注:该系列文章为强化学习相关论文的阅读笔记,欢迎指正!
论文题目:《深度强化学习中稀疏奖励问题研究综述》
文章目录
1. 论文介绍
2. 论文结构
3. 研究背景
3.1 解决稀疏奖励的必要性
1)解决稀疏奖励问题有助于提高样本的利用效率。
2)将强化学习算法大规模地应用于实际问题是未来努力的方向,但目前的强化学习的一些应用需要较高的代价(如围棋系统)。
4. 稀疏奖励问题的解决方法
4.1 奖励设计与学习
4.2 经验回放机制
4.3 探索与利用
4.3.1 基于计数的方法
4.3.2 基于内在激励的方法
4.4 多目标任务
4.5 辅助任务
4.5.1.“课程式”强化学习
4.5.2 直接在原任务的基础上添加并行的辅助任务
总结
1. 论文介绍
该论文是中国联通网络技术研究院杨惟轶、哈尔滨工业大学计算机科学与技术学院白辰甲等,于2019年发表在《计算机科学》期刊上的论文。

该论文针对深度强化学习(DRL)在解决任务中面临的核心问题 — 奖励稀疏问题,进行了解决方法上的研究综述,包括奖励设计与学习、经验回放机制、探索与利用、多目标学习和辅助任务等。
2. 论文结构
该篇论文首先介绍深度强化学习的理论基础和核心算法,然后对稀疏奖励问题的解决方法进行阐述,最后对相关研究 进行总结和展望。全文总体结构如下图1所示。
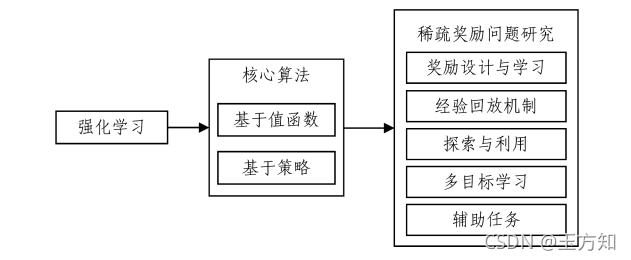
图 1 论文总体框架
3. 研究背景
稀疏奖励问题是
DRL在解决实际任务中面临的核心问题,在监督学习中,监督信号由训练数据提供。在强化学习中,奖励承担了监督信号的作用,智能体依据奖励进行策略优化。而稀疏奖励问题的存在会导致强化学习算法迭代缓慢,甚至难以收敛。因此,研究如何解决稀疏奖励带来的负面影响,并对稀疏奖励环境下的强化学习算法进行研究,对于提升 DRL的学习速度和策略水平有重要作用。
3.1 解决稀疏奖励的必要性
1)解决稀疏奖励问题有助于提高样本的利用效率。
强化学习算法中代价较高的往往不是训练过程,
而是样本获取过程。样本的获取需要智能体与环境进行交互,
而交互的代价较高,这一代价不仅体现在时间上,
还体现在安全性
、
可控性
、
可恢
复性等诸多方面。
特别是在真实任务
(
如机器人
、
自动驾驶)
中
,
与环境交互有时需要真实的硬件设备,
交互过程耗时且具有一定的危险性。
如果交互样本无法获得奖励,
那么该样本对于算法训练的贡献将很小。
因此,
如果能在一定程度上解决稀疏奖励问题,
就能加速学习过程,
减少智能体与环
境的交互次数。
2)将强化学习算法大规模地应用于实际问题是未来努力的方向,但目前的强化学习的一些应用需要较高的代价(如围棋系统)。
导致高昂学习成本的一个重要原因就是稀疏奖励问题。
由于奖励的稀疏性,
智能体需要频繁地与环境交互,
经过反复的尝试才能发现如何获取奖励。
因此,
对稀疏奖励问题及其解决方法的研究,
能够推动强化学习算法在实际问题中的广泛应用。
注:大家应该对深度强化学习的理论基础和核心算法有一定的了解,这里不再赘述,感兴趣的可以参考原文。
4. 稀疏奖励问题的解决方法
前言:如果智能体在与环境的交互过程中没有获得奖励,那么该样本在基于值函数和基于策略梯度的损失中的贡献会很小。直接使用稀疏奖励样本进行学习有时不仅无法提升策略,还会带来负面影响,导致神经网络的训练发散。
4.1 奖励设计与学习
1)人为设计的 “密集”奖励。
以机械臂
“
开门
”的任务为例,
原始的稀疏奖励机制
为:若机械臂把门打开,则给予“+1”奖励,其余情况下均给予“0”奖励。
人为设计的奖励可以
为:在机械臂未碰到门把手时,将机械臂与门把手距离的倒数作为奖励;当机械臂接触门把手时,给予“+0.1”奖励;当机械臂转动门把手时,给予“+ 0.5”奖励;当机械臂完成开门时,给予“+1”奖励。
但是人为设计奖励的方式往往具有一下局限性:第一,与任务密切相关,奖励设计的方法不具有通用性。第二,有时会给学习带来错误的引导,使最终策略收敛到局部最优,给学习带来负面影响。如将吸尘器的奖励设定为“吸收灰尘”时,吸尘器会通过先“喷射灰尘”再“吸收灰尘”来获得奖励。第三,不合理的奖励设计还会使智能体在探索环境中存在安全隐患。
2) 针对人为设计奖励中存在的问题,研究人员提出了不同的解决方法。
如 Ng 等[1]提出了从最优交互序列中学习奖励函数,此类方法称为“逆强化学习” — 视为模仿学习(ImitationLearning)的分支。该类方法中最优交互序列由人类专家给出,逆强化学习通过大量专家决策数据在马尔可夫决策过程中逆向求解环境奖励函数,其基本原则是寻找一个或多个奖励函数来描述专家决策行为。有3种奖励函数的设计形式可以实现求解过程,包括基于最大间隔、基于确定基函数组合以及基于参数化表示。其中,基于参数化的表示方式适用于深度神经网络。基于逆强化学习 Finn 等[2]提出了在深度神经网络表示的奖励函数下逆强化学习中的代价函数。Hadfield 等[3]提出了近似求解奖励函数的方法,能够避免奖励函数的负面影响.ChrisGtiano 等[4]提出根据人类偏好来学习奖励函数,通过选择轨迹来获取人类偏好,使用监督学习的方法来逼近人类偏好。
[1] NG A Y,RUSSELL S J.Algorithms for inverse reinforcement learning[C//ICML.2000,1:2.
[2]FINN C,LEVINE S,ABBEEL P.Guided cost learning:Deep inverse optimal control via policy optimization[C]//International Conference on Machine Learning.2016:49-58.
[3]HADFIELD-MENELL D,MILLI S,ABBEEL P,et al. Inverse reward design[C]//Advances in neural information processing systems.2017:6765-6774.
[4]CHRISTIANO P F,LEIKEJ,BROWN T,et al.Deep reinforce ment learning from human preferences[C]//Advances in Neural Information Processing Systems.2017:4299-4307.
4.2 经验回放机制
经验回放机制适用于离线策略的学习算法。
在深度
Q
网络训练中,
智能体与环境交互产生的样本会存储在经验池中,在算法训练时进行采样。
在稀疏奖励条件下,
经验池中大多数样本没有获得奖励,
具有较小的
TD-error。
注:TD为时间差分,后续的博客会对强化学习基础进行讲解。
为了提高样本的利用效率,Schaul 等[1]
提出了优先经验回放法
(Prioritized Experience Replay,PER),优先采样经验池中有较大 TD-error 的样本,这些样本能在训练中起到更大的作用。样本的优先级定义为:
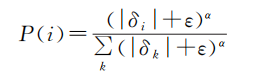
其中, 代表样本 i
的
TD-error,
α
和
ε
为常数,
分母起到规约作用。同时,
PER
算法采样时,
在优先级的基础上引入随机性,使样本被抽取的概率与优先级成正比,
同时所有样本都有机会被采样,有利于增加样本的多样性。
此外,
优先级的引入相比于均匀抽样改变了样本的分布,
引入了偏差。
PER
算法使用重要性采样权重对偏差进行补偿。在计算损失函数梯度时,需要在原有梯度的基础上乘以重要性采样权重,按补偿后的梯度进行更新。优先经验回放的主要过程如图 2 所示。
代表样本 i
的
TD-error,
α
和
ε
为常数,
分母起到规约作用。同时,
PER
算法采样时,
在优先级的基础上引入随机性,使样本被抽取的概率与优先级成正比,
同时所有样本都有机会被采样,有利于增加样本的多样性。
此外,
优先级的引入相比于均匀抽样改变了样本的分布,
引入了偏差。
PER
算法使用重要性采样权重对偏差进行补偿。在计算损失函数梯度时,需要在原有梯度的基础上乘以重要性采样权重,按补偿后的梯度进行更新。优先经验回放的主要过程如图 2 所示。
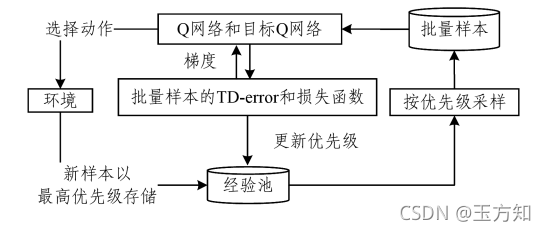
图 2 优先经验回放的原理
该方法与深度
Q
学习的结合
,
显著减少了智能体与环境交互的次数,
提高了智能体的最优得分,
在一定程度上解决了 稀疏奖励问题.
优先经验回放法具有高度的灵活性,可与离策略 的 DRL 算 法 进行广泛结合。Hou 等[2]将该方法与 DDPG 算法结合,提高了确定性策略梯度法在仿真机器人控制中的数据利用效率。
[1]SCHAUL T,QUAN J,ANTONOGLOU I,et al.Prioritized experience replay[J].arXiv:1511.05952,2015.
[2]HOU Y,LIU L,WEI Q,et al.A novel DDPG method with prioritized experience replay[C]//2017 IEEE International Conference on Systems,Man,and Cybernetics (SMC).IEEE,2017:316-321.
4.3 探索与利用
探索与利用是强化学习中的基本问题。
智能体在决策时面临两种选择:
利用当前已有的知识选择最优动作,
或探索非最优但具有不确定性的动作来获取更多信息。
在序列决策中,
智能体可能需要牺牲当前利益来选择非最优动作,
期望能够获得更大的长期回报。
在传统强化学习研究中,
探索与利用方法主要包括 ε-
贪心、
概率匹配、
UCB
、Thompson
采样、
贝叶斯探索
等。
这些方法一般在多臂赌博机中进行测试,
不适用于大规模连续状态空间的
DRL
任务。
在
DRL
领域中使用的探索与利用方法主要包括两类:
基于计数的方法和基于内在激励的方法
。其
目的是构造虚拟奖励,用于和真实奖励函数共同学习。由于真实的奖励是稀疏的,使用虚拟奖励可以加快学习的进程。
4.3.1 基于计数的方法
基于计数(CountGbased)的方法使用状态的访问频率来衡量状态的不确定性,访问次数越少的状态具有越强的新颖性。然而,DRL任务中的 状 态 一 般由图像或位姿参数来表示,很难遇到两个完全相同的状态,因此不能简单地用表格式的方法来进行计数。
针对上述问题,Bellemare等[1]提出了一种虚拟计数的方式,使用状态空间上的概率生成模型来衡量状态出现的频率,使用信息增益将状态出现的频率转化为虚拟计数,在决策时将虚拟计数作为额外的内在奖励。假设智能体当前的状态为 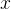 ,智能体之前遇到的状态为
,智能体之前遇到的状态为 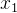 ,
, 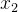 , ... ,
, ... , 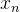 ,概率密度模型记为
,概率密度模型记为 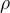 ,则信息增益(PG)定义为概率模型在使用 训练之前对 的概率
,则信息增益(PG)定义为概率模型在使用 训练之前对 的概率  与使用 训练之后对 的概率
与使用 训练之后对 的概率  之差,表示为:
之差,表示为:

如果增益较大
,
表明该状态更加新颖。
在此基础上,
定义虚拟计数为:
虚拟奖励定义为:
在学习中
,
使用原始奖励和  之和进行训练。
之和进行训练。
[1]BELLEMARE M,SRINIVASAN S,OSTROVSKI G,et al.Unifying count-based exploration and intrinsic motivation[C]//Advances in Neural Information Processing Systems.2016:1471-1479.
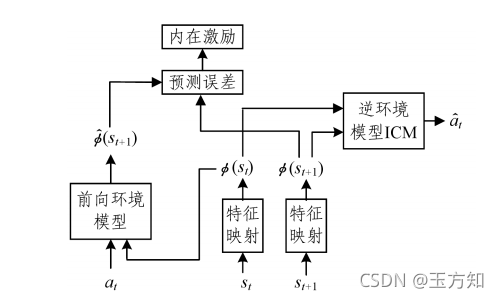
4.3.2 基于内在激励的方法
基于内在激励的方法主要包括变分信息最大化(VIME)、基于好奇心的探索等
.VIME[1]使用
贝叶斯神经网络来构建环境模型,
使用模型的后验概率分布来衡量信息增益,智能体倾向于探索不确定的环境成分。Stadie等[2]利用在训练过程中构建的环境模型
M 来评估状态的新颖程度。具体地,输入状态
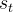
和动作
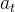
来预测状态

。预测误差的计算过程为:
[1] HOUTHOOFT R,CHEN X,DUAN Y,et al.Vime: Variational information maximizing exploration[C]// Advances in Neural Information Processing Systems.2016:1109-1117.
[2] STADIE B C,LEVINE S,ABBEEL P. Incentivizing exploration in reinforcement learning with deep predictivemodels[J].arXiv: 1507.00814,2015.
[3] PATHAK D,AGRAWAL P,EFROS A A,et al. Curiosity-dri-ven Exploration by Self-supervised Prediction[C]//International Conference on Machine Learning.2017:2778-2787.
4.4 多目标任务
强化学习算法中学习的策略π(s)是状态的函数,
根据该策略可以达到单一的目标。例如,在某个机械臂任务中,机械臂须将末端放置到指定的位置获得奖励。如果末端到达该位置,则奖励为+1,否则为0,这是一个单目标的学习任务。但由于奖励的稀疏性,机械臂从初始化策略开始,需要不断探索,直到到达指定位置才能获得奖励。Andrychowicz 等[1]提出了一种多目标学习[2]算法,智能体可以从已经到达的位置来获得奖励。该算法在训练中使用虚拟目标替代原始目标,使智能体即使在训练初期也能很快获得奖励,极大地加速了学习过程。
在多目标学习的框架下
,
需要扩展值函数  和
和 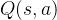 的表达能力,
使 其 成 为 目 标 g
的 函 数。
Sutton
等
[3]
提出了 Horde 结构,
该结构将智能体分解为多个子智能体,
每个智能体分别使用不同的奖励函数来学习如何完成一个单独的目标。Schaul
等
[4]
将
Horde
中多个智能体的策略合并为一个整体的策略,
提出了基于目标的值函数,
扩展了值函数的表达能力。
基于目标的值函数表示为
的表达能力,
使 其 成 为 目 标 g
的 函 数。
Sutton
等
[3]
提出了 Horde 结构,
该结构将智能体分解为多个子智能体,
每个智能体分别使用不同的奖励函数来学习如何完成一个单独的目标。Schaul
等
[4]
将
Horde
中多个智能体的策略合并为一个整体的策略,
提出了基于目标的值函数,
扩展了值函数的表达能力。
基于目标的值函数表示为  和
和  ,
奖励函数表示为
,
奖励函数表示为  ,
策略表示为
,
策略表示为  。
在稀疏奖励条件下,
奖励函数定义为下一个时间步的状态是否到达指定目标,
如果到达则奖励为1,
否则奖励为
0,
如下式所示
:
。
在稀疏奖励条件下,
奖励函数定义为下一个时间步的状态是否到达指定目标,
如果到达则奖励为1,
否则奖励为
0,
如下式所示
:
[1] PLAPPERT M,ANDRYCHOWICZ M,RAY A,et al.Multigoal reinforcement learning:Challenging robotics environments and requestforresearch[J].arXiv:1802. 09464,2018.
[2] ANDRYCHOWICZ M,WOLSKI F,RAY A,et al.Hindsight experience replay[C]//Advancesin Neural Information Processing Systems.2017:5084-5058.
[3] SUTTONR S,MODAYIL J,DELP M,et al. Horde : A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction[C]//The10 th International Conference on Autonomous Agents and Multiagent Systems.2011 : 761-768.
[4] SCHAUL T,HORGAN D,GREGOR K,et al.Universal value function approximators[C]//International Conference on Machine Learning.2015:1312-1320.
4.5 辅助任务
在稀疏奖励情况下,
当原始任务难以完成时,
往往可以通过设置辅助任务的方法加速学习和训练。辅助任务解决稀疏奖励的方法主要包括两种类型:第一类方法是“课程式
”强化学习,第二类方法是直接在原任务的基础上添加并行的辅助任务,原任务和辅助任务共同学习。
4.5.1.“课程式”强化学习
当完成原始任务较为困难时,
奖励的获取是困难的。
智能体可以先从简单的、
相关的任务开始学习,
然后不断增加任务的难度,
逐步学 习更加复杂的任务。PowerPlay[1]是一种典型的方法,在原
始任务的基础上不断增加新的更复杂的任务,
智能体在学习新技能的同时需要不遗忘之前学到的技能。例如,Florsensa
等[2]在此基础上提出通过不断改变智能体出发点的位置,来逐步增加任务的难度。Sukhbaatar
等[3]
提出了一 种自我博弈的方式,
将智能体分为两部分
:A
部分用来提出任
务,
B
部分用来完成任务。
A
部分的奖励函数设置为
:
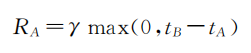
如果
B
部分在完成
A
提出的任务时需要更长的时间
,
则 A 获得更大的奖励。
因此,
A
部分会不断提出更复杂的任务来使 B
难以完成。
B
部分的奖励函数设置为
:
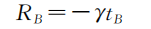
B
部分通过在更少的时间内完成 A 提出的任务来获得奖励。
在不断博弈的过程中,
A
和
B
都能不断提高自身水平,
并持续探索环境。
由于任务的提出和完成均使用内在激励而非外部奖励,
因此在稀疏奖励环境下仍可以高效训练。自我博弈完成后,
智能体在外部奖励的引导下对策略进行微调,
就能够完成复杂的任务。
[1] SCHMIDHUBER J. Powerplay : Training an increasingly general problem solver by continually searching for the simplest still unsolvable problem[J]. Frontiers in psychology,2013,4:313.
[2] FLORENSA C,HELD D,WULFMEIER M,et al.Reverse curriculum generation for reinforcement learning[C]//International conference on Robot Learning.2017.
[3] SUKHBAATAR S,LIN Z,KOSTRIKOVI,et al.Intrinsic motivation and automatic curricula via asymmetric self-play[C]//International Conference on Learning Representations (ICLR).2018.
4.5.2 直接在原任务的基础上添加并行的辅助任务
此类辅助任务有如下优势:
1)
当原任务奖励稀疏时,
智能体可以从辅助任务中获得奖励,
从而缓解了稀疏奖励带来的问题;
2)
通过训练辅助任务可以使智能体掌握某些技能,
这些技能对完成原任务有帮助;
3)
辅助任务与原任务在网络层面会共享一部分表示,
在训练辅助任务时会促进原任务的网络迭代。
Jaderberg等[1]提出了UNREAL框架,即在策略梯度法A3C的基础上添加了像素控制、奖励预测和值函数回放3个辅助任务,如图 4所示。
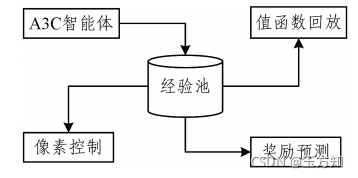
图 4 无监督辅助任务
图3 中,像素控制用于最大化智能体观测中像素的变化,智能体只有在迷宫中不断移动才能获得奖励。通过添加辅助任务,智能体在三维地图视觉导航中获得了很好的效果。Mirowski等[2]进一步提出了一种实用的导航结构,通过添加方向预测的辅助任务,使智能体在城市导航任务中能够准确预测当前方向与正北方向的夹角。该方法在谷歌街景导航中取得了很好的效果,使得基于强化学习的导航算法首次可以用于真实的街景导航中。该算法的结构如图 5所示,其中循环神经网络的使用为网络增加了记忆功能。
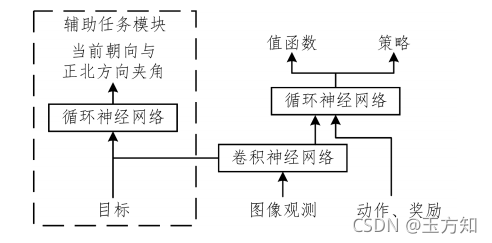
图 5
辅助任务用于视觉导航
[1] JADERBERG M,MNIH V,CZARNECKI W M,et al.Reinforcement learning with unsupervise dauxiliary tasks[C]//International Conference on Learning Representations (ICLR).2017.
[2] MIROWSKI P,GRIMES M,MALINOWSKI M,et al.Learning to navigate in cities without a map[C]//Advances in Neural Information Processing Systems.2018:2424-2425.
总结
该篇论文对深度强化学习的核心算法和解决稀疏奖励问题的进展进行了全面分析,
并指出了当前研究不足和未来的研究趋势。
在本质上,
目前的深度强化学习还不
具备人类自主思考、
决策和推理的能力。随着科技的发展,在未来将会有越来越多的研究成果涌现,推动深度强化学习解决工业生产和日常生活中的问题。
注:需要原文或者文章中出现的参考文献,可以评论去留言+邮箱。











 本文综述了深度强化学习中稀疏奖励问题的研究进展,探讨了奖励设计与学习、经验回放机制、探索与利用策略、多目标任务及辅助任务等多种解决方法。
本文综述了深度强化学习中稀疏奖励问题的研究进展,探讨了奖励设计与学习、经验回放机制、探索与利用策略、多目标任务及辅助任务等多种解决方法。

















 2542
2542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









