







作者 Yi Luo, Zhuo Chen, Takuya Yoshioka
发表于 ICASSP 2020
DPRNN、时域、长语音序列
-
研究发现
基于时域的分离方法要比基于时频域的分离方法要好,但是与时频域方法相比,时域方法在对长语音序列方面有困难。本文提出了DRPNN对RNN进行优化使其可以对长语音序列进行建模,DPRNN将长语音序列分割成更小的块,并迭代地应用块内和块间操作,其中在每次操作中,输入长度可以与原始序列长度的平方根成正比。 -
Introduction
- 基于时频域的方法旨在对幅值和相位进行联合优化
- 基于时域的方法可以分为两类:自适应前端和直接回归方法。自适应前端通过构建可学习前端替代STFT,然后将生成的类似于频谱图的数据作为分离模块的输入。这个方法的好处是可以在窗口大小和前端基频数量方面有更多灵活的选择。该类型的方法类似Conv-TasNet;直接回归方法通过某种形式的一维卷积神经网络(1-D CNN)来学习混合语音到干净语音的映射关系,而无需明确的短时傅里叶变换。
这两种方法都需要依赖对长时间序列的有效建模 - 作者提出的DPRNN以一种简单的方式模拟长时间序列输入,将长时间序列分割为较短的块,并使用块内RNN和块间RNN分别建模局部序列和全局序列
- 对于长度为L的时间序列输入,以块大小为K,步长为P分割为S块,K和S分别为块间RNN和块内RNN的输入。当K=S时,两个RNN的输入长度为原始输入长度开根号,这就可以大大降低长时间序列的优化难度。假设原始长度为100的音频序列,chunk size=10,hop=10,于是得到的S=10。这时K=S,而两个RNN的长度都为10,是√100。
- 大多数分层RNN的第一层输入的为整个时间序列,而DPRNN在块内和块间RNN上的输入都是相同的。与基于CNN的体系结构相比(由于CNN的感受野固定只能对局部进行建模),DPRNN的块间RNN可以充分利用全局信息,并以更小的模型尺寸实现优异的性能
-
模型结构
-
DPRNN的组成部分:分割,块处理和重叠相加。 分割阶段将顺序输入分割为重叠的块,并将所有块连接为一个3-D张量。 然后将张量传递到堆叠的DPRNN块,以交替方式迭代应用局部(块内intra-chunk RNN)和全局(块间Inter-chunk RNN)建模。 最后一层的输出通过重叠相加法转换回顺序输出。
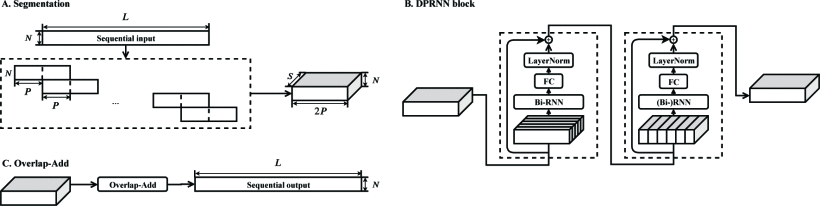
-
分割:输入时间序列 W ∈ R N × L W\in\mathbb{R}^{N×L} W∈RN×L,N为特征维度,L为时间序列;将W按照步长为P,大小为K的形式分割为S个块 D s ∈ R N × K , s = 1 , 2 , . . . , S D_s\in\mathbb{R}^{N×K},s=1,2,...,S Ds∈RN×K,s=1,2,...,S(为了保证均匀分割,第一个块和最后一个块要补零),之后所有块串联起来形成一个三维tensor T ∈ R N × K × S T\in\mathbb{R}^{N×K×S} T∈RN×K×S
-
块处理1:将T输入到就有B个DPRNN块的堆栈中。每个DPRNN块包含块内RNN和块间RNN两部分。首先输入到块内RNN的数据记为 T b ∈ R N × K × S , b = 1 , 2 , . . . , B , T 1 = T T_b\in\mathbb{R}^{N×K×S},b=1,2,...,B,T_1=T Tb∈RN×K×S,b=1,2,...,B,T1=T,块内RNN是双向的,作用于单个混合语音块相当于是 D s D_s Ds,RNN的输出为 U b = [ f b ( T b [ : , : , i ] , i = 1 , . . . , S ) ] , U b ∈ R H × K × S U_b=[f_b(T_b[:,:,i],i=1,...,S)], U_b\in\mathbb{R}^{H×K×S} Ub=[fb(Tb[:,:,i],i=1,...,S)],Ub∈RH×K×S,i表示输入到块间RNN的第i个混合语音块, f b f_b fb表示RNN中定义的映射函数。之后 U b U_b Ub通过FC层将特征维度从H映射到 T b T_b Tb的N U b ^ = [ G U b [ : , : , i ] + m , i = 1 , . . . , S ] , U b ∈ R N × K × S , G ∈ R N × H \hat{U_b}=[GU_b[:,:,i]+m,i=1,...,S],U_b\in\mathbb{R}^{N×K×S},G\in\mathbb{R}^{N×H} Ub^=[GUb[:,:,i]+m,i=1,...,S],Ub∈RN×K×S,G∈RN×H是FC的权重。对 U b ^ \hat{U_b} Ub^使用层归一化增加泛化能力,最后在LN的输出层加一个残差连接得到块内RNN的输出 T b ^ = T b + L N ( U b ) ^ \hat{T_b}=T_b+LN(\hat{U_b)} Tb^=Tb+LN(Ub)^
-
块处理2:块内RNN的输出作为块间RNN的输入。块间RNN由于需要对全局序列进行建模,因此在在混合语音块的时间维度上进行操作(也就是 D s ∈ R N × K D_s\in\mathbb{R}^{N×K} Ds∈RN×K中的K),RNN的输出为 V b = [ h b ( T b ^ [ : , i , : ] ) , i = 1 , . . . , K ] , V b ∈ R H × K × S , T b ^ [ : , i , : ] V_b=[h_b(\hat{T_b}[:,i,:]),i=1,...,K],V_b\in\mathbb{R}^{H×K×S},\hat{T_b}[:,i,:] Vb=[hb(Tb^[:,i,:]),i=1,...,K],Vb∈RH×K×S,Tb^[:,i,:]是S个混合语音块的第i个时间步,由于RNN是双向的,因此 T b ^ \hat{T_b} Tb^中的每个时间步都包含它所属区块的全部信息,这使得块间RNN能够执行完全序列级建模。和块内RNN一样,块间RNN也需要层归一化和残差连接。
-
堆叠相加:在最后一个DPRNN块的输出 T b + 1 ∈ R N × K × S T_{b+1}\in\mathbb{R}^{N×K×S} Tb+1∈RN×K×S应用重叠添加方法恢复成语音波形。
-
本文没有考虑实时语音分离的情况
-
-
数据集:WSJ0-2mix
-
结果:SI-SNR=18.8;SDRi=19.0
















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









