






可以以非常简单的方式组织任意类型的RNN层(不重要,因为我这里会换成transformer)。
优点:
1.模型更小
2.性能更好(SI-SNR)
模型组成:
首先肯定是encoder和decoder了,一个声音的信号经过编码才会得到这种L*N的形式。
1.Segmentation(分割模块)
把输入分割成重叠的块,再把所有的块连接为3-D张量。

先记住这里有一个点:K=2P(就是对应的划分好了的关系!!!!)
输入W:N*L规格的向量信息,N表示词向量维度特征,L表示时间步长。
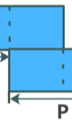
把输入分割为一个一个小小的块,每一个块长度为K=2P,其中P为hope size,也就是说是buffer的一半。(50%)
第一个和最后一个块是用0填充的,目的在于:让输入中的所有样本都可以被处理到,而且都是在重叠的地方(头一个P和尾一个P没有数据,这样所有数据都是放在重叠区)如右图:
生成S个相同大小的块。
把S个块信息,综合起来形成了一个3-D张量——N*K(2P)*S
2.Block processing(块处理模块)

分为两个块:intra和inter。每一个模块输入和输出的矩阵维度信息都是相同的。
首先提出了b=1,…,B as 𝑇𝑏∈𝑅𝑁∗𝐾∗𝑆,其中T1=T(上面的输出?)于是重叠成了左边模块最下面的图形。进入intra进行训练,intra是双向的,并且RNN只用于𝑇𝑏的第二维。
(我明白了,所谓的the second dimension,就是除去前面的N维,这个是不变的词向量特征信息(N维向量表示一个词的特征),剩下的K和S维度,对于这两层进行处理,而K和S就分别代表了intra-chunk和inter-chunk的RNN的长度信息,表示处理的是块内的还是块间的)
在Intra里面RNN输出的信息是𝑈𝑏=[𝑓𝑏𝑇𝑏:,:,𝑖,𝑖=1,…𝑆]:
其中Ub的维度信息是H*K*S,𝑓𝑏(.)是RNN里面定义的mapping 函数(映射函数),𝑇𝑏:,:,:𝑖维度信息是N*K。![]()
维度信息改变了,需要进行归一化和预处理。
FC:线性连接层,用来改变维度信息𝑈𝑏=[𝐺𝑈𝑏:,:,𝑖+𝑚,𝑖=1,…𝑆]:![]()
其中G的维度信息:N*H,就是FC层内的权重分布;m维度信息:N*1,FC层内的偏置项。
LN:LayerNorm归一化层,(简单写一下公式,和BN算法是一致的,多了一个小正数𝜖,用来数值稳定的)![]()
公式:LN𝑈𝑏=𝑈𝑏−𝜇(𝑈𝑏)𝜎𝑈𝑏+𝜖⊙z+r,基本上一模一样。![]()
最后接上一个残差连接。就是输出𝑇𝑏。![]()
在Inter里面RNN输出的同样也是和上面一样的,但是公式有所不同,处理的是最后一个维度的信息。
公式:𝑉𝑏=[h𝑏𝑈𝑏:,𝑖,:,𝑖=1,…𝐾]。![]()
后面的步骤是同样的。也有残差连接,但是块间的RNN是单向的,从第一个到最后一个进行扫描。
3.Overlap-Add(重叠相加块)
𝑇B+1∈𝑅𝑁∗𝐾∗𝑆,作为块处理的结果,进入重叠相加块。把结果转换为顺序输出。![]()
具体机理是,作用于S个块,然后形成一个 𝑄∈𝑅𝑁∗𝐿,作为结果。![]()

参数选择:
K=2P,S=2𝐿/𝐾+1,𝐾+𝑆=𝐾+2𝐿/𝐾+1,K=2𝐿,S≈2𝐿≈𝐾。![]()
















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









