







第二十五课 network in network(NIN)

NIN 叫做network in network或者叫做网络中的网络。这个网络现在用的不多,几乎很少被用到。但是它里面提出了比较重要的概念,在之后很多网络都会被持续的用到。所以今天认识一下这一个网络。
目录
理论部分

在 alexnet 和 vgg 的时候都在最后用了比较大的全连接层,在 vgg 和alexnet都是一样的,用了两个4096的全链阶层,最后通过一个全链阶层作为输出。这些全连阶层的参数其实特别占用空间,也会占用很多的计算带宽,它还很容易会产生过拟合。
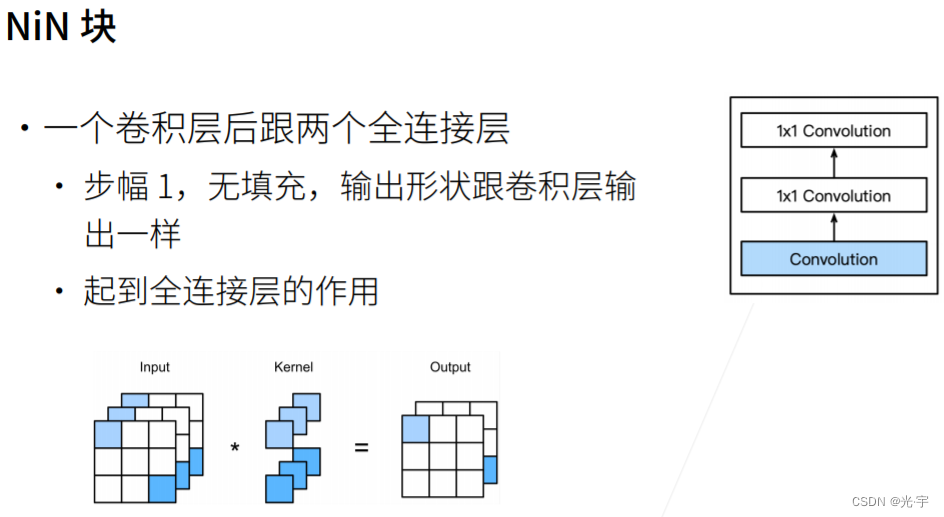
它首先有一个卷积层,然后跟了两个全连阶层,其实1乘1的卷积层可以等价是一个全链阶层,具体来说1乘1的卷积层也就是窗口的大小是1乘1、步幅为1,无填充的卷积层,这个卷积层不会改变输入的形状,也不会改变通道数。所有1乘1的卷积层可以当做全连阶层来使用,它的作用就是对每个通道数帮你做一些混合。

就是说我的池化层的高宽是等于输入的高宽,等价于把每一个通道最大的值给拿出来,再加个 softmax 就会得到我们的概率了。

上图是vgg架构和nin架构的对比图,vgg 就是有四个 vgg块,再加上两个大的全连接层最后得到输出类是1000类;那么 NIN的话主要由nin 块和一个步幅为2的最大池化层组成,不断重复这一个过程,直到最后如果把通道数设成分类个数的话,那么最后直接用全局的平均池化层来得到输出对每一个类的预测即可。

所以整体来讲就是 nin 架构比较简单,就是 nin块 加上最大池化层一直到最后一个全局的平均池化层。而且它的通道参数个数非常少,少是因为整个就没有全链阶层。这就是nin网络。
实践部分



nin与Alex net对比一下。发现nin精度(0.83)还没有之前Alexnet(0.88)高,然后nin的速度是也没有比 alexnet高太多,这是因为nin额外加入了大量的1乘1的卷积层,会使得计算会变慢。然后也因为数据集相对来说比较少。
代码:
#网络中的网络(NiN)
#NiN块
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),#1*1卷积层使得输入输出通道个数一样
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),#1*1卷积层使得输入输出通道个数一样
nn.ReLU())
#NiN模型
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),#一个nin块
nn.MaxPool2d(3, stride=2),#加一个最大池化层,卷积核维度为3,步长为2
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),nn.Dropout(0.5),#把一半的权值设为0,减少计算量
nin_block(384, 10, kernel_size=3, strides=1, padding=1),#最后一个nin块的输出通道数要等于类别数
nn.AdaptiveAvgPool2d((1, 1)),#全局平均池化层,高宽都为1
nn.Flatten())#把最后两个维度直接消掉,就变成了一个 backsize 乘以10的矩阵。这个东西就可以直接softmax回归
#查看每个块的输出形状
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
#训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
training on cuda:0
<Figure size 350x250 with 1 Axes>
<Figure size 350x250 with 1 Axes>。。。。
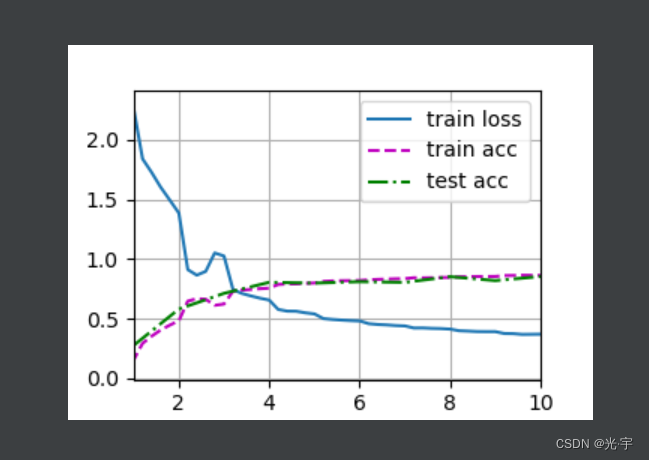
loss 0.369, train acc 0.863, test acc 0.853
1226.8 examples/sec on cuda:0进程已结束,退出代码0
















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











