








P. Peng, M. T. Özsu, L. Zou, C. Yan, C.Liu. MPC: Minimum Property-Cut RDF Graph Partitioning. In Proc. 28th IEEE Int. Conf. on Data Eng., 2022. Accepted for publication。
本文涉及分布式系统中的数据划分,特别是涉及到含有属性的图数据划分,更为具体地讲,涉及到分布式RDF系统的数据划分。本文已经被ICDE 2022接收。
01
—
RDF 数据划分
RDF(Resource Description Framework)是一种由W3C组织提出的数据模型,其用三元组<主语,谓语,宾语>的基本形式表示web资源的属性、关系,目前在知识图谱、社交网络分析等领域均有应用。RDF数据模型表示形式灵活,不仅可以表示成关系数据库中的表,也可以表示成图模型。当RDF表示成图时,一个三元组代表着一条由主体指向客体的有向边及其连接的两个顶点,主体、客体是边的两个顶点,谓语则是有向边上的标签。W3C在提出RDF的同时,也提出了一种标准查询语言SPARQL(Simple Protocol And RDF Query Language)。SPARQL与RDF一样,也能表示成图模型。查询图中的边称为三元组模式,三元组模式中的主语、谓语、宾语均可以是变量或常量。因为SPARQL与RDF都可以表示成图模型,所以SPARQL查询可以转换成子图匹配问题。
随着互联网的快速发展,RDF数据集的规模不断增大,传统的单机系统已经无法有效地处理海量RDF数据,因此出现了分布式RDF系统。在分布式系统中,数据划分是一个最基本的过程。具体而言,即将RDF数据图G分成一组子图{F1,F2,…,Fk},每个子图称为分区,分布在不同的机器中。目前分布式RDF系统中使用较多的数据划分方法是按顶点划分,即将每个顶点划分到不同分区中,例如常见的哈希划分。在该类方法中,一些边会在分区之间被“分割”,即边的两个顶点被划分到不同的分区中。为了保证图的完整性,这些被分割的边会重复保存在两个分区中,称为一跳复制。如果一条边的两个顶点在同一个分区内,则称为内部边;否则称为跨越边。如果一个属性不存在跨越边,则称该属性为内部属性,所有内部属性集合记为Lin。如果一个属性至少存在一条跨越边,则称该属性为跨越属性,即至少有一条跨越边的属性为该属性,所有跨越属性集合记为Lcross。显然,Lin=L-Lcross。
查询的匹配类型与边的类型一样,也可以分成两类:内部匹配,匹配结果只包含在一个分区内;跨越匹配,匹配结果包含在多个分区内。当待执行的查询只有内部匹配时,则只需要在每个分区内独立执行即可。对于含有跨越匹配的查询,现有的方法大多将查询分解成一组星形查询,然后在每个分区中独立执行星形查询,最后执行分区间连接得到最终结果。但是分区间连接会涉及到数据通信和额外计算的开销,对查询性能影响较大。并且,在传统的按顶点划分的方法中,可独立执行的查询只能是星形,限制较大,在处理一般的查询时,通常会进行分布式连接,因此查询效率并不高。
02
—
最小属性割
现有的分布式RDF系统只根据查询图的结构来判断查询是否可以独立执行,只有当查询图是星形时才被认为可以独立执行。本文在考虑图数据中边的属性之后,扩展了可独立执行的查询类型,而不仅仅局限于星形查询。本文的目的之一在于提供一种基于最小属性割的图数据划分方法,该方法能够减少跨越属性的数量,从而避免分区间的连接操作,降低数据通信时间。本文的目的之二在于提供一种查询分解方法,该方法能够将不可以独立执行的原始查询分解成一组可以独立执行的子查询,从而充分利用最小属性割数据划分的优势,提升查询效率。
最小属性割分区定义:给定一个RDF数据图G和一个正整数k,G的最小属性分区{F1,F2,…,Fk}需要满足:(1)跨越属性的数量|Lcross|最小;(2)每个分区中顶点数量不会超过(1+ε)×|V|/k,其中ε是用户自定义的最大的不均衡比例,k是分区数量。
因为Lcross=L-Lin,所以最小属性割等价于最大化Lin的大小。基于此,本文提出求解最小属性割的方法流程如下:
步骤1:读取原始RDF数据图G,并将边属性保存到集合L中;
步骤2:遍历集合L,计算出每个属性p对应的弱连通组件分量WCC(G{p})以及对应的代价Cost({p});
步骤3:尽可能从属性集合L中选择更多的内部属性Lin。将每个内部属性Lin中对应的弱连通组件分量作为一个超点,得到数据图的粗化图;
步骤4:对粗化图中的超点使用顶点分区算法进行划分,在划分之时确保每个分区中的顶点数量不超过(1+ε)×|V|/k。其中ε是用户自定义的、最大的不均衡比例,k是分区数量。
步骤5:将步骤4中划分到同一个分区的超点集合反粗化成最终的一个分区,即将超点集合中包含的原始数据点划分为原始数据图中的一个分区。
图1给出了一个最小属性割RDF数据划分的示例。原始数据图中有12个顶点、6个边属性,当经过粗化的处理后,会选择出内部属性Lin={starring, residence, producer, spouse, foundingDate}。内部属性的边即为图1中加粗的边,这些边形成两个弱连通分量。在粗化图中,这两个弱连通分量各自形成一个超点,并且超点之间由跨越属性birthPlace的边连接。如果分区数量为2,则原始数据图会被图2中的虚线分割成两个分区,从而得到最终的最小属性割划分结果。
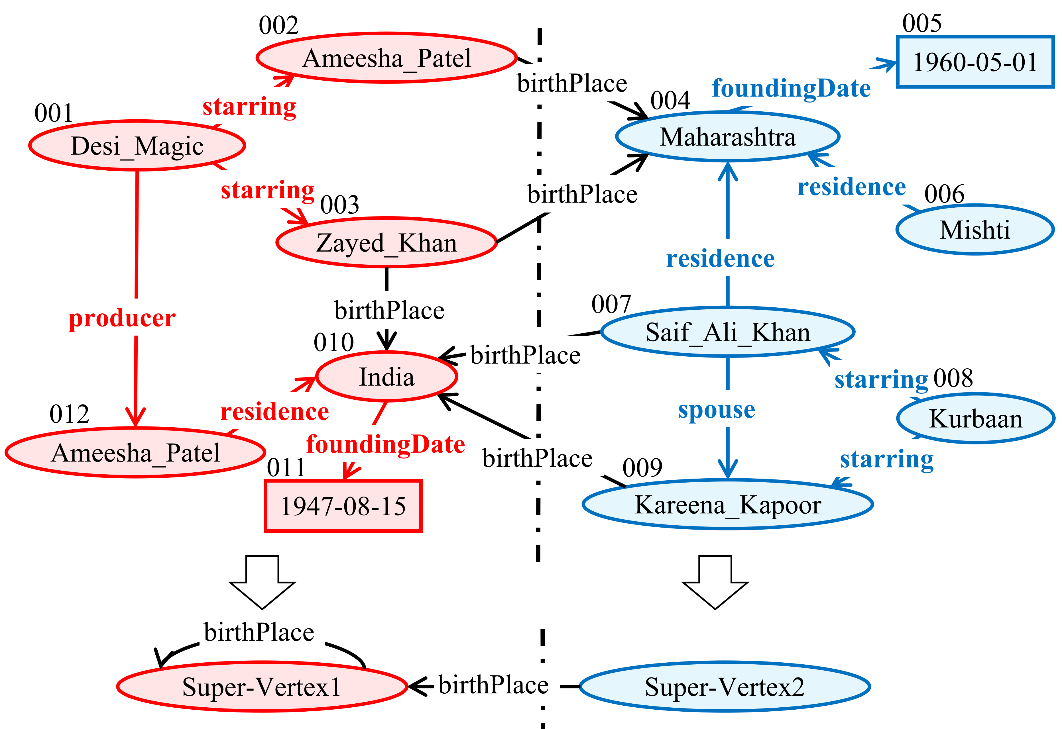
图1.最小属性割划分示例
在查询处理阶段,本文首先将待处理的SPARQL查询分解成一组可以独立执行的子查询。在真实的SPARQL查询任务中,查询很可能是不可以独立执行的。为了能够充分利用最小属性割数据划分的优势,减少分区间的连接,还需要将原始查询分解成一组可以独立执行的子查询。具体而言,本文方法如下:

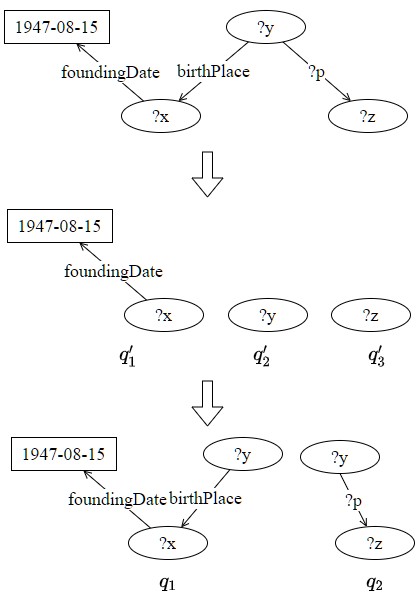
图2.查询分解示例

03
—
实验结果
本文在多个真实和人造数据集上进行了实验。所用的实验数据集如下图所示。
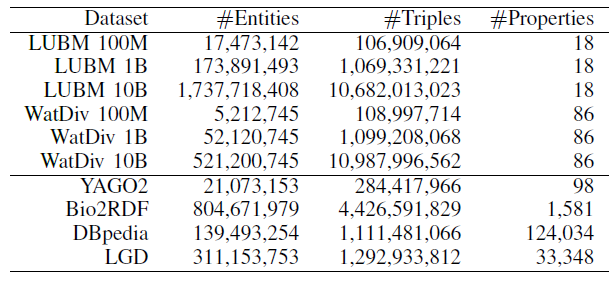
图3. 实验数据集
本文所提出最小属性割方法可以提升独立执行的查询的比例,图4给出了不同数据集上可独立执行查询(Independently Executable Query,简写IEQ)的比例,显然最小属性割方法导致的可独立执行查询比例最高。

图4.不同数据集上可独立执行查询比例
由于可独立执行查询比例比较高,所以LUBM、YAGO2和Bio2RDF基准查询的最小属性割方法所致的分布式执行性能也显著高于现有其他划分方法,如图5所示。
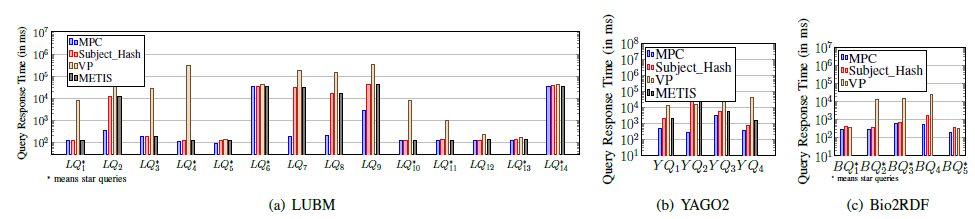
图5. LUBM、YAGO2和Bio2RDF基准查询的性能对比
类似地,在WatDiv、DBpedia和LGD的查询日志上,本文所提的最小属性割方法的分布式执行性能也显著高于现有其他划分方法,如图6所示。
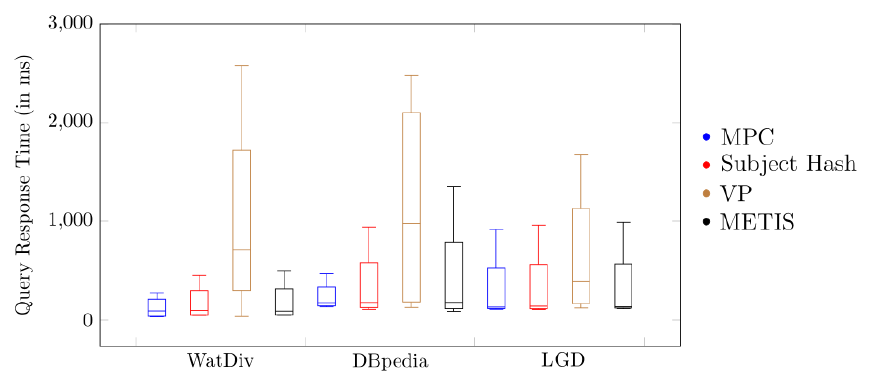
图6. WatDiv、DBpedia和LGD查询日志的性能对比















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









