设备上执行的更新可能不精确。
众所周知,为了使随机方法收敛到平稳点,需要减小步长。这与非随机方法(如梯度下降法)形成对比,后者可以通过采用恒定步长来找到一个稳定点。
为了分析具有恒定步长的方法的收敛行为,需要量化局部目标函数之间的相似度。这可以通过假设数据是IID来实现,即跨设备的均匀性。
不幸的是,在现实的联邦网络中,这种假设是不切实际的。
因此,在本节中,首先提出了一个专门测量局部函数之间差异的度量,然后在考虑变量γ的情况下,在此假设下分析FedProx。
4.1 局部差异性
证明收敛性:
- 通过联邦网络中设备之间的差异性度量。(就是度量局部函数之间的差异)
- 通过梯度的更简单和更严格的有界方差假设,见推论8。
定义 3(B-局部差异): 如果 E k [ ∣ ∣ k ∇ F k ( w ) ∣ ∣ 2 ] ≤ ∣ ∣ ∇ f ( w ) ∣ ∣ 2 B 2 E_k[||k∇F_k(w)||^2]≤ ||∇f(w)||^2B^2 Ek[∣∣k∇Fk(w)∣∣2]≤∣∣∇f(w)∣∣2B2,则称局部函数 F k F_k Fk 在 w w w 处是 B-局部差异的。进一步定义 B ( w ) = E k [ ∣ ∣ ∇ F k ( w ) ∣ ∣ 2 ] ∣ ∣ ∇ f ( w ) ∣ ∣ 2 B(w)=\sqrt{\frac{E_k[||∇F_k(w)||^2]}{||∇f(w)||^2}} B(w)=∣∣∇f(w)∣∣2Ek[∣∣∇Fk(w)∣∣2] ,其中 ∣ ∣ ∇ f ( w ) ∣ ∣ ≠ 0 ||∇f(w)||≠0 ∣∣∇f(w)∣∣=0。
这里, E k [ ⋅ ] E_k[·] Ek[⋅] 表示对设备 k k k 的期望, p k = n k n pk=\frac{nk}{n} pk=nnk 和 ∑ k = 1 N p k = 1 \sum_{k=1}^Np_k=1 ∑k=1Npk=1 。
定义3 可以被视为 IID 假设的概括:具有有限的差异性,同时允许统计异质性。作为健全性检查,当所有局部函数都相同时,所有 w w w 的 B ( w ) = 1 B(w)=1 B(w)=1。
然而,在联邦设置中,由于采样差异,即使假设样本为 IID,数据分布通常是异质的,且 B > 1 B>1 B>1 。
如果所有设备上的样本都是同质的,即以IID方式进行采样,则作为 m i n k n k → ∞ min_kn_k→∞ minknk→∞, 由此得出 B ( w ) → 1 B(w)→1 B(w)→1 。因为所有局部函数在大样本极限中收敛于相同的预期风险函数。因此, B ( w ) ≥ 1 B(w)≥ 1 B(w)≥1 。 B ( w ) B(w) B(w)的值越大,局部函数之间的差异性越大。
假设1(有限差异): 对于一些 ϵ > 0 ϵ>0 ϵ>0,存在 B ϵ B_ϵ Bϵ 使得对于所有点 w ∈ S ϵ c = w ∣ ∣ ∣ ∇ f ( w ) ∣ ∣ 2 > ϵ w∈S_ϵ^c={w\,|\,||∇f(w)||^2>ϵ} w∈Sϵc=w∣∣∣∇f(w)∣∣2>ϵ, B ( w ) ≤ B ϵ B(w)≤B_ϵ B(w)≤Bϵ。
对于大多数实际的机器学习问题,不需要将问题解决为高精度的平稳解,即 ϵ ϵ ϵ 通常不是很小。
事实上,解决超过某个阈值的问题甚至可能由于过度拟合而损害泛化性能。
尽管在实际的联邦学习问题中样本不是 IID,但它们仍然是从并非完全无关的分布中采样的。(否则将完全无关的数据用于训练模型是没有意义的)
因此,可以合理地假设,在整个训练过程中,局部函数之间的差异性保持有限。
4.2 FedProx 分析
(这部分还没看懂 o(╥﹏╥)o )
为了便于在下面的分析中表示,假设任何 k , t k,t k,t的 γ k t γ_k^t γkt 相同。
定理4(非凸 FedProx 收敛:B-局部差异): 让假设1成立。假设函数 F k F_k Fk 是非凸的,L-Lipschitz 光滑的,并且存在 L − > 0 L_− > 0 L−>0,这样 ∇ 2 F k ⪰ − L − I ∇^2F_k\succeq-L_-I ∇2Fk⪰−L−I,其中 µ ˉ : = µ − L − > 0 \bar{µ}:=µ−L_−>0 µˉ:=µ−L−>0。假设 w t w^t wt 不是平稳解,并且局部函数 F k F_k Fk 是 B局部差异的,即 B ( w t ) ≤ B B(w^t)≤ B B(wt)≤B。 如果选择算法2中的 µ、 K µ、K µ、K 和 γ γ γ,则:
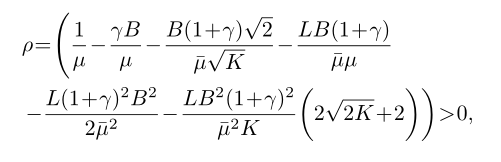
则在算法2的迭代 t t t 处,在全局目标函数中具有以下预期的减少:
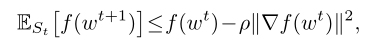
其中 S t S_t St 是在迭代 t t t 处选择的 K K K 个设备的集合, E S t E_{S_t} ESt 是关于在第 t t t 轮中选择设备 S t S_t St 的期望。
关键步骤包括对每个子问题应用 γ-不精确性概念(定义1),并使用有限差异假设,同时每轮只允许 K K K 个设备处于活动状态。
理论上要求 µ ˉ > 0 \bar{µ}>0 µˉ>0,这是 FedProx 收敛的充分但非必要条件。因此,其他一些 µ µ µ(不一定满足 µ ˉ > 0 \bar{µ}>0 µˉ>0)也可能实现收敛。
定理4使用定义3中的差异性来确定 FedProx 每次迭代时目标值充分减小。
接下来提供充分(但不是必要的)条件以确保定理4中的 ρ > 0 ρ>0 ρ>0,从而在每一轮之后都可以实现充分减小。
注5: 对于定理4中的 ρ ρ ρ 为正,需要 γ B < 1 γB<1 γB<1 和 B K < 1 \frac{B}{\sqrt{K}}<1 KB<1 。这些条件有助于量化相似度 ( B ) (B) (B) 和算法参数 ( γ , K ) (γ,K) (γ,K) 之间的权衡。
最后,可以使用上述充分减小来表征在有界差异假设(假设1)下近似平稳解集 S s = w ∣ E [ ∣ ∣ ∇ f ( w ) ∣ ∣ ] 2 ≤ ϵ Ss={w|E[||∇f(w)||]^2≤ϵ} Ss=w∣E[∣∣∇f(w)∣∣]2≤ϵ 的收敛速度。注意,这些结果适用于一般非凸 F k ( ⋅ ) F_k(·) Fk(⋅)。
·
定理6(收敛速度:FedProx): 给出一些 ϵ > 0 ϵ>0 ϵ>0,假设对于 B ≥ B ϵ 、µ、 γ B≥B_ϵ、µ、γ B≥Bϵ、µ、γ 和 K K K,定理4的假设在 FedProx 的每次迭代中都成立。此外, f ( w 0 ) − f ∗ = ∆ f(w^0)−f^∗ = ∆ f(w0)−f∗=∆。然后,在 FedProx 的 $T=O(\frac{∆}{ρ_ϵ}) $ 次迭代后,有 1 T ∑ t = 0 T − 1 E [ ∣ ∣ ∇ f ( w t ) ∣ ∣ 2 ] ≤ ϵ \frac{1}{T}\sum_{t=0}^{T-1}E[||∇f(w^t)||^2]≤ϵ T1∑t=0T−1E[∣∣∇f(wt)∣∣2]≤ϵ。
尽管迄今为止的结果对于非凸 F k ( ⋅ ) F_k(·) Fk(⋅)是成立的,但也可以根据局部目标函数来表征具有精确最小化的凸损失函数的特殊情况的收敛性(推论7)。
推论7(收敛:凸情况): 让定理4的断言成立。设 F k ( ⋅ ) F_k(·) Fk(⋅) 是凸的,并且对于任何 k , t k,t k,t, γ k t = 0 γ^t_k=0 γkt=0,即所有的局部问题都得到了精确的解决,如果 1 ≤ B ≤ 0.5 K 1≤B≤0.5\sqrt{K} 1≤B≤0.5K,那么可以选择 µ ≈ 6 L B 2 µ≈ 6LB^2 µ≈6LB2,由此得出 ρ ≈ 1 24 L B 2 ρ≈\frac{1}{24LB^2} ρ≈24LB21。
注意到在假设1中小 ϵ ϵ ϵ 转换为较大的 B ϵ B_ϵ Bϵ。推论7表明,为了使用 FedProx 解决精度越来越高的问题,需要适当增加 µ µ µ。根据经验验证 µ > 0 µ>0 µ>0 会导致更稳定的收敛。此外,在推论7中,如果我们插入 B ϵ B_ϵ Bϵ 的上界,在有界方差假设(推论10)下,实现精度 ϵ ϵ ϵ 所需的步骤数为 O ( L ∆ ϵ + L ∆ σ 2 ϵ 2 ) O(\frac{L∆}{ϵ} + \frac{L∆σ^2}{ϵ^2} ) O(ϵL∆+ϵ2L∆σ2)。 当本地函数不同时,该分析有助于描述 FedProx 和类似方法的性能。
注8(与 SGD 比较): FedProx 实现了与 SGD 相同的渐近收敛保证:在有界方差假设下,对于小 ϵ ϵ ϵ ,如果在推论10中将 B ϵ B_ϵ Bϵ 替换为其上界,并选择足够大的 µ µ µ,当子问题被精确求解且 F k ( ⋅ ) F_k(·) Fk(⋅) 是凸的时,FedProx 的迭代复杂度为 O ( L ∆ ϵ + L ∆ σ 2 ϵ 2 ) O(\frac{L∆}{ϵ} + \frac{L∆σ^2}{ϵ^2} ) O(ϵL∆+ϵ2L∆σ2),与 SGD 相同。
为了为定理6中的速率提供上下文,将其与注8中凸情况下的 SGD 进行了比较。一般来说,对 FedProx 的分析不会产生比经典分布式 SGD 更好的收敛速率(无需本地更新),尽管 FedProx 可能在每一次通信循环中在本地执行更多的工作。事实上,当数据以非相同的分布式方式生成时,本地更新方案(如 FedProx)的性能可能比分布式 SGD 差。因此,本文理论结果不一定证明 FedProx 优于分布式 SGD;相反,它们为 FedProx 收敛提供了充分的(但不是必要的)条件。
最后,前面的分析假设没有系统异质性,并对所有设备和迭代使用相同的 γ γ γ。然而,可以扩展它们,以允许 γ γ γ随设备和迭代而变化(如定义2),这对应于允许设备执行由本地系统条件确定的可变工作量。以下提供了变量 γ γ γ 的收敛结果。
推论9(收敛:变量 γ γ γ): 假设函数 F k F_k Fk 是非凸的,L-Lipschitz 光滑的,并且存在 L − > 0 L_− > 0 L−>0,这样 ∇ 2 F k ⪰ − L − I ∇^2F_k\succeq-L_-I ∇2Fk⪰−L−I,其中 µ ˉ : = µ − L − > 0 \bar{µ}:=µ−L_−>0 µˉ:=µ−L−>0。假设 w t w^t wt 不是平稳解,并且局部函数 F k F_k Fk 是 B局部差异的,即 B ( w t ) ≤ B B(w^t)≤ B B(wt)≤B。 如果选择算法2中的 µ、 K µ、K µ、K 和 γ k t γ_k^t γkt,则:
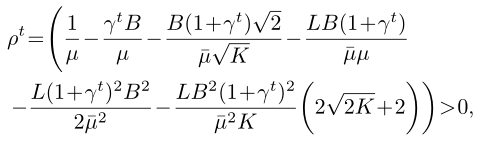
则在算法2的迭代 t t t 处,在全局目标中具有以下预期的减少:
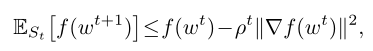
其中 S t S_t St 是在迭代 t t t 和 γ t = m a x k ∈ S t γ t t γ_t=max_{k∈S_t}γ_t^t γt=maxk∈Stγtt 处选择的 K K K 个设备的集合。
该证明可以很容易地从定理4的证明扩展,注意到 E k [ ( 1 + γ t t ) ∣ ∣ ∇ f k ( w t ) ∣ ∣ ] ≤ ( 1 + m a x k ∈ S t γ t t ) E k [ ∣ ∣ ∇ f k ( w t ) ∣ ∣ ] E_k[(1+γ_t^t)||∇f_k(w^t)||]≤(1+max_{k∈S_t}γ_t^t)E_k[||∇f_k(w^t)||] Ek[(1+γtt)∣∣∇fk(wt)∣∣]≤(1+maxk∈Stγtt)Ek[∣∣∇fk(wt)∣∣]。
5. Experiments
(这一部分也还没研究)
给出了广义 FedProx 框架的实验结果。展示了 FedProx 在面对系统异构性时耐受部分解决方案的改进性能。展示了FedProx在具有统计异质性(无论系统异质性如何)的环境中的有效性。研究了统计异质性对收敛的影响,并展示了经验收敛如何与理论有界相异假设(假设1)相关。
5.1 实验细节
在不同的任务、模型和真实世界联邦数据集上评估 FedProx。
为了更好地描述统计异质性并研究其对收敛的影响,还对一组合成数据进行了评估,这允许更精确地处理统计异质性。
通过将不同数量的本地工作分配给不同的设备来模拟系统异构性。
合成数据
数据集:遵循与 Shamir 等人(2014)类似的设置,另外在设备之间施加了异质性。
对于每个设备 k k k,根据模型 y = a r g m a x ( s o f t m a x ( W x + b ) ) , x ∈ R 10 × 60 , W ∈ R 10 × 60 , b ∈ R 10 y=argmax(softmax(W_x+b)),x∈R^{10×60},W∈R^{10×60},b∈R^{10} y=argmax(softmax(Wx+b)),x∈R10×60,W∈R10×60,b∈R10,生成样本 ( X k , Y k ) (X_k,Y_k) (Xk,Yk)。
建模: W k ∼ N ( u k , 1 ) , b k ∼ N ( u k , 1 ) , u k ∼ N ( 0 , α ) ; x k ∼ N ( v k , ∑ ) W_k∼ N(u_k,1),b_k∼ N(u_k,1),u_k∼ N(0,α);x_k∼ N(v_k,∑) Wk∼N(uk,1),bk∼N(uk,1),uk∼N(0,α);xk∼N(vk,∑),其中协方差矩阵 ∑ ∑ ∑ 与 ∑ j , j = j − 1.2 ∑_{j,j}=j^{−1.2} ∑j,j=j−1.2 是对角的。
平均向量 v k v_k vk 中的每个元素从 N ( B k , 1 ) , B k ∼ N ( 0 , β ) N(B_k,1),B_k∼N(0,β) N(Bk,1),Bk∼N(0,β) 中提取。
因此, α α α 控制本地模型之间的差异, β β β 控制每个设备的本地数据与其他设备的数据之间的差异。
改变 α , β α,β α,β 以生成三个异构分布式数据集,表示为合成 ( α , β ) (α,β) (α,β),如图2所示。
通过在所有设备上设置相同的 W , b W,b W,b 并将 X k X_k Xk 设置为遵循相同的分布来生成一个IID数据集。
目标是学习全局 W W W 和 b b b 。
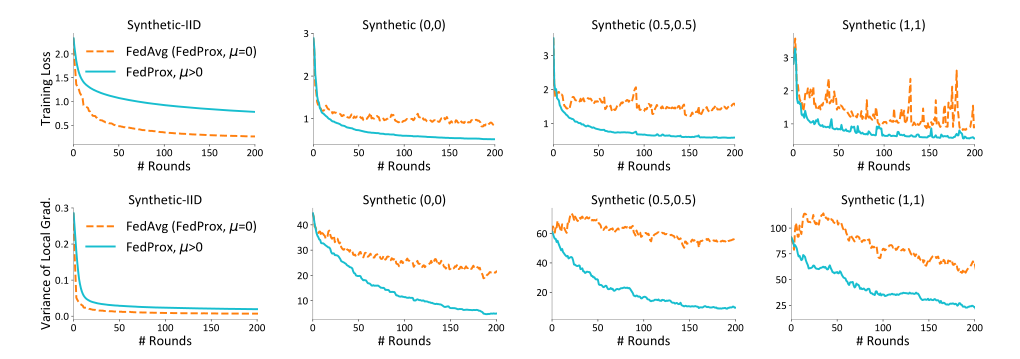
图2 通过强制每个设备运行相同数量的时间段来消除系统异构性的影响。在此设置中, µ = 0 µ=0 µ=0 的 FedProx 减少为 FedAvg。(1) 顶行:在四个统计异质性从左到右增加的合成数据集上显示了训练损失。请注意, µ = 0 µ=0 µ=0 的方法对应于 FedAvg。增加异质性会导致更差的收敛,但设置 µ > 0 µ>0 µ>0 有助于解决这一问题。(2) 下一行:显示了四个合成数据集的相应差异测量(梯度方差)。该度量捕获了统计异质性,并与训练损失相一致–差异越小表示收敛性越好。
真实数据
数据集:四个真实数据集。
使用多项式 logistic 回归研究了 MNIST 的凸分类问题。
为了强加统计异质性,将数据分布在1000个设备中,使得每个设备只有两位数的样本,并且每个设备的样本数遵循幂律。
使用相同的模型研究了更复杂的62类联邦扩展 MNIST(FEMNIST)数据集。
对于非凸设置,使用 LSTM分类器对来自 Sentiment140 的推特进行文本情感分析任务,其中每个推特帐户对应一个设备。
研究了《威廉·莎士比亚全集》数据集上的下一个角色预测任务。剧中的每个发言角色都与不同的设备相关联。
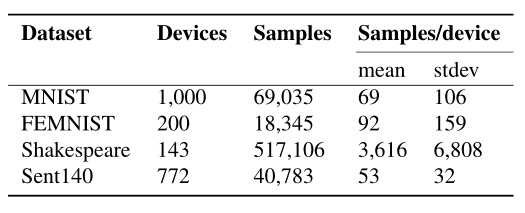
表1 四个真实联邦数据集的统计信息
实现
在 Tensorflow 中实现了 FedAvg(算法1)和 FedProx(算法2)。
为了与 FedAvg 进行公平的比较,使用 SGD 作为 FedProx 的局部解算器,并采用了与算法1和2中略有不同的设备采样方案:对设备进行均匀采样,然后用与局部数据点数量成比例的权重对更新进行平均。
本文中提出的采样方案实际上导致两种方法的性能更稳定,图12。这表明拟议框架的另一个好处。
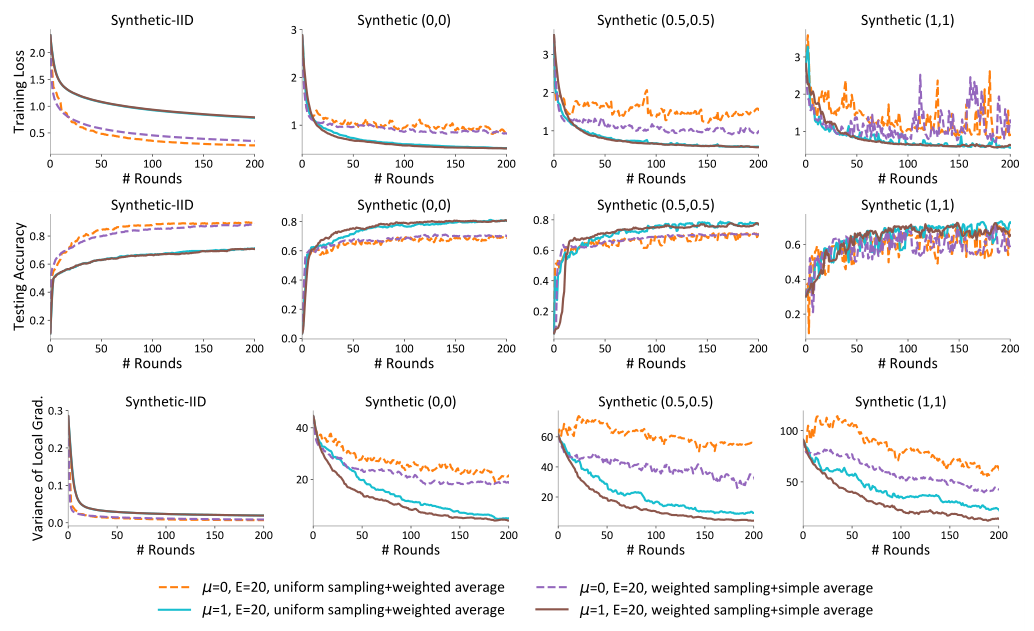
图12 两种抽样方案在训练损失、测试准确性和差异性测量方面的差异。具有与局部数据点的数量成比例的概率的采样设备,然后简单地对局部模型进行平均,其性能略优于均匀采样设备。在任一采样方案下,µ=1的设置比µ=0的设置表现出更稳定的性能。
超参数和评估指标
对于每个数据集,调整 FedAvg 上的学习率(E=1 且没有系统异质性),并对该数据集上的所有实验使用相同的学习率。
对于所有数据集上的所有实验,将所选设备的数量设置为10。对于每次比较,在所有运行中修复随机选择的设备、掉队者和小批量订单。基于全局目标 f ( w ) f(w) f(w)报告所有指标。请注意,在模拟中假设每一轮通信对应于一个特定的聚合时间戳–因此,报告结果是轮次而不是FLOP或挂钟时间。
5.2 系统异质性:容忍部分工作
为了测量允许使用 FedProx 发送部分解决方案以处理系统异构性的效果,模拟了具有不同系统异构的联邦设置,如下所述。
系统异质性模拟
假设在训练期间存在一个全局时钟,并且每个参与设备根据该时钟周期及其系统约束确定本地工作量。该指定的局部计算量对应于第 t t t 次迭代时设备 k k k 的某个隐式值 γ t k γ_t^k γtk。
在模拟中,固定了一个全局时间段 E E E,并强制一些设备在当前系统限制下执行比E时间段更少的更新。对于不同的异构设置,在每一轮,分别将 x x x 个周期(在 [ 1 , E ] [1,E] [1,E] 之间随机选择)分配给0%、50%和90%的选定设备。0%的设备执行少于 E E E 个工作周期的设置对应于没有系统异构性的环境,而发送其部分解决方案的90%的设备对应于高度异构的环境。在达到全球时钟周期后,FedAvg 将简单地减少这0%、50%和90%的掉队者,FedProx 将合并这些设备的部分更新。
在图1中,将 E E E 设置为20,并研究了从其他丢弃的设备中聚集部分功的效果。这里的合成数据集取自图2中的合成(1,1)。在所有数据集上,系统异质性对收敛有负面影响,而更大的异质性会导致更差的收敛(FedAvg)。与丢弃更受限制的设备(FedAvg)相比,合并可变工作量(FedProx,µ=0)是有益的,并导致更稳定和更快的收敛。
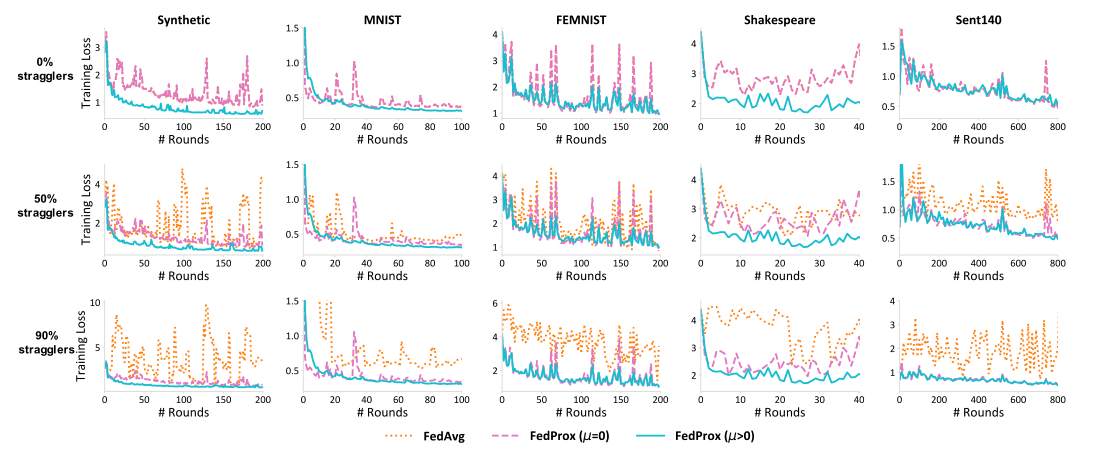
图1 与 FedAvg 相比,FedProx 在异构网络中实现了显著的收敛性改进。通过强制0%、50%和90%的设备成为掉队者(FedAvg放弃)来模拟不同级别的系统异构性。(1) 比较 FedAvg 和 FedProx(µ=0),发现允许执行不同数量的工作有助于在存在系统异构性的情况下实现收敛。(2) 将 FedProx(µ=0)与 FedProx(µ>0)进行比较,显示了增加近端术语的好处。µ>0 的 FedProx 可实现更稳定的收敛,并使发散的方法能够收敛,无论是在存在系统异质性(50%和90%掉队)还是在没有系统异质性的情况下(0%掉队)。请注意,µ=0 且无系统异构性(无掉队)的 FedProx 对应于 FedAvg。
在FedProx中设置 µ>0 可以进一步提高收敛性,正如在第5.3节中所讨论的那样。
还研究了两种不那么异构的设置。
首先,通过将 E E E 设置为1来限制所有设备的能力(即,所有设备最多运行一个本地 epoch),并以类似的方式强加系统异构性。在附录中的图9中显示了训练损失,在图10中显示了测试准确性。即使在这些设置中,与FedAvg相比,允许部分工作也可以提高收敛性。
其次,使用相同分布的合成数据集(合成IID)探索了一个没有任何统计异质性的环境。在该IID设置中,FedAvg在设备故障下相当稳健,容忍可变的本地工作量可能不会导致重大改进。这是严格研究统计异质性对联邦学习新方法的影响的另一个动机,因为仅仅依靠IID数据(在实践中不太可能发生的设置)可能无法讲述完整的故事。
5.3 统计异质性:近似项
为了更好地理解近端项在异质性环境中是如何有益的,首先表明,随着统计异质性的增加,收敛性可能会变得更差。
统计异质性的影响
在图2(第一行)中,使用四个合成数据集研究统计异质性如何影响收敛,而不存在系统异质性(将E固定为20)。从左到右,随着数据变得更加异构,µ=0的FedProx(即FedAvg)的收敛性变得更差。尽管它可能会减缓IID数据的收敛速度,但设置µ>0在异构设置中特别有用。这表明FedProx中引入的修改后的子问题可以使具有不同统计异质性的实际联邦设置受益。对于完美的IID数据,一些试探法(如如果损失继续减少,则减少µ)可能有助于避免收敛减速。
µ > 0 µ>0 µ>0 的影响
FedProx影响性能的关键参数是本地工作量(由本地时间段数E参数化)和以µ为单位的近端项。
直觉上,大E可能导致局部模型偏离初始起点太远,从而导致潜在的分歧。因此,要处理FedAvg与非IID数据的分歧或不稳定性,仔细调整E是有帮助的。然而,E受到设备上底层系统环境的限制,很难为所有设备确定合适的统一E。或者,允许设备特定的E(变量γ)并调整最佳µ(一个可以被视为E的重新参数化的参数)以防止发散并提高方法的稳定性是有益的。适当的µ可以通过将迭代约束为更接近全局模型的迭代来限制迭代的轨迹,从而合并可变量的更新并保证收敛(定理6)。
在图1中显示了FedProx(µ>0)中近端项的影响。对于每个实验,比较了µ=0的FedProx和µ最佳的FedProx之间的结果。对于所有数据集,观察到适当的µ可以增加不稳定方法的稳定性,并可以迫使发散方法收敛。当存在系统异质性(50%和90%落后者)和不存在系统异质(0%落后者)时,这两种情况都适用。µ>0在大多数情况下也会提高精度。特别是,在高度异构的环境中,FedProx相对于FedAvg平均提高了22%的绝对测试精度(90%的掉队)(见图7)。
选择µ
一个自然的问题是确定如何在近端设置惩罚常数µ。较大的µ可能会迫使更新接近起点,从而降低收敛速度,而较小的µ则不会产生任何差异。在所有实验中,从有限的候选集{0.001,0.01,0.1,1}中调整最佳µ。对于图1中的五个联邦数据集,最佳µ值分别为1、1、1,0.001和0.01。虽然自动调整µ很难直接从本文理论结果实例化,但在实践中,注意到µ可以根据模型的当前性能自适应选择。例如,一种简单的启发式方法是,当损失增加时增加µ,当损失减少时减少µ。在图3中,使用两个合成数据集证明了这种启发式方法的有效性。请注意,从与本文方法相反的初始µ值开始。
相异性测量和差异
最后,在图2中(底部一行),证明了定义3中的B局部相异性度量捕获了数据集的异质性,因此是性能的适当代表。特别地,跟踪每个设备上梯度的变化,Ek[k∇Fk(宽)−∇f(w)k2],其下界为B?(见有界方差等价推论10)。经验上,观察到,增加µ导致局部函数Fk之间的差异较小,并且差异度量与训练损失一致。因此,较小的差异性表示更好的收敛性,这可以通过适当设置µ来实现。
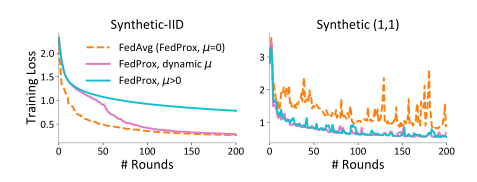
图3 不同程度的数据异构性对 FedAvg 和 FedProx 的影响
6. Conclusion
在这项工作中,提出了优化框架 FedProx,用于解决联邦网络中固有的系统和统计异构性。
FedProx 允许跨设备在本地执行不同数量的工作,并依靠近端项来帮助稳定方法。
在设备不同性假设下为 FedProx 在实际的联邦设置中提供了收敛保证,同时也考虑了诸如掉队等实际问题。
对一组联邦数据集的实证评估验证了理论分析,并证明 FedProx 框架可以显著改善现实异构网络中联邦学习的收敛行为。

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









