






1. 系统概述
AI生成测试用例智能体平台是一款基于人工智能技术的测试用例自动生成工具,利用RAG(检索增强生成)技术,能够结合项目相关知识文档和历史用例,智能生成高质量的测试用例。本平台适用于测试团队快速创建测试用例,提高测试效率和质量。
主要功能
- 自动从需求文本生成结构化测试用例
- 支持多种文档格式的知识库导入和检索
- 结合历史用例和知识文档增强测试用例生成质量
- 支持多种AI大语言模型接入(本地、线上)
- 提供多种用例导出格式(Excel、JSON、Markdown)
2. 安装与配置
系统要求
- Python 3.8+
- 操作系统:Windows 10/11、macOS、Linux
安装步骤
-
克隆或下载项目代码
https://xxx.git (项目源码可我联系获取) cd rag_testcase_plafform -
创建并激活虚拟环境
# Windows python -m venv venv .\venv\Scripts\activate # Linux/macOS python -m venv venv source venv/bin/activate -
安装依赖包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple -
安装Ollama(默认本地模型,可选)
从Ollama官网下载并安装最新版本 -
下载模型(使用Ollama时)
ollama pull qwen2.5:7b -
启动应用
streamlit run rag_test_agent.py
3. 界面介绍
应用启动后会在浏览器中打开,界面分为三个主要标签页:
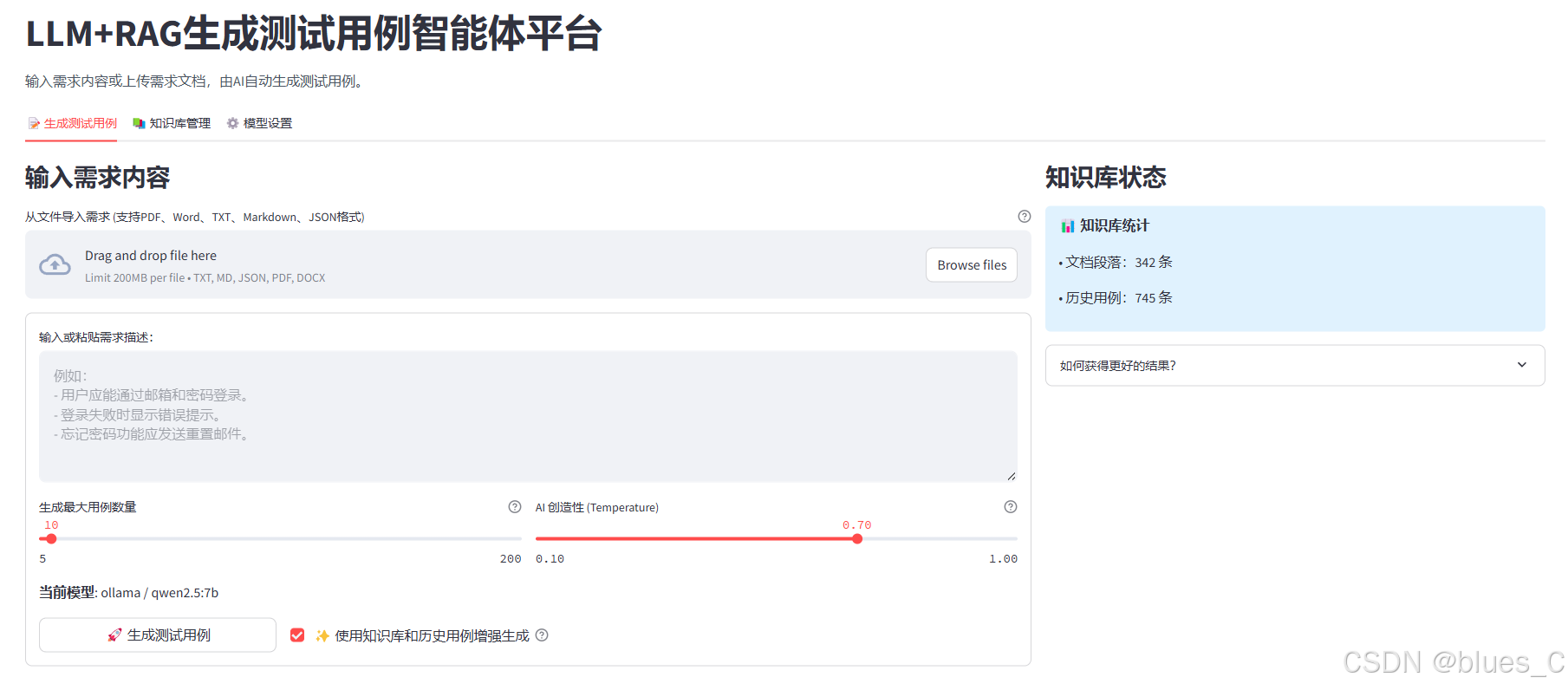
3.1 生成测试用例 (📝)
左侧区域用于输入需求描述和配置生成参数,右侧显示知识库状态。
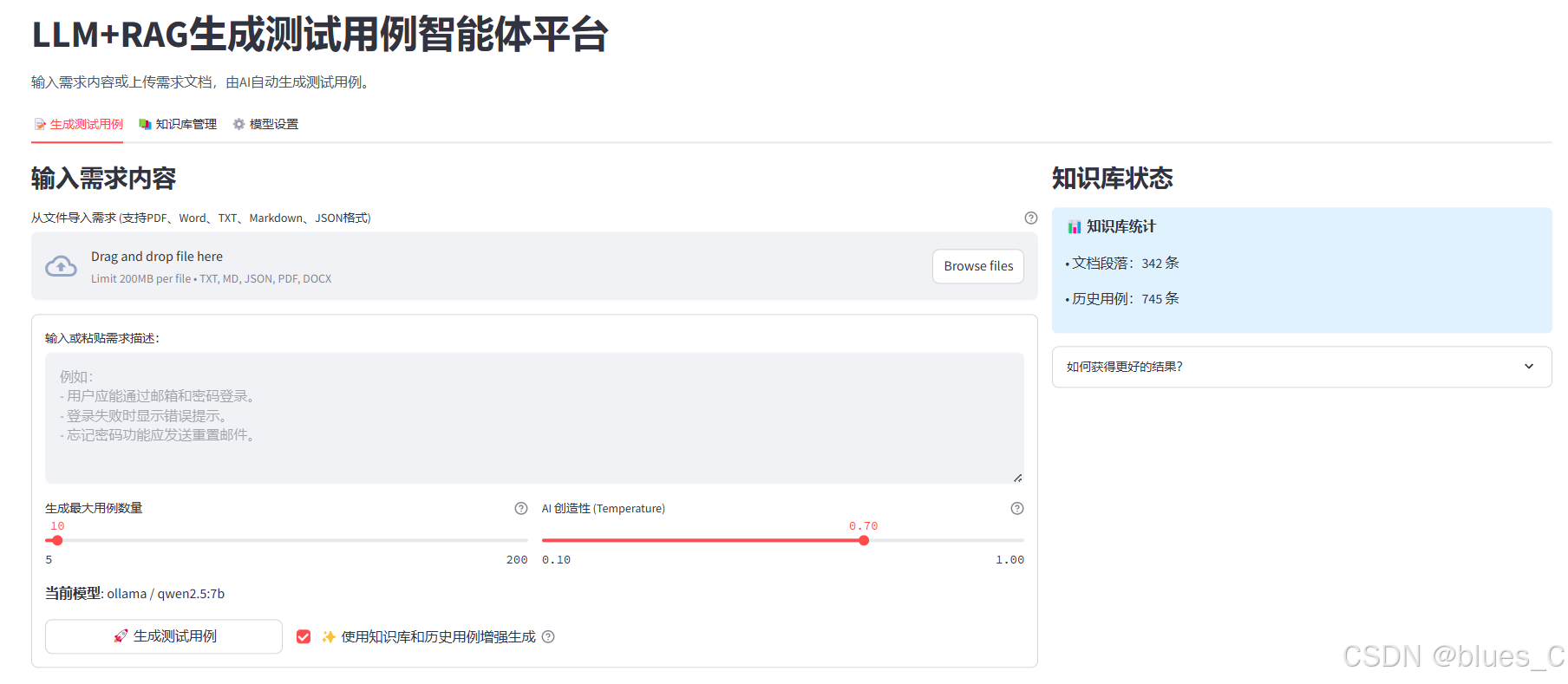
3.2 知识库管理 (📚)
用于上传和管理知识文档,查看已有知识库内容。
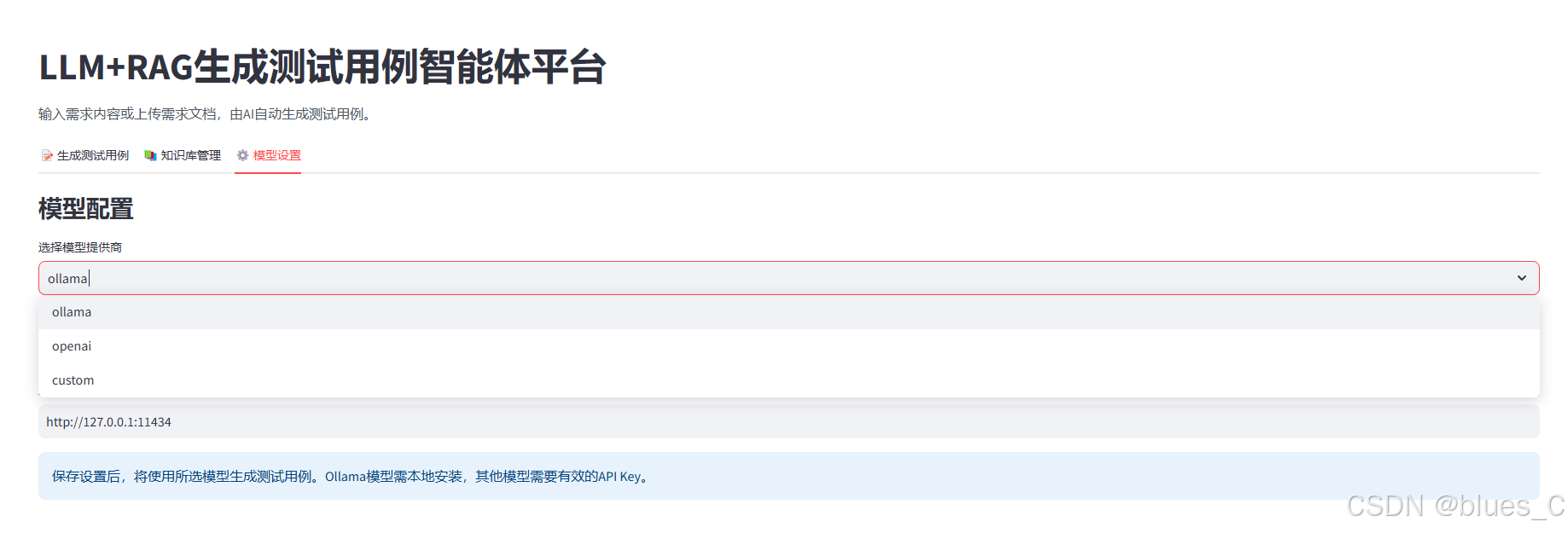
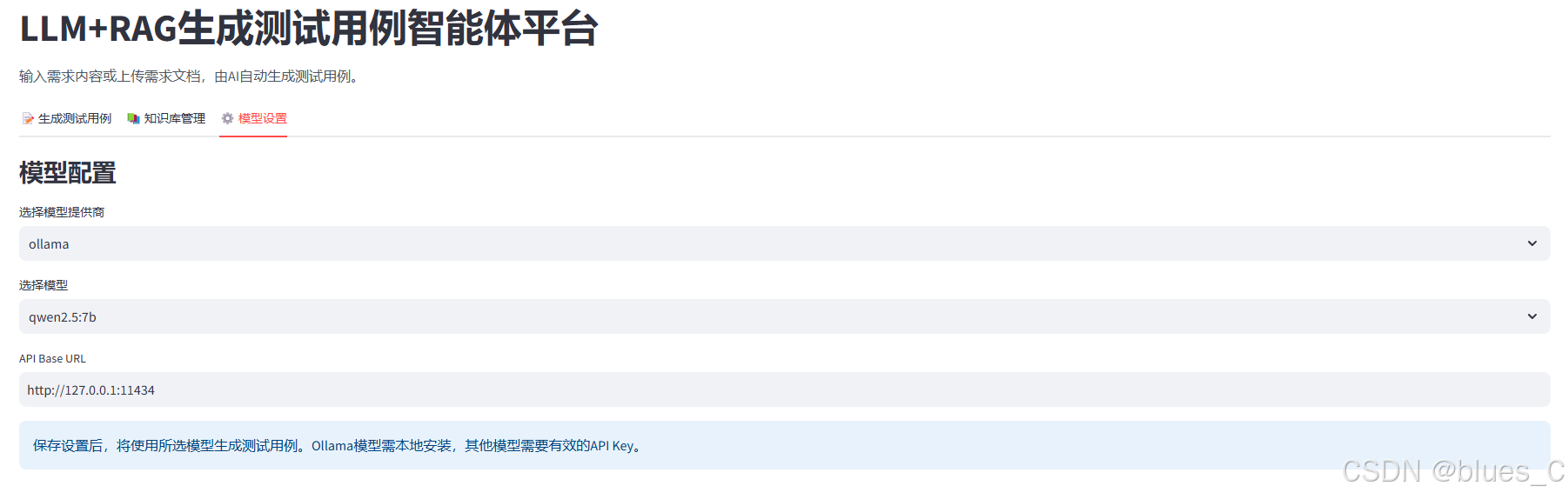
3.3 模型设置 (⚙️)
配置AI模型类型、参数和API连接信息。
4. 生成测试用例
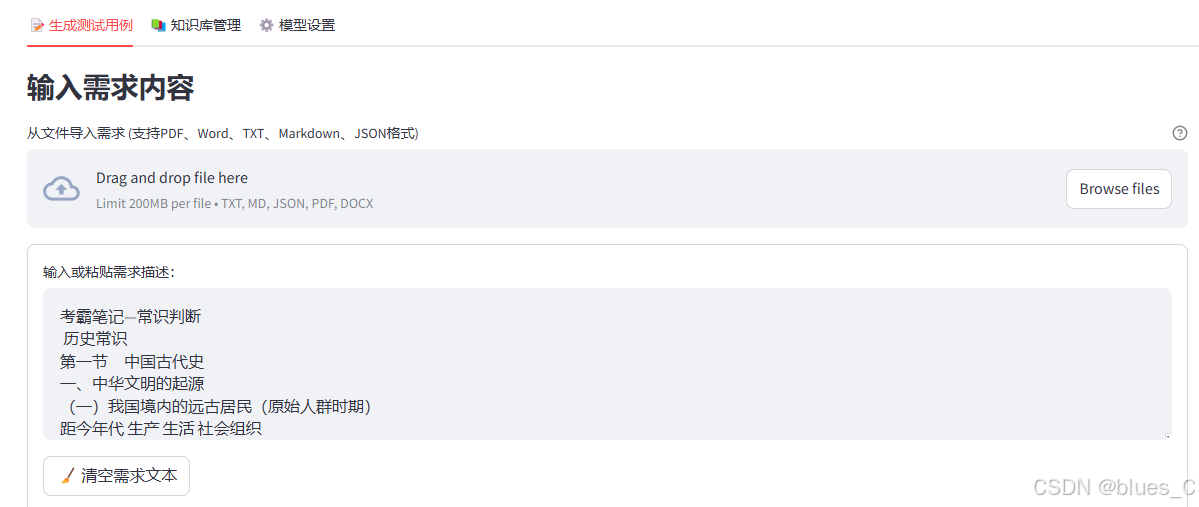
4.1 输入需求描述
有两种方式输入需求描述:
-
在文本框中直接输入或粘贴
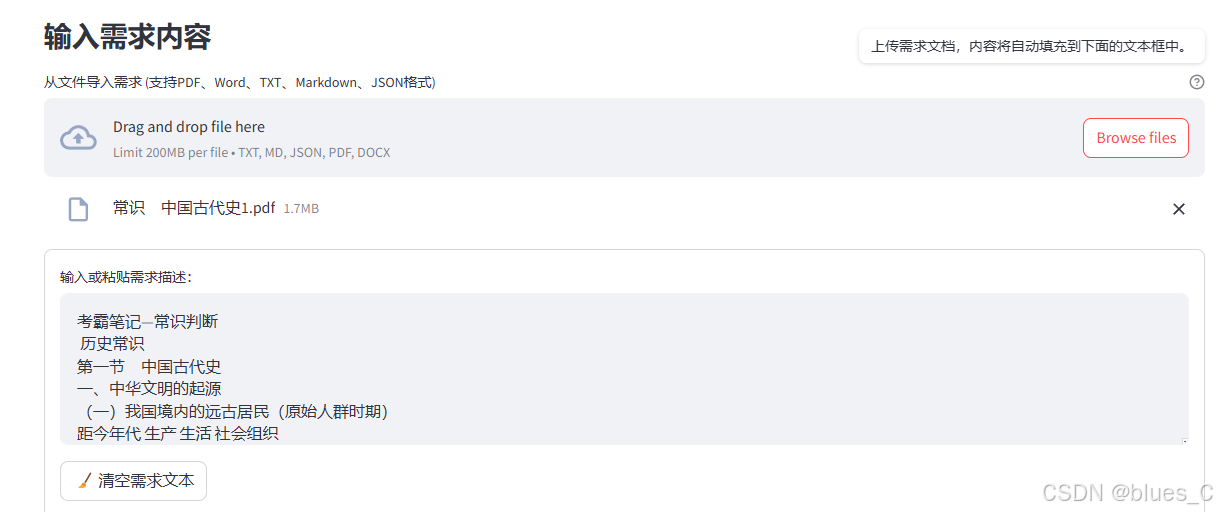
-
上传需求文档(支持PDF、Word、TXT、Markdown、JSON格式)
4.2 配置生成参数
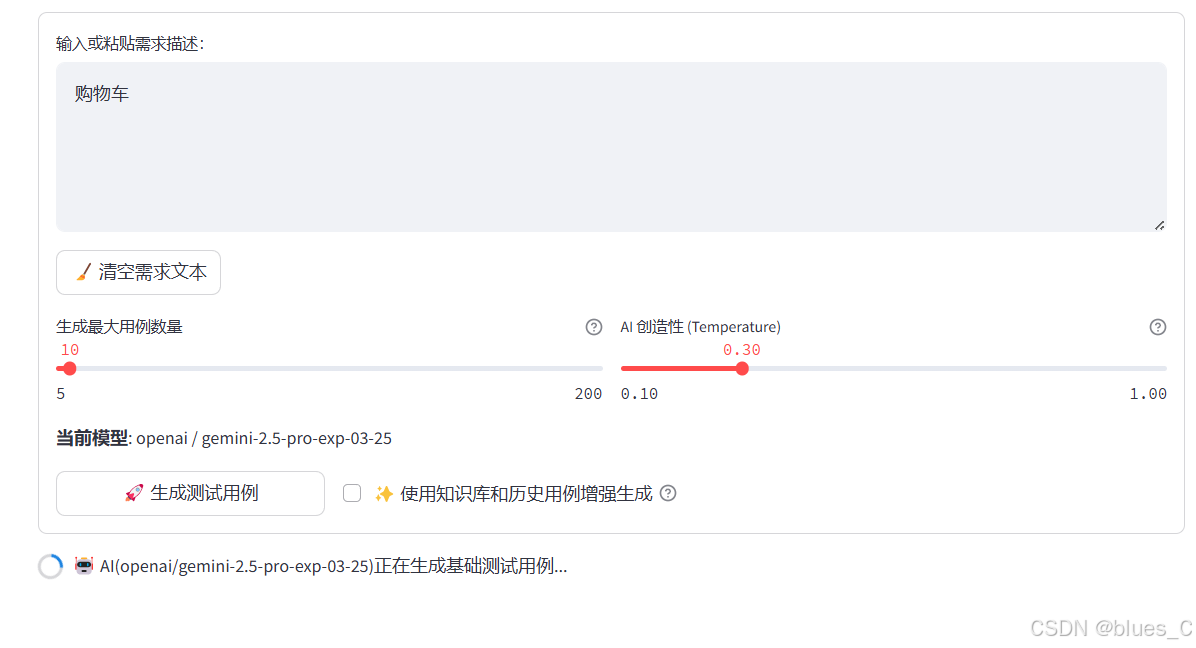
-
生成最大用例数量:设置需要生成的测试用例数量(5-200个)

-
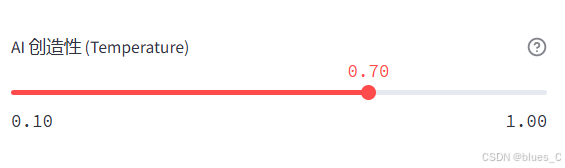
AI创造性(Temperature):控制生成结果的随机性(0.1-1.0)
- 较低值(如0.3):生成更保守、一致的结果
- 较高值(如0.8):生成更多样化、创新的结果
-
使用知识库和历史用例增强:勾选此选项结合已有知识库和历史用例生成更贴合场景的测试用例

4.3 生成测试用例
-
确认输入和参数后,点击"🚀 生成测试用例"按钮
-
系统首先会从知识库中搜索相关信息(如启用了增强功能)
-
调用AI模型生成测试用例
-
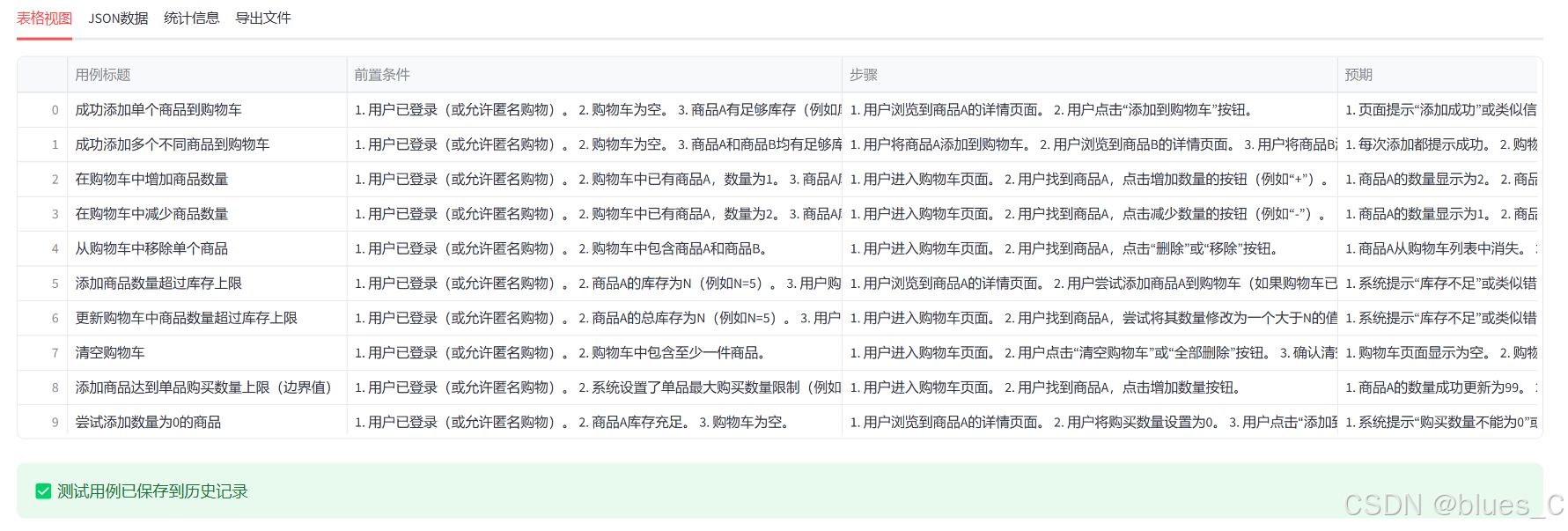
生成完成后显示结果,并自动保存到历史记录中
-
点击导出按钮,可直接导出Excel测试用例


4.4 查看生成结果
结果以四种形式展示:
- 表格视图:以表格形式显示测试用例
- JSON数据:原始JSON格式数据
- 统计信息:如优先级分布等统计图表
- 导出文件:提供JSON和Markdown两种导出选项

5. 知识库管理
5.1 上传知识文档
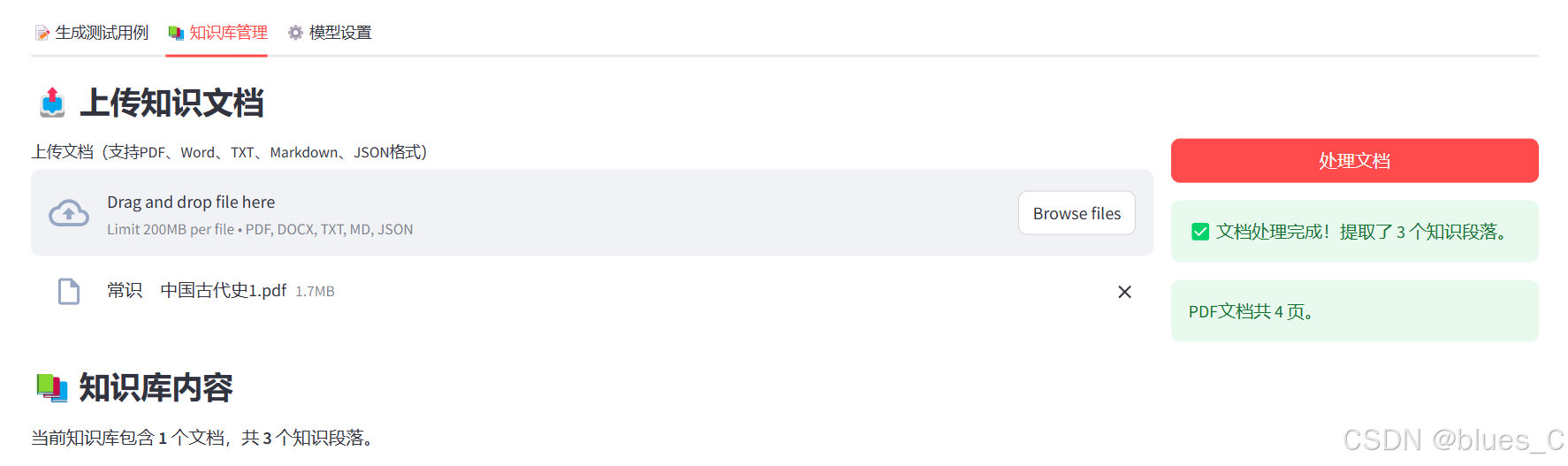
- 切换到"📚 知识库管理"标签页
- 上传文档(支持PDF、Word、TXT、Markdown、JSON格式)
- 点击"处理文档"按钮
- 系统会自动分析文档内容并提取知识段落
- 处理完成后显示提取的段落数量
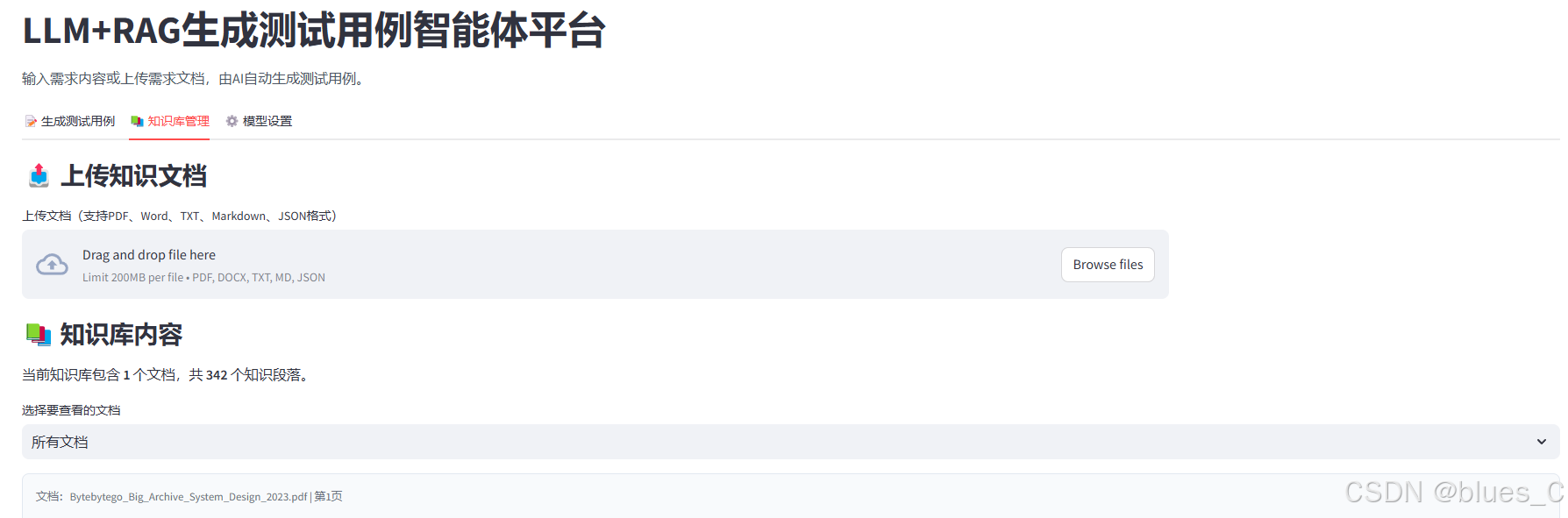
5.2 查看知识库内容
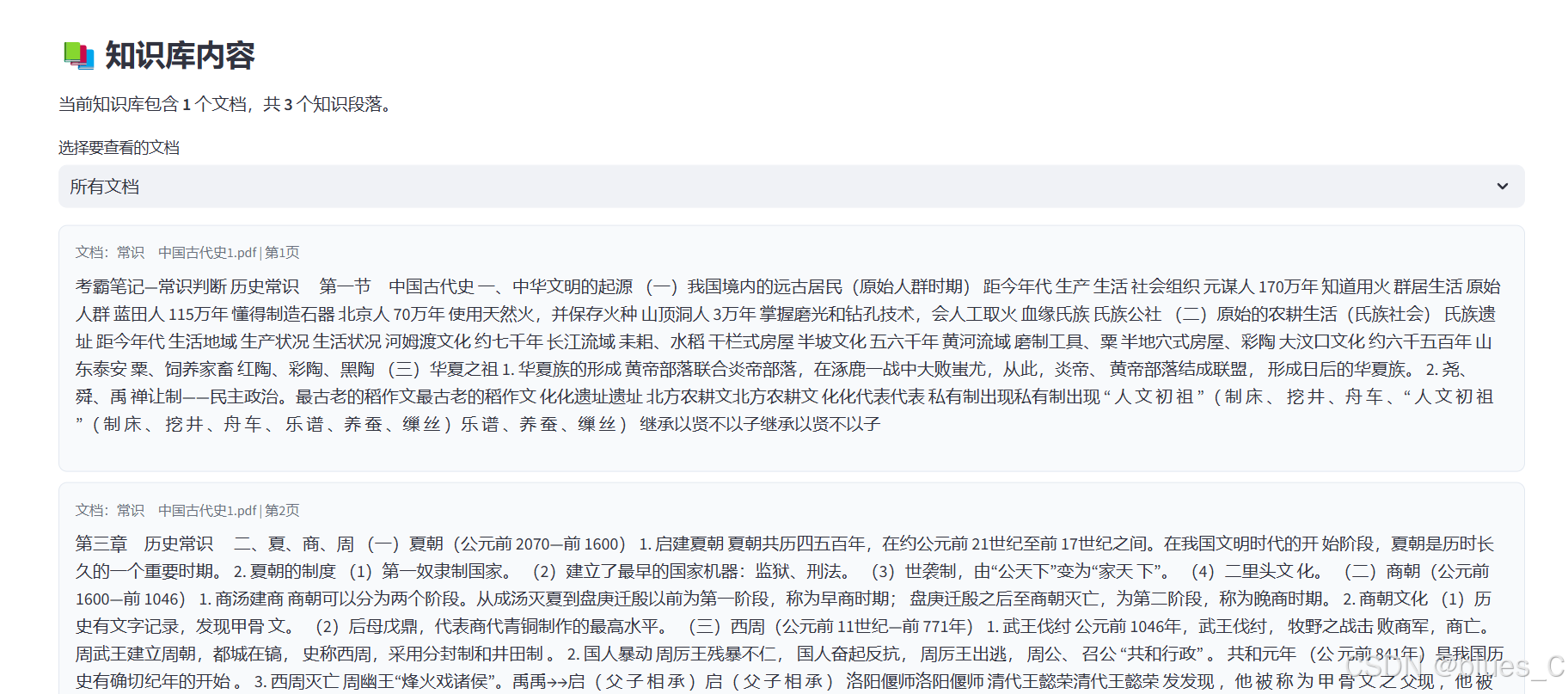
- 选择特定文档或查看所有文档
- 系统显示知识段落内容,包括所属文档和页码信息
- 默认显示前20条记录,若数量较多会提示总数
6. 模型设置
6.1 选择模型提供商
- Ollama:本地部署模型,默认选项
- OpenAI:使用OpenAI API服务
- Custom:自定义API服务

6.2 配置模型参数
根据选择的提供商配置相应参数:
Ollama
- 模型名称:选择可用的本地模型(qwen2.5:7b、llama3、mixtral等)
- API Base URL:默认为http://127.0.0.1:11434,本地Ollama服务地址

OpenAI
- 模型名称:选择OpenAI提供的模型(gpt-4、gpt-3.5-turbo等)
- API Key:输入OpenAI API密钥
- API Base URL:默认为https://api.openai.com

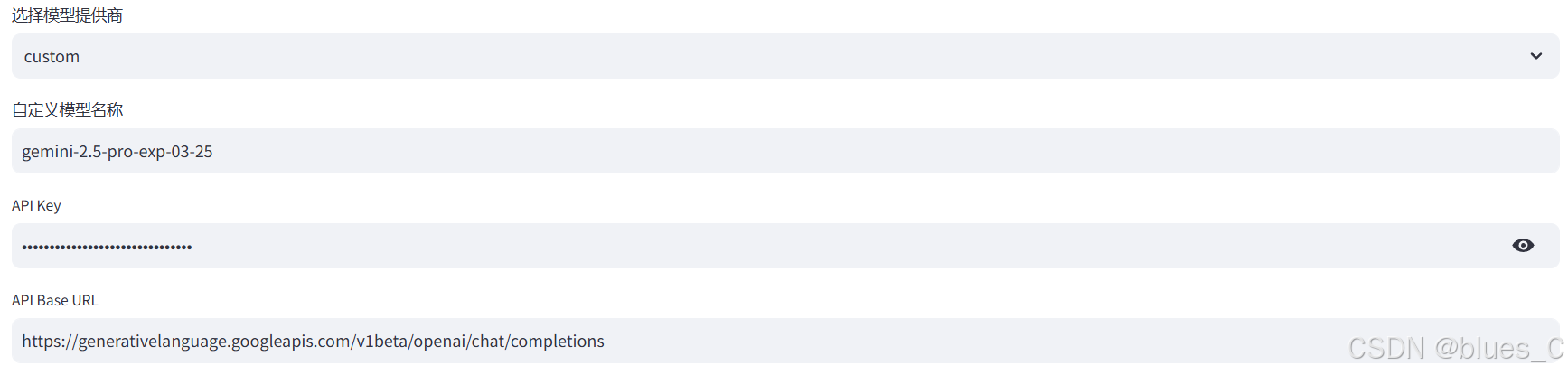
Custom
- 自定义模型名称:输入自定义模型名称
- API Key:输入API密钥(如需要)
- API Base URL:输入自定义API服务地址
7. 导出功能
7.1 导出为JSON
- 生成测试用例后,切换到"导出文件"标签
- 点击"导出为JSON"按钮下载JSON格式文件
7.2 导出为Markdown
- 生成测试用例后,切换到"导出文件"标签
- 点击"导出为Markdown"按钮下载Markdown格式文件
- 可在"Markdown预览"中查看导出效果

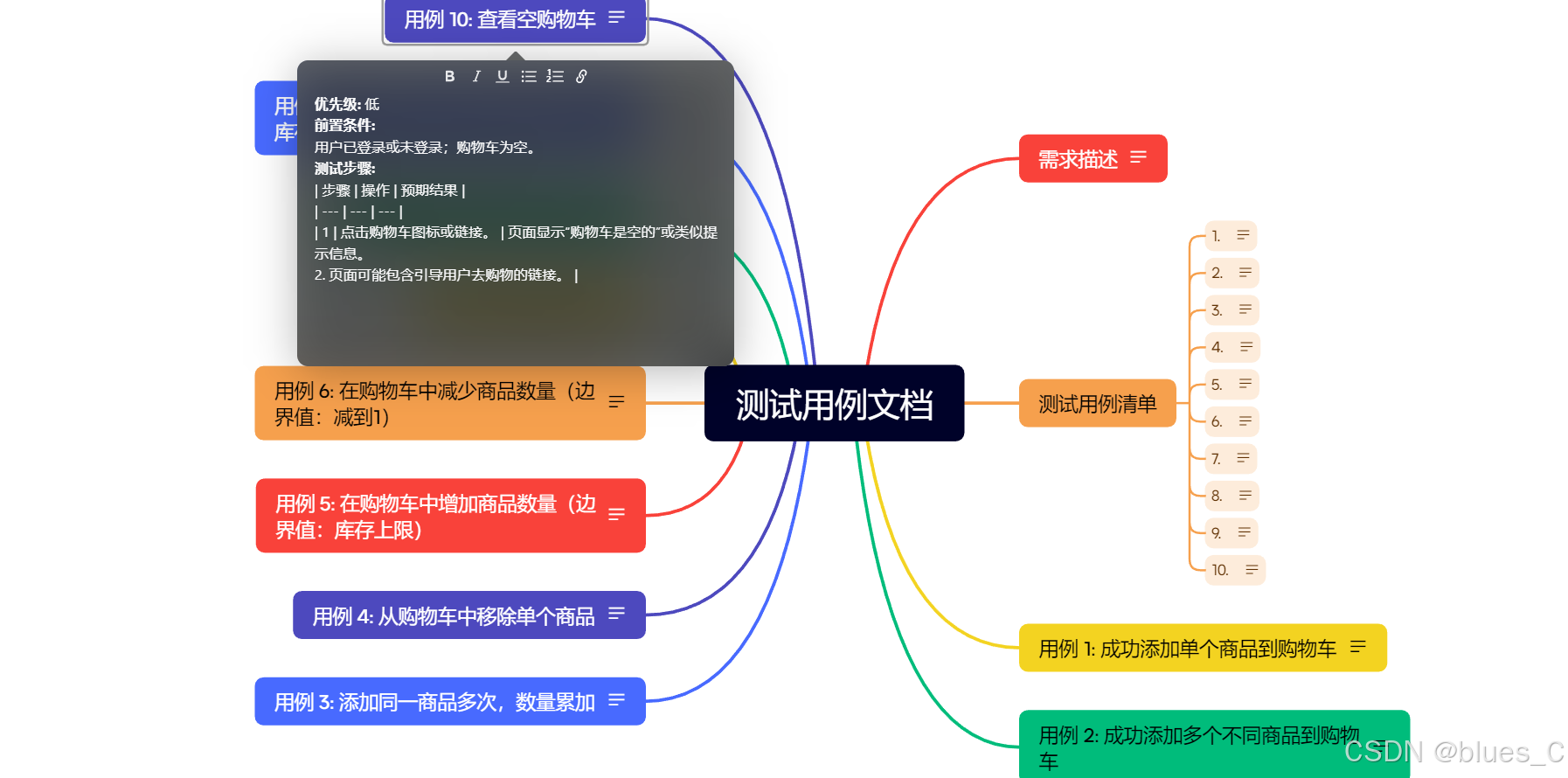
Markdown格式包含:
- 需求描述
- 测试用例列表(带编号和链接)
- 每个测试用例的详细信息(优先级、前置条件、测试步骤和预期结果)

- 导出md文件后,在xmind中导入,进行用例评审
8. 常见问题解答
8.1 生成的测试用例质量不高
- 确保提供详细、明确的需求描述
- 上传与需求相关的知识文档到知识库
- 调整AI创造性参数,尝试不同的值
- 勾选"使用知识库和历史用例增强"选项
8.2 模型连接失败
- Ollama模型:确认Ollama服务已启动且能访问(默认地址:http://127.0.0.1:11434)
- OpenAI模型:验证API密钥是否正确
- 检查网络连接是否正常
8.3 文档上传失败
- 确认文档格式是否支持(PDF、Word、TXT、Markdown、JSON)
- 检查文档是否损坏或加密
- 尝试将文档分割为更小的文件
9. 最佳实践
9.1 提高测试用例生成质量
- 提供详细需求:包含功能细节、业务规则和边界条件
- 充实知识库:上传项目文档、产品规格说明、原型设计等
- 迭代优化:基于生成结果调整需求描述,多次迭代
9.2 知识库管理建议
- 定期更新知识库文档,确保内容最新
- 上传针对特定功能的专业文档,提高相关性
- 对于大型文档,考虑分割后上传,提高处理效率
9.3 效率提升技巧
- 先用较低的用例数量生成,查看质量后再增加数量
- 利用导出功能与测试管理工具集成
- 在团队间共享和复用知识库,避免重复工作
通过本文档,相信你应能够快速上手LLM+RAG的生成测试用例智能体平台,高效地生成和管理测试用例。如有更多问题或建议,请及时联系我。


















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











