







背景
在这之前,图像目标检测问题的解决方案是采用CNN两阶段来解决(以fast-cnn为代表)。首次想尝试一阶段(端对端)来解决图像的目标检测算法。
(一)yolo v1
yolo v1采用了类似Google Net的主干网络,有24个卷积层和2个全连接层,将输入图片分为7*7的网格,每个网格预测两个边界框。共有98个边界框,最多识别49个目标。缺点:不利于识别密集的小目标,因为分的网格比较大。
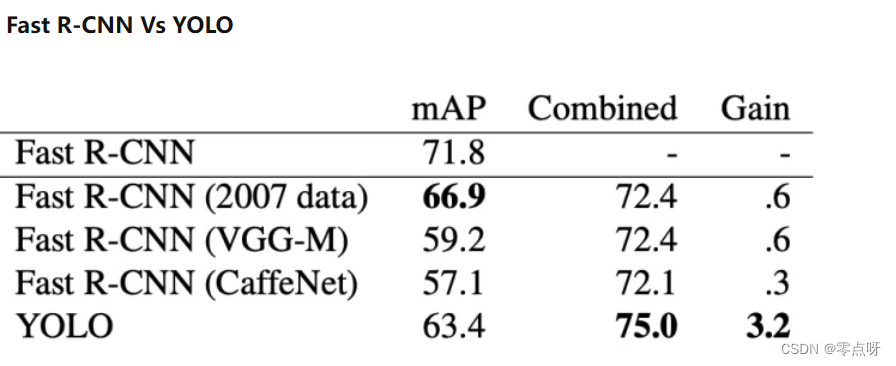
以下为fast-cnn与yolo的比较
(二)yolo v2
1.在v1的基础上,使用 Darknet-19 分类网络。
2.将锚框代替全连接层来预测边界框。
3.联合使用分类和检查的训练方法,扩展目标检查到缺乏检测样本的对象
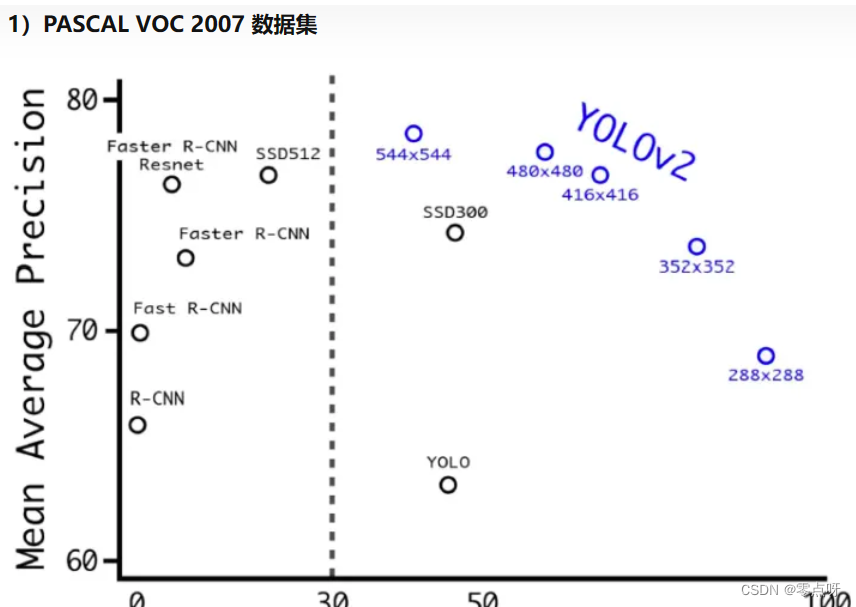
4.将输入图片修改为416416,最后得到1313的特征图
(三)yolo v3
1.主干网络采用darknet53,加深了网络结构,解决了网络梯度爆炸而引发的难以收敛的问题,前向传播过程中,移除池化层和全连接层,通过改变卷积核的步长来改变张量的尺寸。
2.YOLOv3的预测框较YOLOv2增加了10多倍,增加了多尺度检测。使用了3种尺度,其输出分别是52 52,26 26,××13×13用于检测小、中、大目标,每种尺度预测3个锚框。成为单阶段检测中的里程碑算法之一。
(四)yolo v4
1.基础网络部分,YOLOv4的整体架构与YOLOv3相同,但对各个子结构都进行了改进。YOLOv4删去了最后的池化层、全连接层以及Softmax层,其主干网络有5个CSP模块。
2.将v3之后的各类改进方法进行总结,分为免费包和特价包。其中,前者表示提升训练而对推理速度没有影响的模块,后者表示对推理时间影响较小而性能回报较高的模块。
3.引入空间金字塔池化spp与路径聚合网络.,SPP显著增加了感受野,在不降低运行速度的情况下分离了重要的上下文特征。
(五)yolo v5
1.基本结构与YOLOv4类似,最大不同为根据不同通道的尺度缩放,依据模型从小到大构建了YOLOv5-N/S/M/L/X 5种模型。
2.轻量化:一种是设计轻量化的基础网络,比如Mobile Net系列;另一种是压缩整体网络参数,减少卷积层等设计一些“小而薄”的网络,例如YOLO的tiny系列。
3.YOLO还可通过引入注意力机制来提高算法的检测精度,最终选择空间注意力机制。















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









