







一、作品详细简介
1.1附件文件夹程序代码截图

全部完整源代码,请在个人首页置顶文章查看:
学行库小秘_CSDN博客![]() https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.53431.2各文件夹说明
https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.53431.2各文件夹说明
1.2.1 main.m主函数文件
这段代码是一个用于回归任务的MATLAB脚本。以下是对代码的概括解释:
1.清空环境变量和图窗,以便开始一个干净的工作环境。
2.从名为“数据集.xlsx”的Excel文件中导入数据。
3.将数据划分为训练集和测试集。数据共有103个样本,随机打乱样本顺序,并将前80个样本作为训练集,剩下的样本作为测试集。
4.对数据进行归一化处理,将输入和输出数据映射到0和1之间的范围。
5.调整数据维度,将数据转置,以适应模型的要求。
6.使用决策树(集成学习)进行模型训练。设置100棵决策树,每棵树最小叶子节点数为5,同时开启了误差图和特征重要性计算。
7.使用训练好的模型进行仿真测试,对训练集和测试集进行预测。
8.将预测结果进行反归一化,恢复为原始数据的范围。
9.计算均方根误差(RMSE)来评估预测结果与真实值之间的差异。
10.绘制训练集和测试集的真实值与预测值的对比图,以及决策树数目与误差之间的关系图和特征重要性图。
11.计算评估指标:R2(决定系数)、MAE(平均绝对误差)和MBE(平均偏差误差)来进一步评估模型的性能。
12.绘制训练集和测试集真实值与预测值之间的散点图,以直观地展示模型的预测效果。
总体来说,这段代码实现了一个回归模型的训练、评估和可视化过程。它使用了决策树随机森林方法,利用随机抽样和特征重要性来提高模型的泛化能力和解释性。
图1 main.m主函数文件部分代码
1.2.2 数据集文件
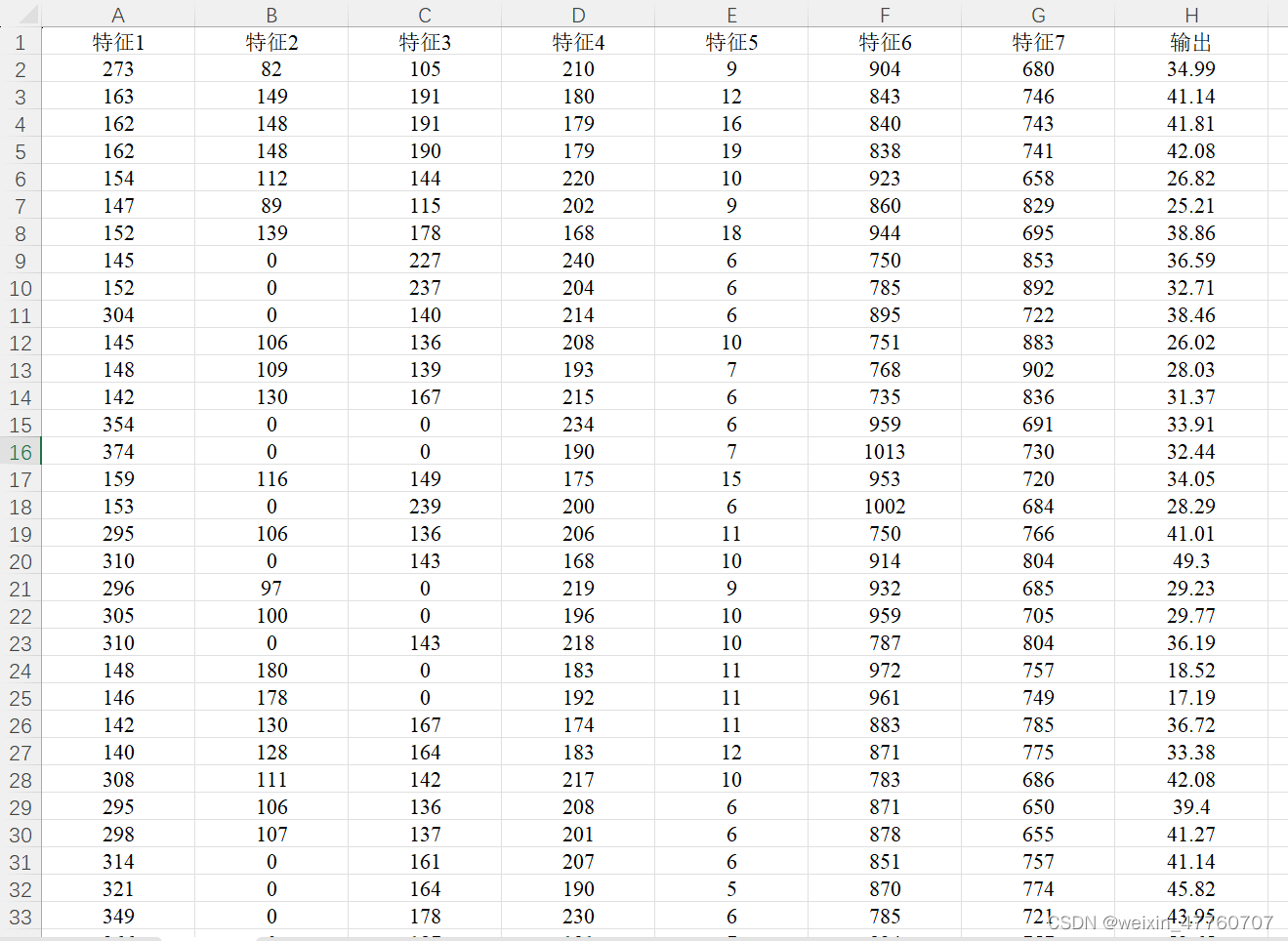
数据集为Excel数据csv格式文件,可以方便地直接替换为自己的数据运行程序。原始数据文件包含7列特征列数据和1列输出标签列数据,一共包含103条样本数据,具体如图所示。
二、代码运行结果展示
这个基于RF随机森林机器学习算法的回归预测模型MATLAB代码实现了一个回归任务的决策树集成模型。
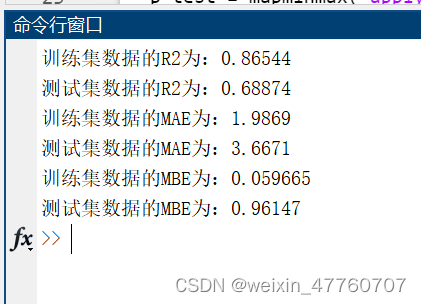
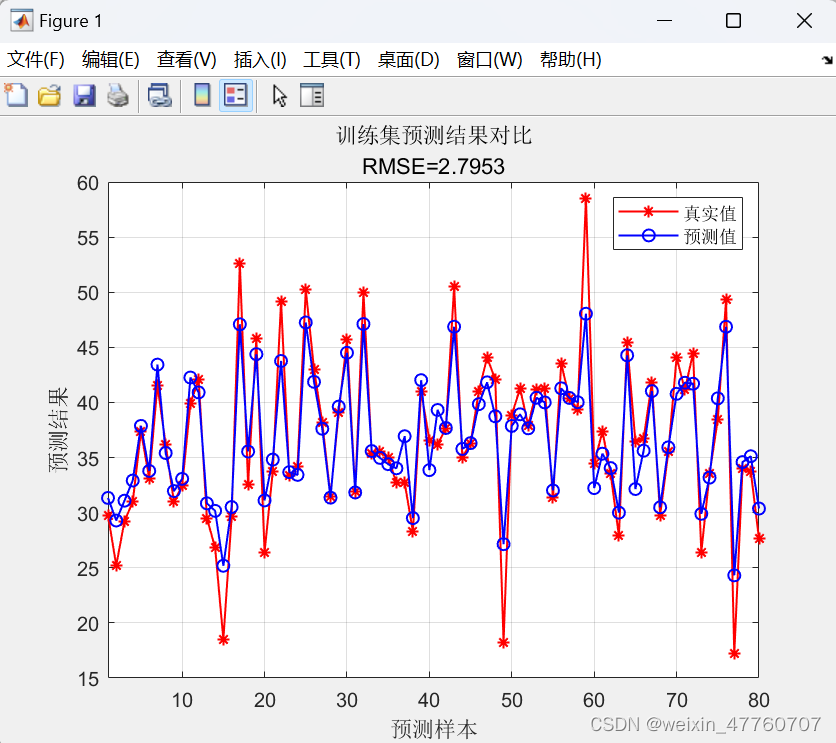
首先从Excel文件中导入数据集,并将数据划分为训练集和测试集。然后,对数据进行归一化处理并转置以适应模型的要求。接下来,使用决策树随机森林算法训练模型,并计算特征重要性。对训练集和测试集进行预测,并反归一化预测结果。最后,通过计算均方根误差、决定系数、平均绝对误差和平均偏差误差等指标来评估模型性能,并绘制真实值与预测值之间的散点图和其他评估图表,以直观地展示模型的预测效果和特征重要性。具体结果如下图所示,包括误差曲线,特征重要性,训练集、测试集的预测值和真实值的预测结果对比图,模型预测结果的散点图等。

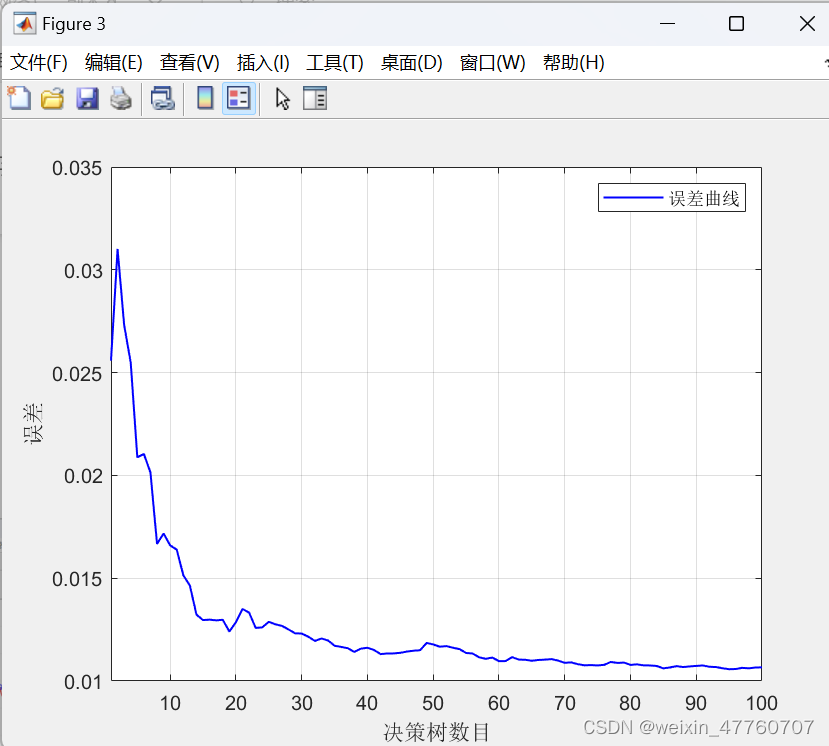
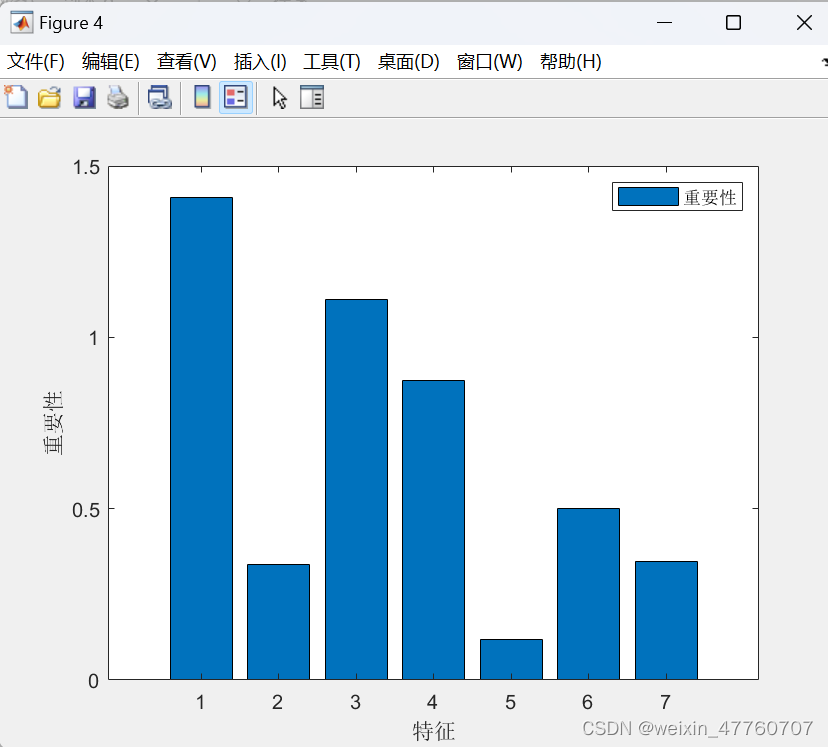
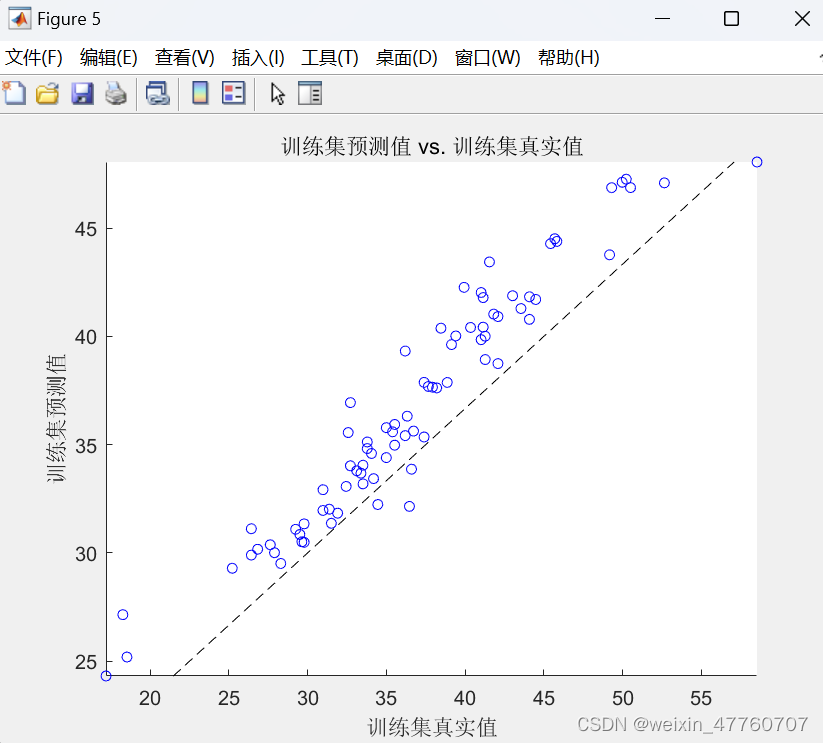

注意事项:
1.程序运行软件推荐Matlab 2018B版本及以上;
2.所有程序都经过验证,保证程序可以运行。此外程序包含简要注释,便于理解。
3. 代码包含详细的文件说明,以及对每个程序文件的功能注释,说明详细清楚。
4.Excel数据,可直接修改数据,替换数据后直接运行即可。
5.如果不会运行,可以帮忙远程运行原始程序以及讲解和其它售后。















 1364
1364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









