






 本文介绍了DPRNN网络在语音分离任务中的应用,该网络通过编码、分离和解码三个阶段实现高效处理。在wsj0-2mix数据集上,DPRNN能提升SI-SNR指标达18.8dB。网络处理两个32000长度的音频片段,并利用LSTM进行特征提取。文章还提及了排序、注意力机制、全排列等概念,并讨论了损失函数和梯度裁剪策略。此外,还涉及到了数据存储和索引操作的示例。
本文介绍了DPRNN网络在语音分离任务中的应用,该网络通过编码、分离和解码三个阶段实现高效处理。在wsj0-2mix数据集上,DPRNN能提升SI-SNR指标达18.8dB。网络处理两个32000长度的音频片段,并利用LSTM进行特征提取。文章还提及了排序、注意力机制、全排列等概念,并讨论了损失函数和梯度裁剪策略。此外,还涉及到了数据存储和索引操作的示例。
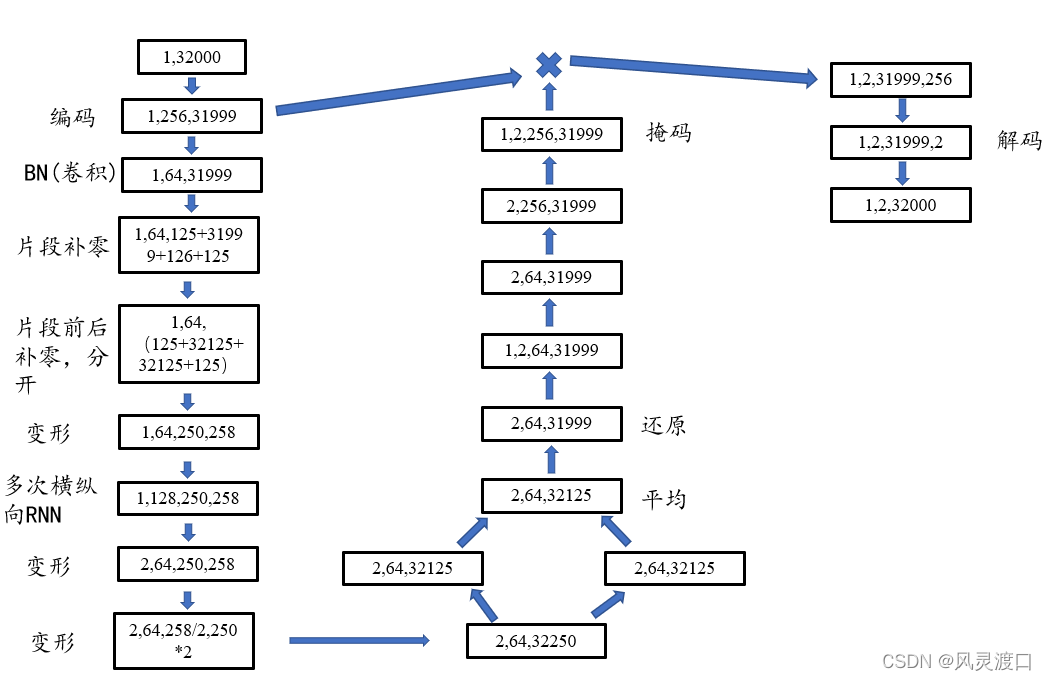
下为DPRNN的网络结构,随手画的,错了请提醒。
网络分为编码、分离、解码
该网络能够在语音分离中的数据集wsj0-2mix 达到SI-SNR提升18.8db的效果。
该网络数据读取时为两个32000长度的音频片段,一个为音频开头,一个为音频结尾;在训练时随机选一个放入网络
sorted( infos, key=lambda info: int(info[1]), reverse=True)进行排序,reverse代表降序,key代表是按info[1]的维度.- break 是中断该次小循环的这一次循环,如果该小循环由其他包含它的循环重启,则小循环继续。
-
- xs[0],在形状中指xs的维度,如xs.size()=[16,64,2,32000],则* xs[0]代表[,64,2,32000]的形状,x[0].new(1,1,* xs[0])则为[1,1,16,64,2,32000]而与x无关,应该和x的类型有关。
- LSTM双向则输入层加倍,因为双向LSTM的输出也为双倍
- getattr获得属性值
bf_filter = self.output(output) * self.output_gate(output)这种滤波器不太懂,我觉得像一个全权重的注意力机制.permutations(range(C)返回可迭代对象的所有数学全排列- 该网络使用-SI-SNR作为损失函数
json.dump(file_infos, f, indent=4)将python中的对象转化成json储存到文件中,indent写入的文本的缩进torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.max_norm)对于存在梯度爆炸的情况, 在优化器函数之前执行这个函数,可以重新整合一遍梯度梯度缩小到指定范围result.index_add_(-2, frame, subframe_signal)按第-2维度,将result和subframe_signal相加,即先按dim和 frame将subframe_signal重新排列,frame有重复的维度则subframe_signal对该维度数据也重复相加,最后与result相加。如下代码,x[:,1]=t[:,0]+t[:,4]
x = torch.tensor([[1, 2, 32000, 1],[1,2,5,8]])
t = torch.tensor([[1, 1, 5, 8,2], [1,1,2,5,1]])
index = torch.tensor([1, 0,2,3,1])
x.index_add_(1, index, t)
print(x.size())
print(x)
torch.Size([2, 4])
tensor([[ 2, 5, 32005, 9],
[ 2, 4, 7, 13]])

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









