







北京大学 林殷年

编者按:
GPU由于其强大的并行处理能力,非常适合SIMD(Single Instruction Multiple Data)计算的处理。因此,近年来大量的工作聚焦于使用GPU来对图算法进行加速。本文通过对Triangle Counting(三角形计数)相关算法的研究,提出了一个利用GPU加速的三角形计数计算框架,并且创新性地引入并行的二分查找方法,进行更加高效的取交集操作。
今天介绍的工作是TRICORE: Parallel Triangle Counting on GPUs,作者为Yang Hu,Hang Liu,H. Howie Huang,发表于The International Conference for High Performance Computing, Networking, Storage, and Analysis 2018.

论文地址:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8665796
(或点击文末“阅读原文”跳转)
1 背景介绍
三角形计数在现代图算法中是非常重要的一环。三角形计数本身能够用于计算图的聚集系数和k-truss等属性,也能够用于进一步进行3-profiles,counting cycles等的计算。在实际场景中,三角形计数也能够在欺诈检测、推荐、社交网络分析等应用领域发挥作用。
传统的三角形计数算法会迭代图中的边,对两个端点的邻接表取交集。每找到一个公共元素,也即找到一个三角形。这类算法的复杂度为,其中E中用于计算交集的边的条数。然而,目前的真实图数据中的边规模能够达到十亿及以上,这时三角形计数会成为一个巨大的性能瓶颈。
目前的GPU的性能得到了巨大的飞跃。NvidiaRTX 3090能够实现35.7 TFLOPS的浮点计算性能。因此,可以利用GPU加速三角形计数算法。此前的工作大多借鉴早期在CPU上的三角形计数算法,将这些算法在GPU上实现。然而,由于没有很好地考虑GPU的硬件特性和图算法的访存模式,没有办法在更大规模的图数据上发挥应有的性能。因此,本文提出了TRICORE,其能够处理大规模的图数据上的三角形计数,而且能够从单GPU拓展到单机多GPU与分布式的GPU环境,并且达到SOTA的性能水平。
本文的主要贡献包括:第一,设计了适应GPU环境的基于二分搜索的三角形计数算法,并且充分利用GPU上的缓存机制进行优化;第二,设计了一种三步优化机制,使得TRICORE能够在边规模特别巨大的图数据上快速计算三角形计数。TRICORE将图数据以CSR格式存放在GPU的显存上,除此之外,TRICORE采取了一种数据分割的方式,将CSR格式存储的图数据进行切分,分别存在不同的GPU或主机上。TRICORE还采用了一种动态的任务分配方法,均衡各块GPU或主机的工作负载。
2 基础知识
图数据中的三角形指的是一个由三个不同的结点构成的集合,这些结点两两之间都有边关联。当前的三角形计数算法主要由两个步骤构成:orientation和compatation。其中,orientation是预处理的操作,通过对图中的边进行过滤,减少下一步需要的计算量。Computation是实际的计算工作,遍历orientation中的得到的边,同时计算每条边关联的两个结点的邻居列表的交集结果,即寻找其公共元素。一个公共元素意味着一个三角形。
在这中间,最常用的取交集的办法是基于归并的方法。因为图数据中的结点的邻居信息都是固定的,因此可以在预处理时将邻居信息有序存放。而对两个有序列表取交集,使用归并的方法的理论时间复杂度是最低的。
另一方面,从硬件角度来看,GPU具有两大特性。其一是nvidia系列的GPU包含大量CUDA核心,能够同时并行运行成千上万个线程。其次,由于计算并行度和吞吐量很高,GPU设备往往带有先进快速的存储设备,访存带宽较CPU内存要高得多,也更适合并行的访存请求处理。除此之外,GPU中还带有一定的访存优化的功能。对同一时刻产生的访存请求,GPU能够将请求地址在一定范围内的的多个请求进行合并,在一个请求的时间内处理多个请求。除此之外,GPU内部还有shared memory和L2 Cache两种快速存储单元可以作为缓存区。
3 Tricore Overview
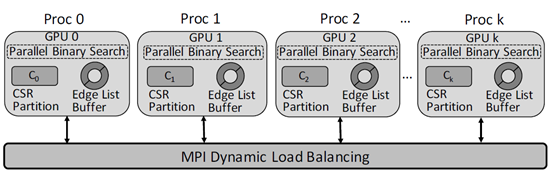
上图显示的是TRICORE系统的架构。系统使用MPI进行动态任务分配,在每块GPU中存储一部分CSR格式存储的图数据,还维护了Edge List Buffer来维护来自Master进程的任务。对Edge List Buffer的每条边,使用一个WARP并行处理,利用基于二分搜索的方式计算两个端点邻接列表的交集。TRICORE的设计主要基于以下两个事实:
第一,此前的算法中常用的基于归并的算法虽然时间复杂度较低,但是当我们将归并的算法在GPU上实现的时候,其访存模式并不适合GPU。在归并算法中通常需要维护两个指针,分别遍历两个集合。虽然两个集合各自是连续存储的,但是它们在显存中的位置并不一定很接近。因此,在进行归并的时候无法利用GPU的访存合并特性。因此TRICORE使用了并行的二分搜索算法来求交集,并针对其访存模式设计了高效的缓存结构。
第二,过去的在GPU上计算三角形计数的算法的空间代价很高。通常而言,三角形计数需要维护一个边的列表,它会占据大量的空间,因此,TRICORE使用一个缓冲区来存放来自CPU的需要处理的边列表。同时,系统采用了一种二维的图数据分割方法,对CSR格式存储的图数据进行分割,减少多块GPU上的显存占用。
4 GPU based binary search
文中基于二分搜索的思想提出了并行的取交集算法。算法将取交集的两个集合中元素较少的一个视为待查找的集合lookup list,另一个视为用于被查找的集合binary search list。利用GPU中的多个线程同时将lookup list中的多个元素在binary search list中进行二分搜索。算法流程如下所示:

本文还针对GPU的特性对上述取交集算法进行了优化:
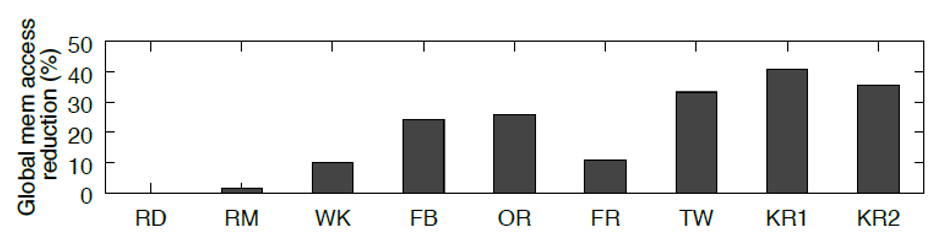
首先,该算法充分利用了GPU上的合并访存特性。同时运行的多个线程会读取lookup list中一段连续的元素作为查找的目标,这些访问请求可以被合并为一个请求,极大地节省了访存时间。另外,由于lookup list是有序的,多个线程二分搜索的过程中,有很多线程都会访问到同一个元素,这时合并访存也能够发挥作用。其次,这个算法天然具有较好的负载均衡。当查询失败时,必然要查找到查询树的最底层,而当查询成功时,也有较大的可能要访问查询树的最底层,即查找成功和查找失败的平均查询次数是非常接近的。最后,本文利用了GPU中的shared memory,将binarysearch list构成的查询树的前几层结点缓存在shared memory中,下图的实验结果显示,此举能够在图规模较大时带来较好的访存代价节约。
5 实验
本文的实验部分使用的GPU包括6块NVIDIA Kepler K40c以及2块NVIDIA Titan X,在CPU端分别采用了一台配备Intel Xeon E5-2683的服务器,一台配备4颗Intel Xeon E7-8857以及2TB RAM的服务器,以及一套使用Intel Xeon E5-2650的集群。
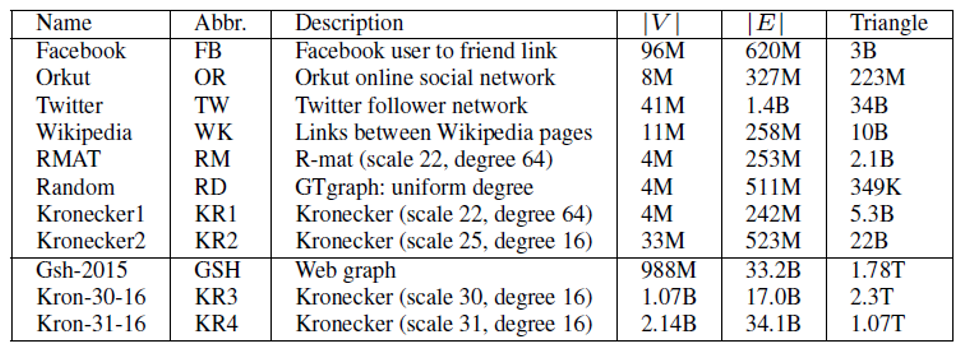
在数据集方面,主要包括以下几组数据集:
本文将TRICORE与多种不同实现策略的三角形计数方法进行了对比,具体包括:Green等人在单个GPU上的工作、Shun等人在单机上的工作以及PDTL,这是一个在分布式系统上的工作。
-
与其他工作的对比

如上图所示,在所有的测试数据集上TRICORE都显示出了较大的性能优势。使用单块K40c的TRICORE系统对比同样使用单块K40的Green等人的系统取得了平均5.9倍的加速。虽然在较小的数据集上的优势并不明显,但是随着数据集的增大,TRICORE的性能优势逐渐展现。而与Shun等人的单机系统和PDTL相比,单GPU的TRICORE分别取得了平均2.5倍和6.5倍的性能提升。当TRICORE使用6块K40c时,平均加速比则分别提高到了24倍,9倍以及23倍。在当时更为先进的TitanX GPU上,TRICORE同样取得了较高的加速比。
-
扩展能力试验
本文还对比了当GPU数量以及结点数量增加时,TRICORE系统的性能提升表现。如下图所示:
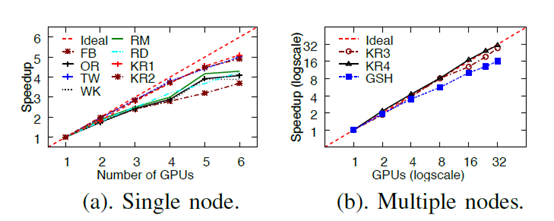

考察GPU的数量时,随着GPU数量翻倍,性能提高在1.8倍左右。而考虑分布式系统时,随着器件数量翻倍,性能的提高在1.9倍左右。














 1345
1345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









