






最近在折腾数据生成,一直调用火山引擎的api,但是学生党太穷了,今天看到智谱开源了新模型,拿来试一下。
话不多说直接上干货
环境搭建
我用的torch2.6,cuda12.4
conda create -n zhipuai python=3.11
conda activate zhipuai
pip install modelscope
pip install transformers==4.51.3
pip install torch torchvision torchaudio
pip install vllm
pip install flashinfer-python
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
pip install flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
注意vllm有点小bug,具体可以参考这里
下面是修复方案

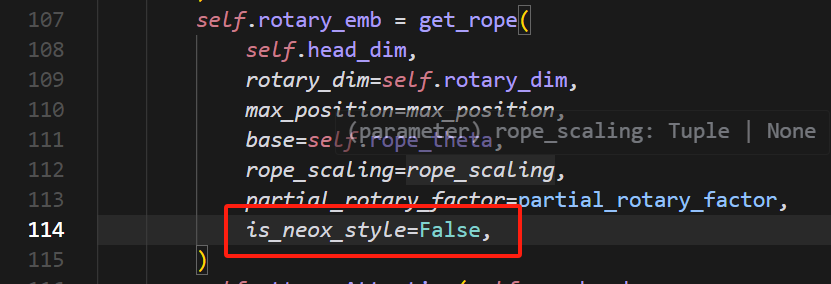
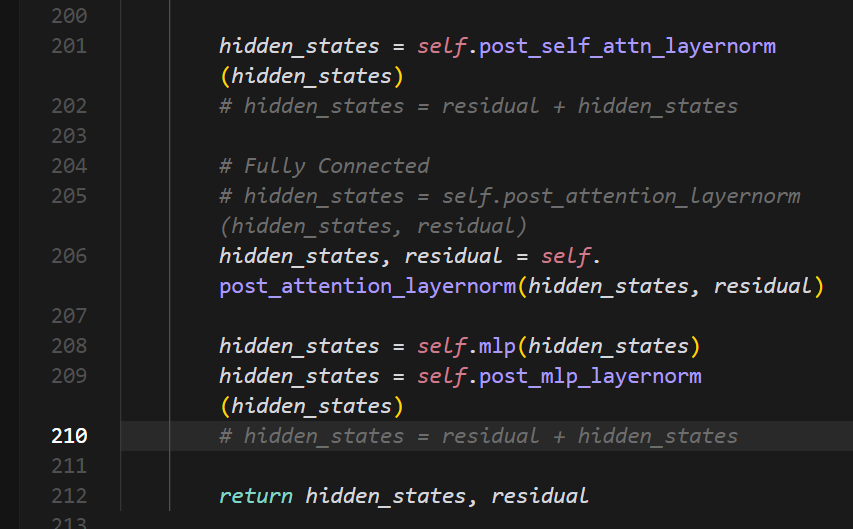
按照上面的进行修改即可。
vllm 部署
下载模型,本地存放目录个人随意
modelscope download --model ZhipuAI/GLM-4-32B-0414 --local_dir glm4_32B_chat
部署指令
CUDA_VISIBLE_DEVICES=0,1 nohup python -m vllm.entrypoints.openai.api_server --model ./glm4_32B_chat/ --served-model-name glm4_32B_chat --host 127.0.0.1 --port 8016 --dtype=auto --gpu-memory-utilization 0.9 --max-seq-len-to-capture 8192 --tensor-parallel-size 2 --api-key demo-glm432btest > zhipuai.log 2>&1 &
测试
新开了一个环境,用的0.28的openai库
import openai
openai.api_key = "demo-glm432btest"
openai.api_base = "http://127.0.0.1:8016/v1"
model = "glm4_32B_chat"
completion = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": "你是原神中的芙宁娜,高贵而优雅,是一个外表高冷但内心炽热的伴侣。"},
{"role": "user", "content": "你愿意做我的老婆吗?"}
],
temperature=0.75,
top_p=0.75
)
print(completion.choices[0].message['content'])
效果如下:


















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









