








目录
一、引言
在朴素的深度学习ctr预估模型中(如DNN),通常以一个行为为预估目标,比如通过ctr预估点击率。但实际推荐系统业务场景中,更多是多种目标融合的结果,比如视频推荐,会存在视频点击率、视频完整播放率、视频播放时长等多个目标,而多种目标如何更好的融合,在工业界与学术界均有较多内容产出,由于该环节对实际业务影响最为直接,特开此专栏对推荐系统深度学习多目标问题进行讲述。
今天重点介绍“样本Loss提权”,该方法通过训练时Loss乘以样本权重实现对其它目标的加权,方法最为简单。
二、样本Loss提权
2.1 技术原理
所有目标使用一个模型,在标注正样本时,考虑多个目标。例如对于点击和播放,在标注正样本时,给予不同的权重,使它们综合体现在模型目标中。如下表,以视频业务为例,每行为一条训练样本,根据业务需要,把点击视频、视频完播、视频时长的权重分别设置为1、3、5。

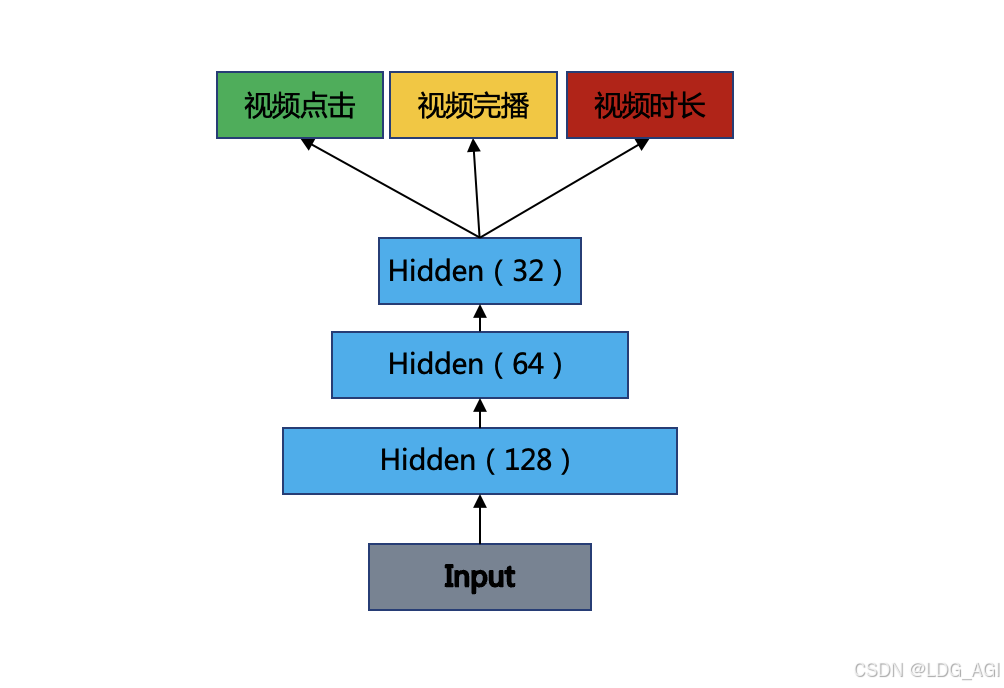
该方法通过对不同正向行为给予不同权重,将多目标问题转化为单目标问题。本质是保证一个主目标的同时,将其它目标转化为样本权重,达到优化其它目标的效果。

2.2 技术优缺点
优点:
- 模型简单:易于理解,仅在训练时通过Loss乘以样本权重实现对其它目标的加权
- 成本较低:相比于训练多个目标模型再融合,单模型资源及维护成本更低
缺点:
- 优化周期长:每次调整样本加权系数,都需要重新训练模型至其收敛
- 跷跷板问题:多个目标之间可能存在相关或互斥的问题,导致一个行为指标提升的同时,另一个指标下降。
2.3 代码实例
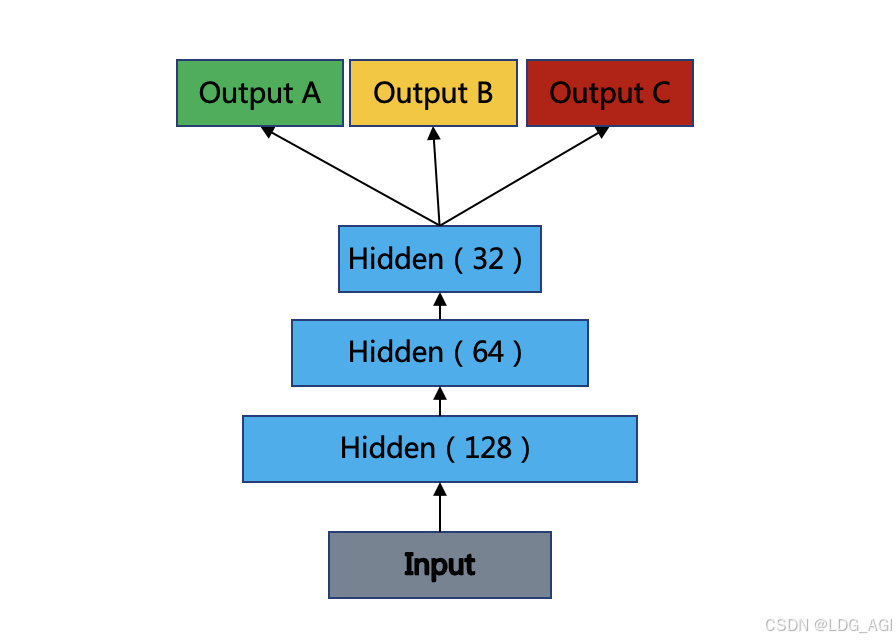
首先,我们需要定义一个DNN模型,并实现一个多目标样本损失函数loss加权算法。这个算法会为不同的目标分配不同的权重,以便在训练过程中优化每个目标的表现。
 TensorFlow版本:
TensorFlow版本:
代码步骤
- 导入库: 导入TensorFlow和其他必要的库。
- 数据准备: 假设我们有一个多目标的数据集,包含多个标签。
- 模型定义: 定义一个简单的DNN模型。
- 损失函数: 实现一个多目标的加权损失函数。
- 训练步骤: 编写训练循环,并使用自定义的损失函数来更新模型权重。
# Python
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.optimizers import Adam
# 假设我们有一个多目标的数据集,包含多个标签
# 数据准备部分在实际应用中可能更加复杂,这里简化处理
num_features = 10
num_targets = 3 # 假设有三个不同的预测目标
batch_size = 64
epochs = 10
# 定义一个简单的DNN模型
def create_model(input_shape, num_targets):
inputs = Input(shape=(input_shape,))
x = Dense(128, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
outputs = [Dense(1)(x) for _ in range(num_targets)] # 每个目标一个输出
model = Model(inputs=inputs, outputs=outputs)
return model
model = create_model(input_shape=num_features, num_targets=num_targets)
# 自定义的多目标加权损失函数
def weighted_loss(weights):
def loss(y_true_list, y_pred_list):
total_loss = 0
for weight, y_true, y_pred in zip(weights, y_true_list, y_pred_list):
# 这里假设使用均方误差作为损失函数
single_loss = tf.reduce_mean(tf.square(y_true - y_pred))
total_loss += weight * single_loss
return total_loss
return loss
# 假设我们给每个目标分配的权重分别是0.5, 0.3, 0.2
loss_weights = [0.5, 0.3, 0.2]
model.compile(optimizer=Adam(), loss=weighted_loss(loss_weights))
# 生成一些虚拟数据以进行训练
import numpy as np
x_train = np.random.rand(1000, num_features) # 随机生成特征
y_train_list = [np.random.rand(1000, 1) for _ in range(num_targets)] # 每个目标的标签
# 训练模型
model.fit(x_train, y_train_list, batch_size=batch_size, epochs=epochs)PyTorch版本:
代码结构
- 导入必要的库。
- 定义多目标 DNN 模型。
- 定义加权损失函数。
- 生成虚拟数据并进行训练。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 定义多目标 DNN 模型
class MultiTargetDNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MultiTargetDNN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 定义加权损失函数
def weighted_loss(weights):
def loss(y_true_list, y_pred_list):
total_loss = 0
for weight, y_true, y_pred in zip(weights, y_true_list, y_pred_list):
# 使用均方误差作为损失函数
single_loss = nn.MSELoss()(y_true, y_pred)
total_loss += weight * single_loss
return total_loss
return loss
# 生成虚拟数据
def generate_data(num_samples, input_dim, num_targets):
x_train = torch.randn(num_samples, input_dim)
y_train_list = [torch.randn(num_samples, 1) for _ in range(num_targets)]
return x_train, y_train_list
# 主训练函数
def train_model(x_train, y_train_list, weights, num_epochs=10, batch_size=8):
# 将数据转换为 DataLoader
dataset = TensorDataset(*([x_train] + y_train_list))
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 初始化模型、损失函数和优化器
input_dim = x_train.shape[1]
hidden_dim = 64
output_dim = len(y_train_list)
model = MultiTargetDNN(input_dim, hidden_dim, output_dim)
criterion = weighted_loss(weights)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(num_epochs):
total_loss = 0
for batch in dataloader:
x_batch = batch[0]
y_true_list = batch[1:]
# 前向传播
optimizer.zero_grad()
y_pred_list = model(x_batch).split(1, dim=1)
loss_value = criterion(y_true_list, y_pred_list)
# 反向传播和优化
loss_value.backward()
optimizer.step()
total_loss += loss_value.item()
print(f"Epoch {epoch + 1}: Loss = {total_loss / len(dataloader)}")
# 主函数
if __name__ == '__main__':
# 设置参数
num_samples = 64
input_dim = 10
num_targets = 3
weights = [0.5, 0.3, 0.2]
# 生成虚拟数据
x_train, y_train_list = generate_data(num_samples, input_dim, num_targets)
# 训练模型
train_model(x_train, y_train_list, weights)关键点解释:
多目标 DNN 模型:
MultiTargetDNN类定义了一个简单的两层全连接网络,输入维度为input_dim,隐藏层维度为hidden_dim,输出维度为output_dim(即目标数量)。加权损失函数:
weighted_loss函数接受权重列表,并返回一个损失计算函数。该函数通过循环遍历每个目标的预测值和真实值,计算均方误差并根据权重进行加权求和。生成虚拟数据:
generate_data函数生成随机输入数据x_train和多个目标的真实值y_train_list。训练模型:
train_model函数将数据加载到DataLoader中,并初始化模型、损失函数和优化器。- 在每个 epoch 中,遍历数据批次,进行前向传播、计算损失、反向传播和参数更新。
三、总结
本文从技术原理和技术优缺点方面对推荐系统深度学习多目标融合的“样本Loss加权”进行简要讲解,以达到对预期指标的强化,具有模型简单,成本较低的优点,但同时优化周期长、多个指标跷跷板问题也是该方法的缺点,业界针对该方法的缺点进行了一系列的升级,专栏中会逐步讲解,期待您的关注。
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)


















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









